概率论
概率论是研究随机现象数量规律的数学分支。
相对:决定性现象。在一定条件下必然发生某一结果的现象称为决定性现象。
举例:掷骰子、扔硬币、抽扑克牌
数理统计(Mathematical statistics)
数理统计是数学的一个分支,分为描述统计和推断统计。
它以概率论为基础,研究大量随机现象的统计规律性。
- 描述统计的任务是搜集资料,进行整理、分组,编制次数分配表,绘制次数分配曲线,计算各种特征指标,以描述资料分布的集中趋势、离中趋势和次数分布的偏斜度等。
- 描述性统计 – 描述数据的统计数据部分,即汇总数据及其典型属性
- 推断统计是在描述统计的基础上,根据样本资料归纳出的规律性,对总体进行推断和预测。
- 推论统计 – 从数据中得出结论的统计数据部分(使用某些数据模型):例如,推论统计涉及选择数据模型,检查数据是否满足特定模型的条件,并量化涉及不确定性(例如使用置信区间)。
线性代数(linear algebra)
线性代数是数学的一个分支,它的研究对象是向量,向量空间(或称线性空间),线性变换和有限维的线性方程组。
线性代数是几何的现代表示中的基础,包括用于定义基本对象,例如线,平面和旋转。
最大后验概率 - Maximum a posteriori estimation | MAP
在贝叶斯统计,一个最大后验概率(MAP)估计是未知数,即等于的估计模式的的后验分布。
MAP可用于基于经验数据获得未观测量的点估计。
它与最大似然(ML)估计方法密切相关,但采用了包含先验分布的增强优化目标(量化通过相关事件的先前知识获得的额外信息)超过想要估计的数量。因此,MAP估计可以被视为ML估计的正则化。
约束优化(Constrained optimization)
它是在一系列约束条件下,寻找一组参数值,使某个或某一组函数的目标值达到最优。
其中约束条件既可以是等式约束也可以是不等式约束。
寻找这一组参数值的关键可是:满足约束条件和目标值要达到最优。
张量 | Tensor
什么是张量
AI领域概念
A tensor is a generalization of vectors and matrices to potentially higher dimensions. 张量是多维数组,目的是把向量、矩阵推向更高的维度。
数学意义
张量是一种几何对象,它以多线性方式将几何向量,标量和其他张量映射到结果张量。
张量是一个可用来表示在一些矢量、标量和其他张量之间的线性关系的多线性函数。
矢量(也说向量) 物理学上指由大小和方向共同决定的量(跟「标量」相区别)。如力、速度等。
标量、向量、矩阵、张量的关系
点——标量(scalar)
线——向量(vector)
面——矩阵(matrix)
体——张量(tensor)
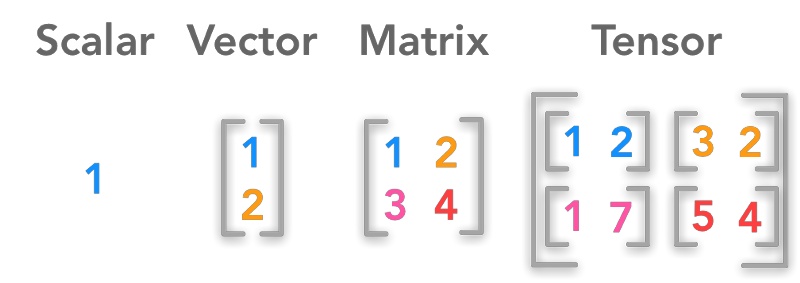
标量
标量只有大小概念,没有方向的概念。通过一个具体的数值就能表达完整。
比如:重量、温度、长度、提及、时间、热量等都数据标量。
向量
向量主要有2个维度:大小、方向。
大小:箭头的长度表示大小
方向:箭头所指的方向表示方向
向量的3种表达方式:代数、几何、坐标表示
1.代数表示
一般印刷用黑体的小写英文字母(a、b、c等)来表示,手写用在a、b、c等字母上加一箭头(→)表示
如 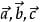
2.几何表示
向量可以用有向线段来表示。有向线段的长度表示向量的大小,向量的大小,也就是向量的长度。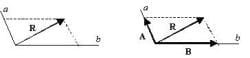
3.坐标表示
在平面直角坐标系中,分别取与x轴、y轴方向相同的两个单位向量i,j作为一组基底。a为平面直角坐标系内的任意向量,以坐标原点O为起点P为终点作向量a。由平面向量基本定理可知,有且只有一对实数(x,y),使得a=xi+yj,因此把实数对(x,y)叫做向量a的坐标,记作a=(x,y)。这就是向量a的坐标表示。其中(x,y)就是点 P 的坐标。向量a称为点P的位置向量。
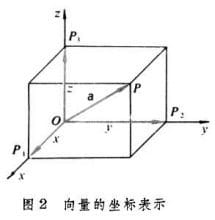
在空间直角坐标系中,分别取与x轴、y轴,z轴方向相同的3个单位向量i,j,k作为一组基底。若为该坐标系内的任意向量,以坐标原点O为起点作向量a。由空间基本定理知,有且只有一组实数(x,y,z),使得a=ix+jy+kz,因此把实数对(x,y,z)叫做向量a的坐标,记作a=(x,y,z)。这就是向量a的坐标表示。其中(x,y,z),就是点P的坐标。向量a称为点P的位置向量。
当然,对于多维的空间向量,可以通过类推得到。
向量的矩阵表示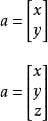
矩阵
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合,元素是实数的矩阵称为实矩阵,元素是复数的矩阵称为复矩阵。
而行数与列数都等于n的矩阵称为n阶矩阵或n阶方阵。
由 m × n 个数aij排成的m行n列的数表称为m行n列的矩阵,简称m × n矩阵。记作:
概率密度函数(Probability Density Function)
用于描述(一维)连续型随机变量所服从的概率分布
思想:通过“面积”来求概率 (如正方形两种颜色各半,其某种颜色发生的概率就是那一半的面积)
先验概率和后验概率
先验概率
先验概率(prior probability)是指根据以往经验和分析得到的概率,如全概率公式,它往往作为”由因求果”问题中的”因”出现的概率。
在贝叶斯统计推断中,不确定数量的先验概率分布(通常简称为先验)是在考虑一些因素之前表达对这一数量的置信程度的概率分布。
置信水平(confidence level)
指特定个体对待特定命题真实性相信的程度,也就是概率是对个人信念合理性的量度。
后验概率
在贝叶斯统计,所述后验概率一个的随机事件或不确定的命题是条件概率是分配相关后证据或背景考虑。类似地,
后验概率分布是未知量的概率分布,作为随机变量处理,
条件是从实验或调查中获得的证据
在这种情况下,“后验”是指在考虑与被审查的具体案件有关的相关证据之后。
计算
后验概率的计算要以先验概率为基础。后验概率可以根据通过贝叶斯公式,用先验概率和似然函数计算出来。
贝叶斯公式:
其中 代表一种假设。
代表一种假设。
其中 代表一种观察结果。
代表一种观察结果。
称 为先验概率,是在还没有观测
为先验概率,是在还没有观测 的情况下,
的情况下, 自身的概率。
自身的概率。
称 为后验概率,表示在观察到了
为后验概率,表示在观察到了 的情况下,
的情况下, 的条件概率。
的条件概率。
称 为似然函数(不叫似然概率),其中C为常数,因为似然函数的绝对数值没有意义。
为似然函数(不叫似然概率),其中C为常数,因为似然函数的绝对数值没有意义。
称 为证据因子(model evidence),有时也会称为边缘似然。
为证据因子(model evidence),有时也会称为边缘似然。
举例
例题:假设一个学校里有60%男生和40%女生。女生穿裤子的人数和穿裙子的人数相等,所有男生穿裤子。
一个人在远处随机看到了一个学生,这个学生是女生的概率是多少?
没有任何观测值时候,完全根据经验来判断的概率,叫做先验概率。
一个人在远处随机看到了一个穿裤子的学生。
有了观测值以后,通过观测值,来反推Unobserved events发生的概率,就叫后验概率。
如果一个人在一个随机点上挖掘,就会发现(“非后验”)概率,如果他们在金属探测器响起的地方挖掘,则会发现埋藏宝藏的后验概率。
先验可以是概率分布,其表示将在未来选举中投票给特定政治家的选民的相对比例。
未知数量可以是模型的参数或潜在变量而不是可观察变量。
“瓜熟蒂落”的例子:
- 首先要理解“瓜熟”是“因”,“蒂落”是“果”
- 其次要理解“瓜熟”并不一定会“蒂落”(就是那么顽强),而“蒂落”了也并不一定“瓜熟”(被熊孩子掰下来了)
- 也就是说一切都有概率存在。
代入到贝叶斯公式中, 为瓜熟,
为瓜熟, 为蒂落,然后可以考虑如下定义:
为蒂落,然后可以考虑如下定义: 是先验概率。作为“因”,瓜熟有自己的固有概率,这就叫“先验”。
是先验概率。作为“因”,瓜熟有自己的固有概率,这就叫“先验”。 是后验概率。当观察到了“果”然后推算“因”的条件概率。
是后验概率。当观察到了“果”然后推算“因”的条件概率。 是似然函数。由“因”而导致“果”的可能性。
是似然函数。由“因”而导致“果”的可能性。
最后 被称为证据因子。当然它本身作为“因”的时候也可以看做是“蒂落”的先验概率,但在本公式讨论范围中,它是“果”。
被称为证据因子。当然它本身作为“因”的时候也可以看做是“蒂落”的先验概率,但在本公式讨论范围中,它是“果”。
特别的,关于似然函数 :
:
其实在上述西瓜例子里, 就是一个由“因”到“果”的条件概率,那干嘛要乘上一个常数C,然后称之为似然呢?
就是一个由“因”到“果”的条件概率,那干嘛要乘上一个常数C,然后称之为似然呢?
概率probability和似然likelihood从英语语境中的是可以互换的,但概率有更严格的数学定义。
在机器学习的任务之中,所谓的“因”实际上是参数。因为机器学习的任务,是把参数当成“因”,把训练数据当成“果”,通过训练数据来学习参数。而参数并不是事件,不符合概率的严格定义,因此对于某一参数产生实际数据情况的可能性,只能称之为“似然”。
全概率公式和贝叶斯公式
全概率公式
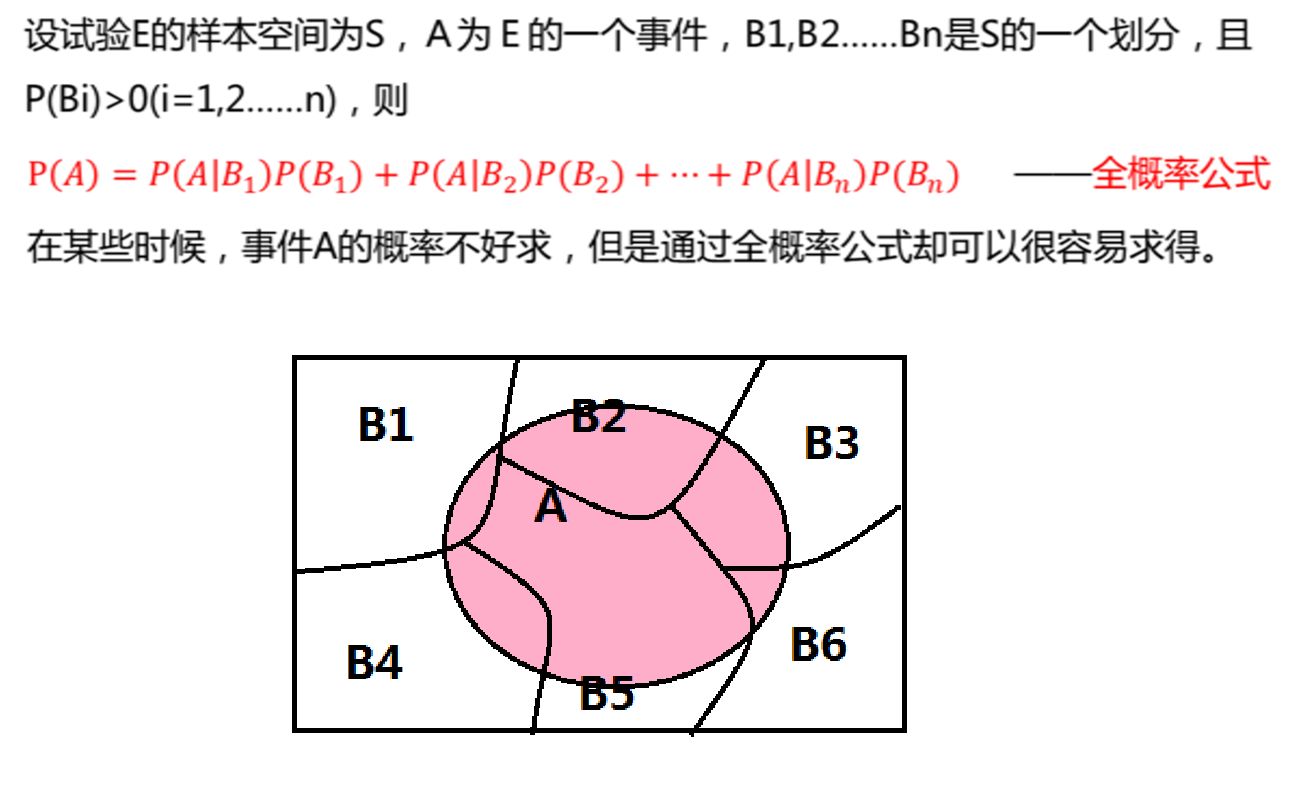

可以看出,全概率公式是“由因推果”的思想,当知道某件事的原因后,推断由某个原因导致这件事发生的概率为多少。
贝叶斯公式
贝叶斯公式:
其中 代表一种假设。
代表一种假设。
其中 代表一种观察结果。
代表一种观察结果。
称 为先验概率,是在还没有观测
为先验概率,是在还没有观测 的情况下,
的情况下, 自身的概率。
自身的概率。
称 为后验概率,表示在观察到了
为后验概率,表示在观察到了 的情况下,
的情况下, 的条件概率。
的条件概率。
称 为似然函数(不叫似然概率),其中C为常数,因为似然函数的绝对数值没有意义。
为似然函数(不叫似然概率),其中C为常数,因为似然函数的绝对数值没有意义。
称 为证据因子(model evidence),有时也会称为边缘似然。
为证据因子(model evidence),有时也会称为边缘似然。

可以看出,贝叶斯公式是“由果溯因”的思想,当知道某件事的结果后,由结果推断这件事是由各个原因导致的概率为多少。
实例

参数估计(Parameter Estimatiom)
Signal processing
- the aim is to obtain some information from the signal (or data)
- inverse of known mapping will suffice (and is often simpler) if noise is small
- better approach: optimum mapping (good quality processing for large noise)
- due to noise, signals are random, hence use statistical approach
Statistical signal processing
- Detection: hypothesis testing, “which value from the set?” (cf. AT-M51)2.
- Estimation: point estimation, “how big is the value?”
估计理论(Estimation theory)
Extract information from noisy signals
估计理论是对收信端接收到的混有噪声的信号,用统计学方法估计出信号的参量或状态的理论。
估计分为参量估计和状态估计两类。
参量和状态的区别是:前者随着时间保持不变或只缓慢变化;后者则随着时间连续变化。
例如
根据雷达回波来估计每一时刻在连续变化的卫星的三个空间位置矢量和三个速度矢量,这是状态估计。
对卫星的质量和惯量等的估计则属于参量估计。
被估计的参量又可分为随机变量和非随机变量两种。
要估计的状态则又有离散时间和连续时间的区别。
常用的估计方法
最小平方误差估计、极大似然估计和贝叶斯估计。
极大似然估计 – Maximum Likelihood Estimate | MLE
‘似然’= likelyhood,即最大可能性估计
定义:
一种在给定观察的情况下估计统计模型的参数的方法。
在给定观察结果的情况下,MLE尝试找到使似然函数最大化的参数值。
得到的估计称为最大似然估计,其也缩写为MLE。
举例:
假设我们对成年雌性企鹅的高度感兴趣,但无法测量群体中每只企鹅的高度。
(由于成本或时间的限制,只知道总体人口的某些样本的高度。)
假设高度正常分布有一些未知的均值和方差,可以用MLE估计均值和方差。
MLE将通过将均值和方差作为参数并找到特定的参数值来实现这一点,这些参数值使得观察到的结果在给定正态模型的情况下最可能。
梯度下降法 – Gradient descent
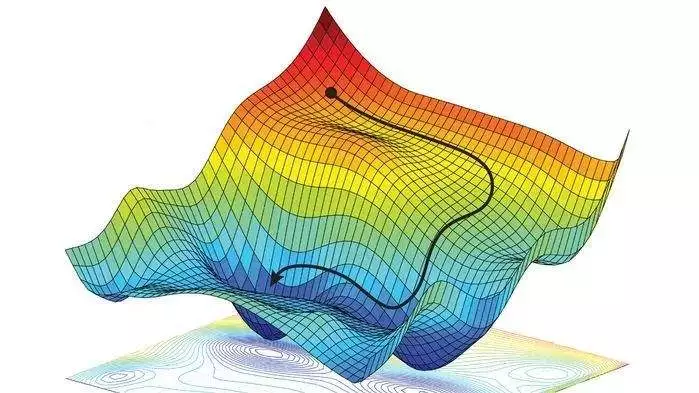
梯度下降算法的公式非常简单,”沿着梯度的反方向(坡度最陡)。
以爬上山顶为例
假设我们位于一座山的山腰处,没有地图,并不知道如何到达山顶。于是决定走一步算一步,也就是每次沿着当前位置最陡峭最易上山的方向前进一步,然后继续沿下一个位置最陡方向前进一小步。这样一步一步走下去,一直走到觉得我们已经到了山顶。这里通过最陡峭的路径上山的方向就是梯度。
梯度下降法(英语:Gradient descent)是用于找到函数最小值的一阶迭代优化算法,通常也称为最速下降法
为了使用梯度下降找到函数的局部最小值,需要采用与当前点处函数的梯度(或近似梯度)的负值成比例的步长。
相反,如果采用与梯度的正值成比例的步长,则接近该函数的局部最大值 ; 然后将该过程称为梯度上升。
什么是梯度?
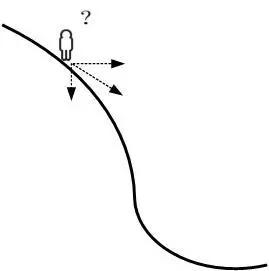
通俗来说,梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在当前位置的导数。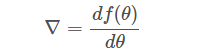
上式中,θ 是自变量,f(θ) 是关于 θ 的函数,θ 表示梯度。
如果函数 f(θ) 是凸函数,那么就可以使用梯度下降算法进行优化。梯度下降算法的公式我们已经很熟悉了: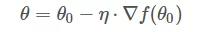
θo 是自变量参数,即下山位置坐标,η 是学习因子,即下山每次前进的一小步(步进长度),θ 是更新后的 θo,即下山移动一小步之后的位置。
延申阅读
随机梯度下降法(Stochastic gradient descent | SGD)
随机梯度下降(通常缩短为SGD),也称为增量梯度下降,是用于优化可微分目标函数的迭代方法,梯度下降优化的随机近似。
Stochastic Gradient Descent (SGD) is a simple yet efficient optimization algorithm used to find the values of parameters/coefficients of functions that minimize a cost function.
Stochastic gradient descent(abbreviated as SGD) is an iterative method often used for machine learning, optimizing the gradient descent during each search once a random weight vector is picked.
The gradient descent is a strategy that
searches through a large or infinite hypothesis space whenever
1) there are hypotheses continuously being parameterized and
2) the errors are differentiable(可微的) based on the parameters.
假设检验(Hypothesis test)
假设检验是推论统计中用于检验统计假设的一种方法。
而“统计假设”是可通过观察一组随机变量的模型进行检验的科学假说。
一旦能估计未知参数,就会希望根据结果对未知的真正参数值做出适当的推论。

若有收获,就点个赞吧
0 人点赞
