- KL divergence
- Variational inference
- Variational Bayesian EM
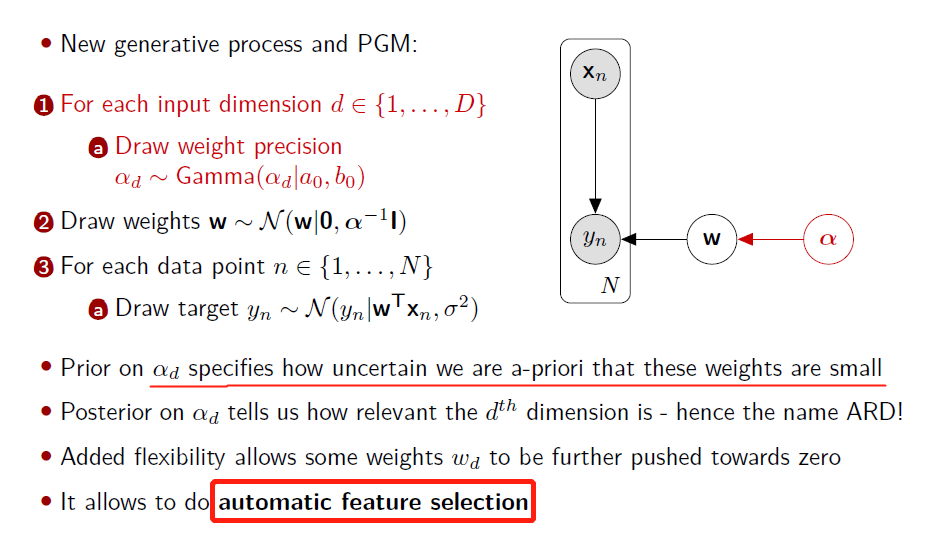
- Automatic Relevance Determination
Recall
推断问题:计算观测数据的似然值、边缘分布、条件分布、密度众数

Approximate inference
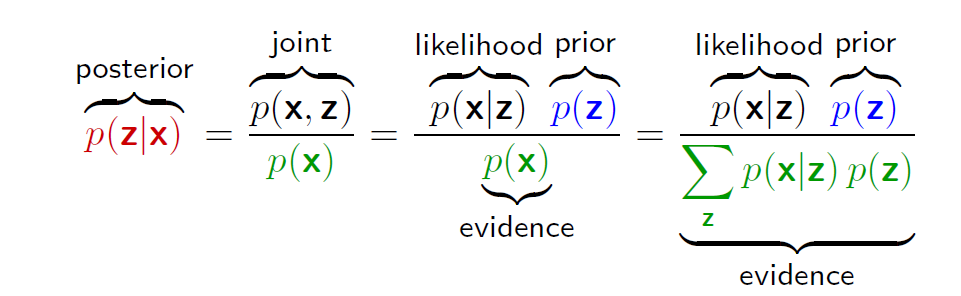
在概率模型的应⽤中,⼀个中心任务是在给定观测(可见)数据变量X的条件下,计算潜变量Z的后验概率分布p(Z | X)。但在很多情况下,后验估计非常棘手(intractable)
Reasons
- 潜在空间的维度太高,以至于无法直接计算;
- 后验概率分布的形式特别复杂,从而期望无法解析地计算。
前面学习了通过使用子例程抽样随机变量为推理问题提供近似解的算法(例如,边际推理)。
大多数基于采样的推理算法是马尔可夫链蒙特卡洛(MCMC)的实例;
两种流行的MCMC方法是Gibbs采样和Metropolis-Hastings。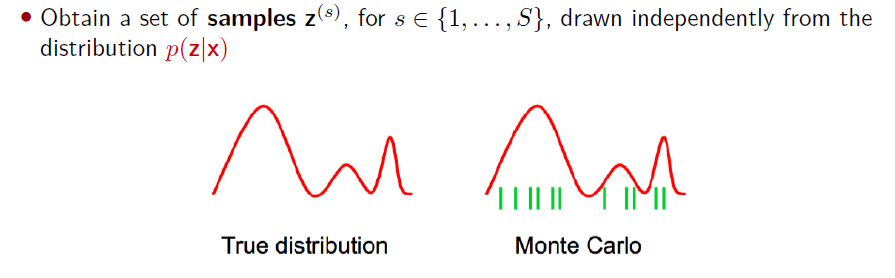
然而!基于采样的方法有几个重要的缺点:
- 计算要求大,不适合大数据集:虽然在足够的时间内,他们保证能找到一个全局最优的解决方案,但考虑到他们在实践中的时间有限,很难说他们离一个好的解决方案有多近。
- 需要提前决定好采样方法:为了快速达成一个好的解决方案,MCMC方法需要选择适当的采样技术,determining convergence, number of samples, burn-in size, thinning, hard to diagnose, etc
Variational Inference
Princeton/cos597C/lectures/variational-inference-i.pdf
https://brunomaga.github.io/Variational-Inference-GMM【总体介绍、简明易懂】

As usual, we will assume that x = x1:n are observations and z = z1:m are hidden variables. We assume additional parameters α that are fixed.
变分方法
变分推断的方法基于的是真实后验概率分布的分解近似。
Main idea behind variational methods: to pick a family of distributions(分布族) over the latent variables with its own variational parameters(变分变量).
find a member q⋆ of that family which is close to the target posterior p(z∣x).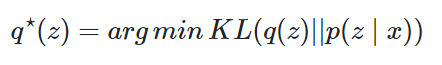
Mean-field variational inference 变分法
Mean Field Variational Inference zhihu.com/p/96971565
Q:那么如何给q(z)选择一个可处理的分布族呢(tractable family of distributions)?
A:Mean-field variational inference 平均场变分推理
We can also assume that the distribution factorizes in groups of latent variables
Kullback-Leibler Divergence
Variational Inference and Learning 爱丁堡大学
定义:未知的分布p(x)和近似的分布q(x)之间的相对熵 (衡量差异度)(relative entropy) 或 者Kullback-Leibler散 度(Kullback-Leibler divergence),或者KL散度(Kullback and Leibler, 1951)
应用:在数据压缩和密度估计(即对未知概率分布建模)之间有⼀种隐含的关系,因为当我们知道真实的概率分布之后,我们可以给出最有效的压缩。如果我们使⽤了不同于真实分布的概率分布,那么我们⼀定会损失编码效率,并且在传输时增加的平均额外信息量至少等于两个分布之间的Kullback-Leibler散度。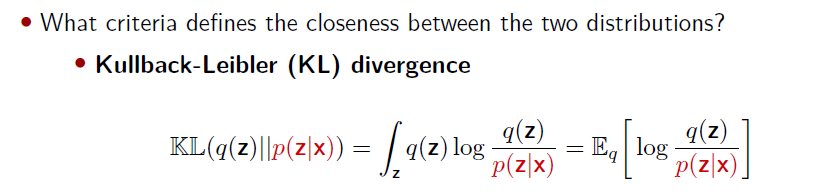

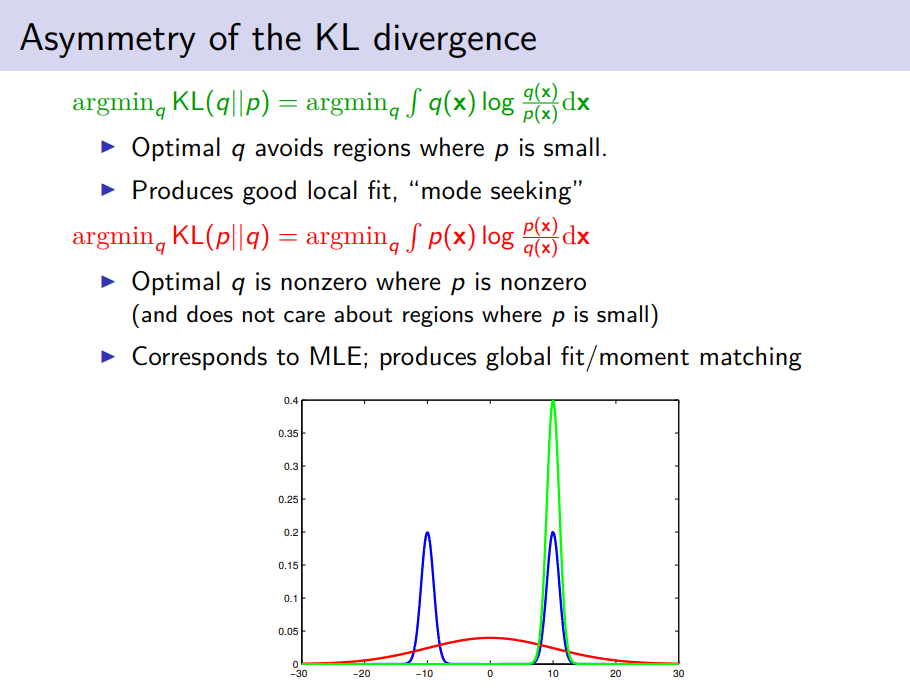

KL in EP and VI
Variational inference (VI) vs expectation propagation (EP)蓝⾊轮廓线展⽰了由两个⾼斯分布混合⽽成的 双峰概率分布p(Z),红⾊轮廓线对应于⼀个⾼斯分布q(Z),它最⼩化了Kullback-Leibler散度KL(p ∥ q), 在这种意义上最好地近似了p(Z)。(b)与(a)相同,但是此时红⾊轮廓线对应的⾼斯分布q(Z)是通过使⽤数值⽅法最⼩化Kullback-Leibler散度KL(q ∥ p)的⽅式得到的。(c)与(b)相同,但是给出了Kullback-Leibler散度的另⼀个局部最⼩值。")
mode-seeking: 在给定从该函数采样的离散数据的情况下定位密度函数的最大值(众数)的过程 moment-matching: The moment matching method (MME) is a widely used method of estimation of parameters. The idea is to find values of the unknown parameters that result in a match between the theoretical (or population) and sample moments evaluated from data.
KL minimization

无法直接最小化KL ——> 最小化KL等价于最大化下界L(q)最大化
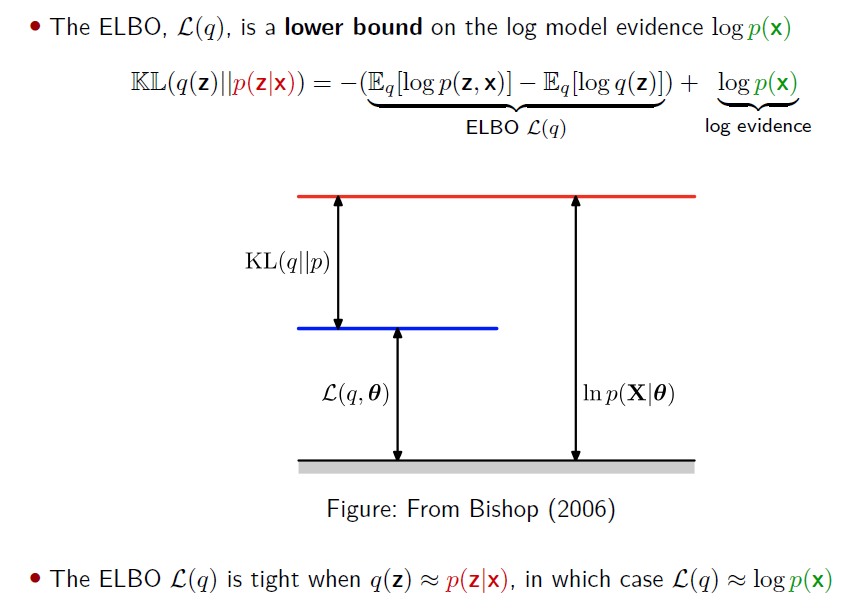

最终目的转换成最大化ELBO
Two different perspectives on the ELBO L(q)

实例

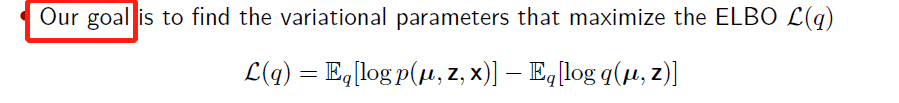


More details: Expectations
Expectations

Playtime




Optimizing hyper-parameters
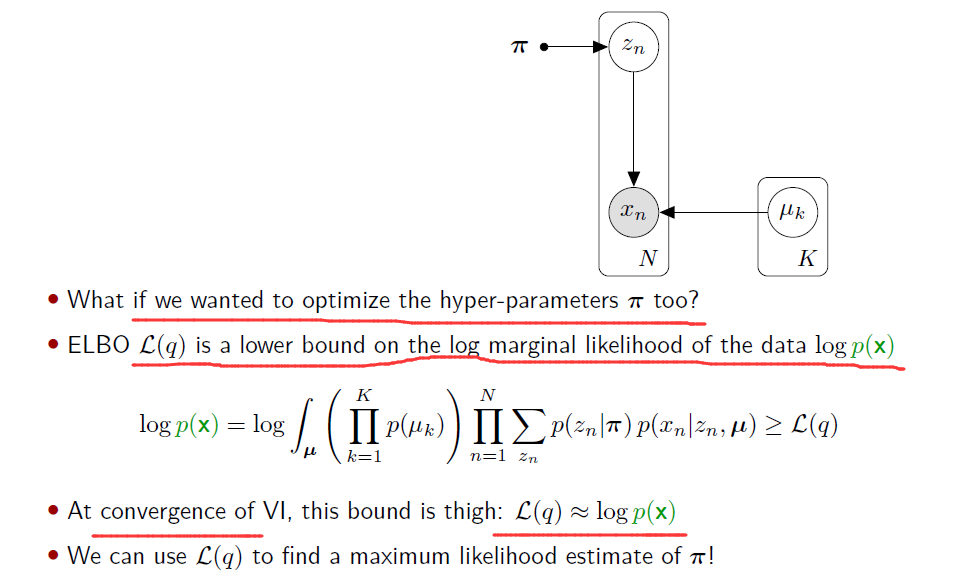
Variational Bayesian Expectation-Maximization (VB-EM)
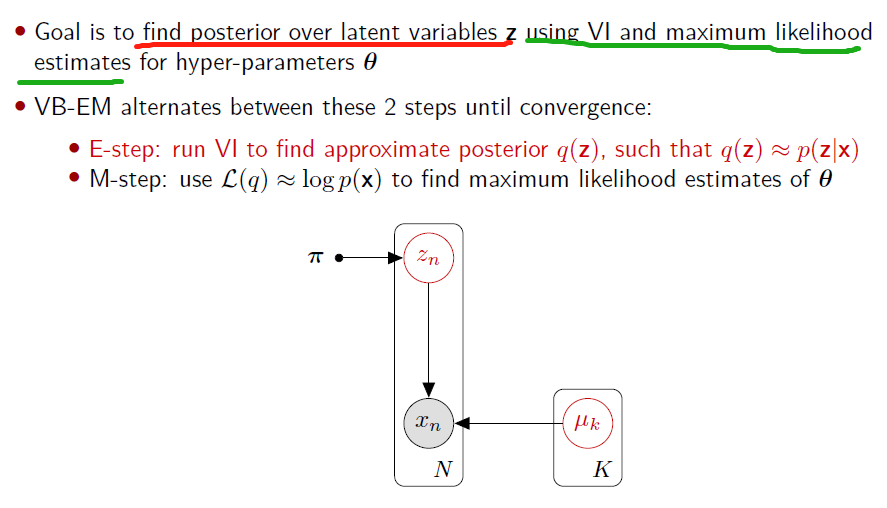
Relation with standard Expectation-Maximization (EM)

VI example: Automatic Relevance Determination (ARD) 自动相关性确定


Playtime


若有收获,就点个赞吧
0 人点赞
