学习如何选择和验证你的实验中使用的指标。

Define
我们做AB test的第一件事是为我们的实验定义一个或多个指标,也就是说我们需要衡量实验组还是对照组的好坏,在决定如何定义metrics之前,应该先思考定义这些metrics的目的,即你会用这些指标来做什么。
Two use cases
- Sanity checking metrics 合理性/完整性检查指标
- 寻找在实验组和对照组中invariant metrics(不变指标),然后进行sanity check
- population总体是否一致(e.g. 用户量)
- distribution分布是否一致(e.g. 不同国家用户数量是否可比较)
- 寻找在实验组和对照组中invariant metrics(不变指标),然后进行sanity check
- Evaluation metrics 评估指标
- What 哪些指标
- High-level/Overall business metrics 上层业务指标(e.g. revenue, market share, user base)
- More Detailed Metrics 更细致的指标,关系产品的用户体验(e.g. Time on Page etc.)
- When we need detailed metrics 什么时候要更细致的指标
- 举例:Users aren’t finishing a class on Udacity. We want to know why.
- 是否视频加载时间太长?—> latency 延迟;quizzes太难?—>正确率
- 方法:user experience research
- What 哪些指标
How to choose
- A high level concept(概念):一句话总结,通过这句话大家能够理解这个指标,如“活跃用户active users”,“点击率click-through probability”
- The nitty gritty details(细节):如何定义?e.g. “活跃”,在线7天、28天?
- Summarize into one(合并):将所有指标总结为一个复合指标,可以是“和,计数,平均,中位数”等等
Single or Multiple metrics
- 从文化角度来看,这取决于公司和你在公司是什么职位,面对领导,他们更愿意看到一整套指标,这样可以更全面了解业务的发展;
- 出于公关目的,在外部报告中,你可能需要制定一个;
- 如果你在一家大公司工作,可能会遇到一个问题,你不想让一个团队朝着一个目标努力,另一个团队朝另一个目标努力,因此在这种情况下,可以创建一个复合指标(composite metric),称为目标函数或 OEC(overall evaluation criterion)综合评估标准(这是微软在加权函数的基础上,结合所有不同的指标提出的一个术语)。
一般来说,倾向于避免使用OEC,理由有三点:
- 首先,很难定义。定义一个代表收益、用户和其他东西结合的指标很难,还得让所有员工认同更难;
- 其次,如果你过度优化、看重一件事情,往往会忽略其他事情的发展。尤其是如果你对网站进行一些重大修改时可能会出问题;
- 开始使用时,大家会问你为什么使用这个指标?最后无论如何你都要考虑所有这些不同的事情。
★Less optimal, but more applicable:
相比一个完美的指标,我们更在乎一个指标是否普遍使用(generally applicable)。一个没有那么完美,但是适用于整套测试(used across the suite),用来对比的指标才是最合适的。
High-level concepts for metrics
Start with the overall business objective 从总体业务目标开始
Expanding on the funnel 细化客户渠道
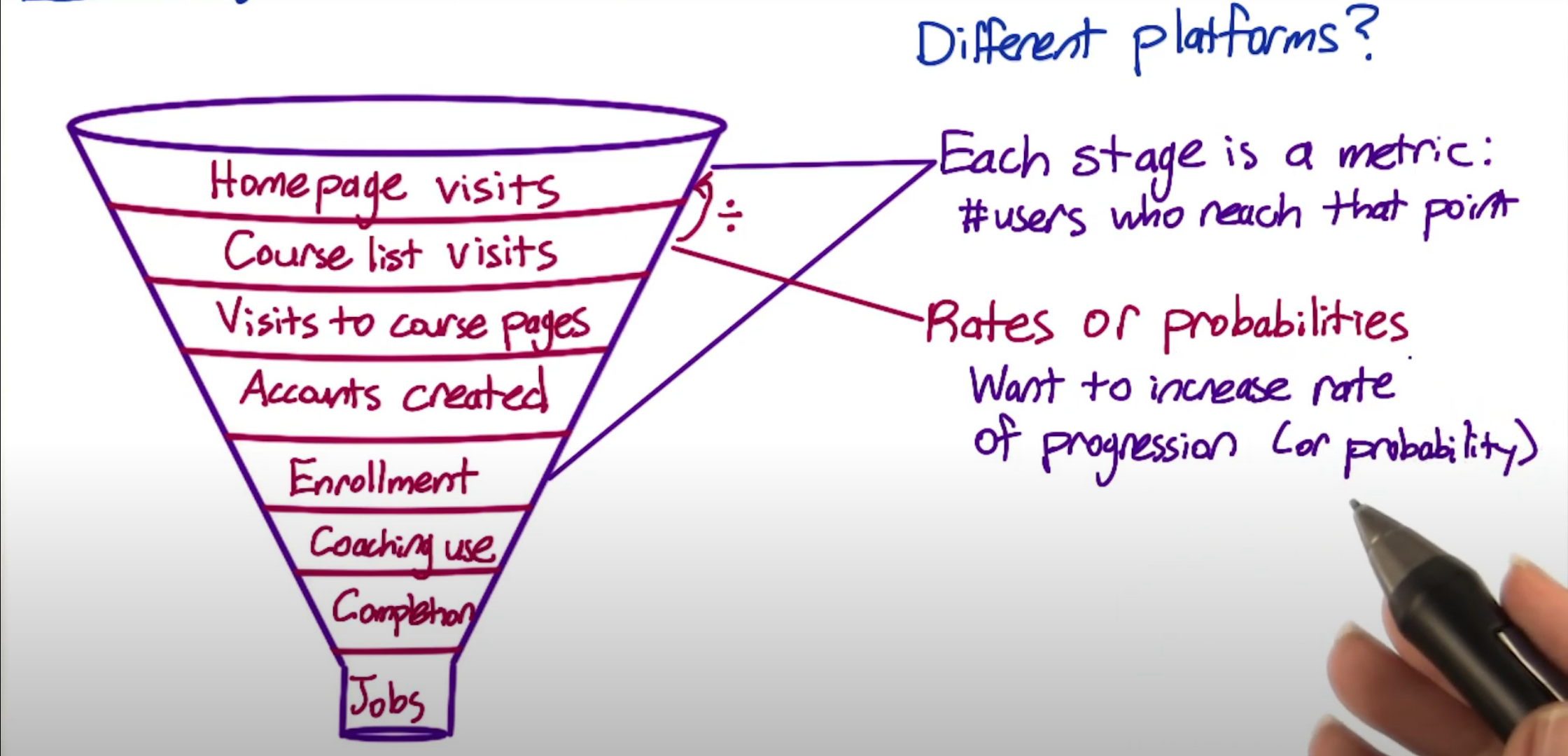
Choosing metrics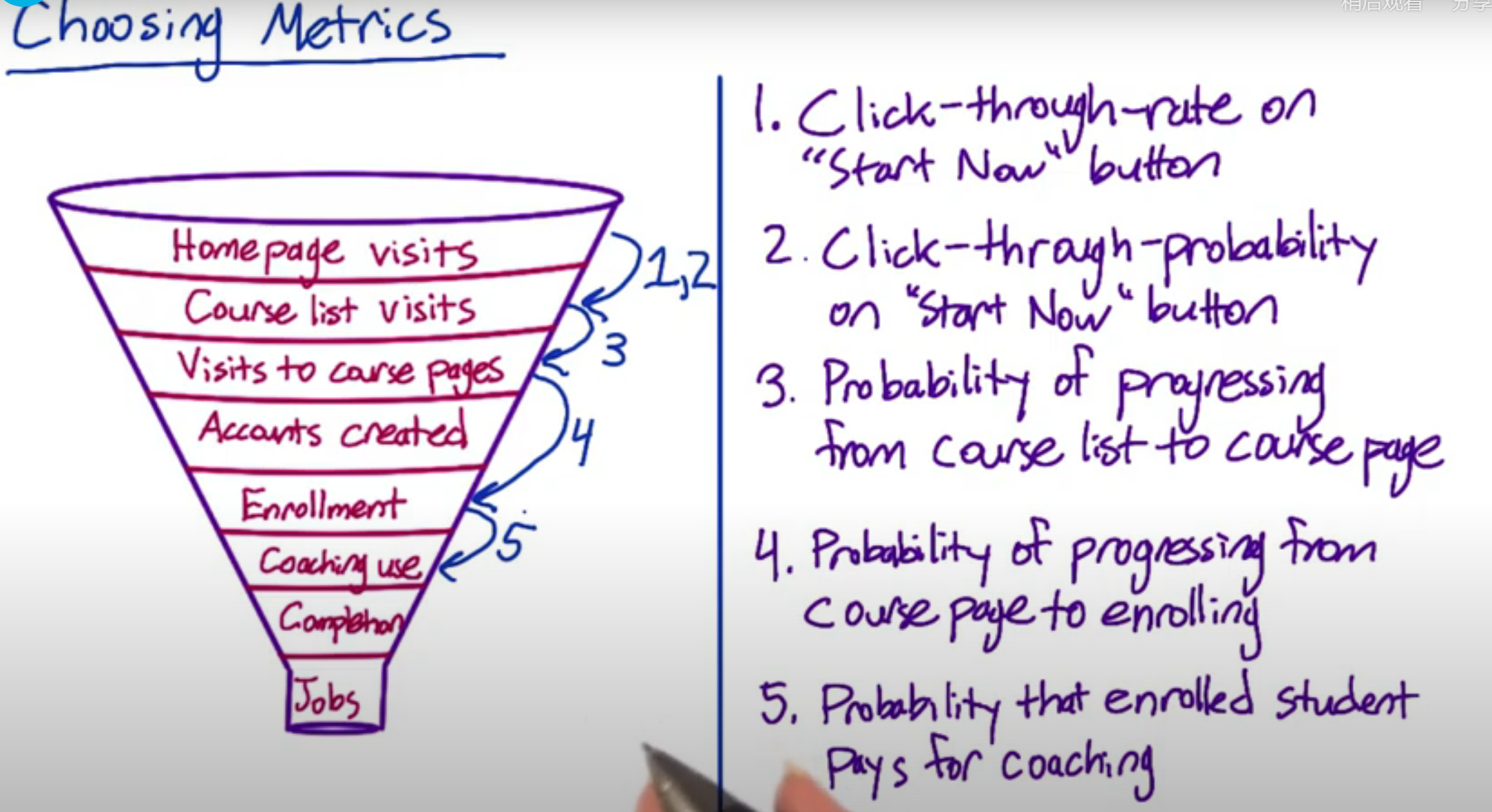
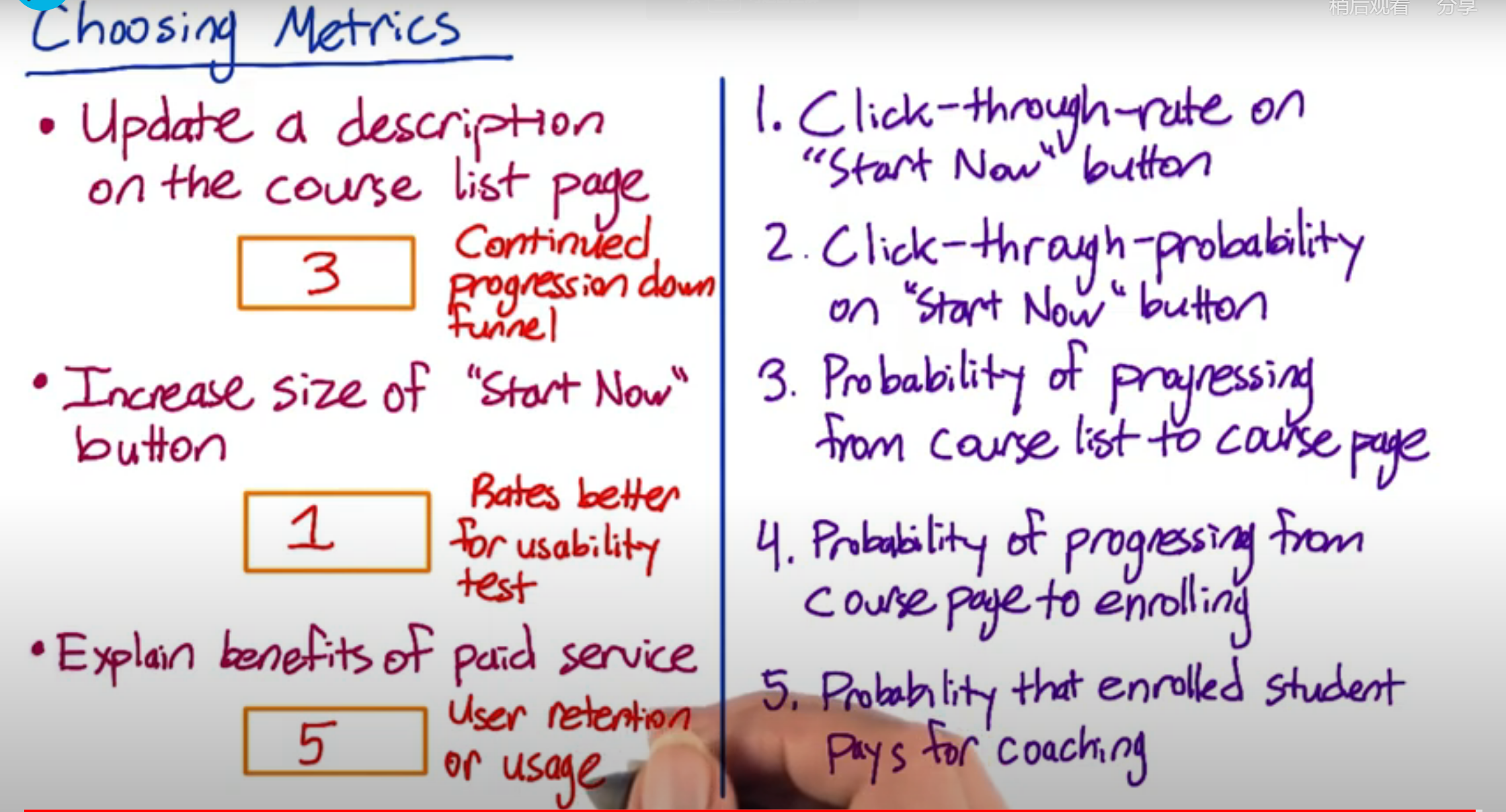
Difficult metrics 困难指标

定义指标:其他技巧
Additional Techniques for Brainstorming and Validating Metrics
- Retrospective Analysis
Gathering additional data 收集更多数据
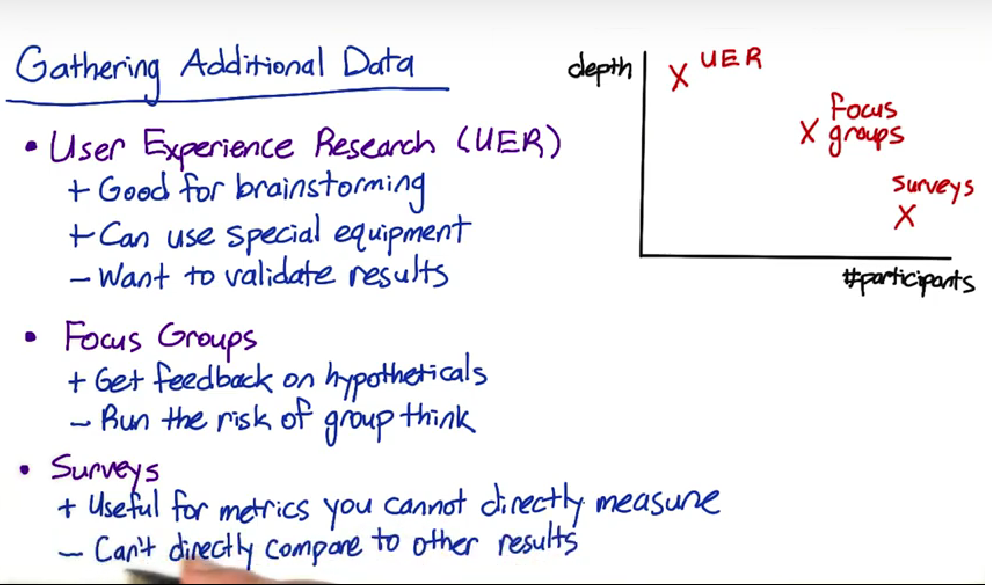
Building intuition
How to transfer from High-level metrix to Specific/Fully realized definition
- Fully decide what data we’re gonna look at to compute the metrix
- 分子,分母
- evaluating possible filters
- Summary metrics
实际方法:建立关于指标、数据、系统的直觉
举例:如何计算点击率
重点:明白 which to count and how to combine
有很多方法去计算:
- 直接算分子分母
- 利用cookie (用来辨识是否为同一用户的一小段的文本信息key-value)
具有variability,得根据实际情况执行
比如:underlying technology会改变我们的计算方法(Javascript发送的204请求是常用的点击率计算方式之一,但不同浏览器不一定支持或者ping的时候failure rate不一样)
Defining a metrix
定义 1(Cookie 概率):对于每个 <时间间隔>,点击的 Cookie 数量除以 Cookie 总数
定义 2(网页流量概率):<时间间隔> 内点击的网页浏览量除以网页浏览量总数
定义 3(比例):点击数除以网页浏览量总数
Segmenting and filtering data
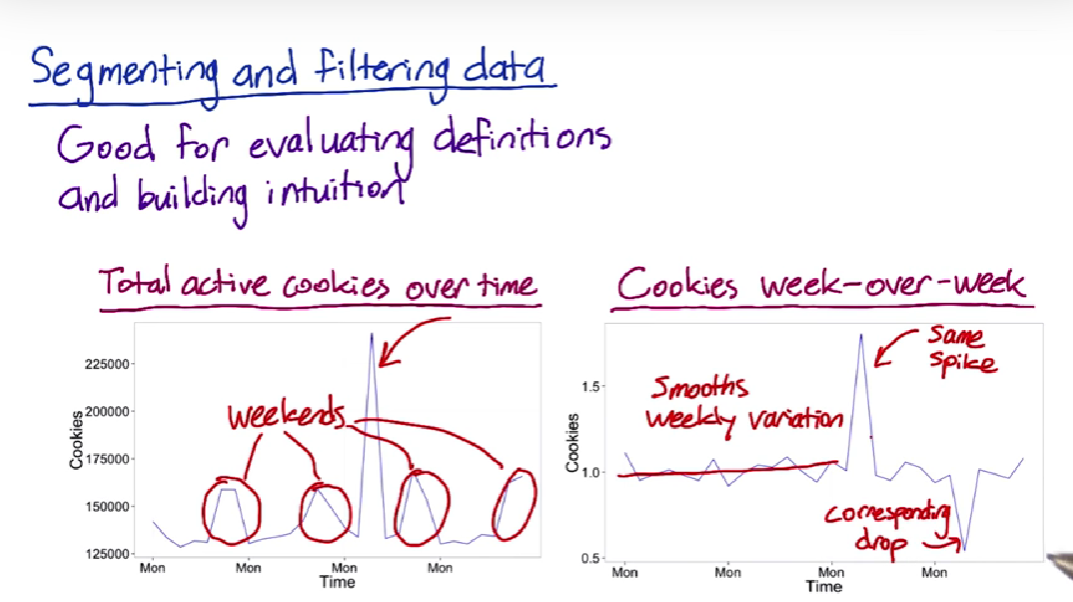
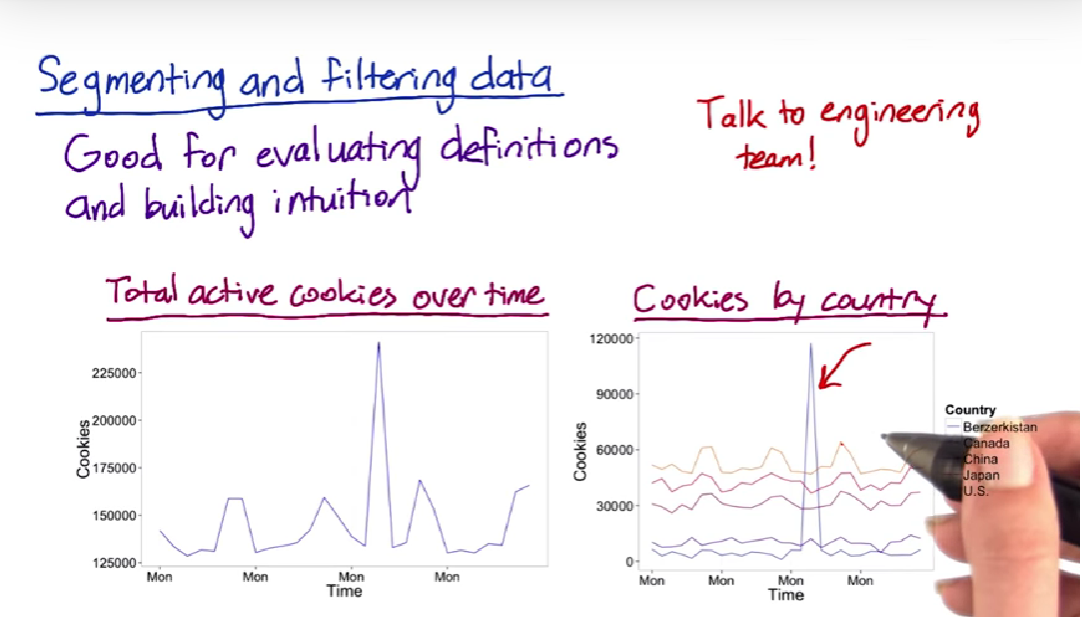
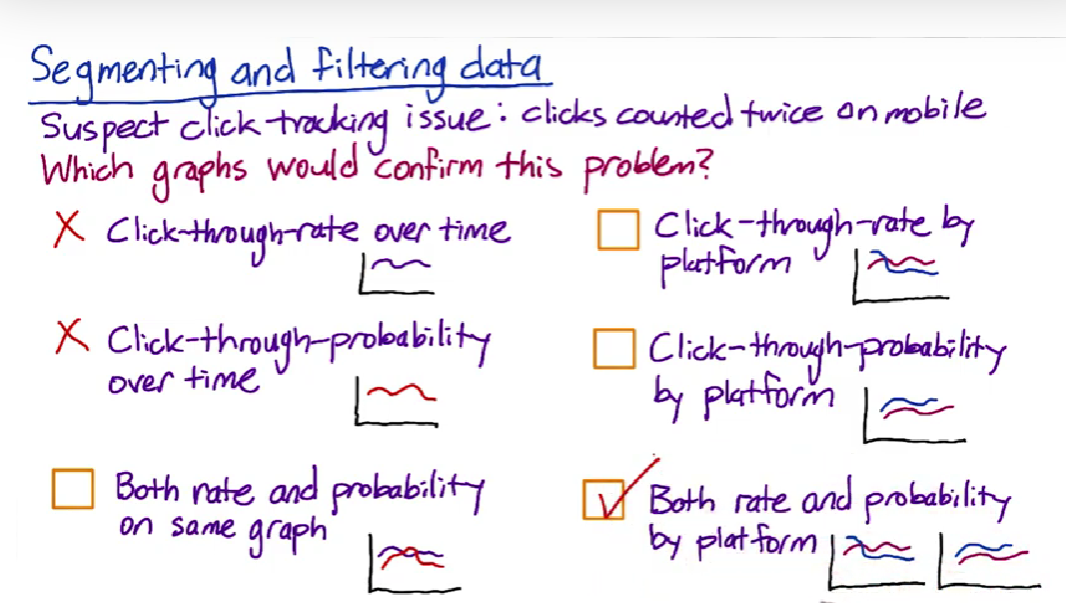
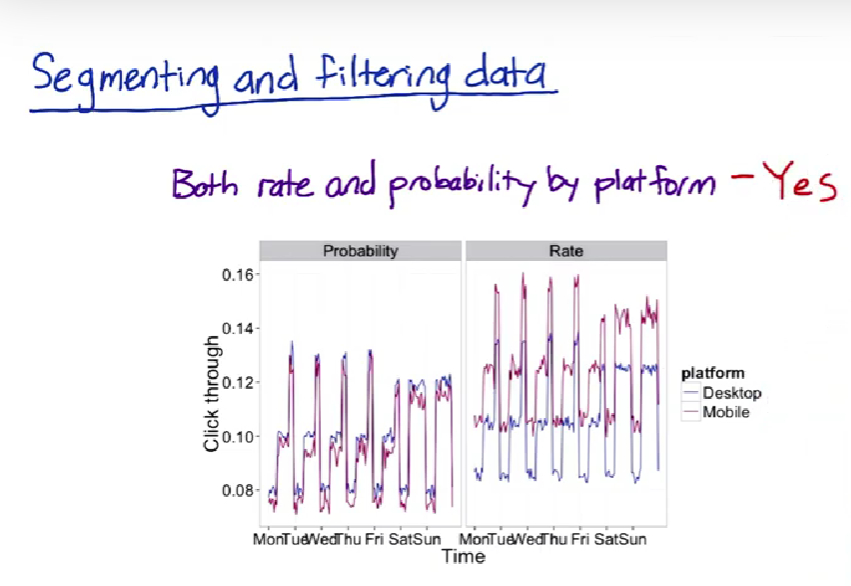
Summary metrics
- eastablish characteristics —> sensitive & robustnesses
- distribution —> retrospective analysis and compute histogram
A retrospective analysis or retrospective study is a research method that is used when the outcome of an event is already known. For example, medical researchers might study the records of patients who suffered from a particular disease to determine what factors may have led to their illness or death.
metrics的4种categories

- Sums and Counts (e.g. how many cookies visit the homepage)
- All distribution metrics(means, medians, percentiles)
- Probabilities and rates(0 or 1, 0 or more)
- Ratios(P(A)/P(B))
在线数据的常见分布
我们来聊聊真实用户数据中的一些常见分布。
例如,我们来衡量一下用户会点击我们搜索页面上某条结果的比率,类似地,我们也可以测量在搜索结果页面之间的平均停留时间。 在这个案例中,你可能会看到我们所称的泊松分布, 或者说停留时间为指数分布。
用户数据的另一个常见分布是“幂律”,Zipfian 或 Pareto 分布。 这基本上是说一个更极端的值 z 的概率跟 1/z(或 1/z^指数)的下降规律一样。 这个分布也出现在其他罕见事件中,如一个文档中某些字的出现频率(最常见的字比列表上旁边的字出现的频率要大得多)。这些类型的重尾分布在互联网数据中比较常见。
最后,你可能会得到不同分布组成的数据——延迟通常具有这个特点,因为较快互联网连接上的用户组成一组,拨号上网或手机上网的用户组成另一组。 即使在手机上,营运商或新手机对比基于文本的旧显示屏之间也有差别。这就形成了我们所称的混合分布,它们很难检测或很好地描述。
这里的关键在于如果答案并不清晰,我们不一定非要找出一种分布来匹配它——这样匹配可能有用——但是选择你能够清楚理解的汇总统计更加适用。 如果你的分布具有非常长的不平衡尾巴,选择均值可能对你来说意义不大,而且在 Pareto 分布等情形下,均值是无限的!
Choosing a summary metric
★sensitive & robustnesses
sensitive:关于感兴趣的指标会随之改变的特征
robustnesses:当其他事件发生时,不会有太大改变
How to measure:
- experiment(相关指标; A/A实验;过往实验)
- retrospective analysis(e.g. 检查网站同期改变是否有影响;指标历史)
示例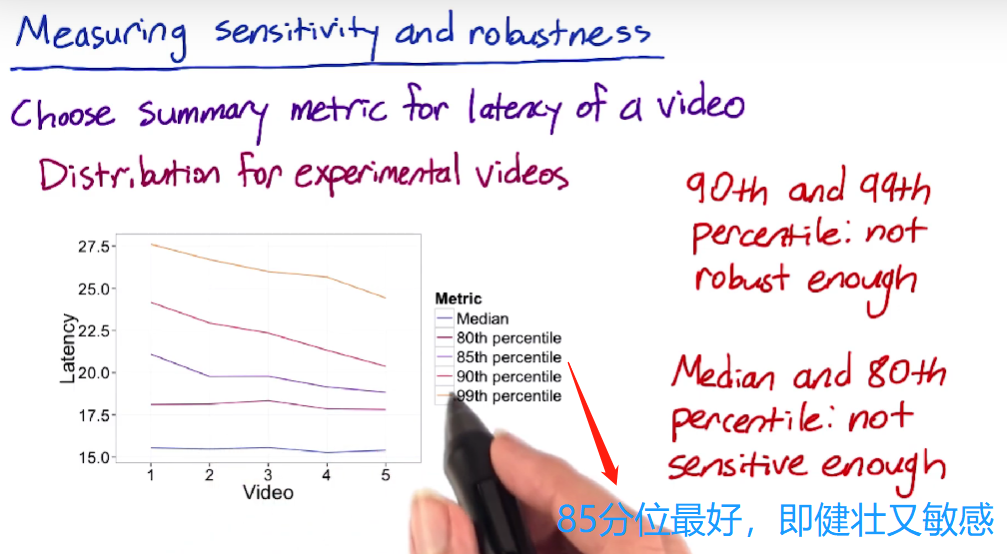
Differences
绝对差(absolute difference)与相对差(relative difference)
假如你要通过一个实验测量你的主页的访问量,对照组测量值为 5000 访问量,实验组为 7000。 那绝对差就是它们相减得到的结果,即 2000。而相对差是绝对差除以控制指标,即为 40%。
概率中的相对差
在概率指标中,人们通常使用百分点来表示绝对差,而用百分比表示相对差。 例如,如果你的控制点进概率为 5%,而你的实验点进概率为 7%,那绝对差就是 2 个百分点,而相对差为 40%。 然而,有时候人们会将绝对差表示为 2% 的变化,那么如果有人给你一个百分比,就很有必要让他们说明这个百分比是指相对差还是绝对差!
对于不太了解的指标,一般用absolute change
Characterize
Calculating variability



泊松变量之间的差别
两个泊松均值之间的差别无法像两个二项概率之间的差别那样用简单的分布来描述。 如果样本量非常大,而你的比率并非无穷小,有时候你可以使用遵循大数法则的正态置信区间。 但通常情况下你需要更为复杂一点的操作。 了解更多选项请单击此处(简单汇总)、 此处第 9.5 节(完整汇总)和 此处(一次免费在线计算)。 如果你可以使用一些统计软件,如 R(免费版本),现在就是利用的好时候,因为多数程序都可以执行你可以使用的这些测试。
如果你对泊松假设没有很大把握,或如果你只想要一些在工程学中更实际、更常见的东西,请参见接下来的“实证可变性” 小节。
测验数据
这是你可以复制并粘贴的测试题数据:[87029, 113407, 84843, 104994, 99327, 92052, 60684]
你也可以下载此文档,用来计算标准偏差。
z-值表
你可以使用此 z-值表。

若有收获,就点个赞吧
0 人点赞
