一.
概述:之前FC层的每个节点代表每个类别的预测概率(softmax后),而FCN用channels来代表了节点,多少节点就有多少层channels,每一层代表一个类别的分割。
输入:整幅图像。
输出:空间尺寸与输入图像相同,通道数等于全部类别个数。(每一层代表一个类别的分割)
真值:**通道数为1(或2)的分割图像。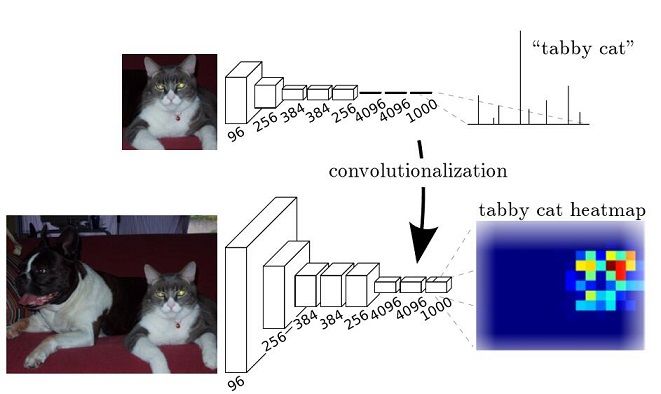
(上图仅提供一个参考,channels不一定准确)
二.
上述网络称为FCN32s,32s 表示转置卷积层前的特征提取网络的整体步长为32,即使用 stride = 2 的下采样 5 次,由于 32 的步长有些大,生成的分割有些不够精确,作者还设计了两个更精细的网络:FCN16s 和 FCN8s。
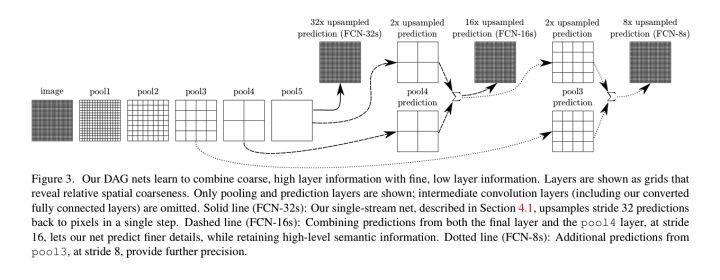
上图的upsample的方式是转置卷积(ConvTranspose,也称‘反卷积,deconv’,但不严谨),和SegNet的不一样,后者采取的是根据位置信息来进行反最大池化来得到上采样的特征图。

若有收获,就点个赞吧
0 人点赞
