现在流行的 CNN,如 AlexNet、VGG、ResNet,虽然识别效果不错,但是模型的参数量和计算量巨大,不适合在移动端、嵌入式设备上运行。所以就出现了更轻量级更快速的的 CNN 设计,这里要讲述的是谷歌的 MobileNet 系列工作。
基础之不同的卷积
这里比较不同卷积的参数量和计算量(bias 项忽略不计),假设他们的输入输出大小是一样的:
输入大小:
输出大小:


- 标准 Conv
卷积核大小为 
,那么



表示参数量, 
表示乘加操作量,即计算量。
- Group Conv
简称 GConv,具体原理详见A Tutorial on Filter Groups (Grouped Convolution)
GConv 卷积核大小为
, 分组为 
,那么


- Depthwise Conv
简称 DWConv,是 Group Conv 的极端,即分组 


MobileNetV1
MobileNetV1 [1]的核心思想就是 Depthwise Separable Conv 来代替标准 Conv,Depthwise Separable Conv 把标准卷积分解为一个 depthwise conv 和一个 
卷积(pointwise conv), 分别起到滤波和线性组合的作用,同时减少参数量和计算量。
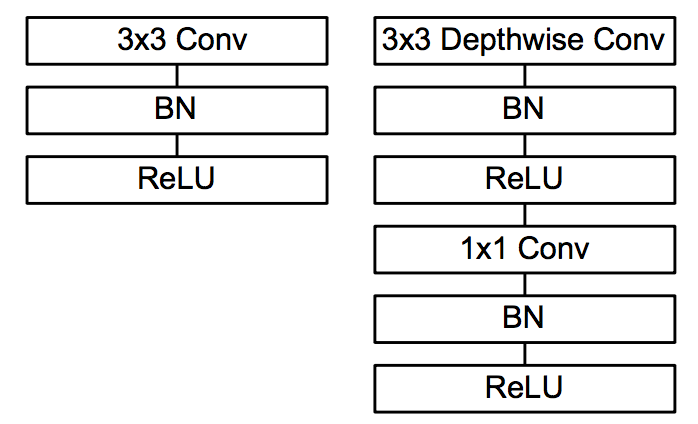
标准 Conv 和 Depthwise Separable Conv
Depthwise Separable Conv 的参数量和计算量:


相比于标准卷积,理论上的加速比例可达

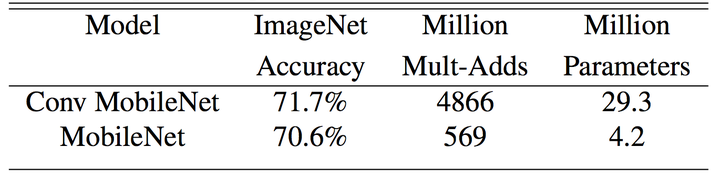
实验结果如下,MobileNet 采用 
的卷积核,所以一般可达 8-9 倍加速,而精度不损失太多。更多有意思的细节和实验请参考原文[1]。
MobileNetV2
MobileNetV1 是类 VGG 的堆叠方式,更先进的方式是加入 ResNet 的 shortcut 连接,所以出现了 V2,核心就是 inverted residual block [2]。
- residual block v.s. inverted residual block
和 Residual block 相比,
- 通道数:两边窄中间宽,所以叫 inverted
- 3*3 卷积改成 Depthwise Conv
- 去掉最后的 ReLU
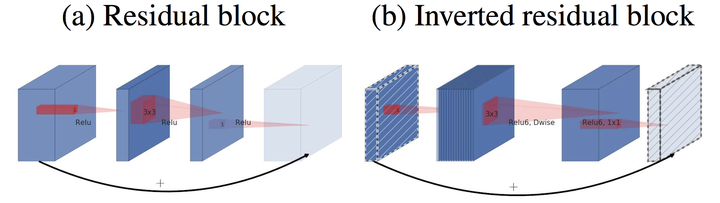
作者这么做的基础是 ReLU 会使得一些神经元失活,而高维的 ReLU 可以保留低维特征的完整信息,同时又不失非线性。所以采用中间宽 + ReLU 的方式来保留低维输入的信息。
- V2 v.s. V1
V2 的参数量和计算量


虽然公式上看 V2 比 V1 计算量大了,其实 V2 可以用更低维的输入来达到同样的效果,所以实际上还是加速了。
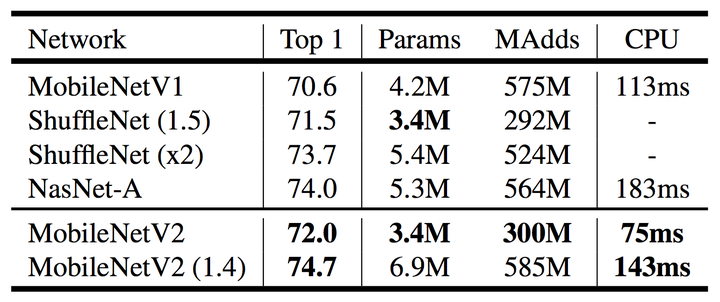
实验结果如下,相比于 MobileNetV1 以及 ShuffleNetV1,MobileNetV2 都具有优势,但说实话,并不明显。
参考文献
[1] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[2] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted Residuals and Linear Bottlenecks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4510-4520.
https://zhuanlan.zhihu.com/p/45209964
https://zhuanlan.zhihu.com/p/45209964

若有收获,就点个赞吧
0 人点赞
