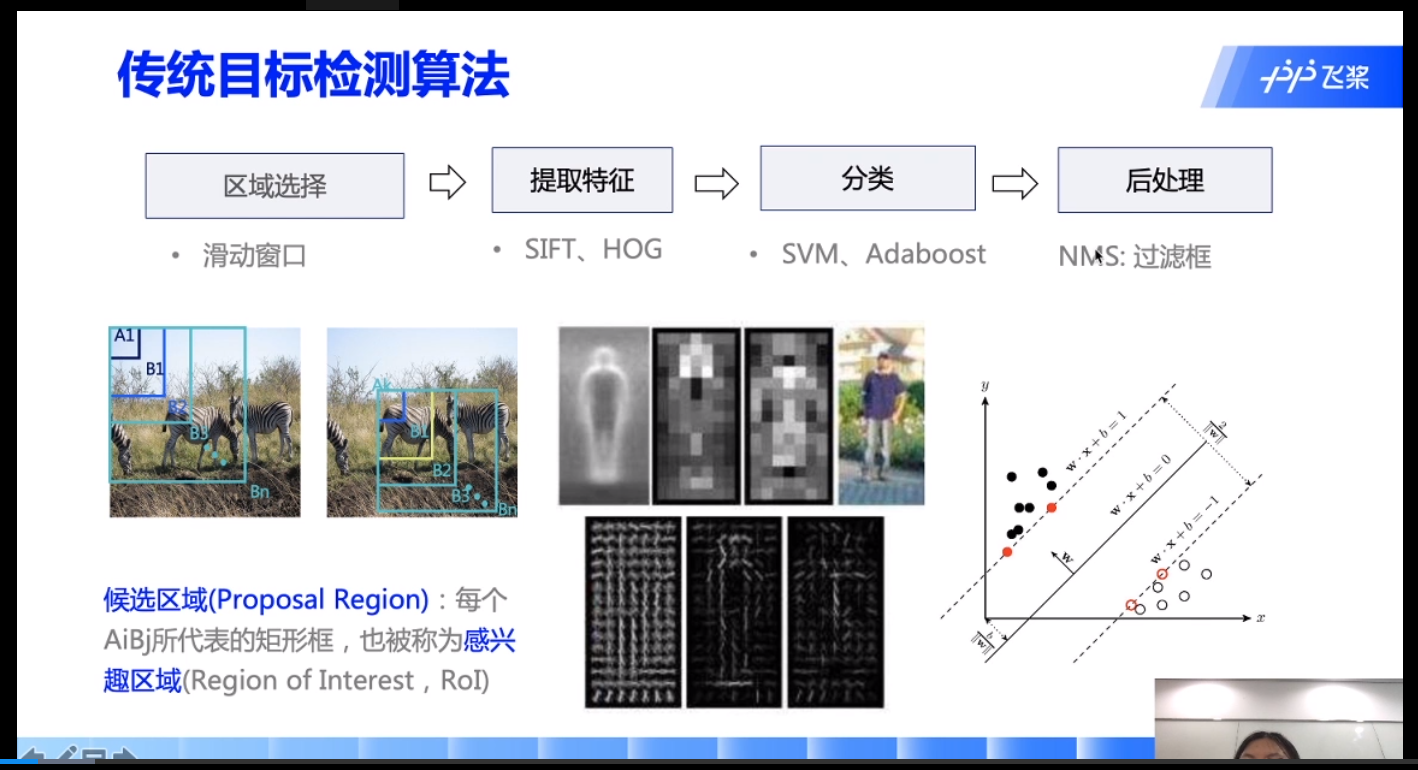
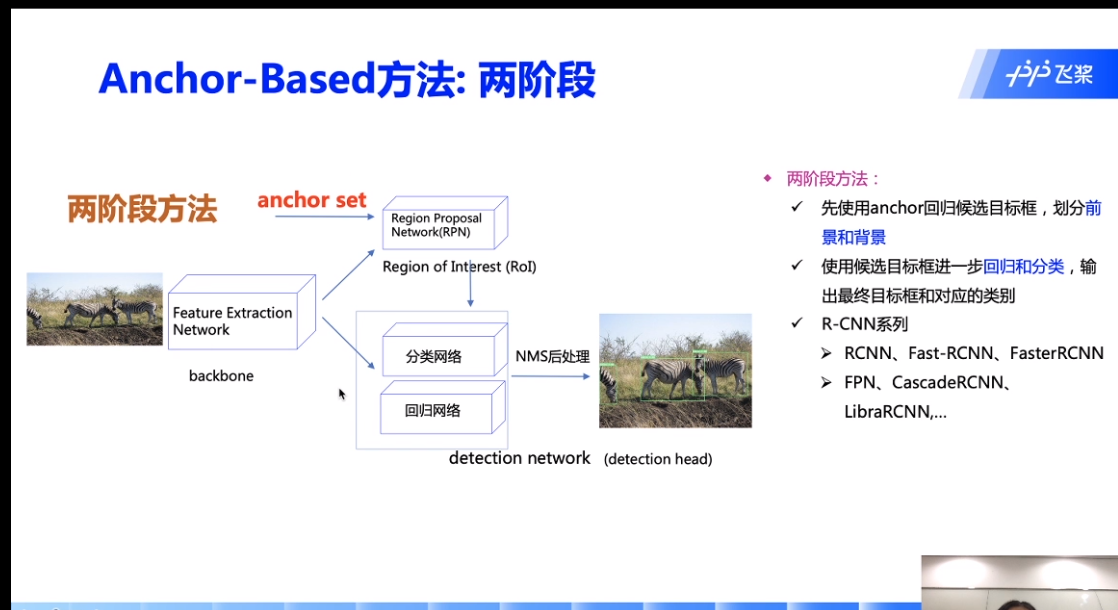
两阶段:实际上还是把目标检测当作分类来做:
缺点:候选框会存在一个重复的提取过程,计算量很大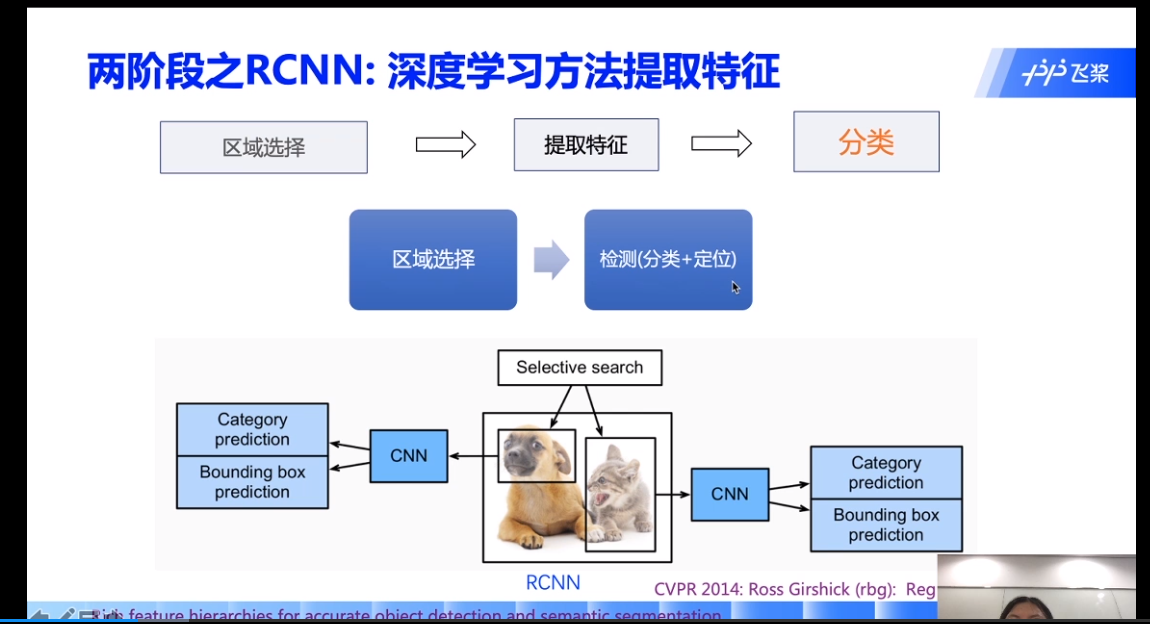
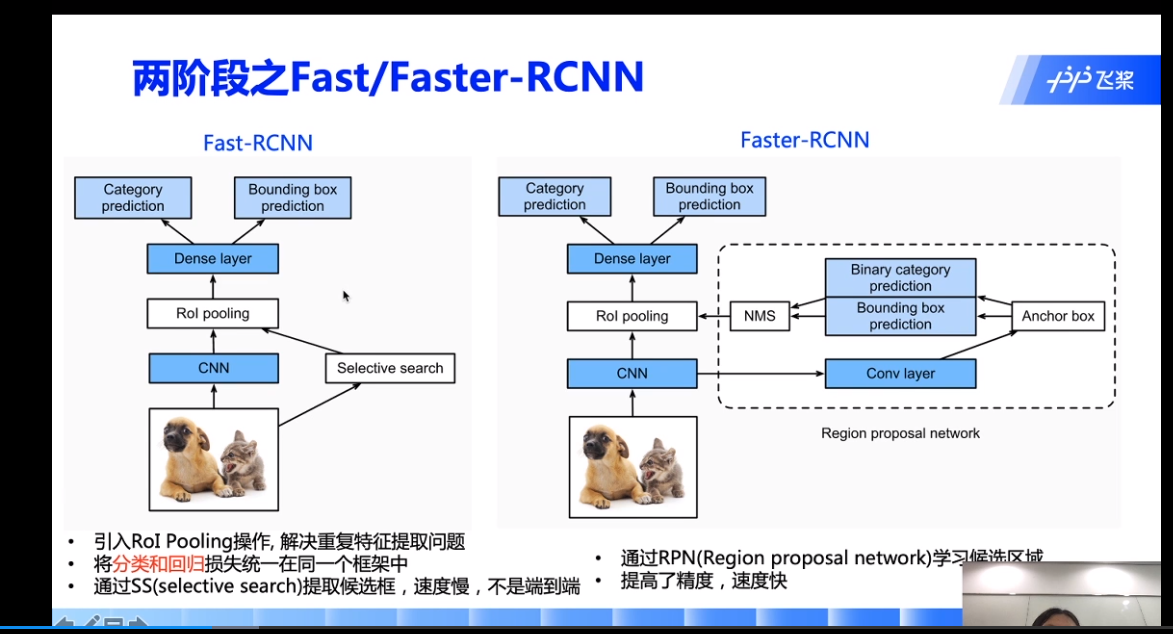
roi pooling:https://blog.csdn.net/u011436429/article/details/80279536
直觉上理解,之前池化的尺寸都为正方形,现在改为矩形,因此可得到固定尺寸的输出特征图。
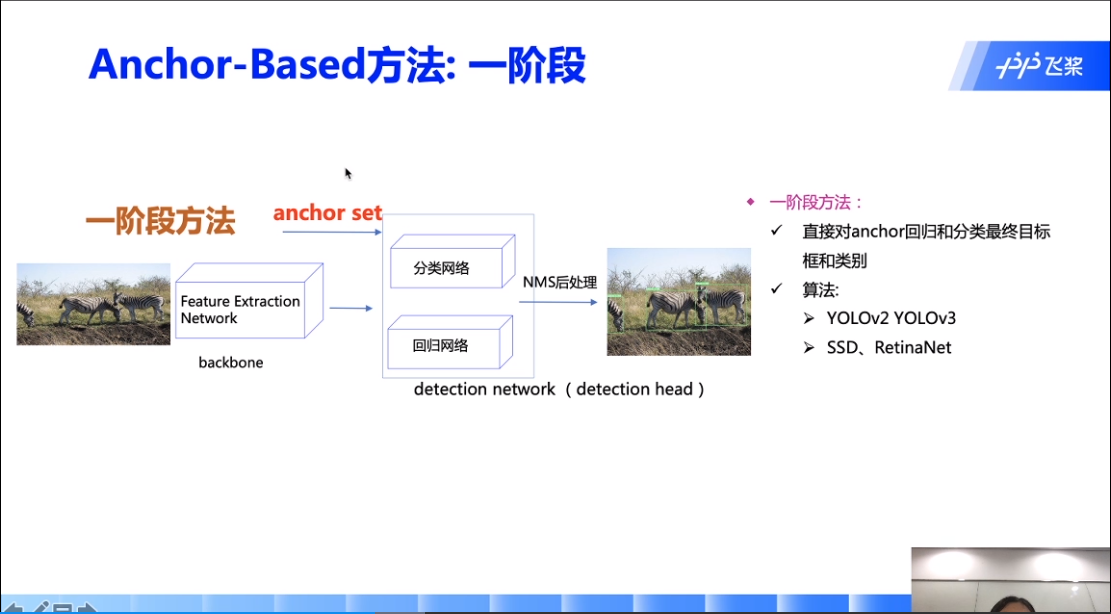
一阶段优点:速度变快
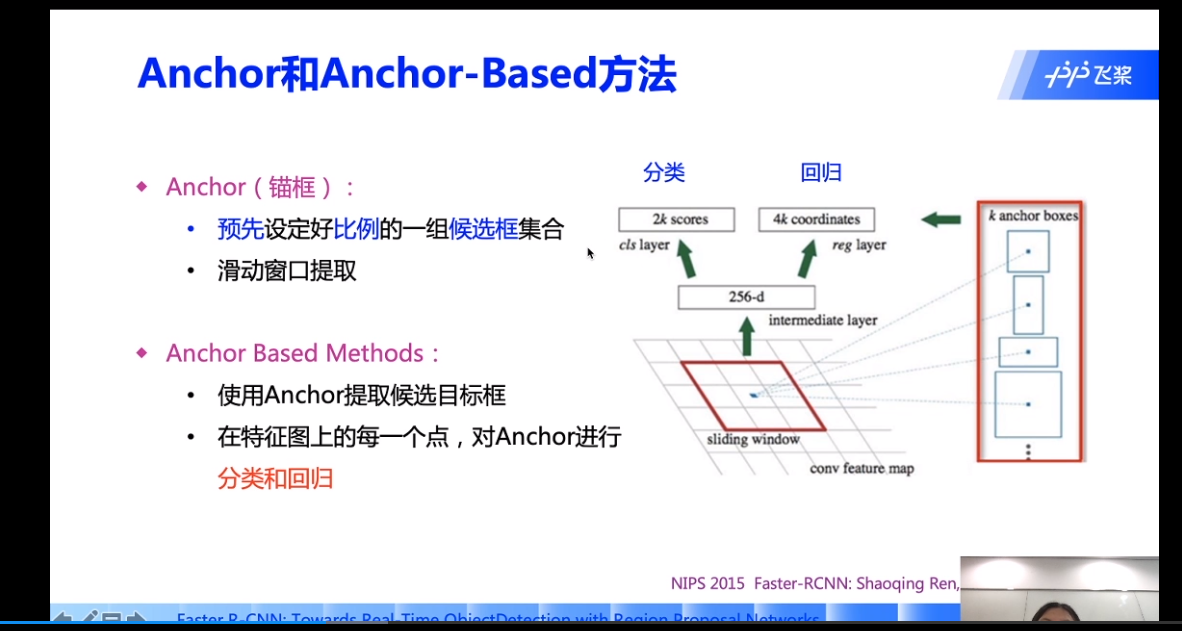
注意没有yolov1,因为yolov1是没有锚狂的


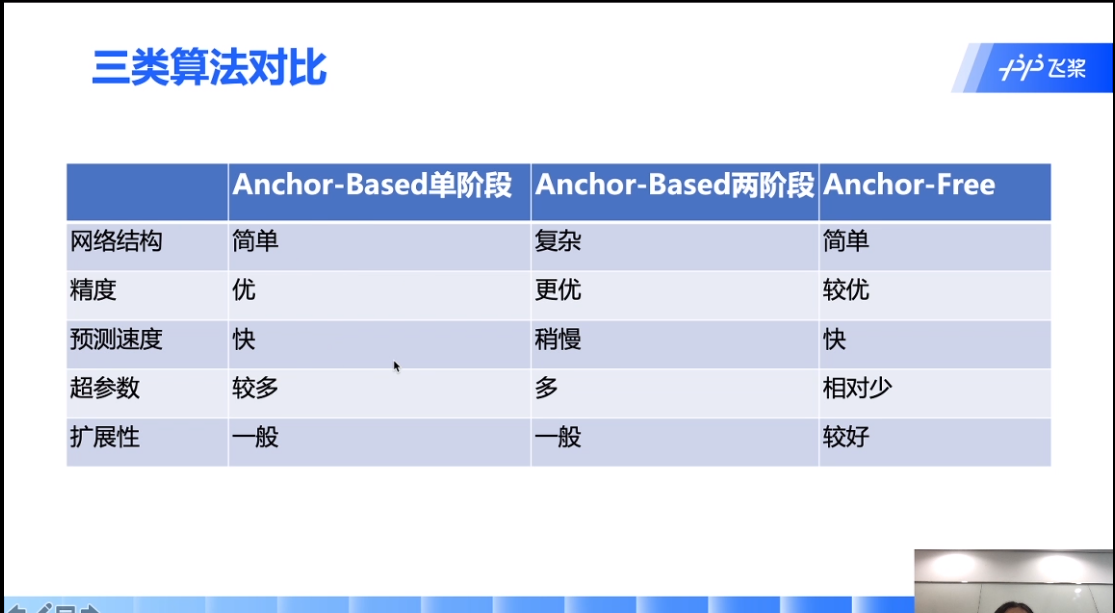

bounding box是个很大的概念,在目标检测里面出现的所有框几乎都可以称为bbox,包括锚框等。

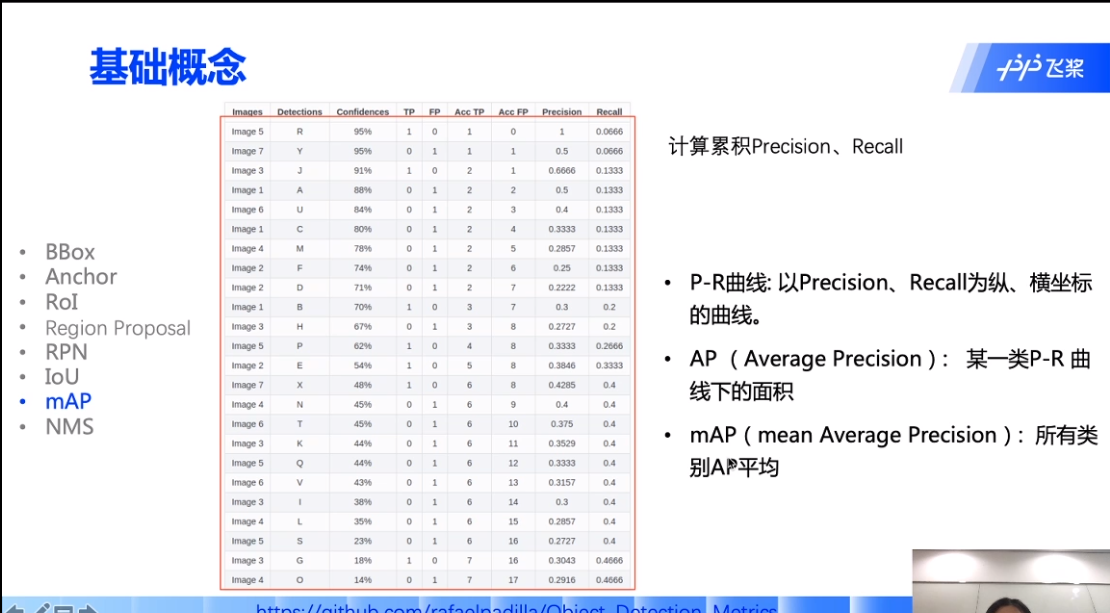
假设预测到100个框,将这100个框按得分从高到低(confidence)排序,以一定阈值(一般都为iou 0.3)来得到累积precision和recall,累积的意思:第一行的precision和recall算的是第一行的框的,得到第一个点,譬如第二行算的是第一行和第二行所有框的p和r,得到第二个点,第三行算的是第一行和第二行和第三行的所有框的p和r,得到第三个点,所以最终得到100个(recall,precision)的点(precision一般为纵坐标y,recall一般为横坐标x),可以绘制P-R曲线,AP即为线下面积。上面讲的都是针对单个类别的,mAP是所有类别做平均。
可以参照https://www.zhihu.com/question/53405779
每次检测都会有很多框,怎么把不要的框去除掉,保留一个框,就是NMS。
思想“去同存异”:去掉相同的,保留不同的。将框按照得分进行排序,让得分第一名的框挨个去往后问,问其他框的意见和它一不一样:如果其他框和它的iou大于设定的阈值,我们就认为意见一样,如果意见一样的,就没必要保留了,所以去除了;反之则保留(因为可能是另外一个目标的检测框)。第一轮结束后可以排除掉第一个目标的多余检测框,此时第二轮是从保留下来的分最高的框开始,开始排除第二个目标的多余框。
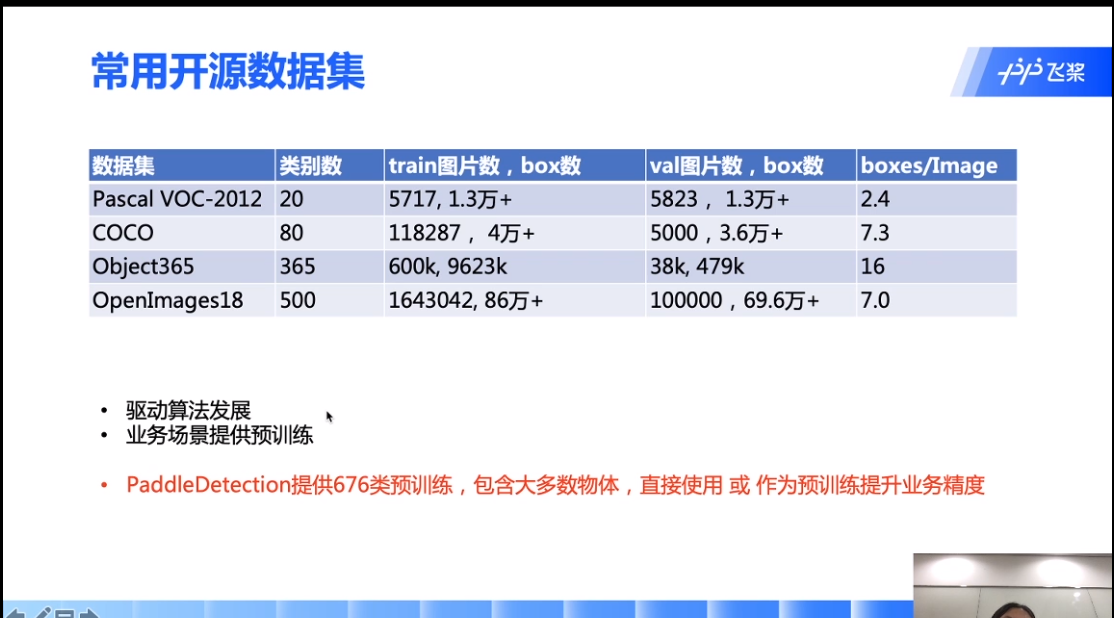
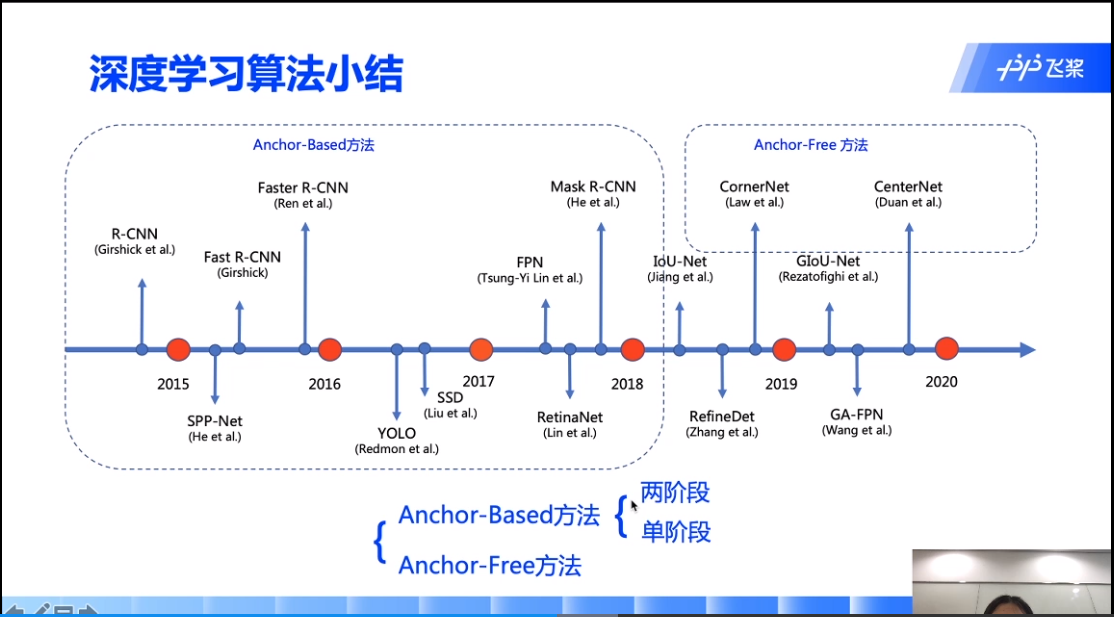
paddledetection集合了object365和openimages18的676类。

若有收获,就点个赞吧
0 人点赞
