Faster RCNN是特别经典的二阶网络;FPN能有效融合高低级特征,更是公认的有利于小目标的检测(分割)。
原始的Faster RCNN中是不带FPN结构的,但torchvision中的Faster RCNN是自带FPN的,因此可以从torchvision中的源码去学习,从而仿造出自己的带fpn的Faster RCNN。
参考:
https://zhuanlan.zhihu.com/p/145842317
首先需要注意的是Faster RCNN目前代表的是一种思想,并非严格按照论文的结构和设计才有作用,而是如果你的网络中有一个网络来提供候选区域(RPN),另外一个网络进一步矫正这个候选区域的话(ROI Net),就可以称之为“Faster RCNN”。因此我们的FPN添加过程也是跟我们的数据集相关的,譬如你的数据集都是小目标,那你的FPN使用了1/64的下采样又有什么意义呢?
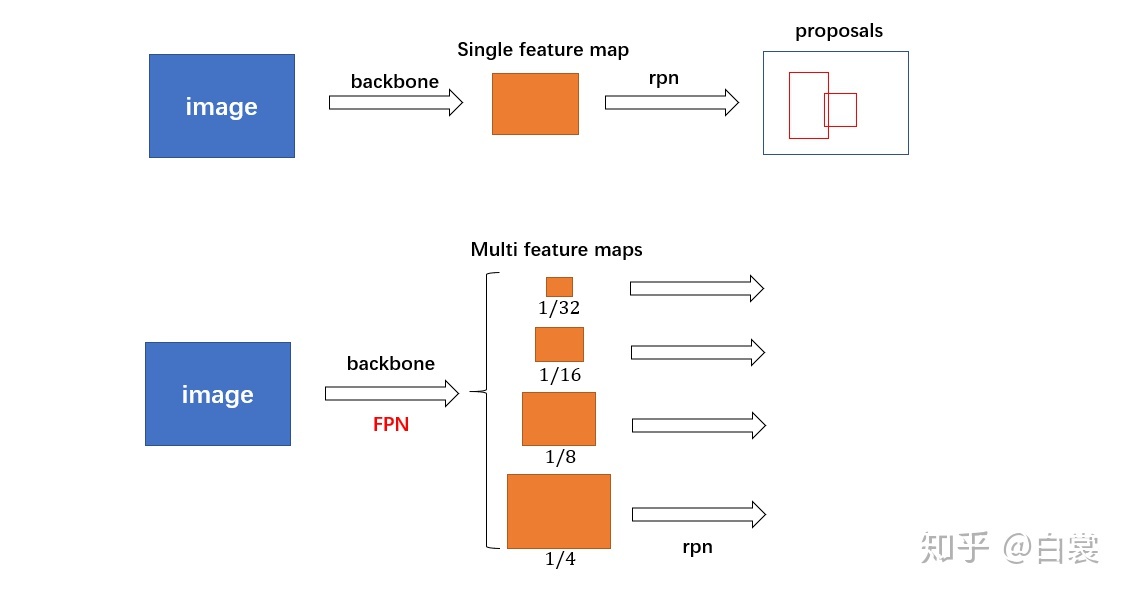
首先看到加不加FPN的区别在于网络(RPN和ROI Net)的输入是单一特征图还是多个层级的特征图,以主干网络为ResNet50为例,原始的Faster RCNN输入的是[1/32 feature map],加了FPN后输入为列表[1/4 feature map,1/8 feature map,1/16 feature map,1/32 feature map],在输入时对该列表进行遍历,即可得到不尺度的输入,当然不同尺度上都会生成anchor。
首先是主干网络ResNet和FPN的结合:
# 这里重点看下return p2,p3,p4 可以看到返回哪些特征图完全是自己决定的,包括你想继续做些文章,譬如在后面接软注意机制,更改可变形卷积,使用更多尺度的特征图,都是完完全全可以更改的。class FPN(nn.Module):def __init__(self, block, layers):super(FPN, self).__init__()self.in_planes = 64self.conv1 = nn.Conv(3, 64, 7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm(64)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=2)# self.layer4 = self._make_layer(block, 512, layers[3], stride=2)self.toplayer = nn.Conv(1024, 256, 1, stride=1, padding=0)self.smooth1 = nn.Conv(256, 256, 3, stride=1, padding=1)self.smooth2 = nn.Conv(256, 256, 3, stride=1, padding=1)self.smooth3 = nn.Conv(256, 256, 3, stride=1, padding=1)# self.latlayer1 = nn.Conv(1024, 256, 1, stride=1, padding=0)self.latlayer2 = nn.Conv(512, 256, 1, stride=1, padding=0)self.latlayer3 = nn.Conv(256, 256, 1, stride=1, padding=0)def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif (stride != 1) or (self.in_planes != (planes * block.expansion)):downsample = nn.Sequential(nn.Conv(self.in_planes, (planes * block.expansion), 1, stride=stride, bias=False), nn.BatchNorm((planes * block.expansion)))layers = []layers.append(block(self.in_planes, planes, stride, downsample))self.in_planes = (planes * block.expansion)for i in range(1, blocks):layers.append(block(self.in_planes, planes))return nn.Sequential(*layers)def _upsample_add(self, x, y):(_, _, H, W) = y.shapereturn nn.interpolate(x, size=(H, W), mode='bilinear', align_corners=True) + ydef execute(self, x):c1 = nn.relu(self.bn1(self.conv1(x)))c1 = nn.max_pool2d(c1, kernel_size=3, stride=2, padding=1)c2 = self.layer1(c1)c3 = self.layer2(c2)c4 = self.layer3(c3)p4 = self.toplayer(c4)# c5 = self.layer4(c4)# p5 = self.toplayer(c5)# p4 = self._upsample_add(p5, self.latlayer1(c4))p3 = self._upsample_add(p4, self.latlayer2(c3))p2 = self._upsample_add(p3, self.latlayer3(c2))p4 = self.smooth1(p4)p3 = self.smooth2(p3)p2 = self.smooth3(p2)return p2, p3, p4def FPN_Resnet50(pretrained=False):model = FPN(Bottleneck, [3, 4, 6, 3])if pretrained: model.load("jittorhub://resnet50.pkl")return model
其次是RPN中FPN的使用:
# todo:fpn in rpn# 不用管return回来的这些参数是什么,我们只需观察到(1)对传进去的特征图列表进行遍历;(2)对返回来的数据进行拼接class Faster_RCNN():......def forward(self,features):rpn_locs_list,rpn_scores_list,rois_list,roi_indices_list,anchor_list = [],[],[],[],[]for i,feature in enumerate(features):rpn_locs, rpn_scores, rois, roi_indices, anchor = self.rpn(feature, img_size)rpn_locs_list.append(rpn_locs),rpn_scores_list.append(rpn_scores),rois_list.append(rois)roi_indices_list.append(roi_indices),anchor_list.append(anchor)rpn_locs = jt.concat(rpn_locs_list,dim=1)rpn_scores = jt.concat(rpn_scores_list,dim=1)rois = jt.concat(rois_list,dim=0)roi_indices = jt.concat(roi_indices_list,dim=0)anchor = jt.concat(anchor_list,dim=0)......# todo:fpn in rpn# 可以看到fpn在RPN的内部影响的仅仅是anchor的scale,也就是不同层级(尺度)的特征图产生的anchor是不一样的。这也是为什么特征图越大(层级越低),对小目标识别效果越好的原因。def rpn(feature,img_size):......x = featuren, _, hh, ww = x.shapefeat_stride = img_size[0] // hhassert feat_stride in [4,8,16,32]scale_feat_dict = {4:32,8:64,16:128,32:256}anchor_scale = [scale_feat_dict[feat_stride]]anchor_base = generate_anchor_base(anchor_scales=anchor_scale, ratios=self.ratios)anchor = _enumerate_shifted_anchor(anchor_base, feat_stride, hh, ww)anchor = jt.array(anchor)......

若有收获,就点个赞吧
0 人点赞
