YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
现在 YOLO 已经发展到 v3 版本,不过新版本也是在原有版本基础上不断改进演化的,所以本文先分析 YOLO v1 版本。
关于 YOLOv2/YOLO9000 和 YOLOv3 的分析理解请移步 YOLO v2 / YOLO 9000 和 YOLO v3 深入理解。
对象识别和定位
输入一张图片,要求输出其中所包含的对象,以及每个对象的位置(包含该对象的矩形框)。
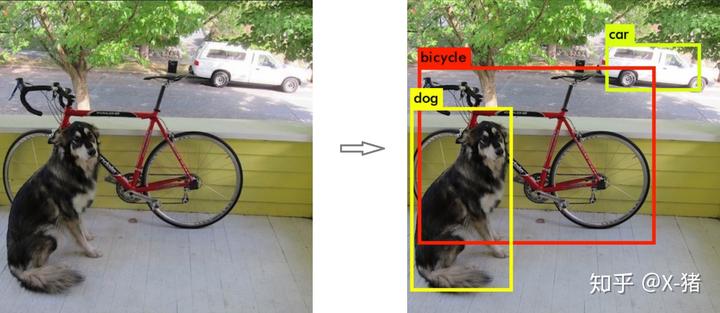
图 1 对象识别和定位
对象识别和定位,可以看成两个任务:找到图片中某个存在对象的区域,然后识别出该区域中具体是哪个对象。
对象识别这件事(一张图片仅包含一个对象,且基本占据图片的整个范围),最近几年基于 CNN 卷积神经网络的各种方法已经能达到不错的效果了。所以主要需要解决的问题是,对象在哪里。
最简单的想法,就是遍历图片中所有可能的位置,地毯式搜索不同大小,不同宽高比,不同位置的每个区域,逐一检测其中是否存在某个对象,挑选其中概率最大的结果作为输出。显然这种方法效率太低。
RCNN/Fast RCNN/Faster RCNN
RCNN 开创性的提出了候选区 (Region Proposals) 的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概 2000 个左右,然后对每个候选区进行对象识别。大幅提升了对象识别和定位的效率。
不过 RCNN 的速度依然很慢,其处理一张图片大概需要 49 秒。因此又有了后续的 Fast RCNN 和 Faster RCNN,针对 RCNN 的神经网络结构和候选区的算法不断改进,Faster RCNN 已经可以达到一张图片约 0.2 秒的处理速度。下图来自 R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
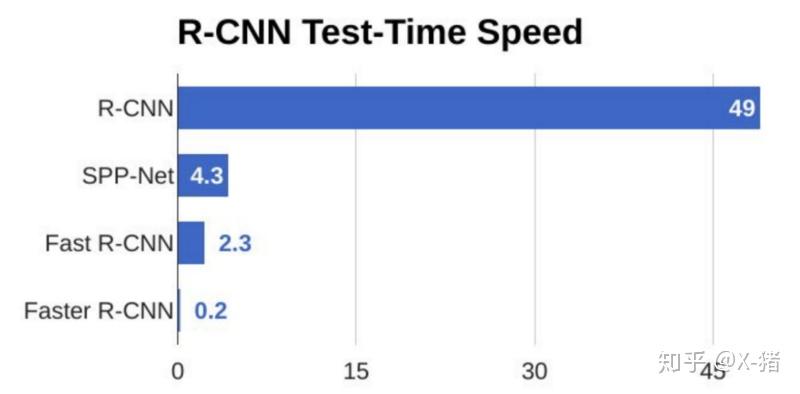
图 2 RCNN 系列处理速度
但总体来说,RCNN 系列依然是两阶段处理模式:先提出候选区,再识别候选区中的对象。
YOLO
YOLO 意思是 You Only Look Once,创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片(不用看两眼哦)就能知道有哪些对象以及它们的位置。
实际上,YOLO 并没有真正去掉候选区,而是采用了预定义的候选区(准确点说应该是预测区,因为并不是 Faster RCNN 所采用的 Anchor)。也就是将图片划分为 77=49 个网格(grid),每个网格允许预测出 2 个边框(bounding box,包含某个对象的矩形框),总共 492=98 个 bounding box。可以理解为 98 个候选区,它们很粗略的覆盖了图片的整个区域。
RCNN:我们先来研究一下图片,嗯,这些位置很可能存在一些对象,你们对这些位置再检测一下看到底是哪些对象在里面。YOLO:我们把图片大致分成98个区域,每个区域看下有没有对象存在,以及具体位置在哪里。RCNN:你这么简单粗暴真的没问题吗?YOLO:当然没有......咳,其实是有一点点问题的,准确率要低一点,但是我非常快!快!快!RCNN:为什么你用那么粗略的候选区,最后也能得到还不错的bounding box呢?YOLO:你不是用过边框回归吗?我拿来用用怎么不行了。
RCNN 虽然会找到一些候选区,但毕竟只是候选,等真正识别出其中的对象以后,还要对候选区进行微调,使之更接近真实的 bounding box。这个过程就是边框回归:将候选区 bounding box 调整到更接近真实的 bounding box。
既然反正最后都是要调整的,干嘛还要先费劲去寻找候选区呢,大致有个区域范围就行了,所以 YOLO 就这么干了。
不过话说回来,边框回归为啥能起作用,我觉得本质上是因为 分类信息 中已经包含了 位置信息。就像你看到主子的脸和身体,就能推测出耳朵和屁股的位置。

图 3 边框调整
[

下面具体看下 YOLO 的实现方案。
1)结构
去掉候选区这个步骤以后,YOLO 的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的 CNN 对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测 bounding box 的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO 的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示。
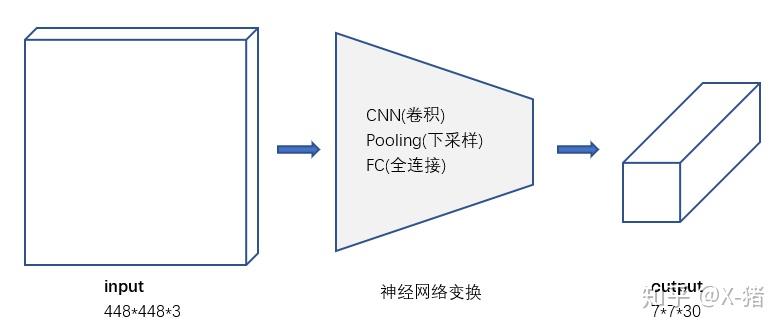
图 4 输入 - 输出
因为只是一些常规的神经网络结构,所以,理解 YOLO 的设计的时候,重要的是理解输入和输出的映射关系.
2)输入和输出的映射关系
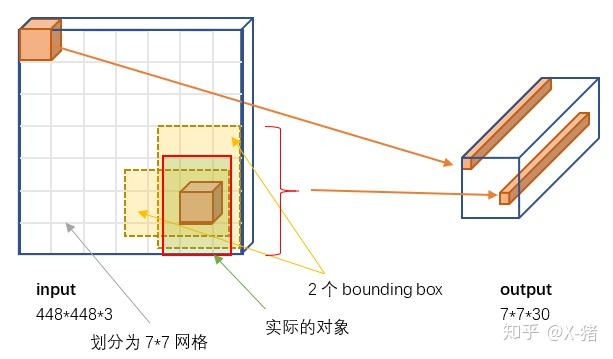
图 5 输入 - 输出
3)输入
参考图 5,输入就是原始图像,唯一的要求是缩放到 448448 的大小。主要是因为 YOLO 的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以倒推回去也就要求原始图像有固定的尺寸。那么 YOLO 设计的尺寸就是 448448。
4)输出
输出是一个 7730 的张量(tensor)。
4.1)7*7 网格
根据 YOLO 的设计,输入图像被划分为 77 的网格(grid),输出张量中的 77 就对应着输入图像的 77 网格。或者我们把 7730 的张量看作 77=49 个 30 维的向量,也就是输入图像中的每个网格对应输出一个 30 维的向量。参考上面图 5,比如输入图像左上角的网格对应到输出张量中左上角的向量。
要注意的是,并不是说仅仅网格内的信息被映射到一个 30 维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个 30 维向量中。
4.2)30 维向量
具体来看每个网格对应的 30 维向量中包含了哪些信息。
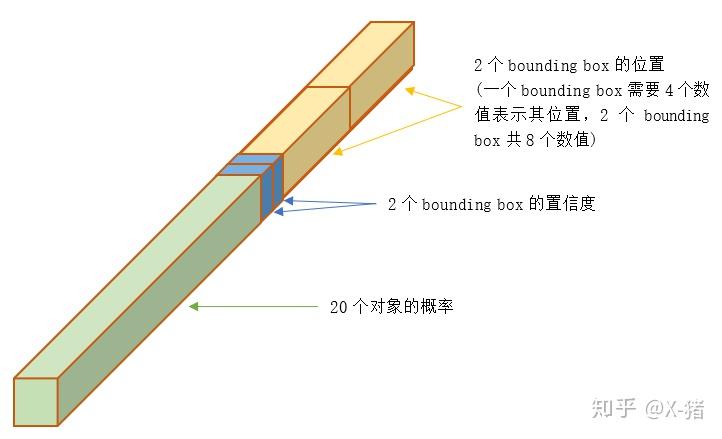
图 6 30 维输出向量
① 20 个对象分类的概率
因为 YOLO 支持识别 20 种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有 20 个值表示该网格位置存在任一种对象的概率。可以记为 
,之所以写成条件概率,意思是如果该网格存在一个对象 Object,那么它是 
的概率是 
。(记不清条件概率的同学可以参考一下 理解贝叶斯定理)
② 2 个 bounding box 的位置
每个 bounding box 需要 4 个数值来表示其位置,(Center_x,Center_y,width,height),即 (bounding box 的中心点的 x 坐标,y 坐标,bounding box 的宽度,高度),2 个 bounding box 共需要 8 个数值来表示其位置。
③ 2 个 bounding box 的置信度
bounding box 的置信度 = 该 bounding box 内存在对象的概率 * 该 bounding box 与该对象实际 bounding box 的 IOU
用公式来表示就是 

是 bounding box 内存在对象的概率,区别于上面第①点的
。Pr(Object) 并不管是哪个对象,它体现的是 有或没有 对象的概率。第①点中的
意思是假设已经有一个对象在网格中了,这个对象具体是哪一个。

是 bounding box 与 对象真实 bounding box 的 IOU(Intersection over Union,交并比)。要注意的是,现在讨论的 30 维向量中的 bounding box 是 YOLO 网络的输出,也就是预测的 bounding box。所以
体现了预测的 bounding box 与真实 bounding box 的接近程度。
还要说明的是,虽然有时说 “预测” 的 bounding box,但这个 IOU 是在训练阶段计算的。等到了测试阶段(Inference),这时并不知道真实对象在哪里,只能完全依赖于网络的输出,这时已经不需要(也无法)计算 IOU 了。
综合来说,一个 bounding box 的置信度 Confidence 意味着它 是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象 或者 即便有对象也存在较大的位置偏差。
简单解释一下 IOU。下图来自 Andrew Ng 的深度学习课程,IOU = 交集部分面积 / 并集部分面积,2 个 box 完全重合时 IOU=1,不相交时 IOU=0。

图 7 IOU
总的来说,30 维向量 = 20 个对象的概率 + 2 个 bounding box * 4 个坐标 + 2 个 bounding box 的置信度
4.3)讨论
① 一张图片最多可以检测出 49 个对象
每个 30 维向量中只有一组(20 个)对象分类的概率,也就只能预测出一个对象。所以输出的 7*7=49 个 30 维向量,最多表示出 49 个对象。
② 总共有 49*2=98 个候选区(bounding box)
每个 30 维向量中有 2 组 bounding box,所以总共是 98 个候选区。
③ YOLO 的 bounding box 并不是 Faster RCNN 的 Anchor
Faster RCNN 等一些算法采用每个 grid 中手工设置 n 个 Anchor(先验框,预先设置好位置的 bounding box)的设计,每个 Anchor 有不同的大小和宽高比。YOLO 的 bounding box 看起来很像一个 grid 中 2 个 Anchor,但它们不是。YOLO 并没有预先设置 2 个 bounding box 的大小和形状,也没有对每个 bounding box 分别输出一个对象的预测。它的意思仅仅是对一个对象预测出 2 个 bounding box,选择预测得相对比较准的那个。
这里采用 2 个 bounding box,有点不完全算监督算法,而是像进化算法。如果是监督算法,我们需要事先根据样本就能给出一个正确的 bounding box 作为回归的目标。但 YOLO 的 2 个 bounding box 事先并不知道会在什么位置,只有经过前向计算,网络会输出 2 个 bounding box,这两个 bounding box 与样本中对象实际的 bounding box 计算 IOU。这时才能确定,IOU 值大的那个 bounding box,作为负责预测该对象的 bounding box。
训练开始阶段,网络预测的 bounding box 可能都是乱来的,但总是选择 IOU 相对好一些的那个,随着训练的进行,每个 bounding box 会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)。所以,这是一种进化或者非监督学习的思想。
另外论文中经常提到responsible。比如:Our system divides the input image into an S*S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. 这个 responsible 有点让人疑惑,对预测 “负责” 是啥意思。其实没啥特别意思,就是一个 Object 只由一个 grid 来进行预测,不要多个 grid 都抢着预测同一个 Object。更具体一点说,就是在设置训练样本的时候,样本中的每个 Object 归属到且仅归属到一个 grid,即便有时 Object 跨越了几个 grid,也仅指定其中一个。具体就是计算出该 Object 的 bounding box 的中心位置,这个中心位置落在哪个 grid,该 grid 对应的输出向量中该对象的类别概率是 1(该 gird 负责预测该对象),所有其它 grid 对该 Object 的预测概率设为 0(不负责预测该对象)。
还有:YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. 同样,虽然一个 grid 中会产生 2 个 bounding box,但我们会选择其中一个作为预测结果,另一个会被忽略。下面构造训练样本的部分会看的更清楚。
④ 可以调整网格数量、bounding box 数量
77 网格,每个网格 2 个 bounding box,对 448448 输入图像来说覆盖粒度有点粗。我们也可以设置更多的网格以及更多的 bounding box。设网格数量为 S*S,每个网格产生 B 个边框,网络支持识别 C 个不同的对象。这时,输出的向量长度为: 
整个输出的 tensor 就是: 
YOLO 选择的参数是 77 网格,2 个 bounding box,20 种对象,因此 输出向量长度 = 20 + 2 (4+1) = 30。整个输出的 tensor 就是 7730。
因为网格和 bounding box 设置的比较稀疏,所以这个版本的 YOLO 训练出来后预测的准确率和召回率都不是很理想,后续的 v2、v3 版本还会改进。当然,因为其速度能够满足实时处理的要求,所以对工业界还是挺有吸引力的。
5)训练样本构造
作为监督学习,我们需要先构造好训练样本,才能让模型从中学习。

图 8 输入样本图片
对于一张输入图片,其对应输出的 7730 张量(也就是通常监督学习所说的标签 y 或者 label)应该填写什么数据呢。
首先,输出的 77 维度 对应于输入的 77 网格。 然后具体看下 30 维向量的填写(请对照上面图 6)。
① 20 个对象分类的概率
对于输入图像中的每个对象,先找到其中心点。比如图 8 中的自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的 30 维向量中,自行车的概率是 1,其它对象的概率是 0。所有其它 48 个网格的 30 维向量中,该自行车的概率都是 0。这就是所谓的 “中心点所在的网格对预测该对象负责”。狗和汽车的分类概率也是同样的方法填写。
② 2 个 bounding box 的位置
训练样本的 bounding box 位置应该填写对象实际的 bounding box,但一个对象对应了 2 个 bounding box,该填哪一个呢?上面讨论过,需要根据网络输出的 bounding box 与对象实际 bounding box 的 IOU 来选择,所以要在训练过程中动态决定到底填哪一个 bounding box。参考下面第③点。
③ 2 个 bounding box 的置信度
上面讨论过置信度公式
可以直接计算出来,就是用网络输出的 2 个 bounding box 与对象真实 bounding box 一起计算出 IOU。
然后看 2 个 bounding box 的 IOU,哪个比较大(更接近对象实际的 bounding box),就由哪个 bounding box 来负责预测该对象是否存在,即该 bounding box 的 
,同时对象真实 bounding box 的位置也就填入该 bounding box。另一个不负责预测的 bounding box 的 
。
总的来说就是,与对象实际 bounding box 最接近的那个 bounding box,其 
,该网格的其它 bounding box 的 
。
举个例子,比如上图中自行车的中心点位于 4 行 3 列网格中,所以输出 tensor 中 4 行 3 列位置的 30 维向量如下图所示。
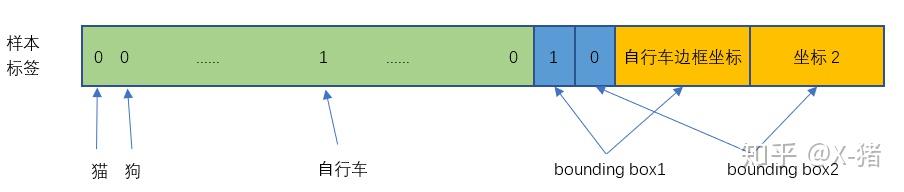
图 9 训练样本的一个 30 维向量
翻译成人话就是:4 行 3 列网格位置有一辆自行车,它的中心点在这个网格内,它的位置边框是 bounding box1 所填写的自行车实际边框。
注意,图中将自行车的位置放在 bounding box1,但实际上是在训练过程中等网络输出以后,比较两个 bounding box 与自行车实际位置的 IOU,自行车的位置(实际 bounding box)放置在 IOU 比较大的那个 bounding box(图中假设是 bounding box1),且该 bounding box 的置信度设为 1。
6)损失函数
损失就是网络实际输出值与样本标签值之间的偏差。
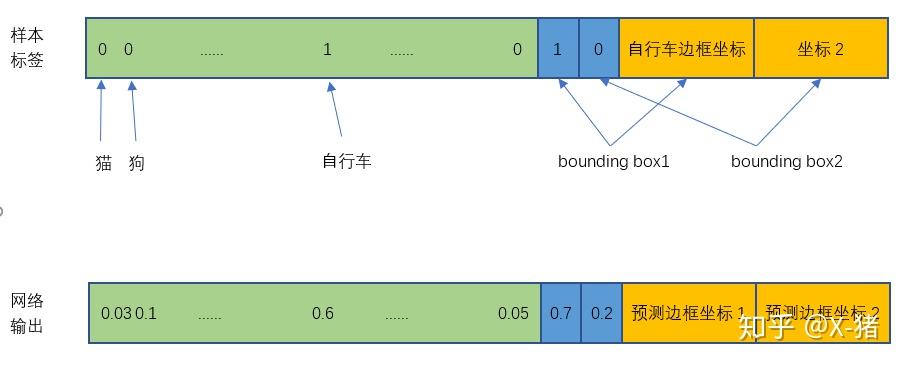
图 10 样本标签与网络实际输出
YOLO 给出的损失函数如下
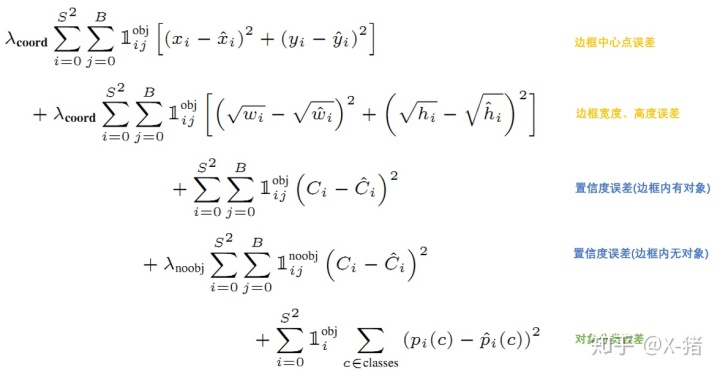
图 11 损失函数
公式中

意思是网格 i 中存在对象。

意思是网格 i 的第 j 个 bounding box 中存在对象。

意思是网格 i 的第 j 个 bounding box 中不存在对象。
总的来说,就是用网络输出与样本标签的各项内容的误差平方和作为一个样本的整体误差。 损失函数中的几个项是与输出的 30 维向量中的内容相对应的。
① 对象分类的误差
公式第 5 行,注意
意味着存在对象的网格才计入误差。
② bounding box 的位置误差
公式第 1 行和第 2 行。
a)都带有
意味着只有 “负责”(IOU 比较大)预测的那个 bounding box 的数据才会计入误差。
b)第 2 行宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重。
c)乘以 
调节 bounding box 位置误差的权重(相对分类误差和置信度误差)。YOLO 设置 
,即调高位置误差的权重。
③ bounding box 的置信度误差
公式第 3 行和第 4 行。
a)第 3 行是存在对象的 bounding box 的置信度误差。带有
意味着只有 “负责”(IOU 比较大)预测的那个 bounding box 的置信度才会计入误差。
b)第 4 行是不存在对象的 bounding box 的置信度误差。因为不存在对象的 bounding box 应该老老实实的说 “我这里没有对象”,也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正 “负责” 该对象预测的那个 bounding box 产生混淆。其实就像对象分类一样,正确的对象概率最好是 1,所有其它对象的概率最好是 0。
c)第 4 行会乘以 
调节不存在对象的 bounding box 的置信度的权重(相对其它误差)。YOLO 设置 
,即调低不存在对象的 bounding box 的置信度误差的权重。
7)训练
YOLO 先使用 ImageNet 数据集对前 20 层卷积网络进行预训练,然后使用完整的网络,在 PASCAL VOC 数据集上进行对象识别和定位的训练和预测。YOLO 的网络结构如下图所示:
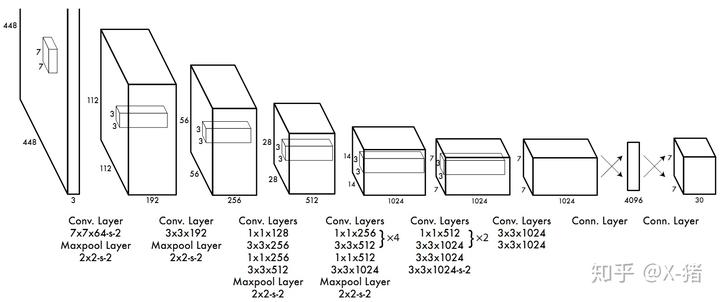
YOLO 的最后一层采用线性激活函数,其它层都是 Leaky ReLU。训练中采用了 drop out 和数据增强(data augmentation)来防止过拟合。更多细节请参考原论文。
8)预测(inference)
训练好的 YOLO 网络,输入一张图片,将输出一个 7730 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的 2 个位置(bounding box)和可信程度(置信度)。 为了从中提取出最有可能的那些对象和位置,YOLO 采用 NMS(Non-maximal suppression,非极大值抑制)算法。
9)NMS(非极大值抑制)
NMS 方法并不复杂,其核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
YOLO 的 NMS 计算方法如下。
网络输出的 7730 的张量,在每一个网格中,对象
位于第 j 个 bounding box 的得分: 
它代表着某个对象
存在于第 j 个 bounding box 的可能性。
每个网格有:20 个对象的概率 * 2 个 bounding box 的置信度,共 40 个得分(候选对象)。49 个网格共 1960 个得分。Andrew Ng 建议每种对象分别进行 NMS,那么每种对象有 1960/20=98 个得分。
NMS 步骤如下:
1)设置一个 Score 的阈值,低于该阈值的候选对象排除掉(将该 Score 设为 0)
2)遍历每一个对象类别
2.1)遍历该对象的 98 个得分
2.1.1)找到 Score 最大的那个对象及其 bounding box,添加到输出列表
2.1.2)对每个 Score 不为 0 的候选对象,计算其与上面 2.1.1 输出对象的 bounding box 的 IOU
2.1.3)根据预先设置的 IOU 阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将 Score 设为 0)
2.1.4)如果所有 bounding box 要么在输出列表中,要么 Score=0,则该对象类别的 NMS 完成,返回步骤 2 处理下一种对象
3)输出列表即为预测的对象
10)小结
YOLO 以速度见长,处理速度可以达到 45fps,其快速版本(网络较小)甚至可以达到 155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。
不足之处是小对象检测效果不太好(尤其是一些聚集在一起的小对象),对边框的预测准确度不是很高,总体预测精度略低于 Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外 Pooling 层会丢失一些细节信息,对定位存在影响。 更多细节请参考原论文。
最后,如果你竟然坚持看到这里,觉得还有所帮助的话,请点个赞:)๑ ๑
参考
You Only Look Once: Unified, Real-Time Object Detection

若有收获,就点个赞吧
0 人点赞
