原文链接:https://blog.csdn.net/yapifeitu/article/details/105749693
看了下 yolov4 的作者给的操作说明,链接如下:https://github.com/AlexeyAB/darknet#how-to-compile-on-linux-using-make,有兴趣的可以去看看,总结起来,跟 yolov3 的操作方式基本一样,所以现在记录一下这次的整个操作流程。
在几个月前,一直在准备一个项目,那个项目已经让人用 lableme 这个标注软件标注好了图片,但是直到现在,这个项目依旧还没有动工的苗头,估计是悬了,之前也用标注好的数据进行过 yolov3 的训练,但是说实话,那时候对于 yolov3 是一头雾水,只知道按照他人的给的操作流程去做,但是为什么这样做,我是不清楚的,这也导致我自己都不知道当初的训练模型的流程是否正确,现在好了,前段时间把 yolov3,ssd 学习了,现在来操作,就知道这样操作的原理了,整个操作流程就知道的很详细了,也知道怎么训练自己的数据了,不再茫然。
环境说明:yolo 系列一直都有 linux 版本和 windows 版本,我看了哈,很明显 linux 版本更加简单,windows 版本还需要搭配 vs 来操作,光 vs 这个软件就十几个 g, 太大了,所以我就采取在 ubuntu 上训练数据了。
首先,要感谢下面的这篇文章的作者:https://www.cnblogs.com/Assist/p/11091501.html,这篇文章为我梳理了整个思路,这也为我想处理自己的数据,训练自己的模型有了想法。
一般来说,训练 coco, vol 这些数据集,网上很多教程来进行数据的预处理,但是训练自己的数据,就得自己根据网上的教程来改代码了,因为 coco 这些数据集的标注文件和图片存储结果可能跟自己的数据都不一样,对于我用 labelme 来标注的图像来说,每一张图片会对应一个 json 文件,这个 json 文件里面拥有这标注的类别坐标这些信息,所以,我这里值将所有图片放到一个文件夹,所有 json 文件放到一个文件夹,但是为了区分训练数据和 val 数据,我将 json 进行了划分,一部分放到了 train 文件夹,一部分放到了 val 文件夹,最后整个文件的结构如下:
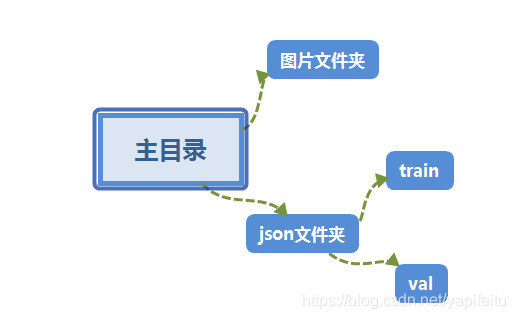
接下来咱就可以开始正式的数据预处理了,这一块是最麻烦的,我个人觉得哈。我们运行第一个 Py 文件后,要创建出下面这几个文件夹:

第一个文件夹用来装 xml 文件,这个 xml 文件里面有标签类别,图片的宽高,标签的左上角和右下角坐标这些信息,每一张照片对应一个 xml 文件,imagesets 这个文件夹里面还有一个文件夹:/Main, 在这个 Main 文件夹下面会产生 train.txt 和 val.txt,这些文件里面的信息只是图片的名字,不带. jpg 这些后缀的名字,而在 JPEGImages 里面就是所有图片了。
我们假设这第一个 py 文件叫 convertvoc.py,我下面提供我的代码,大家不能照搬,有些地方要改。
'''author:nike hu'''import shutilimport osimport jsonimport cv2headstr = """\<annotation><folder>VOC2007</folder><filename>%06d.jpg</filename><source><database>My Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image><flickrid>NULL</flickrid></source><owner><flickrid>NULL</flickrid><name>company</name></owner><size><width>%d</width><height>%d</height><depth>%d</depth></size><segmented>0</segmented>"""objstr = """\<object><name>%s</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>%d</xmin><ymin>%d</ymin><xmax>%d</xmax><ymax>%d</ymax></bndbox></object>"""tailstr = '''\</annotation>'''def writexml(idx, head, bbxes, tail):filename = ("Annotations/%06d.xml" % (idx))f = open(filename, "w")f.write(head)for bbx in bbxes:f.write(objstr % (bbx[0], bbx[1], bbx[2], bbx[3], bbx[4]))f.write(tail)f.close()def clear_dir():if shutil.os.path.exists(('Annotations')):shutil.rmtree(('Annotations'))if shutil.os.path.exists(('ImageSets')):shutil.rmtree(('ImageSets'))if shutil.os.path.exists(('JPEGImages')):shutil.rmtree(('JPEGImages'))shutil.os.mkdir(('Annotations'))shutil.os.makedirs(('ImageSets/Main'))shutil.os.mkdir(('JPEGImages'))def excute_datasets(json_path, tr, idx):json_path = os.path.join(json_path, tr)json_file = os.listdir(json_path)savename = open(('ImageSets/Main/' + tr + '.txt'), 'a')for file in json_file:file_path = os.path.join(json_path, file)with open(file_path, 'r', encoding='utf-8') as f:file_json = json.load(f)imagename = file_json["imagePath"].split('\\')[-1]image_path = os.path.join('./images', imagename)image = cv2.imread(image_path)if image is None:continuelabel_shape_type = file_json['shapes'][0]['shape_type']if label_shape_type != 'rectangle':continuehead = headstr % (idx, image.shape[1], image.shape[0], image.shape[2])shapes = file_json['shapes']boxes = []for i in range(len(shapes)):classname = file_json['shapes'][i]['label']'''接下来转化类别为英文,因为labelme在标注的时候,为了标注人员的遍历,类别是中文,但是我们训练模型的时候必须是英文,这里就需要转化了,这里得xxxx不代表真的是xxxx,是你自己训练的类别,为了不让我老板看出我做的是他的项目,这里隐藏了'''if 'xxxxxxx' in classname:classname = 'xxxxxxx'if 'xxxxxxx' in classname:classname = 'xxxxxxx'if 'xxxxxxx' in classname:classname = 'xxxxxxx'if 'xxxxxxx' in classname:classname = 'xxxxxxx'if 'xxxxxxx' in classname:classname = 'xxxxxxx'if 'xxxxxxx' in classname:classname = 'xxxxxxx'box = [classname, file_json['shapes'][i]['points'][0][0],file_json['shapes'][i]['points'][0][1], file_json['shapes'][i]['points'][1][0],file_json['shapes'][i]['points'][1][1]]boxes.append(box)writexml(idx, head, boxes, tailstr)cv2.imwrite('JPEGImages/%06d.jpg' % (idx), image)savename.write('%06d\n' % (idx))idx += 1savename.close()return idxif __name__ == '__main__':clear_dir()idx = 1idx = excute_datasets('./jsonhot', 'train', idx)idx = excute_datasets('./jsonhot', 'val', idx)print('Complete...')
大概需要改的地方我都标注出来了,大家根据自己的实际情况去改上面的代码。上面的代码借鉴了我最上面给的作者的一些代码,毕竟原理都这样,只需要改一改细节上的东西。之前写过一篇文章,在构造 xml 结构的时候用的是 xml 这个库区一个一个节点的构造,现在看来,还是直接向上面的代码那样做简单很多。
我们运行这个代码之后,就会达到我们上面说的目的,生成 annotations 这些文件夹和数据,这个 py 文件运行完后大家一定要去看看产生了什么数据,不然对后面的操作会懵逼的,接下来,我们要写一个 py 文件,我们假设这个文件叫 getdata.py, 我们要达到的目的是:在主目录下生成两个文件夹 train.txt 和 val.txt,这文件名字随意,这两个文件里面存储的是图片的绝对路径,比如:/media/yunyi/file/code/darknet/data/voc/VOCface/JPEGImages/000003.jpg,这个 Py 文件运行后还会生成一个 label 文件夹,这个文件夹里面也会生成以图片名称命名的 txt 文件,这些文件保存的是图片中的标签类别,中心点的 x, 中心点的 y, 标签的宽,边框的高,接下来,我们看看代码:
import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinsets=['train', 'val']classes = ['......']def convert(size, box):dw = 1./size[0]dh = 1./size[1]x = (box[0] + box[1])/2.0y = (box[2] + box[3])/2.0w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)def convert_annotation(image_id):in_file = open(wd + '/Annotations/%s.xml'%(image_id))out_file = open( wd + '/labels/%s.txt'%(image_id), 'w')tree=ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w,h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')if __name__=='__main__':wd = getcwd()wd = wd.replace('\\', '/')for image_set in sets:if not os.path.exists(wd + '/labels/'):os.makedirs(wd + '/labels/')image_ids = open(wd +'/ImageSets/Main/%s.txt' % image_set).read().strip().split()list_file = open('%s.txt' % image_set, 'w')for image_id in image_ids:list_file.write(wd + '/JPEGImages/%s.jpg\n' % image_id)convert_annotation(image_id)list_file.close()
代码里面很多 xml.find() 啥的函数,就是找 xml 里面的节点用的,这些代码,我个人感觉当我们第一个 py 文件执行之后,这个 py 文件改一改类别就可以运行了,当然,有可能会出现意外情况,这时候根据不同的报错解决吧,我这反正是没问题的。
好了,最麻烦的预处理弄完了,接下来咱看看怎么配置 yolov4 了,直接看图片,形象:




在这个 yolov4.cfg 里面,我们一般要更改的就是 batchsize,subdivisions, classes, 这几个参数,对于 filters=255 这一行,根据上面的说明进行更改,max_batches = 500200,steps=400000,450000 这两行大家根据实际情况看该不该,电脑配置给力就没必要改,配置不行就改一下,一般是改为 max_batches = 2000,steps=1600,1800,大家更改的时候直接 ctrl+f 进行定位就行。
对 cfg 文件进行更改之后,我们就要创建两个文件了,比如叫 face.data,face.names,名字你随意,在 face.data 里面,你的内容范本如下:
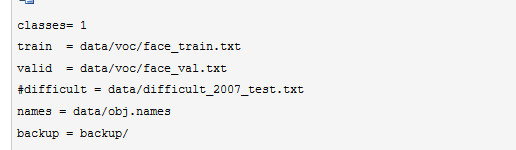
classes 就是你的数据的类别总数,train 就是你上面 getdata.py 生成的 train.txt 文件的路径,这里是相对路径,val 同理,names 就是刚刚创建的 face.names 的路径,backup 就是训练过程保存模型的路径。至于 face.names, 里面的内容就是你的类别名字了,类似下面这张:

做了上面那些工作,终于可以开始训练了,只需要一行命令:./darknet detector train data/xxx.data cfg/yolov4.cfg yolov4.conv.137 -map,其中 yolov4.conv.137 是预训练模型,需要另外进行下载,我有空去下载好然后分享一下,如果没有这个文件,那么只需要执行./darknet detector train data/xxx.data cfg/yolov4.cfg -map(没有 - map 也可以) 即可,yolov4 和 yolov3 训练的时候区别就出来了,yolov4 训练的时候会用一张动态图来显示训练的效果,如下所示:
至于训练的效果,哎,不提了,我的 gtx2060 还在学校,现在还没有返校,只能用多年前的笔记本了,这笔记本显卡是 720m,但是不知道是不是 cuda 这些版本没有选择好,yolo 不能使用我这台的 gpu,以前折腾了很久,最后放弃了,所以,我只能用 cpu 来跑,但是我这 cpu 还是四代 i5 的,跑不动,所以。。。。。。。。没有训练效果。
好了,训练过程终于理清并且写完了,觉得有用的,留个赞再走呗。
补充:刚刚把作者给的预训练模型下载了,免费分享链接如下:https://blog.csdn.net/yapifeitu/article/details/105756274,拿走的时候记得点赞哦。
ps:5.7 号用百度的显卡跑了一下 yolov3 的模型,果然出问题了,最后,补上上面没有说到的地方:我们在训练的时候,对于 cfg 文件,我们要将 test 注释掉,类似于下面这种:
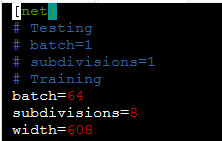
哎,就这里没注释然后去跑模型,让我纠结了好久,希望大家后面注意。
5.8 号我在 aistudio 上用上面的 tesla v100 跑了一个人脸检测的 yolov4 模型 (由于这篇文章涉及到的数据是我老板发钱买来的,不适合放到公开平台去,所以就用公开数据集跑了人脸检测的模型),显卡给力,跑模型的速度就给力,模型跑的 avgloss 在 3 左右后一直在这附近徘徊,知道应该是降不下去多少了,然后把模型下载了,放到自己的的电脑上来测试了几张照片,效果挺不错的,给大家看看效果吧:


很明显这里误检测了一个地方,其余的 16 张人脸都检测到了,还别说,那个误检测的还真有些像。

至于这张图片,用 yolov4 训练的模型,检测完美,但是用 yolov3 训练好的模型然后用 yolov3 去测试,会出现误检的情况,不知道是不是模型训练不够的原因。
2020 4.25
https://blog.csdn.net/yapifeitu/article/details/105749693

若有收获,就点个赞吧
0 人点赞
