Q:如何阅读源码? A:先了解技术框架或前世今生,建立全局认知观,再深入具体细节会更容易坚持。否则可能看了半天细节类不知道整体如何运作,好像看了,但又好像什么都不明白。
还可以关注 Kafka 社区的新动态。 如官网最上面就有 community https://kafka.apache.org/
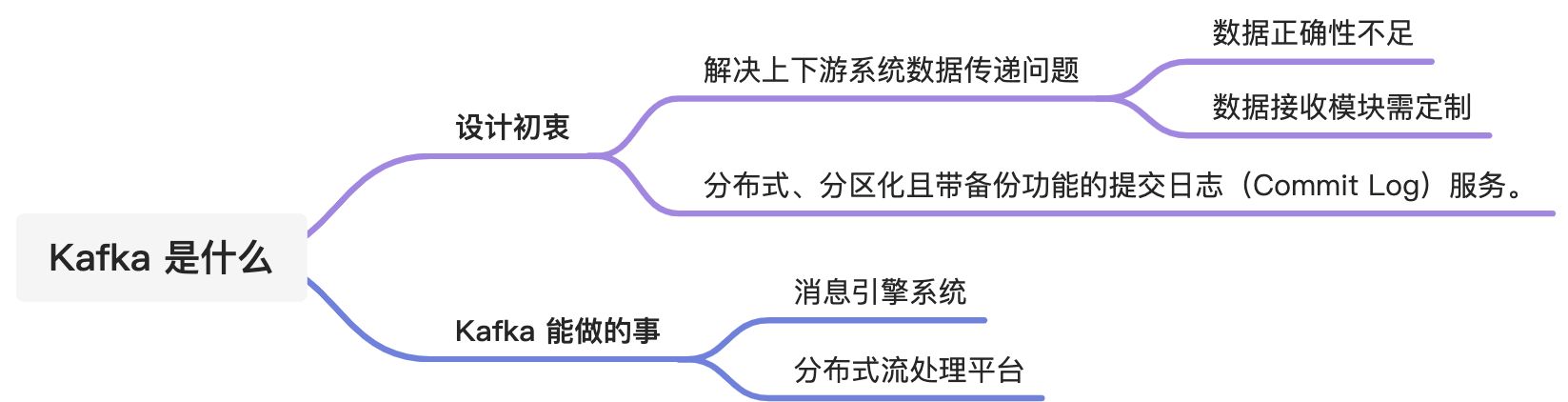
Kafka 设计初衷
- 提供一套 API 实现生产者和消费者;
- 降低网络传输和磁盘存储开销;
- 实现高伸缩性架构。
目前理解:大数据下的生产者消费者场景工具。
如果是你来设计 Kafka 会用什么方式应对大数据场景? 其中能考虑到可能那些环节会遇到问题?
Kafka 还是个流处理平台
Kafka 不光是消息引擎系统,同时还兼具流处理平台的功能(只不过这个功能在国内还没有很好的推广开)。
流处理功能设计的初衷是:
从一个系统流入 Kafka 再流向下游另一个系统。那 Kafka 为何不直接把数据处理也做了呢?
思考: 1)为何没被推广开呢?如果真的好用,可能也不会有 Flink 之类的爆火了,肯定是有一些局限的 2)Kafka 真的需要流处理的功能么?仅做消息引擎系统不好么
与主流大数据流式计算框架相比,优势在哪里呢?
- 更容易实现端到端的正确性
- 以 Flink 为例,实现端到端的 exactly-once 是一个很麻烦的事情。需要上下游的系统协同配合。把数据输出到下游之后,再想修改这个数据就很困难了。
- 如果使用 Kafka 就可以所有计算都在内部完成。
- 定位:Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统
- 可以在小规模计算资源下完成部署
- 但同时,也需要一大票工具或系统来帮助 Kafka 提供集群调度、弹性部署等功能,不能开箱即用
Kafka在流处理平台的来龙去脉 —— “ETL Is Dead, Long Live Streams”
https://www.youtube.com/watch?v=I32hmY4diFY

若有收获,就点个赞吧
0 人点赞
