思考: 如果你来设计高并发请求会如何处理?
- 使用线程池
本节详细讨论一下 Kafka Broker 端处理请求的全流程。
一、数据类请求处理
Kafka 是如何处理请求的呢?用一句话概括就是,Kafka 使用的是Reactor 模式。
谈到 Reactor 模式,大神 Doug Lea 的“Scalable IO in Java”应该算是最好的入门教材了。即使你没听说过 Doug Lea,那你应该也用过 ConcurrentHashMap 吧?这个类就是这位大神写的。其实,整个 java.util.concurrent 包都是他的杰作!
简单来说,Reactor 模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。
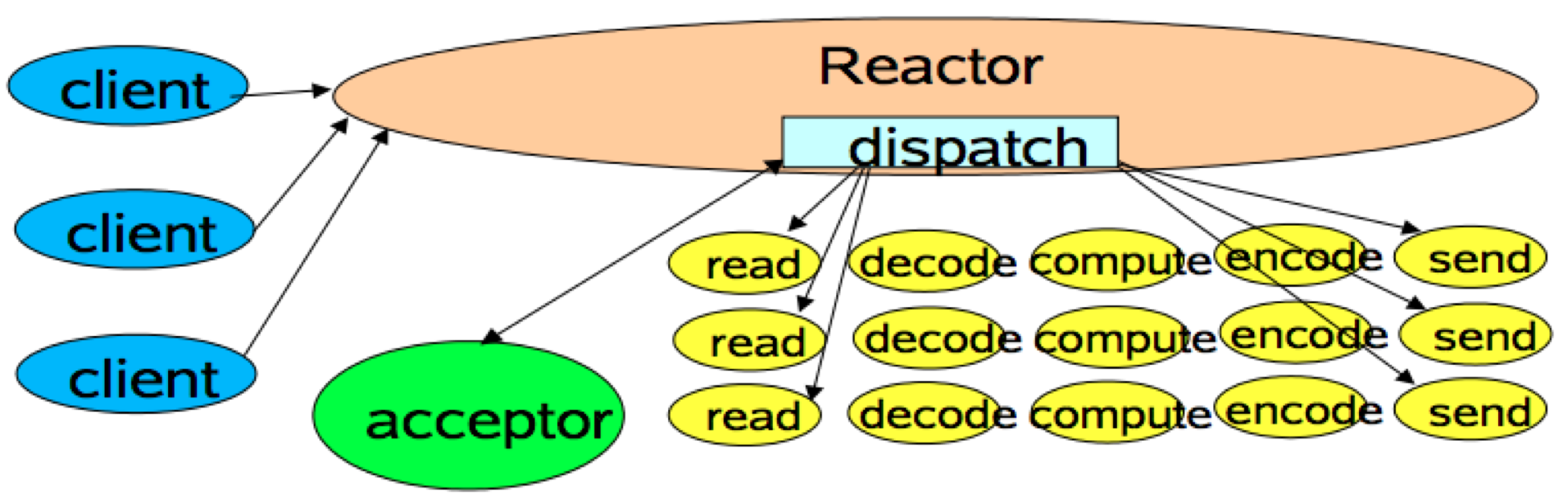
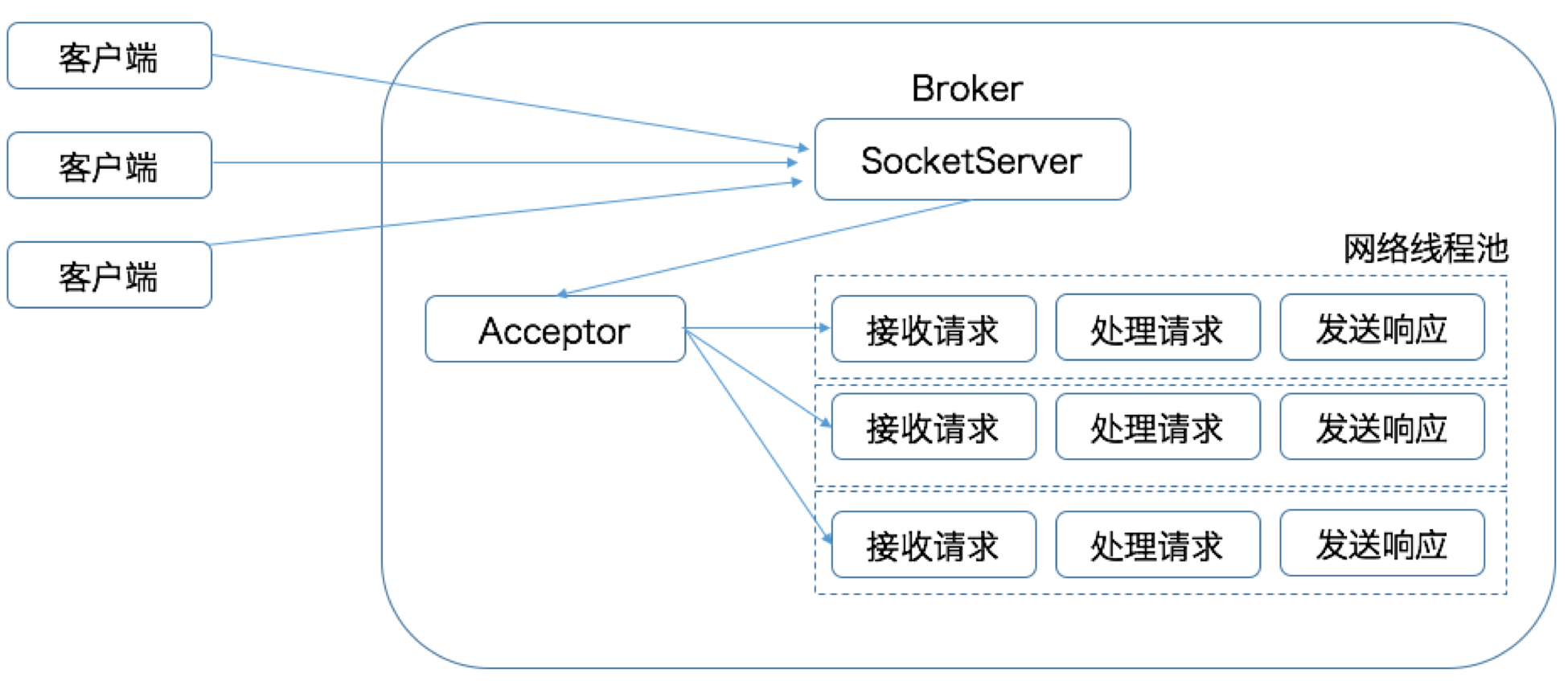
请求处理流程:
- client 发请求给 SocketServer
- Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中
- 网络线程池异步处理请求
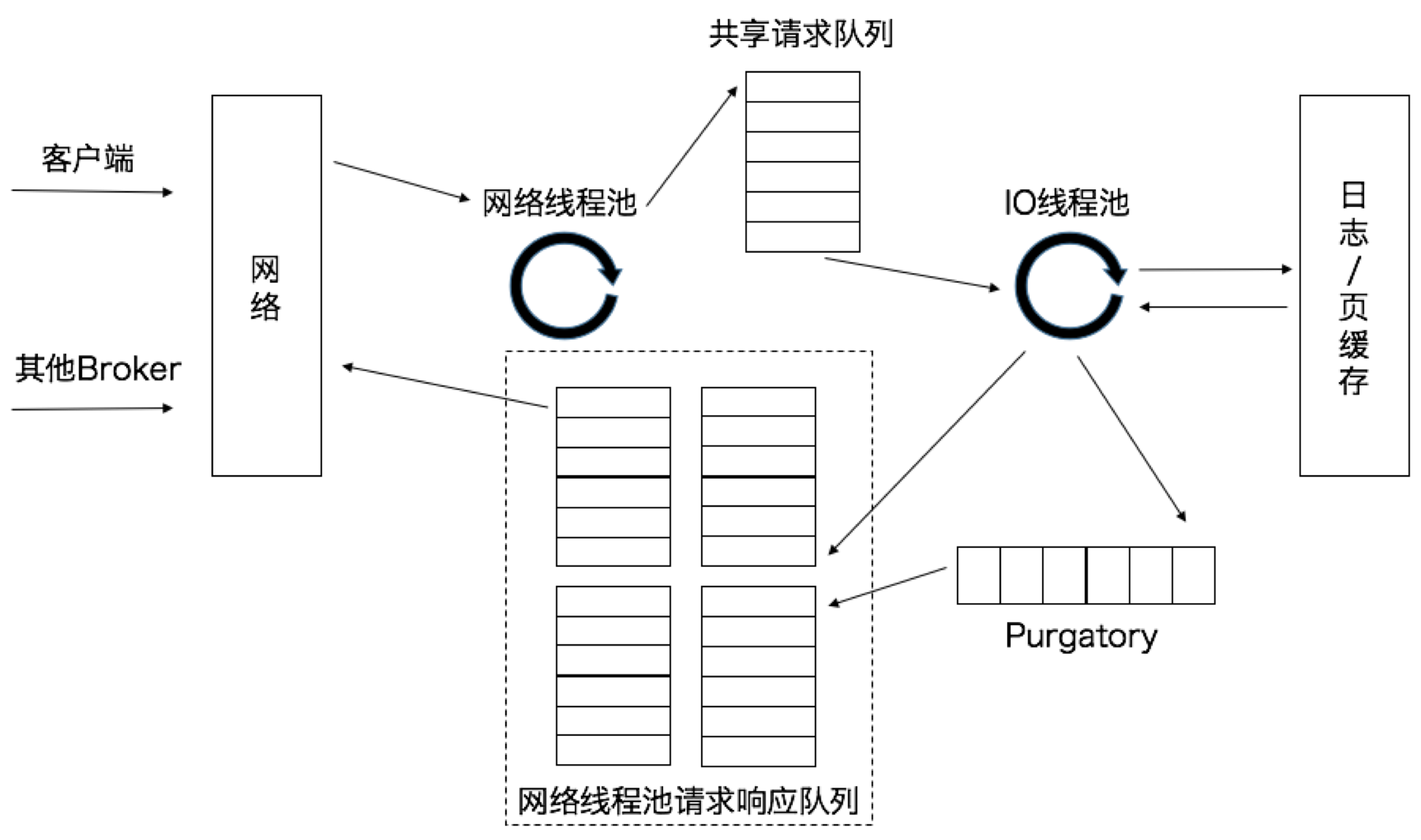
网络线程池处理请求的流程:
- 当网络线程拿到请求后,它不是自己处理,而是将请求放入到一个共享请求队列中。
- Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理(IO 线程池处中的线程才是执行请求逻辑的线程)
- 当 IO 线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中,然后由对应的网络线程负责将 Response 返还给客户端
- 图中有一个叫 Purgatory 的组件,这是 Kafka 中著名的“炼狱”组件。它是用来缓存延时请求。即等待相关线程都完成后再一起返回
思考: 这么做的目的是把网络请求和数据访问解耦?
- 网络线程池就只负责接收和响应请求
- IO 线程池只负责做数据交互
这样就可以理解为什么共用一个请求队列而响应队列要分开:
- 都放进一个请求队列,让 IO 线程依次处理
- 但 IO 线程不负责 response 数据,因此要把消息返回给各个网络线程,让它们自己与客户端交互
二、控制类请求处理
需要保证「控制类请求」能被优先处理,因为其会影响数据类请求。
方法:在单独开一个和数据类请求一模一样的处理流程,两种请求互不干涉
另:使用优先级队列看似也能解决问题,但如果遇到队列满了的情况可能需要额外的逻辑来保障

若有收获,就点个赞吧
0 人点赞
