用 Java 中最常见的工具类,开发一个简单的流计算框架,你会进一步在源码细节的层面,看到异步和流是如何相通的。另外,虽然这个框架简单,但它是我们从 Java 异步编程,迈入流计算领域的第一步,同时它也反映出了所有流计算框架中,最基础也是最核心的组件,即用于传递流数据的队列,和用于执行流计算的线程。
一、开源流计算框架是如何描述计算流程的
Flink
采用了 JobGraph 这个概念,来描述流计算的过程的。下图是 Flink 将 JobGraph 分解为运行时的任务的过程
很容易看出,左边的 JobGraph 不就是 DAG 有向无环图嘛!其中 JobVertex A 到 JobVertex D,以及表示它们之间依赖关系的有向线段,共同构成了 DAG 有向无环图。这个 DAG 被分解成右边一个个并行且有依赖关系的计算节点,这相当于原始 DAG 的并行化版本。之后在运行时,就是按照这个并行化版本的 DAG 分配线程并执行计算任务。
二、用 DAG 描述流计算过程
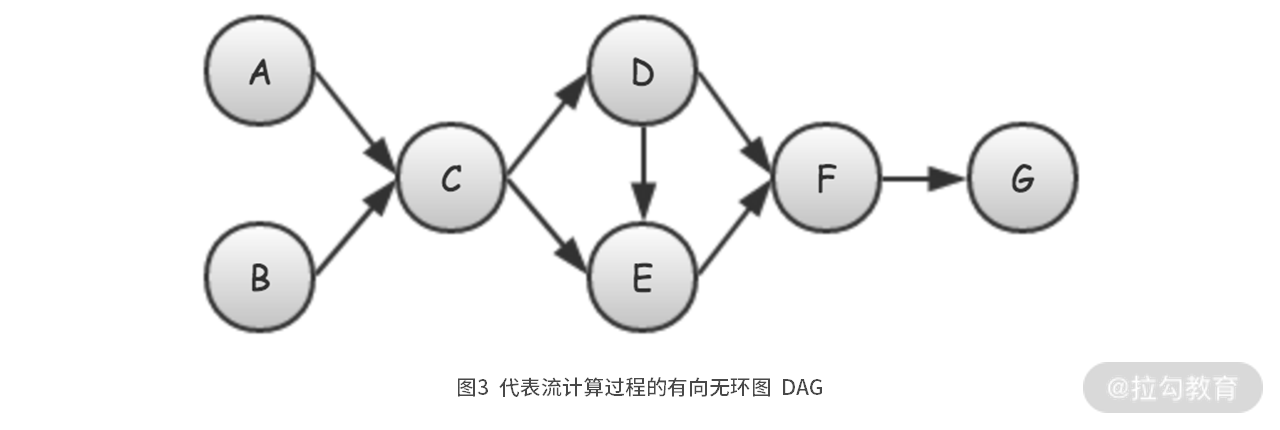
我们对 DAG 的概念稍微做些总结。可以看到上面这个 DAG 图,是由两种元素组成,也就是代表节点的圆圈,和代表节点间依赖关系的有向线段。
DAG 有以下两种不同的表达含义。
- 一是,如果不考虑并行度,那么每个节点表示的是计算步骤,每条边表示的是数据在计算步骤之间的流动,比如图 3 中的 A->C->D。
- 二是,如果考虑并行度,那么每个节点表示的是计算单元,每条边表示的是,数据在计算单元间的流动。这个就相当于将表示计算步骤的 DAG 进行并行化任务分解后,形成的并行化版本 DAG。
为了实现并行提取特征值的目的,我们设计了下图 4 所示的,特征提取流计算过程 DAG。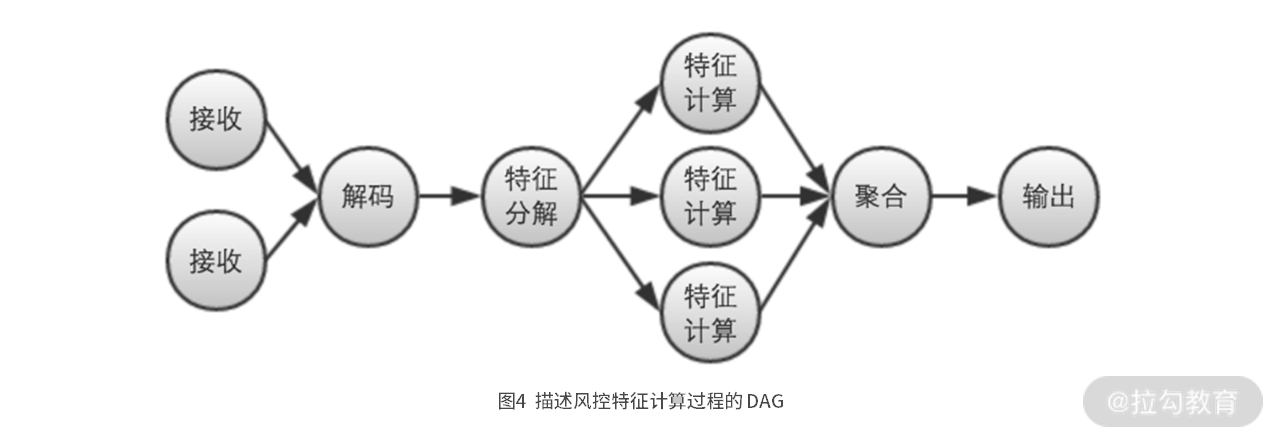
接下来,我们就需要看具体如何,实现这个并行化的 DAG 。看着图 4 这个 DAG,我们很容易想到,可以给每个节点分配一个线程,来执行具体的计算任务。而在节点之间,就用队列(Queue) ,来作为线程之间传递数据的载体。
具体而言,就是类似于下图 5 所描述的过程。一组线程从其输入队列中取出数据进行处理,然后输出给下游的输入队列,供下游的线程继续读取并处理。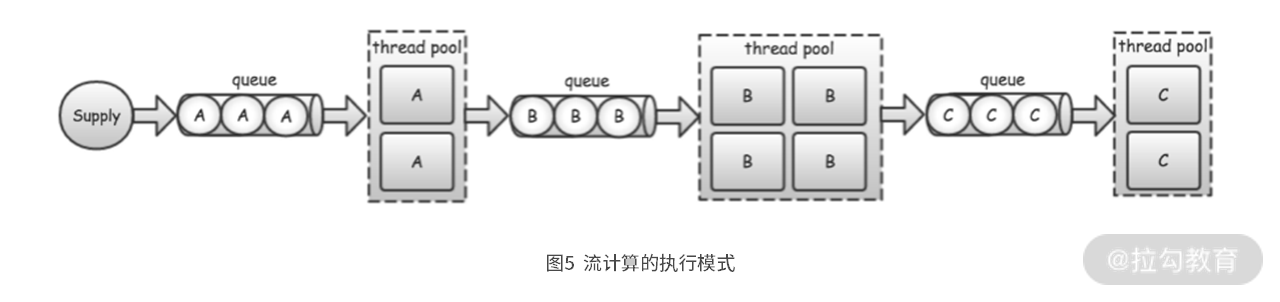
三、用线程和队列实现 DAG
涉及技术:
- 线程
- 阻塞队列

若有收获,就点个赞吧
0 人点赞
