一、实时流计算技术应用场景
任何一个系统的产生,都是为了解决一个具体的问题。实时流计算技术的诞生,就是为了更快更完整地获取数据,更快更充分地挖掘出数据价值。
场景1: 某打车软件公司交通热点路段分析及可视化系统。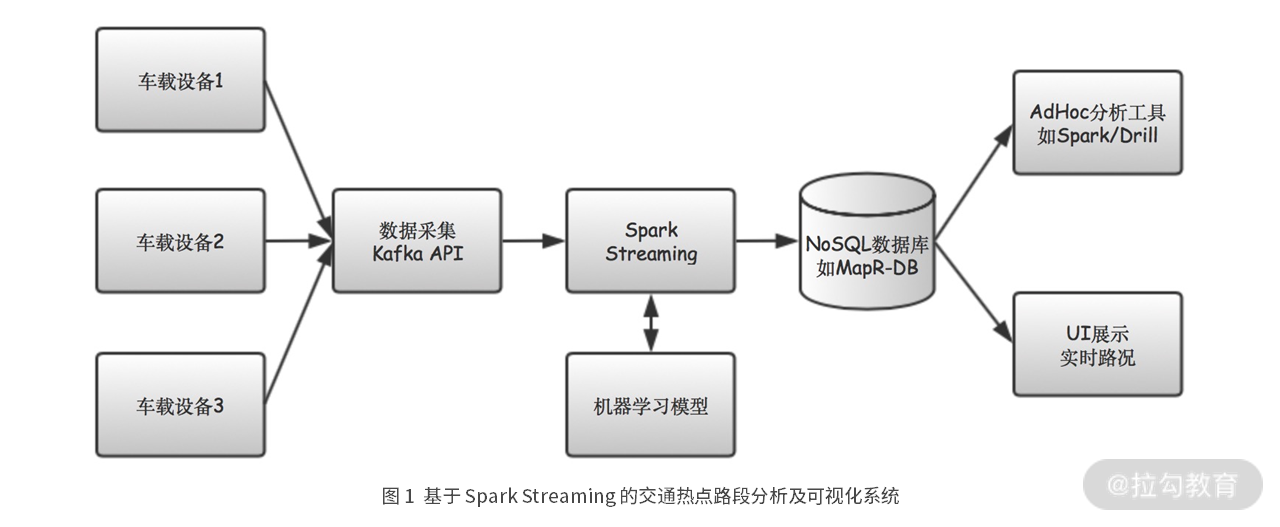
场景2:基于 Flink 的实时欺诈检测平台。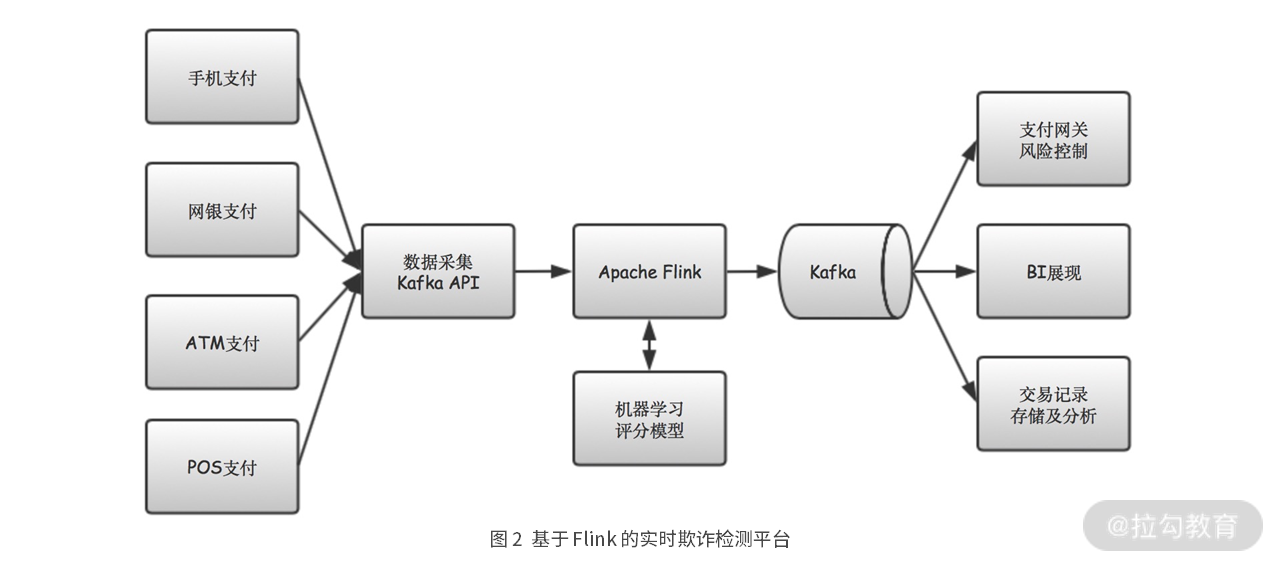
二、实时流计算系统通用架构
比较上面两个场景的流计算系统组成,我们不难发现这些系统,都包含了五个部分:数据采集、数据传输、数据处理、数据存储和数据展现。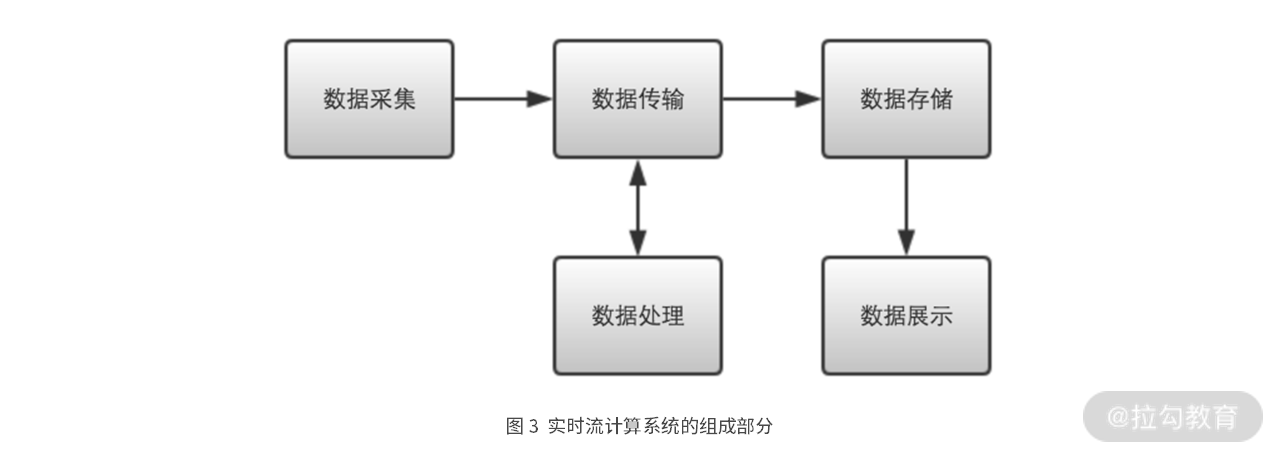
数据采集
数据采集,就是从各种数据源收集数据的过程,比如浏览器、手机、工业传感器、日志代理等。
其中有五个关键点。
- 吞吐量
我们一般用 TPS(Transactions Per Second),也就是每秒处理事务数,来描述系统的吞吐量。当吞吐量要求很高时,通常就只能选择非阻塞 IO 的编程框架了。
- 时延
当吞吐量和时延同时有性能要求时,我一般是先保证能够满足时延要求,然后在此基础上,再尽可能提高吞吐量。如果一个服务实例的吞吐量,满足不了要求,就部署多个服务实例。
- 发送方式
数据可以逐条发送,也可以批次发送。相比逐条发送而言,批次发送每次的网络 IO 耗时更多,为了提升接收服务器的吞吐能力,我一般也会采用 Netty 这样的非阻塞 IO 框架。
- 连接方式
使用长连接还是短连接,一般由具体的场景决定。当有大量连接需要维持时,就需要使用非阻塞 IO 服务器框架,比如 Netty。而当连接数量较少时,采用长连接和连接池的方案,一般也会非常显著提升请求处理的性能。
- 连接数量
如果数据源相对固定,比如微服务之间的调用,那我们可以采用长连接配合连接池的方案,这样一般会非常显著地提升请求处理的性能。但当数据源很多或经常变化时,应该将连接保持时间(Keep Alive Timeout)设置为一个合理的值。
难点:在高并发和高吞吐场景下,需要对 NIO 和异步编程有非常深刻的理解。
数据传输
我们这里说的数据传输,是指流数据在各个模块间流转的过程。
流计算系统中,一般是采用消息中间件进行数据传输的,比如 Apache Kafka、RabbitMQ 等,在微服务系统中一般是采用 HTTP 或 RPC 的方式进行数据传输。这是流计算系统与微服务系统最明显的区别。
在选择消息中间件时,需要重点考虑五个方面的问题:吞吐量、时延、高可用、持久化和水平扩展。
数据处理
接下来,我们来看下流计算系统的核心模块,即数据处理。
我们构建实时流计算系统的目的,就是为了解决具体的业务问题。总的来说,这些业务问题可以分为以下四类。
- 第一类是数据转化
数据转化包括对流数据的抽取、清洗、转换和加载。比如使用 filter 函数过滤出符合条件的流数据,使用 map 函数给流数据增加新的字段。再比如更复杂的 Flink SQL CDC,也属于数据转化的内容。
- 第二类是在流数据上统计
各种指标,比如计数、求和、均值、标准差、极值、聚合、关联、直方图等。
- 第三类是模式匹配
模式匹配是指在流数据上,寻找预先设定的事件序列模式。比如我们常说的 CEP,也就是复杂事件处理,就属于模式匹配。
- 第四类是模型学习和预测
基于流的模型学习算法,可以实时动态地训练或更新模型参数,继而根据模型做出预测,能更加准确地描述数据背后当时正在发生的事情。
难点:主要表现在与业务的贴合。需要对流计算能够解决哪些问题有比较深刻的理解,并需要熟练掌握解决这些问题的算法。
数据存储
数据存储,是一个非常麻烦的问题,特别是在实时流计算领域,这种大数据、低时延、高吞吐的场景,对我们的数据存储方案,挑战是非常大的。
不知道你是否考虑过这个问题,为什么软件行业,有那么多不同种类的数据库?MySQL、MongoDB、Redis、HBase、ElasticSearch、CockroachDB……随便想一下,就可以列举出数十种数据库。这是因为每种数据库,其实都有其擅长的使用场景,没有一种数据库能够在所有场景下都能胜任。
数据展现
数据展现就是将数据呈现给最终用户的过程。

若有收获,就点个赞吧
0 人点赞
