一、什么是流数据操作
它是针对数据流的“转化”或“转移”处理。流数据操作的内容主要包括四类。
流数据的清洗、规整和结构化。比如提取感兴趣字段、统一数据格式、过滤不合条件事件。
流数据的关联及合并。比如在广告转化率分析中,将“点击”事件流和“安装”事件流关联起来。
流数据的分发和并行处理。比如将一个包含了来自不同设备事件的数据流,按照设备id分发到不同的流中进行处理。
流数据的转移和存储。比如将数据从 Kafka 转移到数据库里。
虽然不同系统实现以上四类流数据操作的具体方法不尽相同,但经过多年的实践和经验积累,业界针对流数据操作的目标和手段都有了一定的共识。比如:
- 针对流数据的清洗、规整和结构化,抽象出 filter、map、flatMap、reduce 等方法;
- 针对流数据的关联及合并,抽象出 join、union 等方法;
- 针对流数据的分发和并行处理,抽象出 keyBy 或 groupBy 等方法;
- 针对流数据的转移和存储,则抽象出 foreach 等方法。
二、常用 API
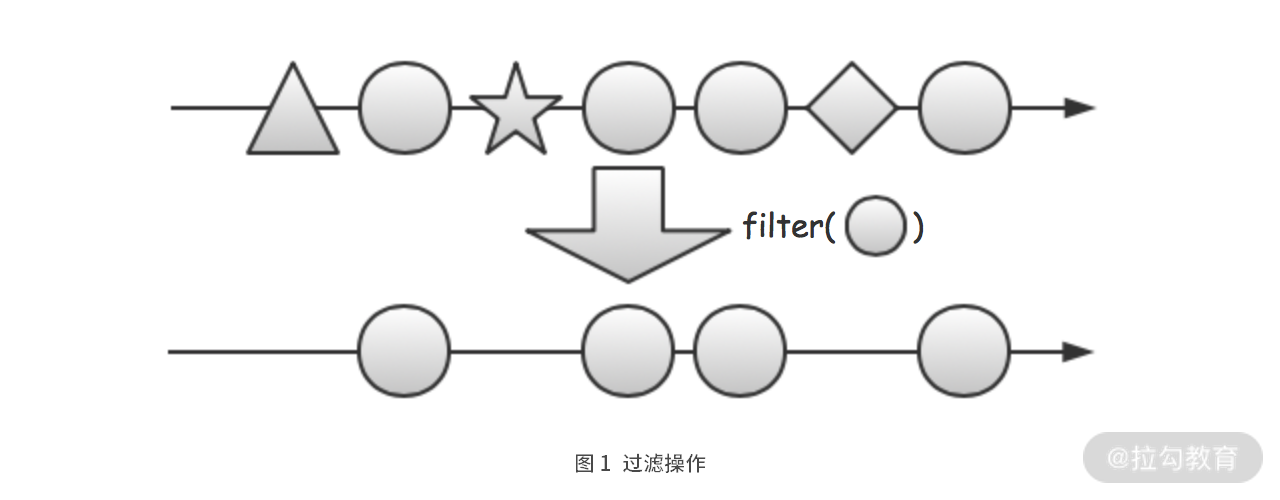
Filter 过滤
DataStream<JSONObject> highTemperatureStream = temperatureStream.filter(x -> x.getDouble("temperature") > 100);
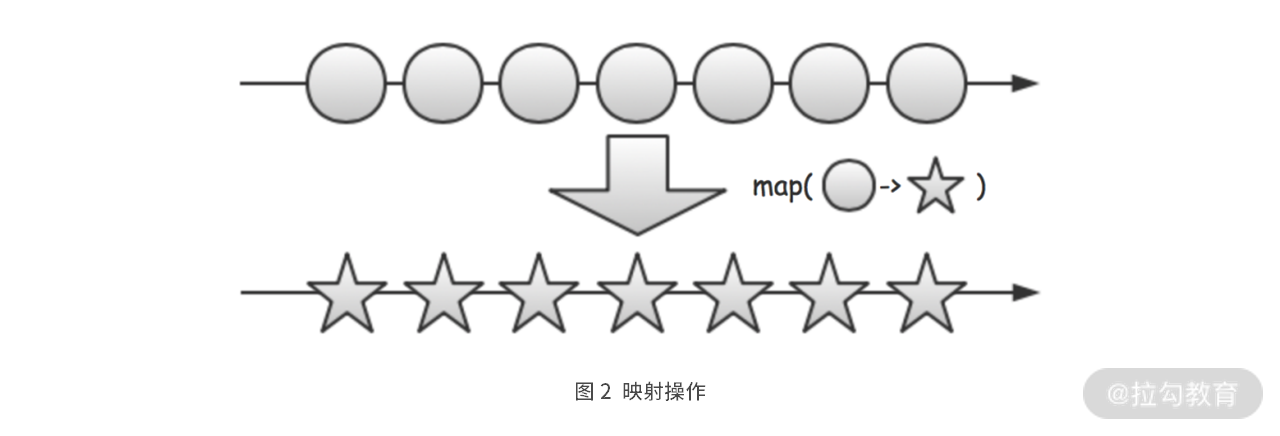
Map 映射
DataStream<JSONObject> enhancedTemperatureStream = temperatureStream.map(x -> {x.put("isHighTemperature", x.getDouble("temperature") > 100);return x;});
FlatMap 展开映射
“展开映射”用于将数据流中的每条数据转化为 N 条新数据。
如:将数组中的元素拆开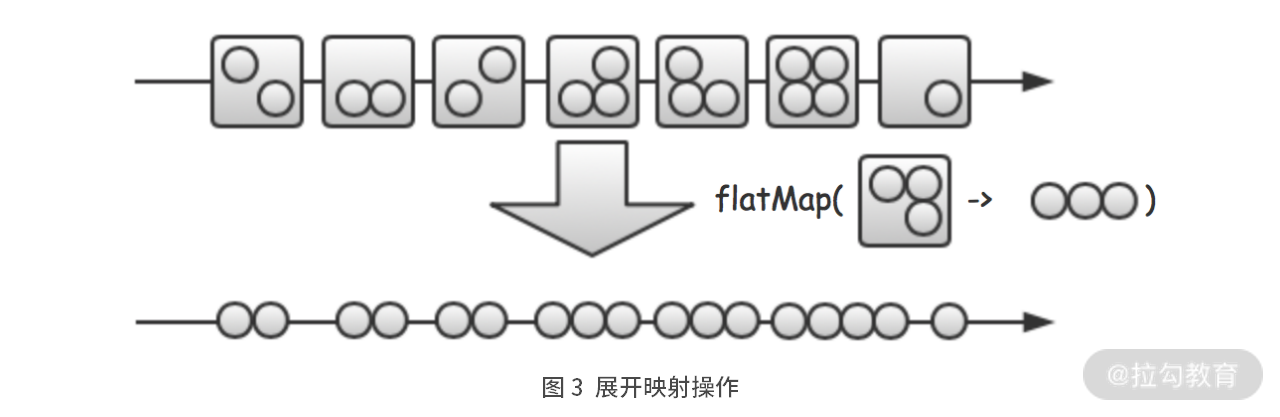
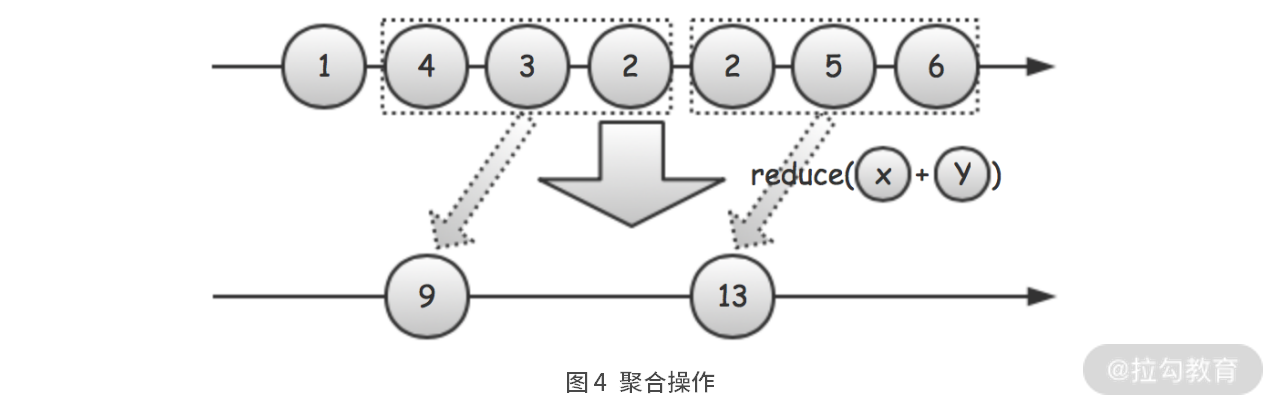
Reduce 聚合
DataStream<Tuple2<String, Integer>> countStream = socialWebStream.map(x -> Tuple2.of("count", 1)).returns(Types.TUPLE(Types.STRING, Types.INT)).timeWindowAll(Time.seconds(10), Time.seconds(1)).reduce((count1, count2) -> Tuple2.of("count", count1.f1 + count2.f1));
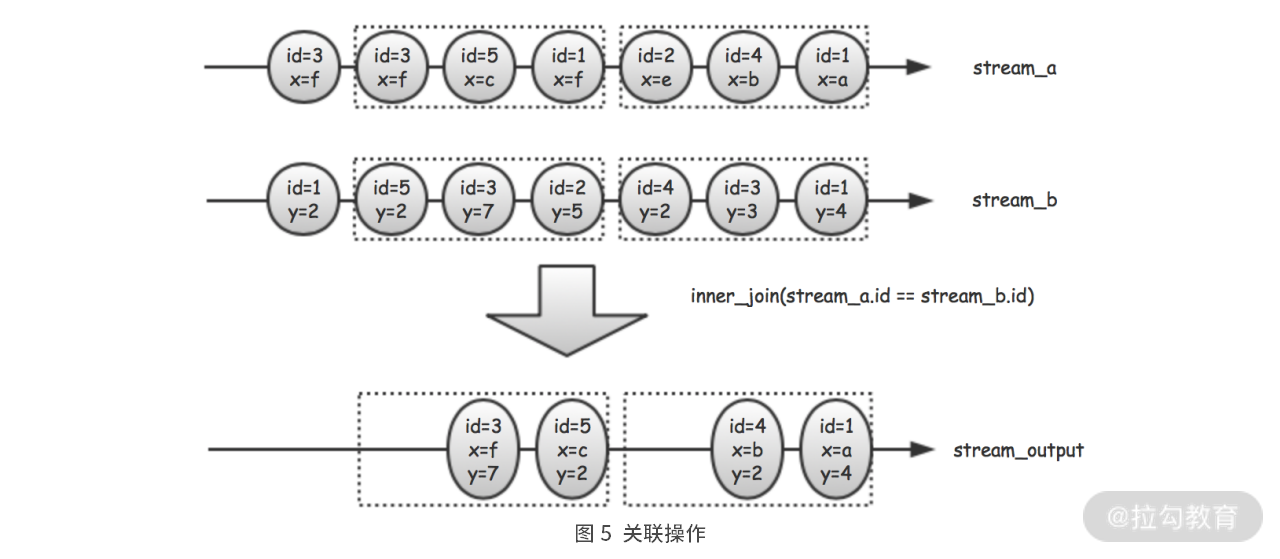
Join 关联
“关联”用于将两个数据流中满足特定条件的数据对组合起来,再按指定规则形成新数据,最后将新数据添加到输出数据流。
需要注意的是,join 一般需要关注窗口长度,否则会带来极大的性能问题。
DataStream<JSONObject> joinStream = socialWebStream.join(socialWebStream2).where(x1 -> x1.getString("user")).equalTo(x2 -> x2.getString("user")).window(TumblingEventTimeWindows.of(Time.seconds(10), Time.seconds(1))).apply((x1, x2) -> {JSONObject res = new JSONObject();res.putAll(x1);res.putAll(x2);return res;});
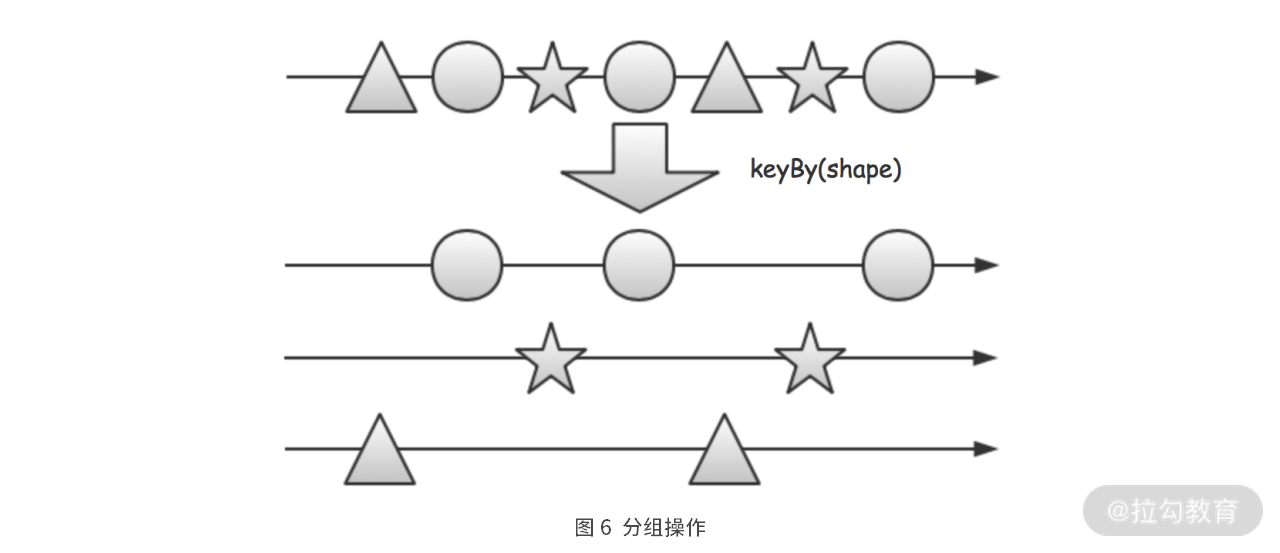
Key by 分组
如果说各种流计算框架最终能够实现分布式计算,实现高并发和高吞吐,那么最大的功臣莫过于“分组”操作的实现。
“分组”操作是实现并行流计算的最主要手段,它将流划分为不相交的分区流,之后分组键相同的消息会被划分到相同的分区流中。并且,各个分区流在逻辑上互不干扰,具有各自独立的运行时上下文。这就带来两个非常大的好处。
其一,流分组后,能够被分配到不同的计算节点上执行,从而实现了 CPU、内存、磁盘等资源的分布式使用和扩展。
其二,分区流具有独立的运行时上下文,就像线程局部量一样,对于涉及运行时状态的流计算任务来说,极大地简化了安全处理并发问题的难度。
DataStream<Tuple2<String, Integer>> keyedStream = transactionStream.map(x -> Tuple2.of(x.getString("product"), x.getInteger("number"))).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(10))).sum(1);
Foreach 遍历
流数据的归宿,即遍历 foreach 操作。“遍历”是对数据流的每个元素执行指定方法的过程。遍历与映射非常相似但又非常不同。
说不同是因为 foreach 和 map 语义大不相同。从 API 语义上来讲,map 作用是对数据流进行转换,但 foreach 并非对数据流进行转换,而是“消费”掉数据流。也就是说,数据流在经过 foreach 后也就终结了。所以我们通常使用 foreach 操作对数据流进行各种 IO 操作,比如写入文件、存入数据库、打印到显示器等。

若有收获,就点个赞吧
0 人点赞
