算法复杂度过高、数据量过大,我们并不能通过直接的实时计算,获得想要的结果。比如,二度关联图谱计算以及一些复杂的统计学习模型或机器学习模型训练等。在这种情况下,我们该如何制定出一个可以真实落地的系统架构方案呢?
Lambda 架构
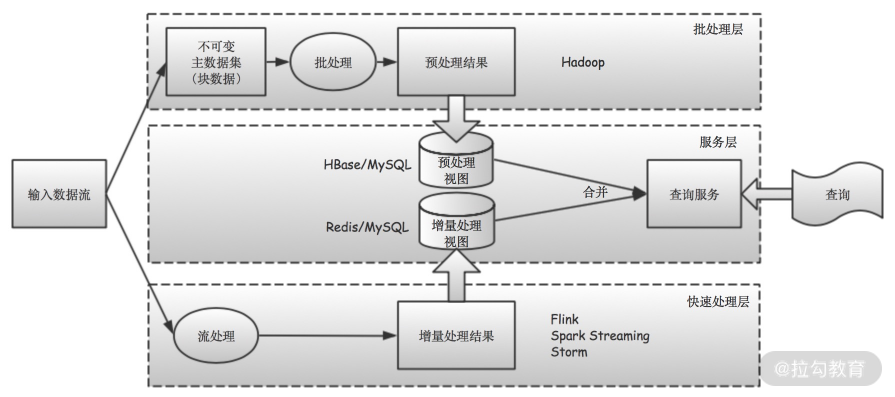
从上面的图 1 可以看出,Lambda 架构总体上分为三层:批处理层(batch layer)、快速处理层(speed layer)和服务层(serving layer),其中:
- 批处理层负责处理主数据集(也就是历史全量数据)
- 快速处理层负责处理增量数据(也就是新进入系统的数据)
- 服务层用于将批处理层和快速处理层的结果合并起来,给用户或应用程序提供查询服务
Lambda 架构是一种架构设计思路,针对每一层的技术组件选型并没有严格限定。我们可以根据自己公司和项目的实际情况,选择相应的技术方案。
如:批处理层选择离线计算方案,MR、Hive、Spark 等
快速处理层用 Flink、Spark streaming 等
虽然 Lambda 架构实现了间接的实时计算,但它也存在一些问题。其中最主要的就是,对于同一个查询目标,需要分别为批处理层和快速处理层开发不同的算法实现。也就是说,对于相同的逻辑,需要开发两种不同的代码,并使用两种不同的计算框架(比如同时使用 Storm 和 Spark)。
Kappa 架构
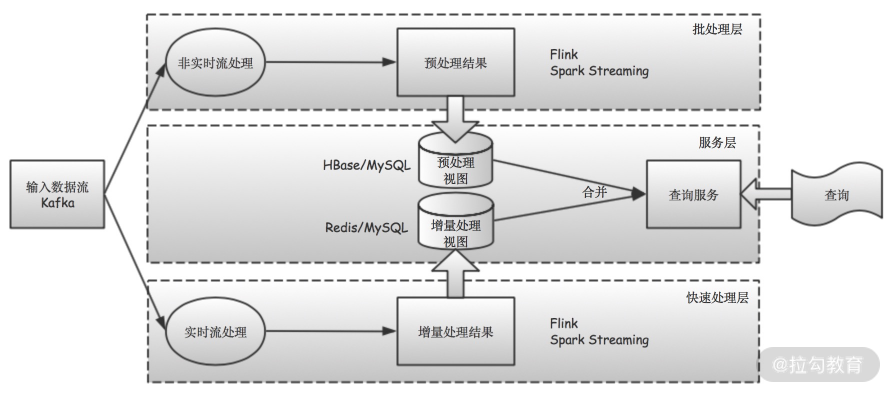
Kappa 架构相比 Lambda 架构的最大改进,就是将批处理层也用快速处理层的流计算技术所取代。这样一来,批处理层和快速处理层使用相同的流计算逻辑,并有更统一的计算框架,从而降低了开发、测试和运维的成本。

若有收获,就点个赞吧
0 人点赞
