一、基本神经网络
1. 神经网络简述
神经网络利用现有的数据找出输入与输出之间的权值关系,然后利用这样的权值关系进行仿真,例如输入一组数据仿真出输出结果,当然你的输入要和训练时采用的数据集在一个范畴之内。例如学历、专业、性别、工作城市等作为输入,工资作为输出,利用这组输入输出可以构建一个神经网络模型,通过模型再来预测未知人员的工资情况。
2.神经元模型
神经元模型也称之为MP模型,根据发明这个模型的两个人的名字命名的,一个典型的神经元模型如下: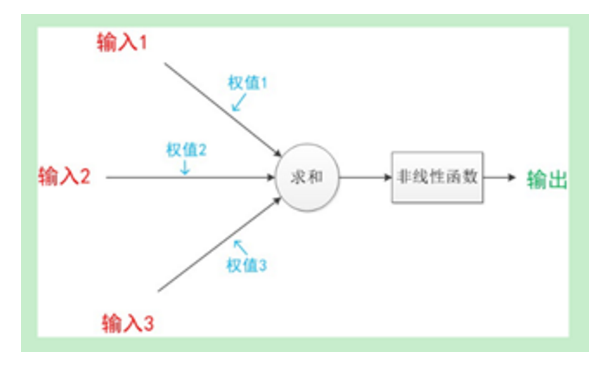
如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。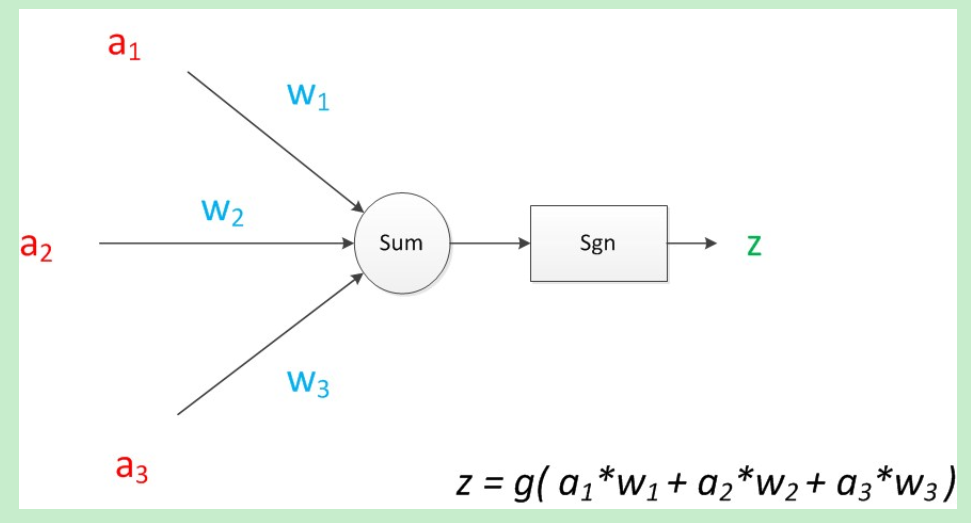
请注意:在MP模型中,函数g是sgn函数,也就是取符号函数。因此MP模型是可以做线性分类任务的(并且MP模型由于是单层的,只能做线性分类),类似于逻辑回归。我们可以用决策分界来形象的表达分类的效果,决策分界就是在二维的数据平面中划出一条直线。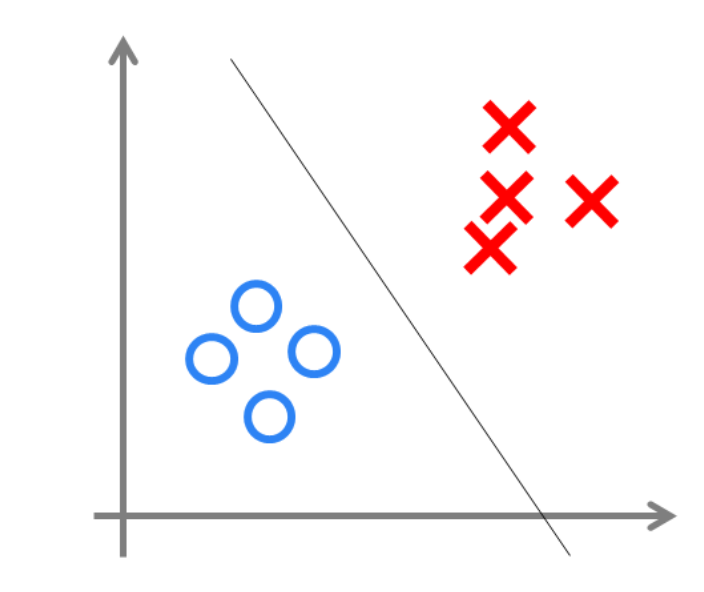
3.感知器
感知器和MP模型所不同的是,在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”,其余不变。在感知器中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。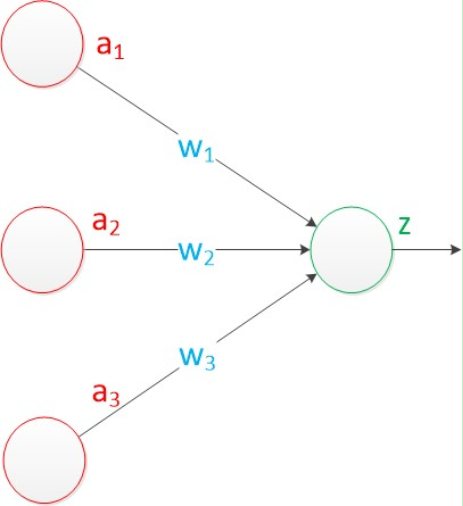
如果要预测的目标不再是一个值,而是一个向量,例如[2,3],那么可以在输出层再增加一个“输出单元”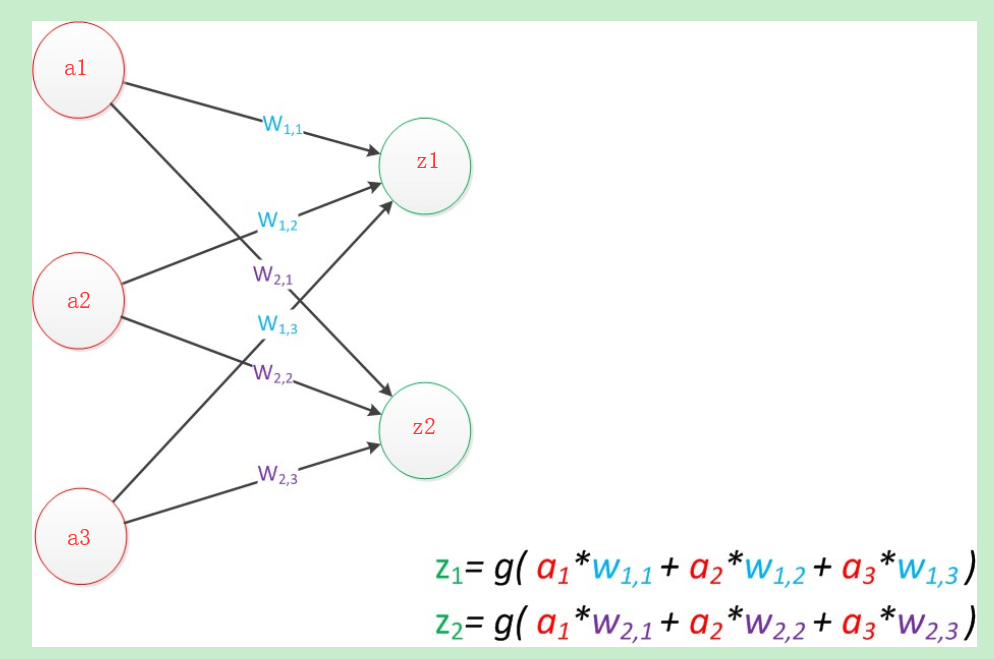
这里我们将这个列向量表示成向量a,a=[a1,a2,a3]T同理将输出表示为[z,z],用向量z表示,系数则是w,表示为
那么这个公式可表示为
即有g(w·a)= z,这个公式就是神经网络中从前一层计算后一层的矩阵运算。
4.两层神经网络
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。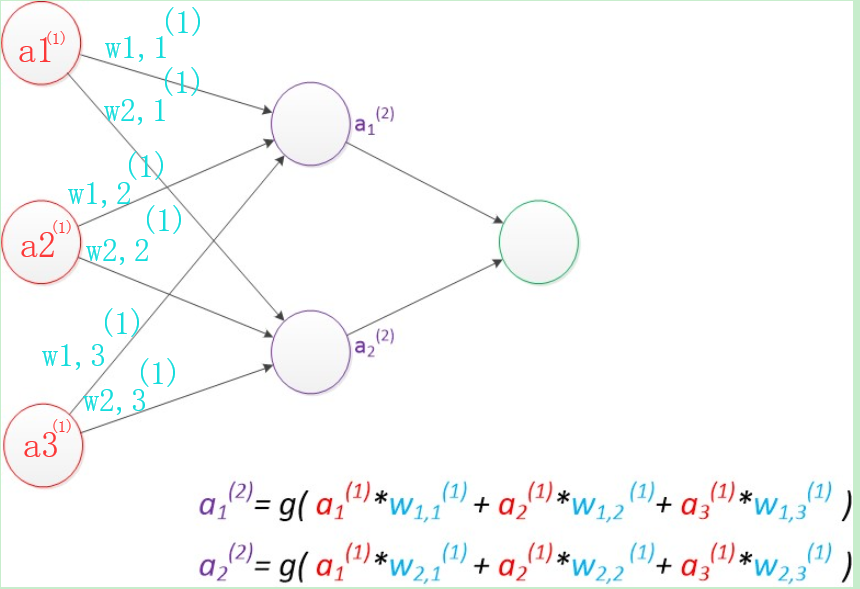
最终的输出z的方式是利用了中间层的a1(2),a2(2)和第二个权值矩阵计算得到的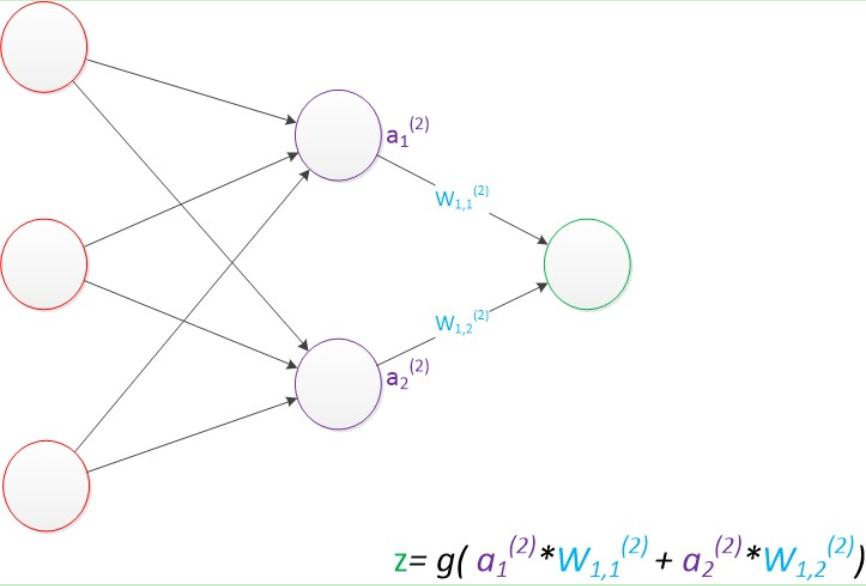
需要说明的是,在两层神经网络中,不再使用sgn函数作为函数g,而是使用平滑函数sigmoid作为函数g,我们把函数g也称作激活函数,sigmoid函数公式为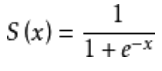
sigmoid函数图像为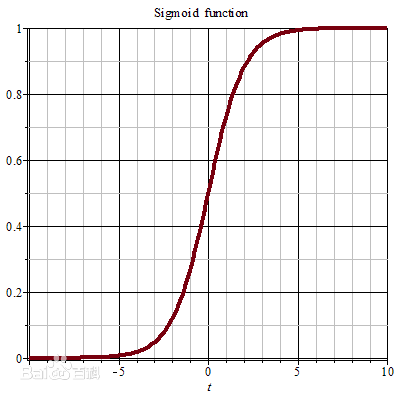
两层神经网络具有非常好的非线性分类效果,理论证明,两层神经网络可以无限逼近任意连续函数。也就是说,面对复杂的非线性分类任务,两层(带一个隐藏层)神经网络可以分类的很好。红色的线与蓝色的线代表数据。而红色区域和蓝色区域代表由神经网络划开的区域,两者的分界线就是决策分界。
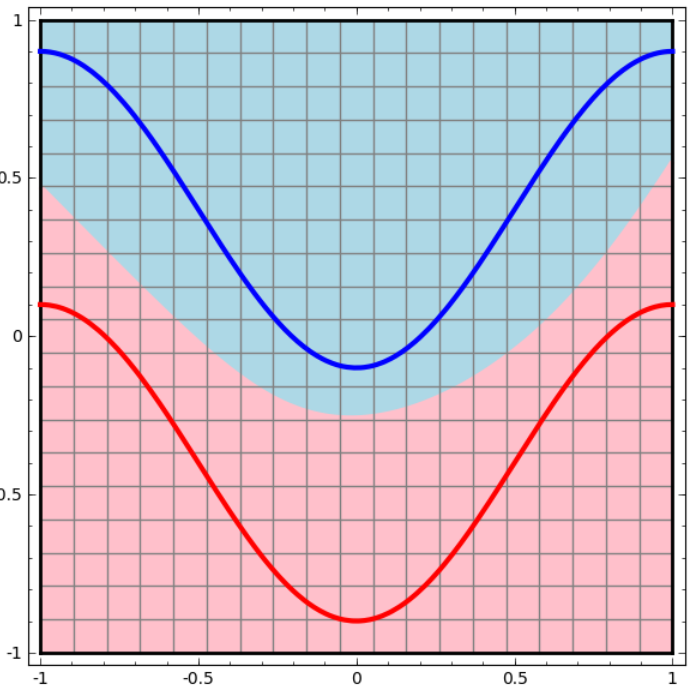
这样就导出了两层神经网络可以做非线性分类的关键—隐藏层。联想到我们一开始推导出的矩阵公式,我们知道,矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。因此,隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。如何决定这个自由层的节点数呢?目前业界没有完善的理论来指导这个决策。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择效果最好的值作为最终选择。这种方法又叫做Grid Search(网格搜索)。
5.反向传播法
机器学习模型训练的目的,就是使得参数尽可能的与真实的模型逼近。具体做法是这样的。首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。

这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。将先前的神经网络预测的矩阵公式带入到y中,这个函数称之为损失函数(loss function)。下面的问题就是如何优化参数能够让损失函数的值最小。此时这个问题就被转化为一个优化问题。一个常用方法就是高等数学中的求导,但是这里的问题由于参数不止一个,求导后计算导数等于0的运算量很大,所以一般来说解决这个优化问题使用的是梯度下降算法。梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。在神经网络模型中,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。反向传播法(Backpropagation ,缩写为BP),是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法,该方法对网络中所有权重计算损失函数的梯度,这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。假设我们有这样一个网络层:
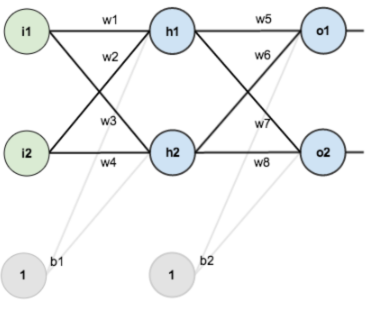
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。现在对他们赋上初值,如下图: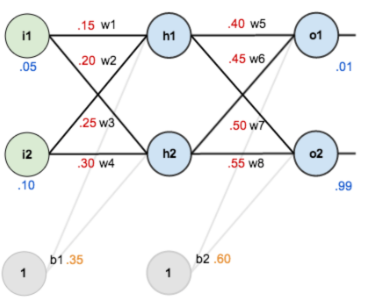
其中,输入数据 i1=0.05,i2=0.10; 输出数据 o1=0.01,o2=0.99;初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30,w5=0.40,w6=0.45,w7=0.50,w8=0.55;截距b1=0.35,b2=0.60。目标:给出输入数据i1,i2(0.05和0.10),使输出尽可
能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向传播
1.输入层——>隐含层:
计算神经元h1的输入加权和: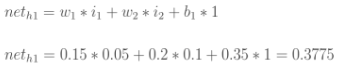
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):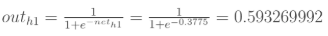
同理,可计算出神经元h2的输出o2: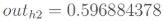
2.隐含层——>输出层:
计算输出层神经元o1和o2的值: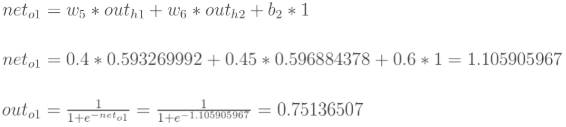
同理计算out
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1.计算总误差
总误差:(square error)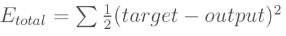
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和: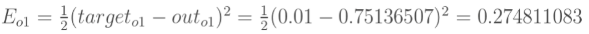
同理可以计算E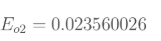
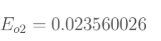 总误差
总误差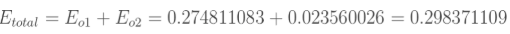
2.隐含层——>输出层的权值更新:以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)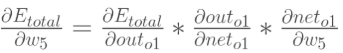
下面的图可以更直观的看清楚误差是怎样反向传播的: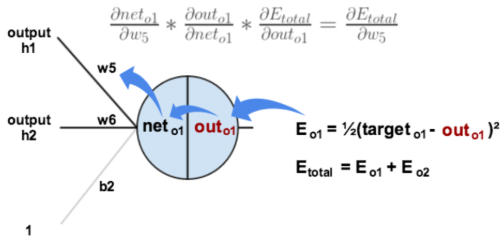
来分别计算每个式子的值:
(1)计算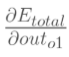
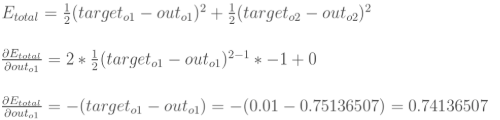
(2)计算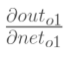

(3)计算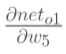
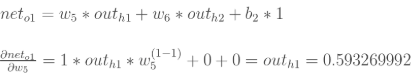
(4)最后三者相乘
这样我们就计算出整体误差E(total)对w的偏导值。回过头来再看看上面的公式,我们发现:
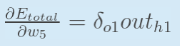 最后我们来更新w的值:
最后我们来更新w的值: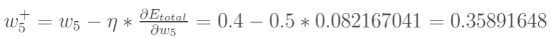
其中,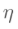 是学习速率,这里我们取0.5。同理,可更新w,w,w:
是学习速率,这里我们取0.5。同理,可更新w,w,w:

3.隐含层——>隐含层的权值更新:
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o)—>net(o)—->w,但是在隐含层之间的权值更新时,是out(h)—>net(h)—>w,而out(h1)会接受E(o)和E(o)两个地方传来的误差,所以这个地方两个都要计算。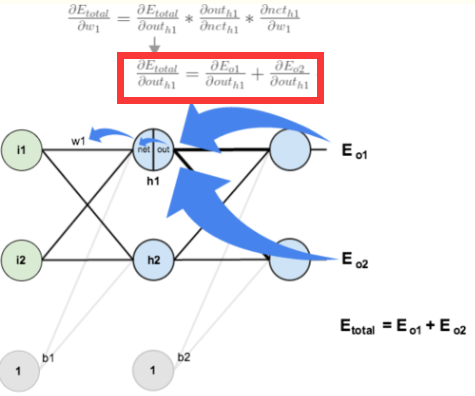
(1)计算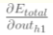
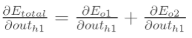
先计算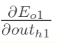
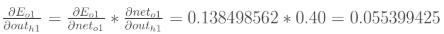
同理计算出: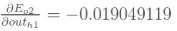
两者相加得到总值: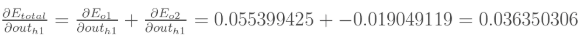
再计算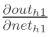

再计算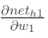
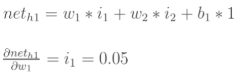
最后,三者相乘:
最后,更新w1的权值: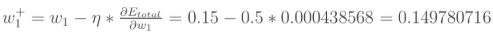
同理,额可更新w2,w3,w4的权值: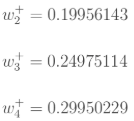
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差由0.29837110降至0.291027924。迭代10000次后总误差为0.000035085,输出为[0.015912196,0.984065734] (原输入为[0.01,0.99]),证明效果还是不错的,完整代码见博客
6.多层神经网络(深度学习)
尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便。我们延续两层神经网络的方式来设计一个多层神经网络。在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图。
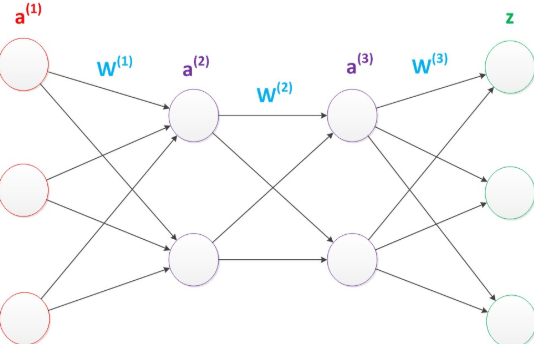
多层神经网络中,输出也是按照一层一层的方式来计算。从最外面的层开始,算出所有单元的值以后,再继续计算更深一层。只有当前层所有单元的值都计算完毕以后,才会算下一层。有点像计算向前不断推进的感觉。所以这个过程叫做“正向传播”。首先我们看第一张图,可以看出W(1)中有6个参数,W(2)中有4个参数,W(3)中有6个参数,所以整个神经网络中的参数有16个(这里我们不考虑偏置节点,下同)。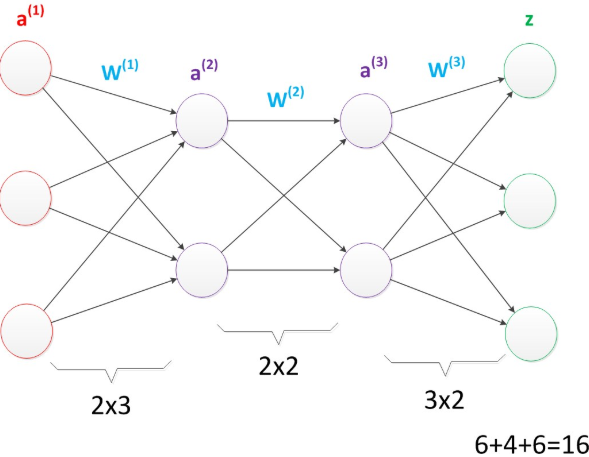
假设我们将中间层的节点数做一下调整。第一个中间层改为3个单元,第二个中间层改为4个单元。经过调整以后,整个网络的参数变成了33个。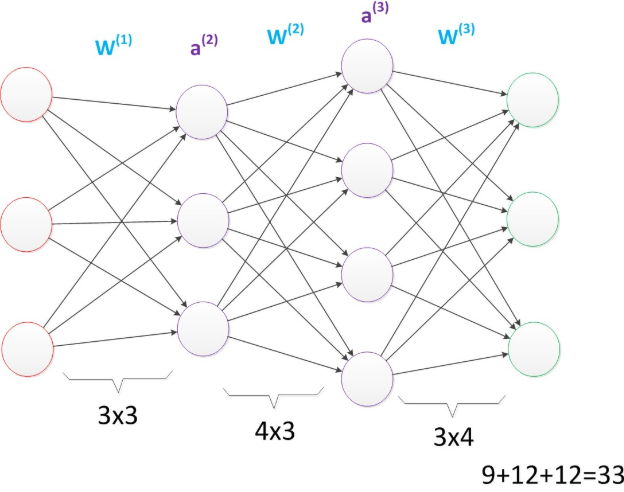
虽然层数保持不变,但是第二个神经网络的参数数量却是第一个神经网络的接近两倍之多,从而带来了更好的表示(represention)能力。在参数一致的情况下,我们也可以获得一个“更深”的网络。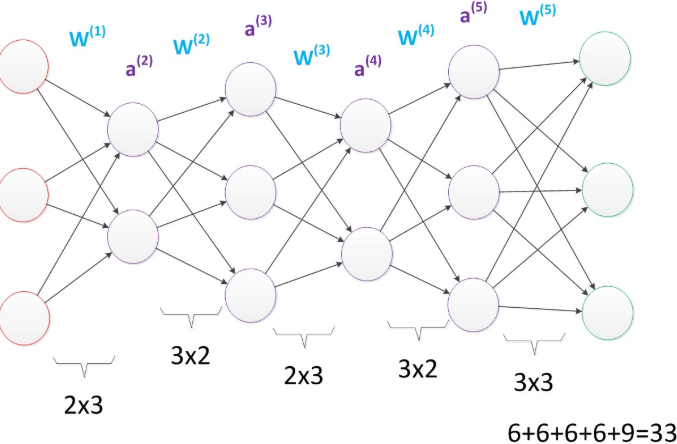
上图的网络中,虽然参数数量仍然是33,但却有4个中间层,是原来层数的接近两倍。这意味着一样的参数数量,可以用更深的层次去表达。增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。更强的函数模拟能力是由于随着层数的增加,整个网络的参数就越多。而神经网络其实本质就是模拟特征与目标之间的真实关系函数的方法,更多的参数意味着其模拟的函数可以更加的复杂,可以有更多的容量(capcity)去拟合真正的关系。通过研究发现,在参数数量一样的情况下,更深的网络往往具有比浅层的网络更好的识别效率。
7.多层神经网络的训练
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
以上1~7部分内容整理来自博客《神经网络浅讲:从神经元到深度学习》
8.用代码实现神经网络算法
(1)简单代码
首先是最简单的神经网络模型,示意图如下所示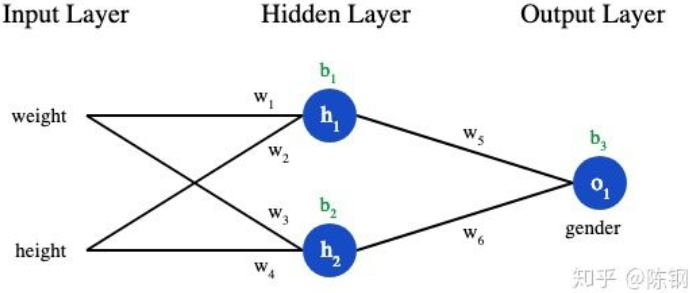
对应的代码块如下所示,这个代码就实现编码一个神经元
# -*- coding: utf-8 -*-"""@author: Haojie Shu@time:@description:"""import numpy as npdef sigmoid(para1): # 定义激活函数sigmoidreturn 1 / (1 + np.exp(-para1))class Neuron:def __init__(self, weights, bias):self.weights = weightsself.bias = biasdef first_forward(self, inputs):total = np.dot(self.weights, inputs) + self.biasreturn sigmoid(total)class OurNeuralNetwork:def __init__(self):weights = np.array([0, 1])bias = 0self.h1 = Neuron(weights, bias)self.h2 = Neuron(weights, bias)self.o1 = Neuron(weights, bias)def second_forward(self, para2):out_h1 = self.h1.first_forward(para2)out_h2 = self.h2.first_forward(para2)out_o1 = self.o1.first_forward(np.array([out_h1, out_h2]))return out_o1'''程序的执行顺序如下1.首先执行OurNeuralNetwork类的__init__方法2.然后执行Neuron类的__init__方法,注意这个时候是不执行first_forward方法的3.network对象调用second_forward方法4.second_forward方法里的self.h1对象调用first_forward方法,将参数para2传给inputs可以得out_h1=sigmoid([0,1]*[2,3]+0)=sigmoid(3)out_h2=sigmoid([0,1]*[2,3]+0)=sigmoid(3)out_o1=[0,1]*[sigmoid(3),sigmoid(3)]+0=sigmoid(sigmoid(3))'''network = OurNeuralNetwork()x = np.array([2, 3])print(network.second_forward(x)) # 0.7216325609518421
(2)预测性别
有了这个代码的预备知识后,就可以干活了,现在有这样的数据: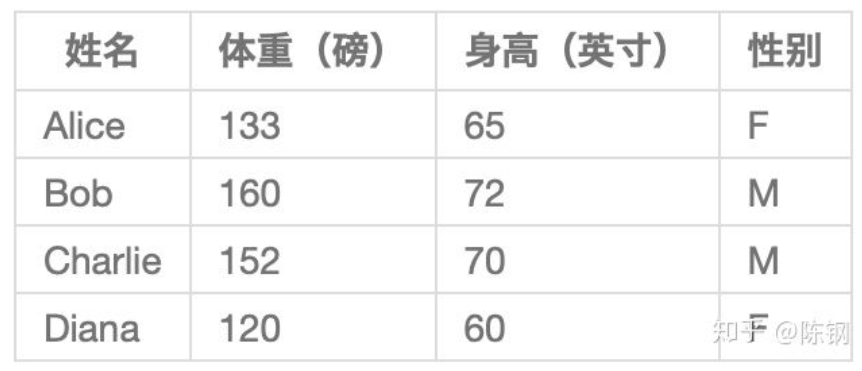
接下来我们用这个数据来训练神经网络的权重和截距项,从而可以根据身高体重预测性别: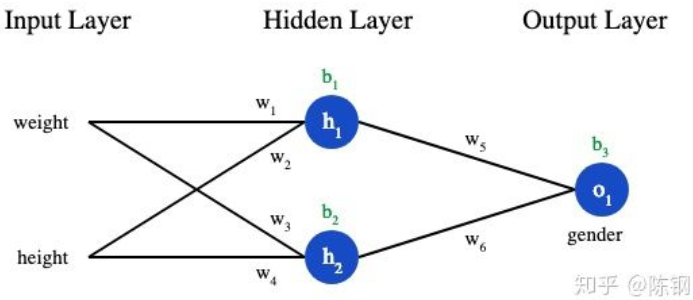
用0和1分别表示男性(M)和女性(F),这里随意选取了135和66来标准化数据,通常会使用平均值,转化后的数据如下所示。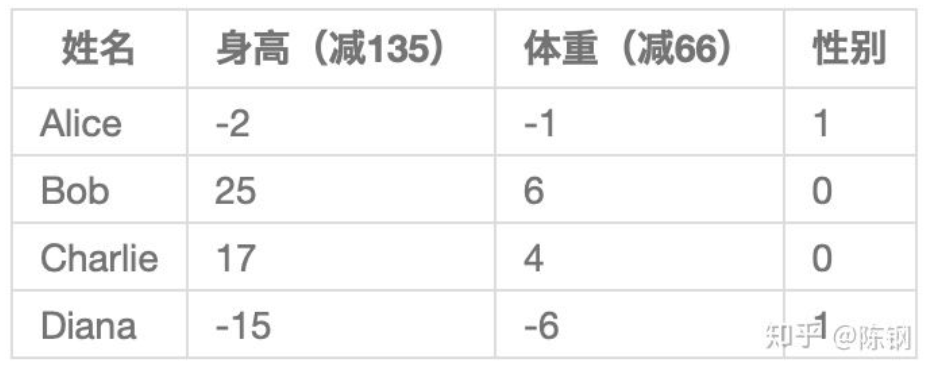
(3)损失函数
在训练网络之前,我们需要量化当前的网络是『好』还是『坏』,从而可以寻找更好的网络。这就是定义损失的目的。我们在这里用平均方差(MSE)损失,它的公式为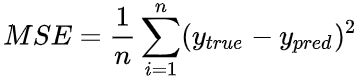
假设我们的网络总是输出0,换言之就是认为所有人都是男性,也即下面的y=0。损失如何?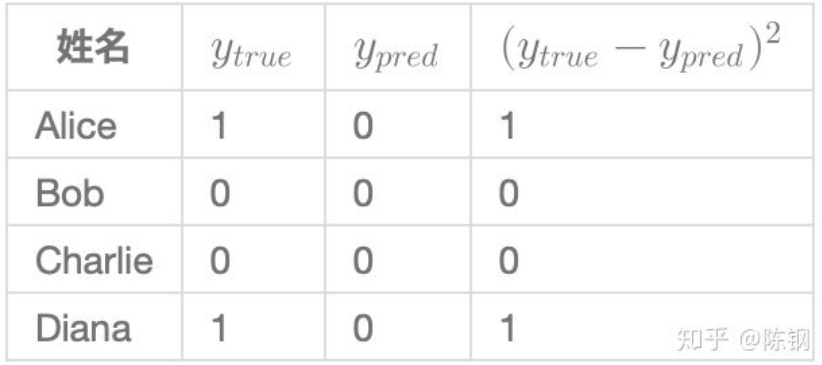
此时的损失可以表示为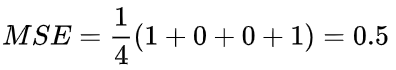
用代码来定义损失函数
import numpy as npdef mse_loss(y_true, y_pred):return ((y_true - y_pred) ** 2).mean()y_true = np.array([1, 0, 0, 1])y_pred = np.array([0, 0, 0, 0])print(mse_loss(y_true, y_pred)) # 0.5
现在目标明确了,就是要减少损失函数的值,如何减少呢?为了简化问题,假设我们的数据集中只有Alice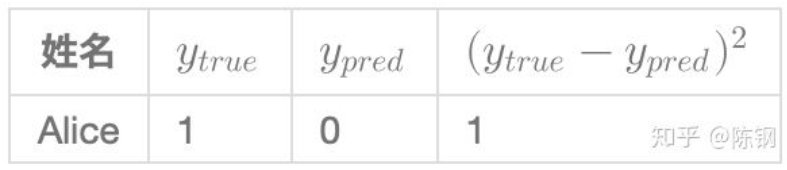
那均方差损失就只是Alice的方差:
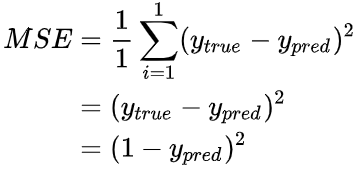
我们给网络标上权重和截距项: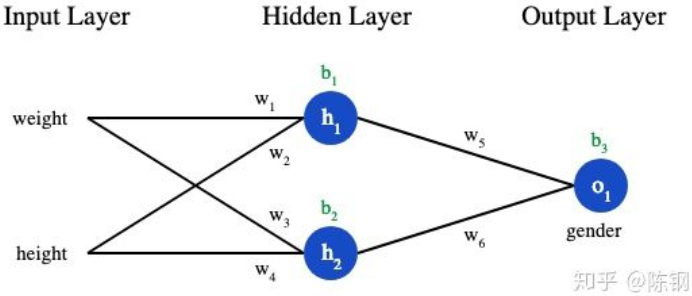
假设我们要优化 w ,当我们改变 w 时,损失 L 会怎么变化?这里参数w 对L的影响可以表达为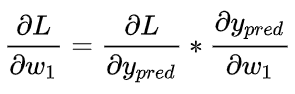
这里的y表示预测值,其实就是模型的输出值,前面已经提到了,损失可以表示为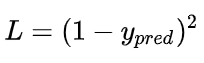
所以我们可以计算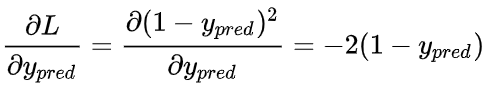
再来计算y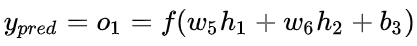
由于w1只会影响h1不会影响h2,所以:

再来计算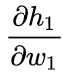 ,也可以这样做
,也可以这样做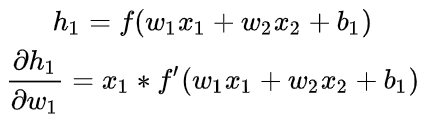
在这里, x1是身高,x2是体重,这里有:
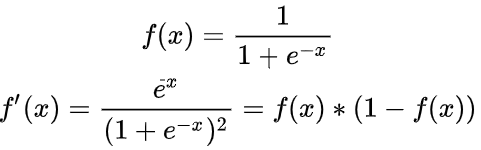
我们已经把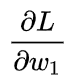 分解成了几个我们能计算的部分:
分解成了几个我们能计算的部分: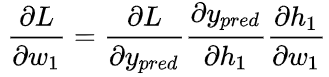
这就是前面所说的反向传播算法,有了这些预备知识后,我们就可以来实现一个完备的神经网络算法代码了
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def derive_sigmoid(x):fx = sigmoid(x)return fx * (1 - fx)def mse_loss(y_true, y_pre):return ((y_true - y_pre) ** 2).mean()class OurNeuralNetwork:def __init__(self):"""random.normal():生成高斯分布的概率密度随机数1.由于没有指定参数,取0的可能性最大,往两边取的可能性逐渐降低2.每次w1,w2...的值和前一次的值很可能是不一致的"""self.w1 = np.random.normal()self.w2 = np.random.normal()self.w3 = np.random.normal()self.w4 = np.random.normal()self.w5 = np.random.normal()self.w6 = np.random.normal()self.b1 = np.random.normal()self.b2 = np.random.normal()self.b3 = np.random.normal()def feed_forward(self, x):h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)return o1def train(self, data, all_y_trues): # data和all_y_trues分别是输入和输出learn_rate = 0.1epochs = 1000'''a = [1,2,3], b = [4,5,6], c = [4,5,6,7,8]zip(a,b) # 打包为元组的列表>>>[(1, 4), (2, 5), (3, 6)]zip(a,c) # 元素个数与最短的列表一致>>>[(1, 4), (2, 5), (3, 6)]zip:Return a list of tuples>>>[(array([-2, -1]), 1), (array([25, 6]), 0), (array([17, 4]), 0), (array([-15, -6]), 1)]'''zipped_data = zip(data, all_y_trues)for epoch in range(epochs):for x, y_true in zipped_data:sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1h1 = sigmoid(sum_h1)sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2h2 = sigmoid(sum_h2)sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3o1 = sigmoid(sum_o1) # 输出总和y_pre = o1partial_y_pre = -2 * (y_true - y_pre) # 计算偏导,相当于计算了反向传播的最后一层,输出值对输入值的偏导# Neuron o1d_ypred_d_w5 = h1 * derive_sigmoid(sum_o1) # 计算o1对w5的偏导d_ypred_d_w6 = h2 * derive_sigmoid(sum_o1)d_ypred_d_b3 = derive_sigmoid(sum_o1)d_ypred_d_h1 = self.w5 * derive_sigmoid(sum_o1)d_ypred_d_h2 = self.w6 * derive_sigmoid(sum_o1)# Neuron h1d_h1_d_w1 = x[0] * derive_sigmoid(sum_h1) # 计算h1对w1的偏导d_h1_d_w2 = x[1] * derive_sigmoid(sum_h1)d_h1_d_b1 = derive_sigmoid(sum_h1)# Neuron h2d_h2_d_w3 = x[0] * derive_sigmoid(sum_h2) # 计算h2对w3的偏导d_h2_d_w4 = x[1] * derive_sigmoid(sum_h2)d_h2_d_b2 = derive_sigmoid(sum_h2)'''1.计算了对w1的偏导后, 不断进行迭代 w1 = w1 - rate * 偏导2.w1的值相当于进行了一次更新,在第二次for循环的时候会发生变化'''self.w1 -= learn_rate * partial_y_pre * d_ypred_d_h1 * d_h1_d_w1self.w2 -= learn_rate * partial_y_pre * d_ypred_d_h1 * d_h1_d_w2self.b1 -= learn_rate * partial_y_pre * d_ypred_d_h1 * d_h1_d_b1self.w3 -= learn_rate * partial_y_pre * d_ypred_d_h2 * d_h2_d_w3self.w4 -= learn_rate * partial_y_pre * d_ypred_d_h2 * d_h2_d_w4self.b2 -= learn_rate * partial_y_pre * d_ypred_d_h2 * d_h2_d_b2self.w5 -= learn_rate * partial_y_pre * d_ypred_d_w5self.w6 -= learn_rate * partial_y_pre * d_ypred_d_w6self.b3 -= learn_rate * partial_y_pre * d_ypred_d_b3if epoch % 10 == 0:'''feed_forward没有参数,因为是np.apply_along_axis函数的原因def f(a):return (a[0] + a[1]) * 2b = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])c = np.apply_along_axis(f, 0, b) # (1+5)*2=12 (2+6)*2=16依次类推d = np.apply_along_axis(f, 1, b) # (1+2)*2=6 (5+6)*2=22依次类推print c, d'''y_pre = np.apply_along_axis(self.feed_forward, 1, data)loss = mse_loss(all_y_trues, y_pre)print("Epoch %d loss: %.3f" % (epoch, loss))input_data = np.array([[-2, -1], # Alice[25, 6], # Bob[17, 4], # Charlie[-15, -6],])y_trues = np.array([1, 0, 0, 1])network = OurNeuralNetwork() # 初始化network对象,并实现类的__init__方法network.train(input_data, y_trues)
将输出结果绘制成图,结果如下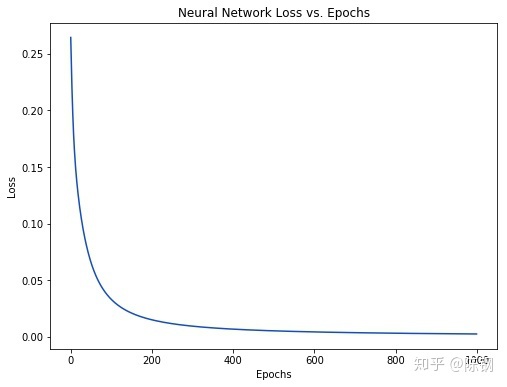
(为什么每一次迭代之后,损失loss都会减少呢?留在下一节当中说明)
这里执行完network.train(input_data, y_trues)之后,相当于对所有的参数进行了1000次的迭代,然后我们取最后一次的参数,作为神经网络的权重值。有了这个权重值之后,就可以进行预测了。
emily = np.array([-7, -3]) # 128 pounds, 63 inchesfrank = np.array([20, 2]) # 155 pounds, 68 inchesprint("Emily: %.3f" % network.feedforward(emily)) # 0.951 - Fprint("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M
本代码部分参考知乎《用Python从头实现一个神经网络》
BP神经网络在前面其实已经有很多介绍了,这里只准备搞清楚两件事情。第一,为什么每次反向传播后,误差值就会减少?第二,如何用sklearn来实现BP神经网络
9. BP神经网络误差怎么减少的?
在上一节的代码中,我们有这么一幅图,在每一次迭代之后,损失值loss就会减少,这是为什么呢?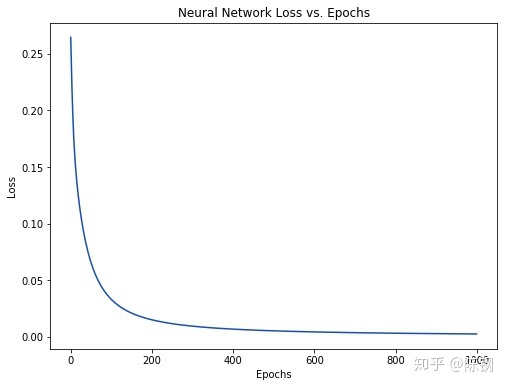
在神经网络中,我们用权值得到的输出f(x)=kx+kx+…+kx和最终的输出g(x)之间,还存在sigmoid函数的关系
g(x)=sigmoid(f(x)),现在来好好研究一下sigmoid函数,它的表达式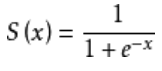
而S’(x)则可以表达为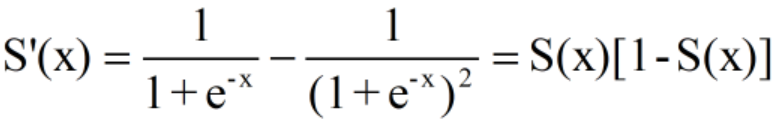
它们的函数图像分别为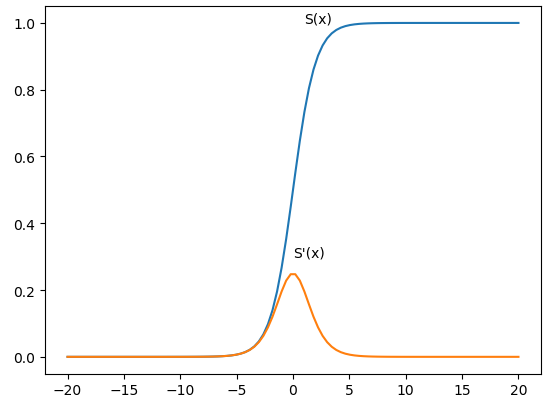
附画图代码
import numpy as npimport matplotlib.pyplot as pltdef sigmoid(para1): # 定义激活函数sigmoidreturn 1 / (1 + np.exp(-para1))def derive_sigmoid(x):fx = sigmoid(x)return fx * (1 - fx)x = np.linspace(-20, 20, num=100)y = sigmoid(x)z = derive_sigmoid(x)plt.plot(x, y)plt.text(x=1, y=1, s='S(x)')plt.plot(x, z)plt.text(x=0, y=0.3, s="S'(x)")plt.show()
为了搞清楚误差到底是怎么减少的,还是需要对前面反向传播的过程进行回顾,下图是神经网络图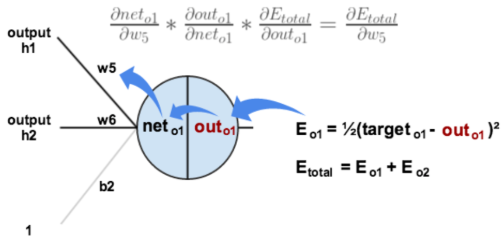
(1)计算总误差E
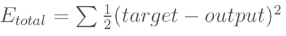
(2)权值更新:以w5为例,想知道w5对总误差产生了多少影响,可以用如下的表达式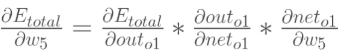
然后对w5进行更新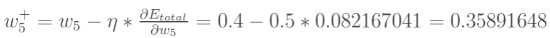
这里的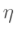 是学习速率,这里的反向传播找最小loss的过程其实就相当于一个梯度下降的过程,不断更新权值使loss不断减少,具体可以看本篇
是学习速率,这里的反向传播找最小loss的过程其实就相当于一个梯度下降的过程,不断更新权值使loss不断减少,具体可以看本篇
二、多层感知器(MLP)
1.MLP的定义
维基百科:多层感知器(Multilayer Perceptron,缩写MLP)是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元,一种被称为反向传播算法的监督学习方法常被用来训练MLP。MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
2.MLP和BP神经网络的区别
前面已经有说过,再来说一下,首先要明白,什么是感知器?这个需要和神经元模型对比起来说,一个典型的神经元模型图如下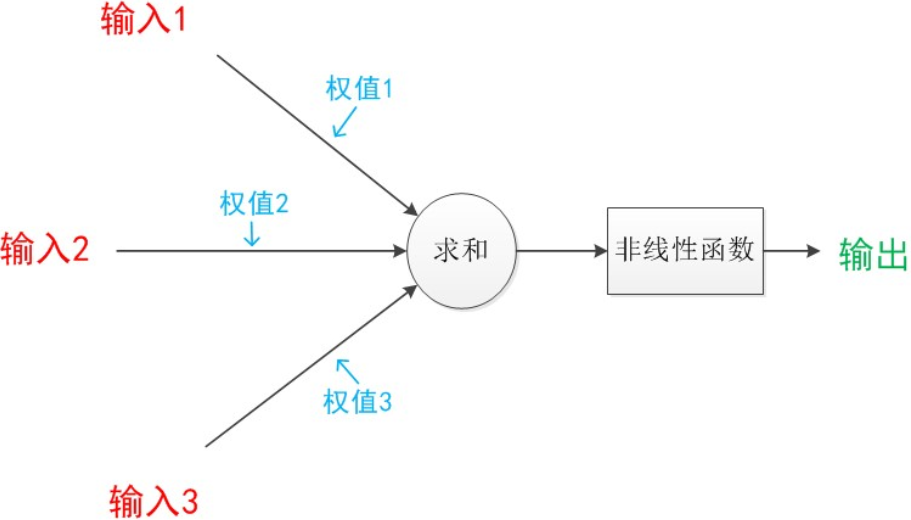
而感知器则是在原来神经元模型的“输入”位置添加神经元节点,标志其为“输入单元”,其余不变。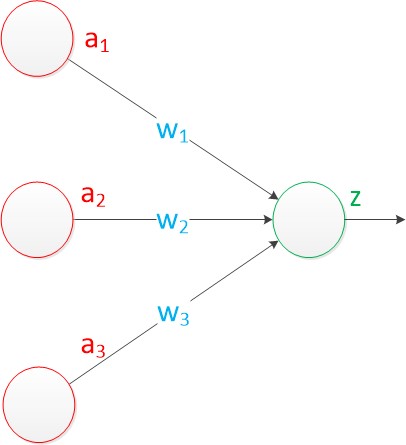
这样的神经网络称之为单层感知器,而多层感知器(MLP)就是在单层神经网络上增加一层中间层。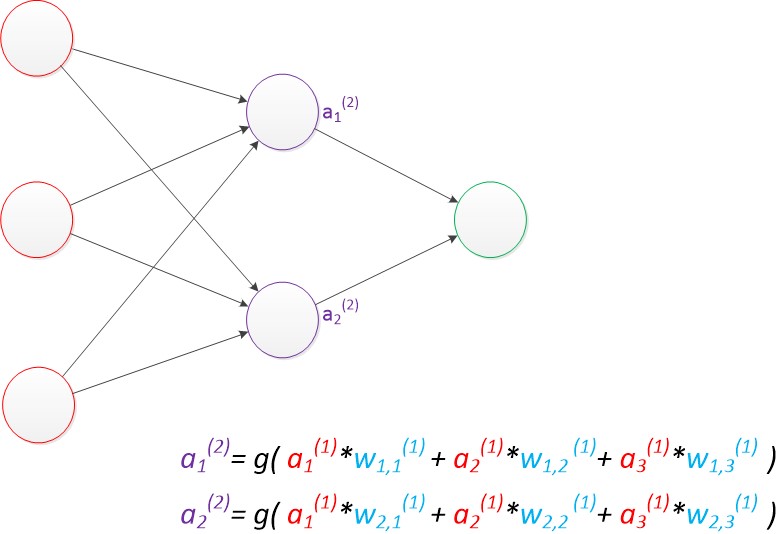
首先说MLP和神经网络的区别,请注意这两者是同一个东西, 前面的博客在文章最后对这两者进行了概括,“MLP这个术语属于历史遗留的产物。现在我们一般就说神经网络,以及深度神经网络,前者代表带一个隐藏层的两层神经网络,也是EasyPR目前使用的识别网络,后者指深度学习的网络。值得注意的是,虽然叫“多层”,MLP一般都指的是两层(带一个隐藏层的)神经网络”。两层神经网络和多层神经一个很显著的差别是,两层神经网络的激活函数是sigmoid,而多层神经网络的激活函数是ReLU,具体可以看这个图。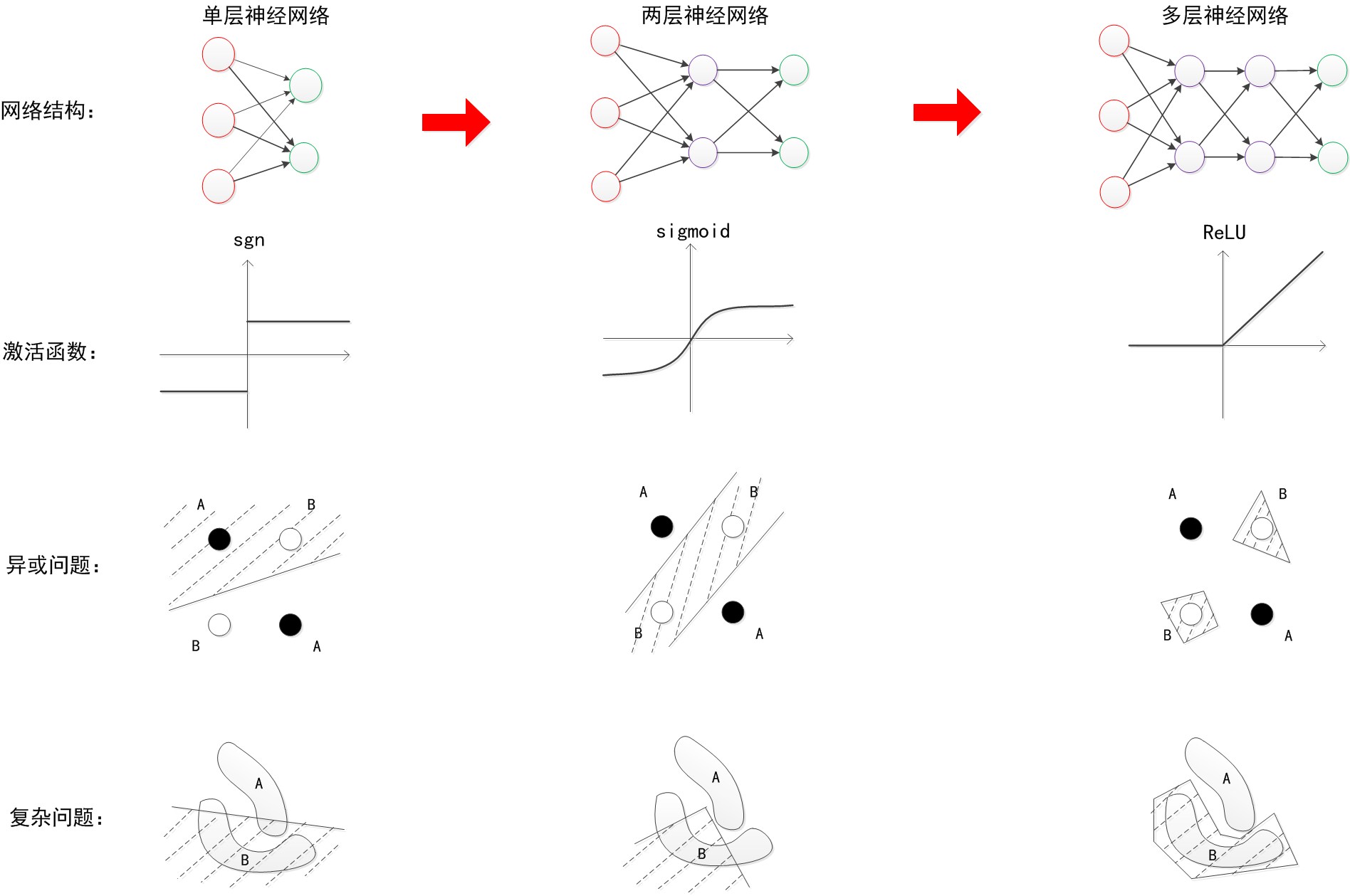
最后再来说BP神经网络和MLP的区别,在维基百科中并没有BP神经网络这一个词条,而对反向传播则有如下定义:“反向传播是【误差反向传播】的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法”,所以BP神经网络其实就是指的在神经网络中采用反向传播法来进行训练。最后总结一下 MLP= 神经网络(两层),BP神经网络(实际并没有)=采用BP算法进行训练的神经网络。
3.用sklearn实现MLP
MLP算法既可以用于分类,也可以用于回归,二者在代码实现上区别不是很大,这里只看用于回归的情形
# -*- coding: utf-8 -*-from sklearn.datasets import load_bostonfrom sklearn.model_selection import train_test_splitfrom sklearn import preprocessingfrom sklearn.neural_network import MLPRegressorimport matplotlib.pyplot as pltboston = load_boston()x = boston.datay = boston.target # 波士顿房价,其中输入x有13个维度,输出y只有1个维度(房价),数据集共506个样本# random_state:保证分离后训练和测试的数据是固定的,参数具体多少不重要,会有自己的选择逻辑,默认是不固定的,就会每次train和test不一样train_x, test_x, train_y, test_y = train_test_split(x, y, train_size=0.8, random_state=50)# StandardScaler():数据预处理,在默认情况下StandardScaler就是减去均值,然后除以标准差# 数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性.# 简单例子,一个百分制的变量与一个5分值的变量在一起怎么比较,只有通过数据标准化,都把它们标准到同一个标准时才具有可比性.# 一般标准化采用的是Z标准化,即均值为0方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择.# 参考http://sofasofa.io/forum_main_post.php?postid=1001487和https://zhidao.baidu.com/question/271321019.htmlstandard_scalar = preprocessing.StandardScaler()# fit_transform:先拟合数据,然后转化它将其转化为标准形式train_x = standard_scalar.fit_transform(train_x)# transform:找中心和缩放等实现标准化,参考https://blog.csdn.net/quiet_girl/article/details/72517053test_x = standard_scalar.transform(test_x)# reshape(-1,1):将数据转化为1列,前面的-1是指未给定的train_y = standard_scalar.fit_transform(train_y.reshape(-1, 1))test_y = standard_scalar.transform(test_y.reshape(-1, 1))'''1.solver:权重更新的方法,这里solver有三个参数lbfgs,sgd,adam, 他们都是采用反向传播的方法,只不过反向传播的实现方式不同拿sgd随机梯度下降来说,在深度学习中,权值可能有几万个,如果采用我们常规的梯度下降,那么要每次反向传播要更新的权值有几万个,这样哪怕只反向传播一次,它的计算量都大得吓人,而随机梯度下降从几万个权值里选择部分权值进行更新,这样每次反向传播的速度就能快很多2.hidden_layer_sizes隐藏层的网络数,这里表示有3个隐藏层,每层的数量都是203.activation:激活函数,有‘identity’, ‘logistic’, ‘tanh’, ‘relu’四个4.alpha:L2正则化系数,具体什么是L2正则化可以后面再了解'''model_mlp = MLPRegressor(solver='lbfgs', hidden_layer_sizes=(20, 20, 20), activation='tanh', random_state=1, alpha=0.01)model_mlp.fit(train_x, train_y.ravel()) # 用输入和输出来拟合出一个模型mlp_score = model_mlp.score(test_x, test_y.ravel()) # 模型评分mlp_params = model_mlp.get_params()print 'model score:', mlp_score, 'model params:', mlp_paramsmlp_predict = model_mlp.predict(test_x) # 用模型来预测plt.plot(range(len(test_y)), test_y, 'b')plt.plot(range(len(mlp_predict)), mlp_predict, 'r')plt.title('blue:real, red: predict')plt.show()
打印结果
model score: 0.872344734919 model params: {'beta_1': 0.9, 'warm_start': False, 'beta_2': 0.999, 'shuffle': True, 'verbose': False, 'nesterovs_momentum': True, 'hidden_layer_sizes': (20, 20, 20), 'epsilon': 1e-08, 'activation': 'tanh', 'max_iter': 200, 'batch_size': 'auto', 'power_t': 0.5, 'random_state': 1, 'learning_rate_init': 0.001, 'tol': 0.0001, 'validation_fraction': 0.1, 'alpha': 0.01, 'solver': 'lbfgs', 'momentum': 0.9, 'learning_rate': 'constant', 'early_stopping': False}
绘图的图案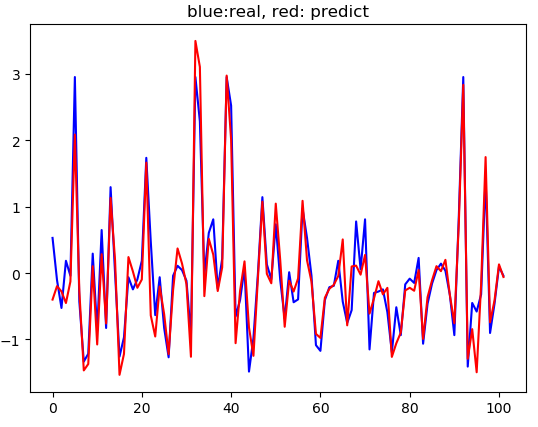

若有收获,就点个赞吧
0 人点赞
