由于XgBoost算法和GBDT算法都是采用的CART回归树(XgBoost有可能还会有其他简单模型),需要对CART回归树有一个简单的了解。
1.回归树
(1)简单例子
首先看一个具体的例子,对一群样本(5个人)我们要判断ta是否玩电脑游戏,可以开始对这群人用多颗决策树进行一个简单的分类,对每个类别分配不同的权重项,正数代表这个人愿意去玩电脑游戏,负数代表这个人不愿意去玩电脑游戏。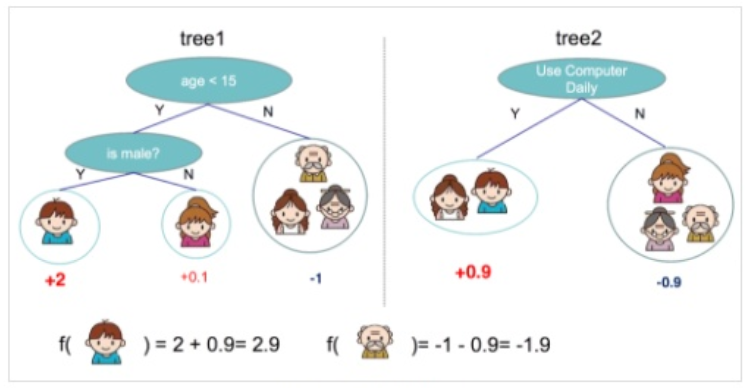
在第一颗树中,小男孩玩游戏的得分是2,第二颗树中的得分是0.9,那么整体下来小男孩的得分就是2.9。
(2)小结
回归树有以下两个特点:
(1)决策规则和决策树一样
(2)每个叶子节点都包含了一个权重,也称之为分数
2.XgBoost算法思想
f(x)表示第i个样本落在第k树中的权重,那么第i个样本的预测值为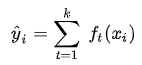
模型可以理解为最开始第一棵树是0,然后往里面加一颗树(用f(x)来表示),这样第二棵树就表示为第一棵树和新表达式之和……到第t轮之后,模型就可以用t-1轮的模型预测,再加上第t轮新加的树来表示。
XgBoost是一个由k个基模型组成的加法运算式,其中f为第k个基模型,i表示第i个样本,算法的原始目标函数为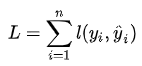
n表示样本的个数,k表示集成模型总共有k颗树。由于树越多,模型的表达能力越强,可能会产生过拟合,为了抑制过拟合,可以加上惩罚项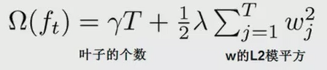
最终的损失函数就变为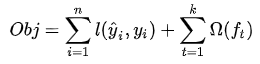
损失函数表达式可以进行一定的转换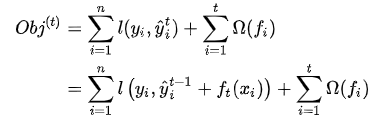
怎么理解这个式子呢,和PPR中的残差概念有点类似,例如这里某个样本的真实值y=100,上一轮的预测值y是90,两个值之间的差值10就是残差,f(x)就是为了来减少这个残差的。求最优化目标函数,就相当于求解f(x) 。
3.算法求解
(1)泰勒展开
根据泰勒公式我们把函数f(x+△x)在点x处进行泰勒的二阶展开,可得到如下等式:
为什么要变成二阶展开,而不是三阶四阶呢?二阶信息能让梯度收敛更快更准确,因为一阶导指引梯度方向,二阶导指引梯度方向如何变化
在上面的式子中,可以把残差y,y看作是泰勒展开的x,把后面的f(x)看作是△x,那么前面的损失函数可以转换为如下表达式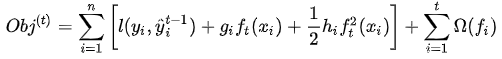
其中gi为损失函数的一阶导,hi为损失函数的二阶导(都是对y求导)。以平方损失函数为例: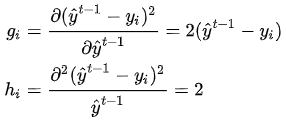
由于在第  步时
步时  其实是一个已知的值(例如前面例子中的10),所以
其实是一个已知的值(例如前面例子中的10),所以  是一个常数,其对函数的优化不会产生影响,因此目标函数可以写成:
是一个常数,其对函数的优化不会产生影响,因此目标函数可以写成: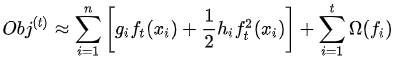
(2)目标转换
前面讨论的是按照样本进行遍历来求损失函数,下面按照树的结构来求损失函数。设q(xi)来表示样本xi落在树叶的位置,这里q(xi)∈(1,2,…,T),如下图所示
落在第j个节点的样本的个数为
目标函数可以写成: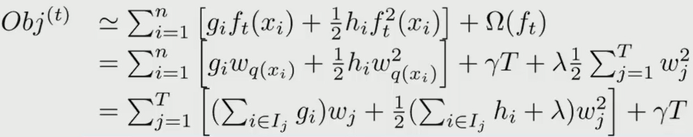
相当于之前求损失函数是对样本进行遍历,现在改为按照叶子节点进行遍历,看每个叶子节点共有多少个样本。为简化表达式,定义
那么损失函数为: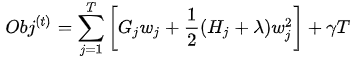
对损失函数求导,可以得到损失函数的最小值,为: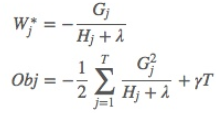
(3)算法实例
下图是一个具体例子
按照上面的公式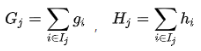
因此损失函数可以写为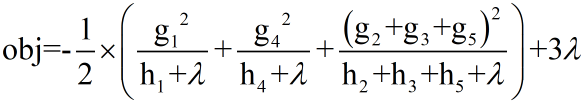
Obj越小,说明预测和目标的差越小,也说明这个树的结构越好

若有收获,就点个赞吧
0 人点赞
