1.SVM算法
在机器学习中,SVM是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法建立一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。 除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。当数据未被标记时,不能进行监督学习,需要用非监督学习,它会尝试找出数据到簇的自然聚类,并将新数据映射到这些已形成的簇。将支持向量机改进的聚类算法被称为支持向量聚类,当数据未被标记或者仅一些数据被标记时,支持向量聚类经常在工业应用中用作分类步骤的预处理。
2.SVM算法通俗说明
在桌子上有规律放了两种颜色的球,用一根棍分开它们,要求:即便再放更多球之后,仍然能将它们分开。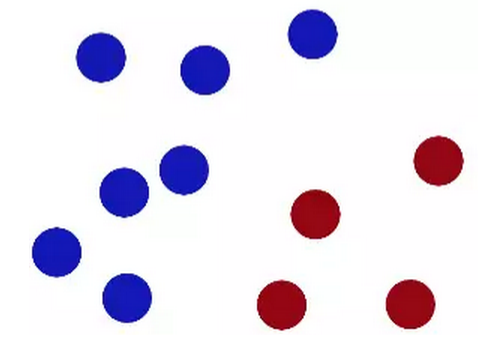
第一次放成如下图这样,看起来似乎解决问题了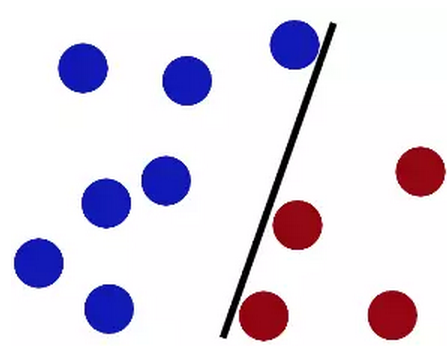
但增加一个球之后,似乎上面的放法就有问题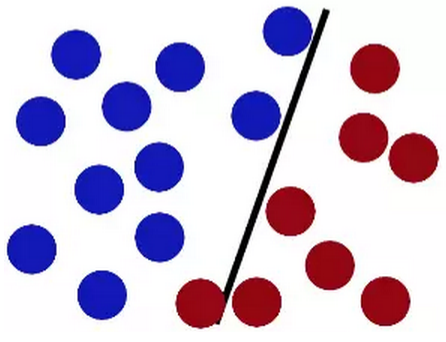
这时我们对之前的方法稍微进行了调整,看起来即使放了更多的球,新的棍子仍然是一个好的分界线。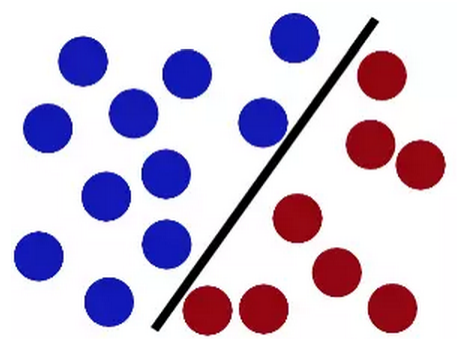
这就是SVM算法要解决的问题,试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
但即便如此,面对下图中的红蓝两种颜色的球,还是束手无策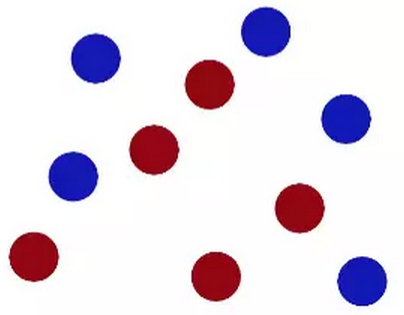
怎么办呢?将桌子一拍,球飞到空中。然后抓起一张纸,插到了两种球的中间。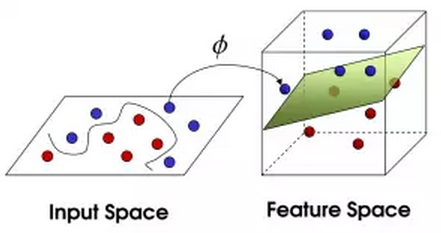
现在这些球被一条曲线给分开了
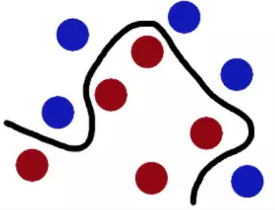
最后总结一下这个过程,球可以看作是数据源(data),棍子可以看作是分类器(classifier), 最大间隙trick叫作最优化(optimization), 拍桌子看作是建立核函数(kernelling)的过程, 那张纸可以看作是超平面(hyperplane)。
3.SVM算法的数学推导
SVM要解决的问题很简单,求出最大的margin,其中margin=2d,并求出分离平面的表达式w·x+b=0,也就是确定w和b的值。先来看怎么求margin,这是一个简单的svm示意图,在这里分离平面和两个支持平面分别被表示为w·x+b=0,w·x+b=1和w·x+b=-1,这是为什么呢?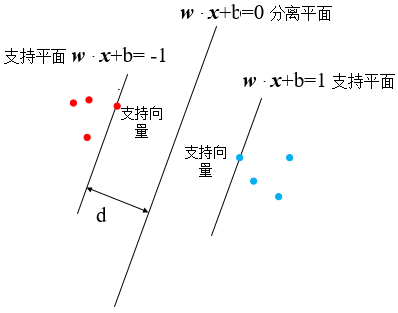
在搞清楚为什么前,先回顾两个初高中数学的背景知识
1)任何平面都可以用w·x+b=0来表述吗?如果不可以,这个公式岂不是有特殊性?
注意这里的w和x 这都是向量,假设这是一个二维向量,w=(w,w),x =(x,x)按照两个向量作内积的公式,我们有w·x+w·x+b=0,这就是一个一般的二维平面上的直线方程了。同样的,对多维空间里,同样可以表示为w·x+w·x+…+w·x+b=0
2)这里的w这写成了向量的形式,示意图如下所示。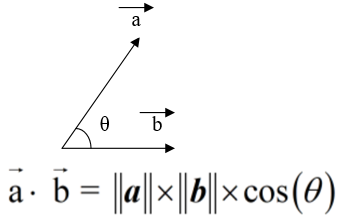
两条平行直线的距离:若两直线分别为Ax+By+C1=0和Ax+By+C2=0
,则距离为|C1-C2|/√ (A^2+B^2)
2.支持平面:为什么左右两边的支持平面分别写成了w·x+b=1和w·x+b=-1?在上图中,对于所有蓝色和红色的点,它们到分离平面的距离都是要大于或等于d的,用公式可以表示成: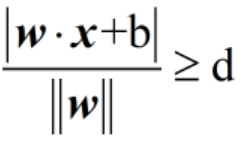
来考虑去绝对值的问题:由于红色和蓝色的点分别位于分离平面的两侧,因此必定有一侧的w·x+b≤0,而另一侧的w·x+b≥0
对这个不等式稍微作一下变化,将不等式右边的d移到分母上,则有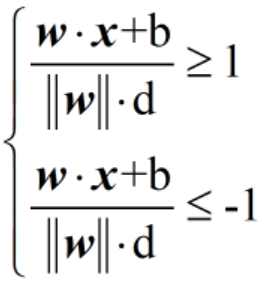
仔细观察这里的分母,||w||·d是一个实数,分子分母同时除以||w||·d,则有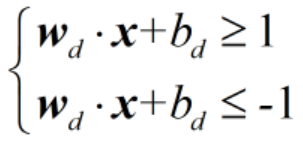
这里的w,b可以理解为经过压缩之后的变量,例如a=(2,4),b=(1,2),那么b就是a压缩一半之后的变量,这里w是可以由w表示的,只是我们要清楚二者之间的对应关系。这里我们上面两个不等式表示的是图中所有蓝色的点和红色的点,那么两个支持平面的方程就是w·x+b=1和w·x+b=-1,到了这里,我们再做一步,将分离平面w·x+b=0左右两侧同时除以||w||·d,除完之后就有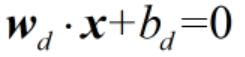
为了书写方便,我们将所有的小d去掉,就有了支持平面 的w·x+b=1和w·x+b=-1,以及分离平面的w·x+b=0。只是此时的w和d之前的w、d完全不一样而已,为什么可以换?想一想,ax+by+c=0,我们完全可以换成是aw+bv+c=0,只是换了一个字母而已。但注意:此时的分离平面w·x+b=0和之前的已经不是同一个了,两者之间存在倍数关系。
4.目标函数
前面提到过,SVM算法要做的就是求出最大的margin,由于margin=2d,因此求出最大的d即可。前面提到过的点到直线距离公式,这里点是哪个点,直线是哪一条直线?
很明显点是支持平面上的点,直线是分离平面,由点到直线的距离公式可以得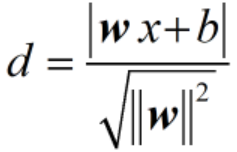
由于都是支持平面上的点,这里就有|w·x+b|=1,那么d=1/||w||,要求d的最大值,实际上是求||w||的最小值min ||w||,求这个最小值也可以转换为求如下这个表达式的最小值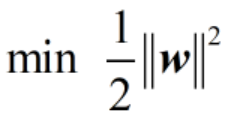
这个公式是有限定条件的,就是w·x+b=1和w·x+b=-1是支持平面。而如果它们是支持平面,则图中右边区域的任意一个蓝色样本点x_i,设其类别标签yi为1;图中左边区域的任意一个红色样本点xi,设其类别标签yi为-1
这里我们要怎么理解这个标签呢,我们可以把w·x+b≥1和w·x+b≤-1分别理解成是在三维空间z坐标为1和z坐标为-1的两个平面,也即对于蓝色的点它们的“z轴”坐标为1,对于红色的点它们的“z轴”坐标为-1,这些是所有的蓝色点和所有红色的点所具有的一个共性,而对于一个新的点,它如果属于蓝色或者红色中的一类,则必须要满足这个条件,即它的“z轴”坐标为1或者-1。这些用公式来表达就是:
综合起来可以得到表达式
这个就是我们求||w_||最小值的限定条件。终于我们找到了目标函数,以及这个目标函数的限定条件。
5.从原始问题到对偶问题
在这里我们要做的工作是求表达式
并且约束条件是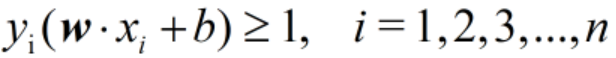
由于这个问题的特殊结构,可以通过拉格朗日对偶性(Lagrange Duality)变换到对偶变量的优化问题,即通过求解与原问题等价的对偶问题得到原始问题的最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题
。那什么是拉格朗日对偶性呢?简单来讲,通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier)α,定义拉格朗日函数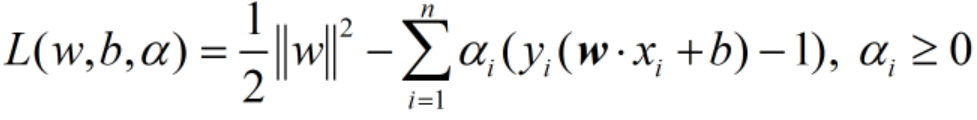
通过拉格朗日函数将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题。然后令

此时我们的目标函数转换成了求L(w,b,α)函数的最大值,为什么呢?容易验证,当某个约束条件不满足时,例如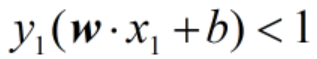
可以通过调整α的值,使得表达式的右边为正值,例如当α为+∞时,那么表达式L(w,b,α)减号的后边是一个无穷大的数,此时L(w,b,α)=+∞,那么此时θ(w)=+∞≠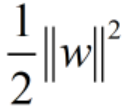 ,只有当右边所有的约束条件都满足时,即
,只有当右边所有的约束条件都满足时,即
这个表达式都成立。此时表达式L(w,b,α)减号的后边是非负数,那么它的最大值为 ,即最初要最小化的量,这这样我们就将最初要求的那个熟悉的目标函数
,即最初要最小化的量,这这样我们就将最初要求的那个熟悉的目标函数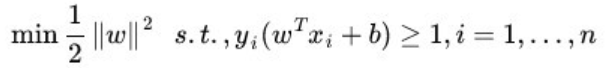
转化为求θ(w)的最小值,具体写出来,我们的优化函数变成了
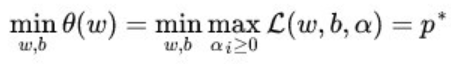
这里用p来表示这个问题的最优值,且和最初的问题是等价的。如果直接求解,那么一上来便得面对w和b两个参数,而α又是不等式约束,这个求解过程不好做。不妨把最小和最大的位置交换一下,变成: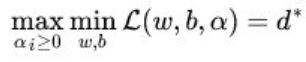
交换以后的新问题是原始问题的对偶问题,这个新问题的最优值用d来表示,而且有d≤p,在满足某些条件的情况下,这两者相等。这个时候就可以通过求解对偶问题来间接地求解原始问题。换言之,之所以从minmax的原始问题p,转化为maxmin的对偶问题d,一者因为d是p的近似解,二者,转化为对偶问题后,更容易求解,容易在哪里?可以看到对偶问题外层的优化目标参数是拉格朗日参数,然后通过求得的拉格朗日参数,间接得到我们最终要求的超平面的参数w。而原始问题外层的优化目标参数直接是w,无法直接去优化得到这个参数。
6.KKT条件
上文中提到“d≤p在满足某些条件的情况下,两者等价”,这所谓的“满足某些条件”可以简单理解为要满足KKT条件。什么是KTT条件呢?先铺垫一下,一般存在下面三种求最优化问题的
(1)一般的函数f(x)求解最优化问题,将问题表示为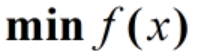
常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
(2)有等式约束的优化问题,即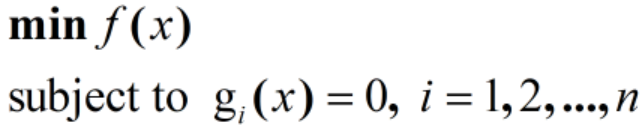
此时求最优化问题可以常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束g(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令导数为零,可以求得候选值集合,然后验证求得最优值。
(3)有不等式约束的优化问题,这类问题可表述为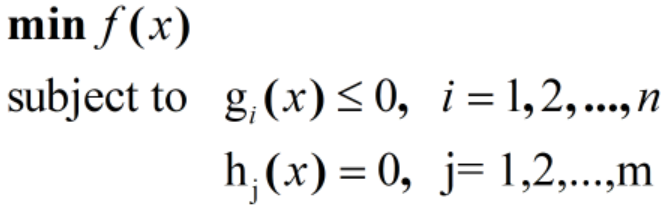
这类问题常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子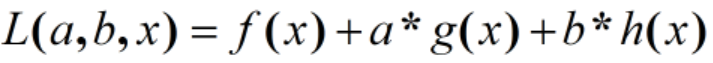
这个式子也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件,铺垫完毕。KKT条件是说最优解x必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. ∑ag(x)=0,α≥0
经过论证,我们这里的问题是满足 KKT 条件的(事实上,这里并没有搞清楚,看了不少博客,对这个地方的表述都不一致并且也含糊其辞,由于KKT条件不是SVM算法的核心,时间关系,这里暂时不再作重点研究,关于KKT条件,可以参考李航的《统计学习方法》)。
7.对偶问题的求解
在前面已经将求解原始问题转化成了求
这里求解这个最大最小值的步骤如下,首先固定α,要让L关于w和b最小化,我们分别对w,b求偏导数。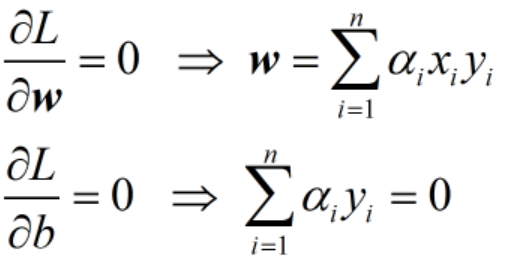
这样表达式就可以写成(暂时不要求搞清楚公式是怎么推出来的,比较复杂)
然后是求对α的极大,即是关于对偶问题的最优化问题。经过上面第一个步骤的求w和b,得到的拉格朗日函数式子已经没有了变量w,b,只有α。此时要求解的问题变成了:
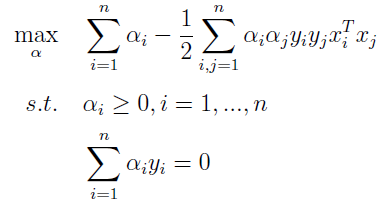
这样,便可求解出α(但是α并不好表示,要根据具体的情况得到),解出 α之后,根据公式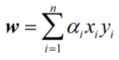
就可以得到w,而b可以根据下面这个公式得到
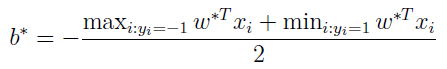
这样就可以求出表达式w·x+b=0的具体表达式了
*以上部分选自博客https://blog.csdn.net/sinat_20177327/article/details/79729551
8.核函数
在下图中的左边,红色和蓝色的点在二维空间是线性不可分的,我们可以通过某种映射将它投影到高维空间中,从而使得它们在高维中线性可分,这也是kernel的基本思想。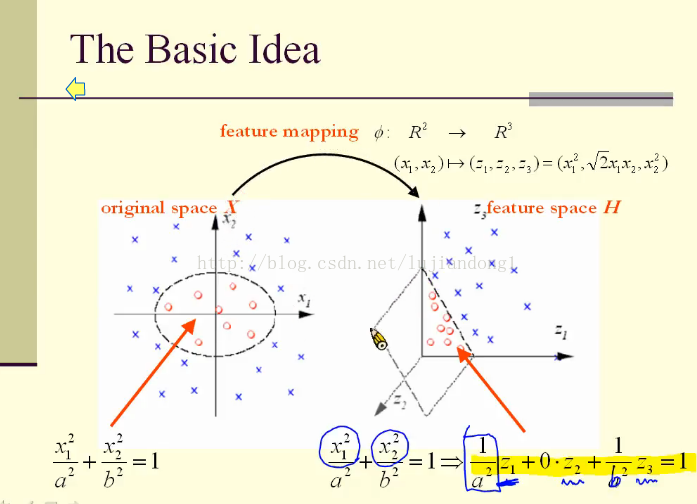
上图中,映射关系如下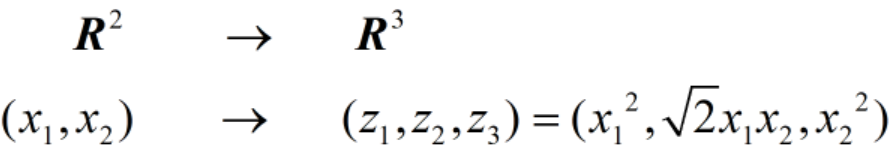
注意这里后面的等式就是映射(z1,z2,z3=x12,√2x1x2,x22)。在二维空间中,红色和蓝色的点线性不可分,只能由一个椭圆将其分开,它的分界线是: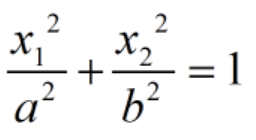
将这个分界线映射到三维空间中,就可以得到线性的分界面
这里一个关键点是核函数,在二维空间中的两点(x,x)和(x1’,x2’),这里我们将映射表示为Φ,那么有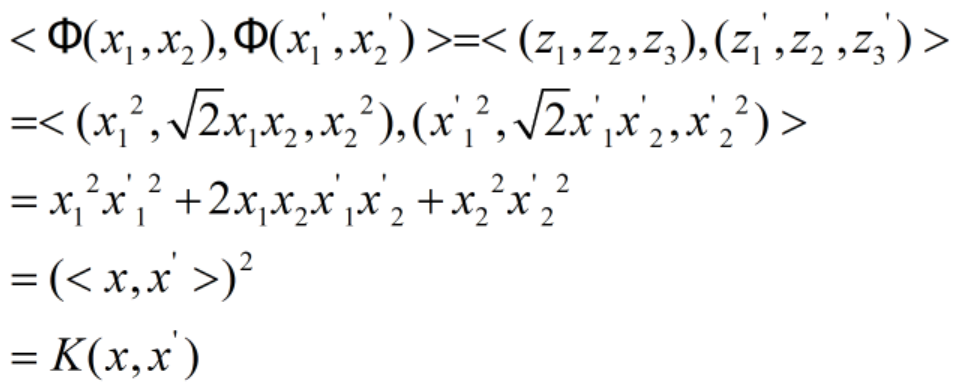
这里(x,x’)就是坐标为(x,x)和(x1’,x2’)的两个点,也就是说这里我们要求三维空间的内积<(z,z,z)(z1’,z2’,z3’)>,只需要求二维空间的内积(x,x’)即可,用这个内积求平方即为三维空间的内积。这里的核函数就表示为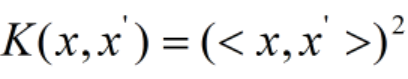
至此,我们可以对核函数下一个自己理解的定义了:低维空间内积到高维空间内积的一种映射方式。核函数到底有什么作用呢?由前面的知识我们知道,当知道核函数的表达式之后,我们就知道了高维空间的内积,内积有什么作用呢?它可以求距离和角度,在空间中的两点,距离可以表示为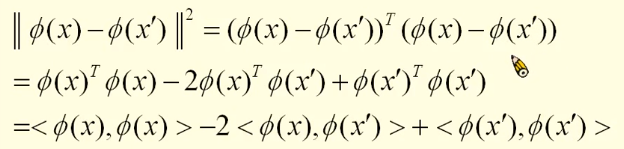
用核函数可以表示为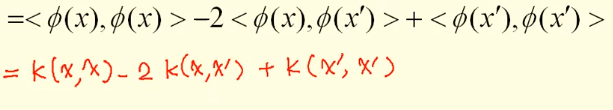
角度的计算公式由核函数可以表示为
有了这些东西,它的作用是什么呢?来看一个简单的例子
如上图左边的“+”和右边的“○”分别代表了从低维空间映射到高维空间的点,并且它们是被分好了的两类,其中“+”这一类表示为y=+1,“○”这一类表示为y=-1。它们的中心分别是红色的“+”和红色的“○”,并且坐标表示为c+和c-,并且坐标表示成图中所示的样子。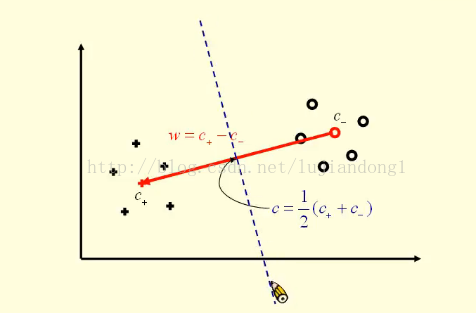
那么这两点的中点可以表示为c,并且坐标表示为c,它可以写成上图所示的样子。红色这条线的向量可以写成是w,它是等于w = c+ - c-,有了这些预备知识后,就可以进行分类了。对于高维空间中的一个点Φ(x),我们如果要判断这个点属于哪一类,就可以求如上图所示的夹角θ,如果这个角是锐角,那么它就属于“+”这一类,如果夹角是钝角,那么它就是属于“○”这一类。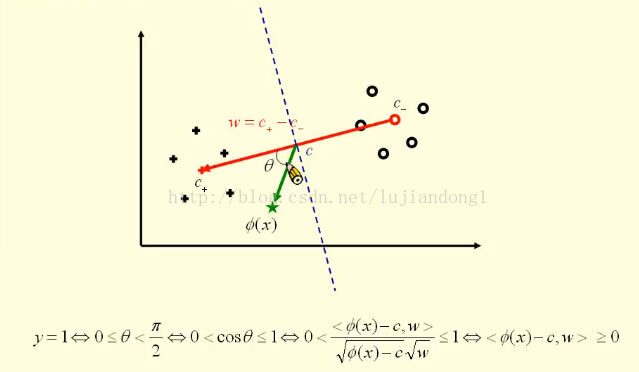
这里的绿色这条线的坐标可以表示为Φ(x)-c(向量减法得到的),这里的θ可以表示为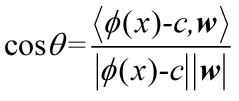
由于分母是恒大于0的,那么只需要判断分子的正负即可,分子可以写成如下的形式: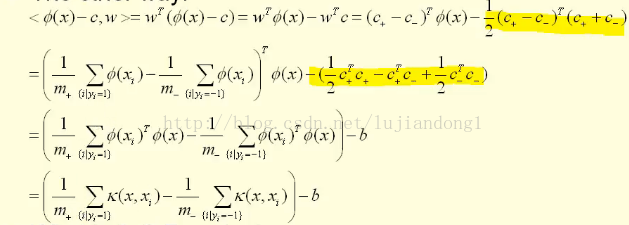
这其中,b也是可以用核函数解决的,所以这里我们只要知道核函数K,就可以通过核函数来求出分子的正负,进而判断出映射到高维中的这个点是属于哪一类的。本部分参考了台湾李政軒的视频
9.高斯核函数
在核函数中一个比较重要的核函数是高斯核函数,高斯核函数会将原始空间映射为无穷维空间,高斯核函数是最常见径向基函数 (Radial Basis Function,RBF), 径向基函数是某种沿径向对称的标量函数。高斯核函数的表达式为: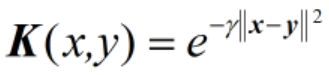
按照维基百科的定义,这里x、y表示两个特征向量,||x-y||可看作是两个特征向量之间的平方欧几里得距离。需要注意的是,在前面讲核函数的时候,将核函数表示为
当我们知道低维空间的内积之后,就可以通过核函数知道高维空间的内积。但是在高斯核函数里,怎么求高维空间的内积呢?这里参考我在知乎和王赟的对话,“核函数的值一般来说,是用低维空间中两个向量的坐标算出来的,而不一定是用低维空间中的内积算出来的。只知道低维空间中的内积,不一定能确定核函数的值。”高斯核函数到底有什么作用呢?看Andrew Ng的视频和这个视频配套博客。首先我们来看这样一个决策边界为非线性的情况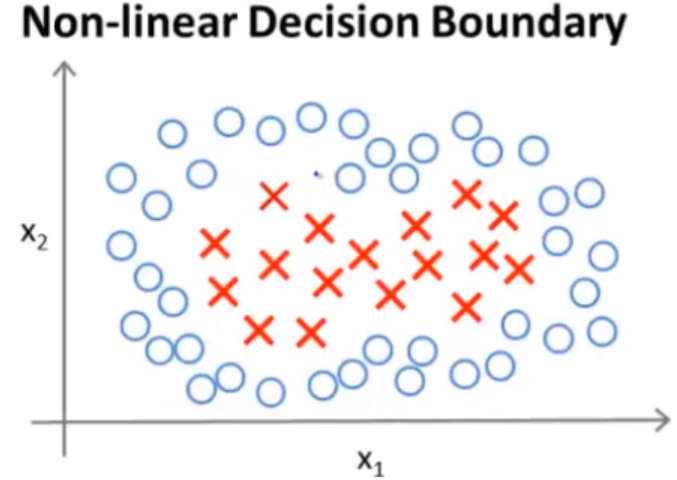
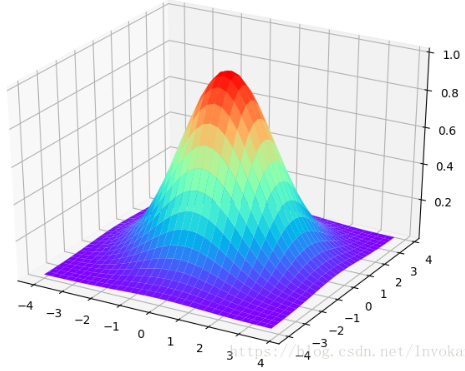
要想拟合这个非线性的决策边界,其中有一种方法就是用高阶函数去拟合这个特征,事实上,这个方案是并不可行,因为这样做存在一定的问题:从理论上来说,我们有很多不同的特征去选择来拟合这个边界(选择起来是一个问题)或者可能会存在比这些高阶多项式更好的特征,因为我们并不知道这些高阶多项式的组合是否一定对模型的提升有帮助。引入高斯核函数,我们首先来看二维正态分布的图
从图像中我们可以看出,离中心点越近,函数值就越接近于1。其公式为
如果我们把二维平面上的点,映射到到上图中,那么从上往下看就会看到类似于下面这张同心圆的图: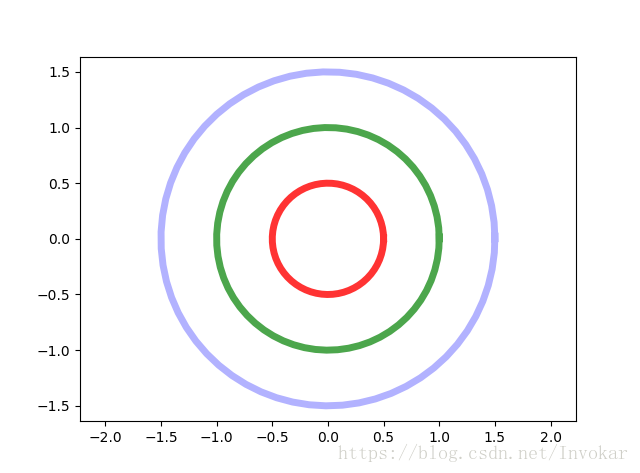
因此以任意一种颜色的同心圆作为决策边界,我们都可以完成对数据集的简单非线性划分。再来简单说明一下,这个是怎么运作的,如下图中的红色和蓝色的两类点。
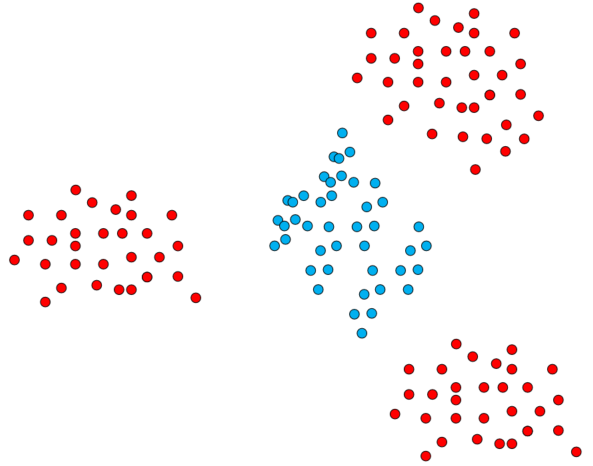
此时,它们还是否线性可分呢?答案是否定的,至少在二维平面空间内,它们不是线性可分的,但是在高维空间里有可能它们是线性可分的,有可能红色的部分投过去之后,就变成了下图中的红色部分,蓝色部分投过去之后,变成了蓝色的部分,这样我们就可以很好地把它们线性分隔开。
那么问题来了,如何映射到高维空间上去呢?采用高斯核函数。
10.用scikit-learn实现SVM
高斯核函数的表达式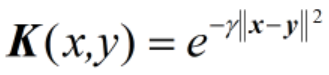
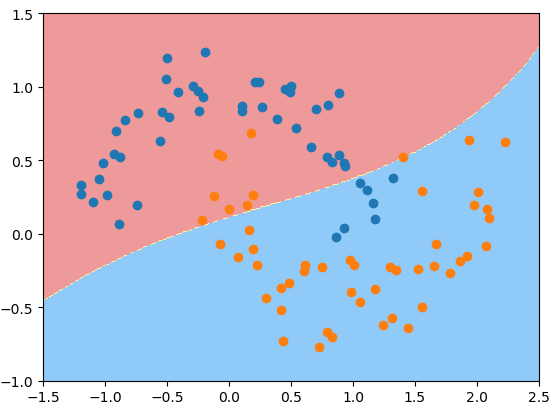
这里有个参数就是gamma,它的大小对高斯核函数起什么作用呢?先看代码。
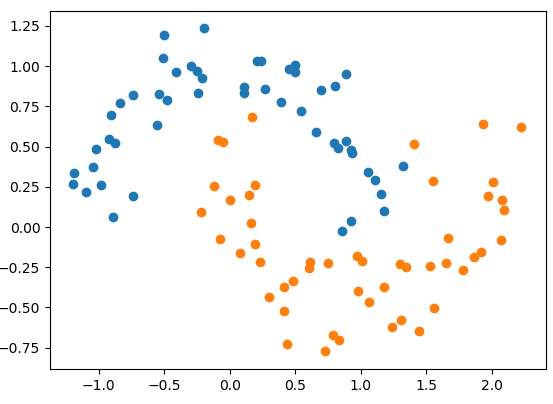
import matplotlib.pyplot as pltfrom sklearn import datasetsX, y = datasets.make_moons(noise=0.15, random_state=666) # 使用半月形数据并加入噪音plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show()
from sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import Pipelinefrom sklearn.svm import SVCdef rbf_kernel_svc(gamma): # 对数据进行预处理"""Pipeline可以将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流,好处:(1)直接调用fit和predict方法来对pipeline中的所有算法模型进行训练和预测(2)可以结合grid search对参数进行选择StandardScaler()的作用:标准化,标准化后平均值变为0,标准差变为1.此外它还可以保存训练集中的参数(均值、方差).标准化的公式为z=(x-u)/s, u表示均值, s表示标准差, 当with_mean=False时u=1, with_std=False时s=1"""return Pipeline(steps=[("std_scaler", StandardScaler()), ("svc", SVC(kernel="rbf", gamma=gamma))])svc = rbf_kernel_svc(gamma=1)svc.fit(X, y)def plot_decision_boundary(model, parameter): # 添加绘制图像函数# meshgrid:从坐标向量返回坐标矩阵.不好理解,直接上代码# x = array([-2, -1, 0, 1]), y = array([0, 1, 2])# z,s = np.meshgrid(x,y)# out>>> z = array([[-2, -1, 0, 1],[-2, -1, 0, 1],[-2, -1, 0, 1]])# s = array([[0, 0, 0, 0], [1, 1, 1, 1], [2, 2, 2, 2]])x0, x1 = np.meshgrid(# reshape(-1, 1)转成只有1列的,注意只有一列怎么写的.注意最后返回的x0和x1都是(400L,250L)的np.linspace(parameter[0], parameter[1], int((parameter[1]-parameter[0])*100)).reshape(-1, 1),np.linspace(parameter[2], parameter[3], int((parameter[3]-parameter[2])*100)).reshape(-1, 1),)# numpy.ravel,将数据降为一维, np.c_,按行连接两个矩阵,np.r_是按列连接两个矩阵# 降维后x0.ravel()和x1.ravel()都变为1行多列,但np.c_按照按行连接,因此最后生成的数组是多行两列的,两列刚好是坐标轴的横纵坐标x_new = np.c_[x0.ravel(), x1.ravel()]# 前面铺垫了很多,就是为了这里预测作准备,这里x_new就是要预测(分类的数据)y_predict = model.predict(x_new)zz = y_predict.reshape(x0.shape) # zz的行列数和x0一样# for jj in zz:# print jj # 可以看看数组zz里具体的情况from matplotlib.colors import ListedColormapcustom_map = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_map) # plt.contourf 等高线图plot_decision_boundary(svc, parameter=[-1.5, 2.5, -1.0, 1.5])plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show() # gamma=1
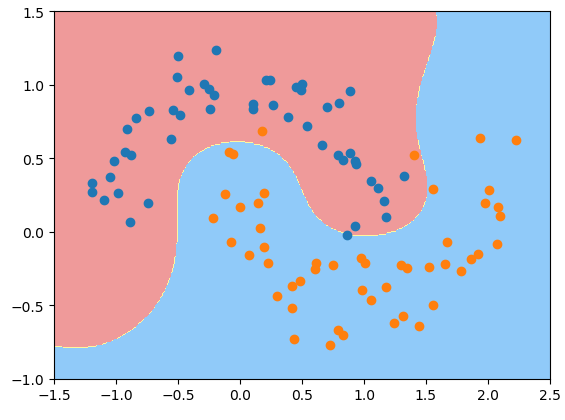
svc_gamma100 = rbf_kernel_svc(gamma=100)svc_gamma100.fit(X, y)plot_decision_boundary(svc_gamma100, parameter=[-1.5, 2.5, -1.0, 1.5])plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show() # gamma=100, 此时高斯分布窄, 有点过拟合
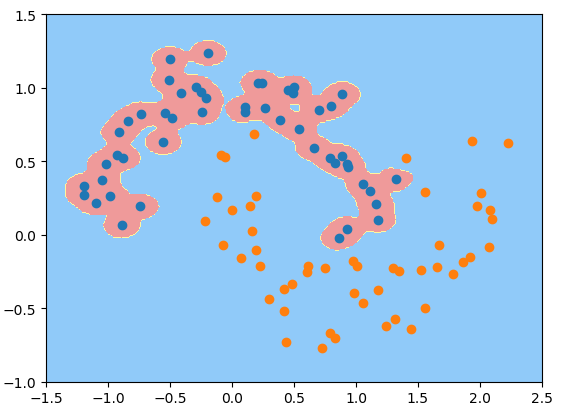
svc_gamma10 = rbf_kernel_svc(gamma=10)svc_gamma10.fit(X, y)plot_decision_boundary(svc_gamma10, axis=[-1.5, 2.5, -1.0, 1.5])plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show() # gamma=10
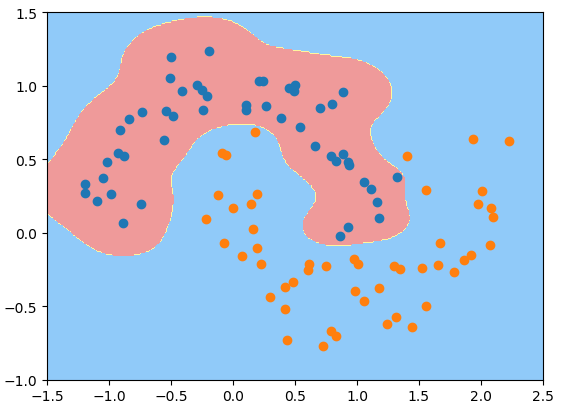
svc_gamma10 = rbf_kernel_svc(gamma=0.5)svc_gamma10.fit(X, y)plot_decision_boundary(svc_gamma10, axis=[-1.5, 2.5, -1.0, 1.5])plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show() # gamma=0.5,有点欠拟合
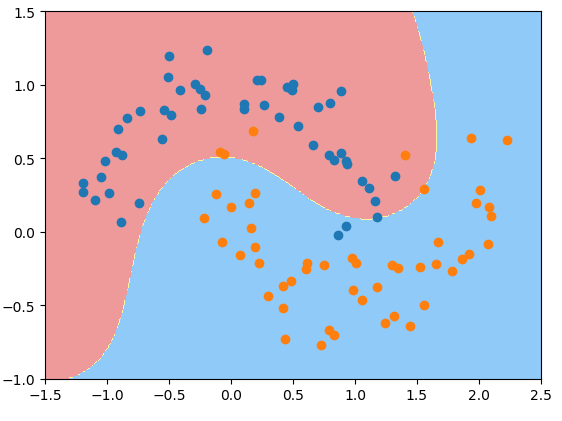
svc_gamma10 = rbf_kernel_svc(gamma=0.1) # gamma传入0.1svc_gamma10.fit(X, y)plot_decision_boundary(svc_gamma10, parameter=[-1.5, 2.5, -1.0, 1.5])plt.scatter(X[y == 0, 0], X[y == 0, 1])plt.scatter(X[y == 1, 0], X[y == 1, 1])plt.show() # gamma=0.1,决策边界和一个线性的决策边界差不多,欠拟合
高斯核函数表述为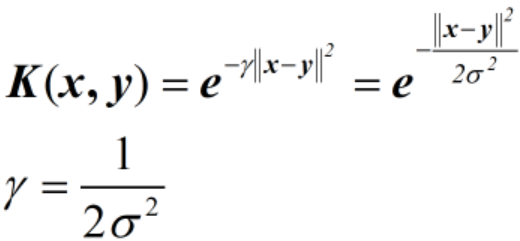
如果gamma设的太大,σ会很小,σ很小的高斯分布长得又高又瘦, 会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,存在训练准确率可以很高,而测试准确率不高的可能,就是通常说的过训练;而如果设的过小,则会造成平滑效应太大,无法在训练集上得到特别高的准确率,也会影响测试集的准确率,gamma其实就是在调整模型的复杂度!另外,这里需要说明的一点是,这里的分界线到底是什么?
可以参考我在知乎上的提问,它可以理解为映射到高维空间后得到的决策平面(或者超平面)再映射回平面(或者低维空间)中得到的决策边界。
11.Soft Margin SVM
并没有具体的定义,它存在着两种情况
(1)正确分类不如错误分类时的泛化能力强,如下图所示,当将蓝色的点分到蓝色这一类时,也就是图中更靠上的位置,这个分离平面的泛化能力很弱。而将蓝色的点分到红色这一类时,泛化能力反而更强。
(2)线性不可分:此时Hard Margin SVM根本不可用。由于这种情况并不是大量的点不可分,可不用核函数。
因此SVM必须具备一定的容错能力,这样的SVM就称之为Soft Margin SVM,Soft Margin SVM具体是怎么做的呢?在Hard Mragin SVM中,它要求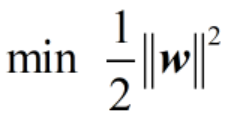
这个表达式的最小值,并且给的条件是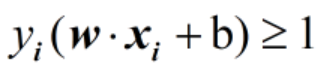
这个条件的意思是所有点必须在支持平面外面
为了让Hard-margin容忍一定的误差,在每个样本点后面加上了一个宽松条件,允许这个点违反一点点ξ大小的误差,下图中的violation就是这个ξ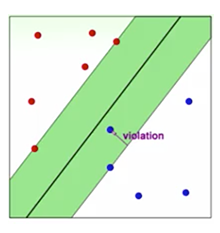
对于没有违反的点,则ξ为0,此时Soft Margin SVM的限定条件就可以表达成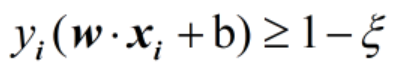
此时支持平面就变成了图中的虚线。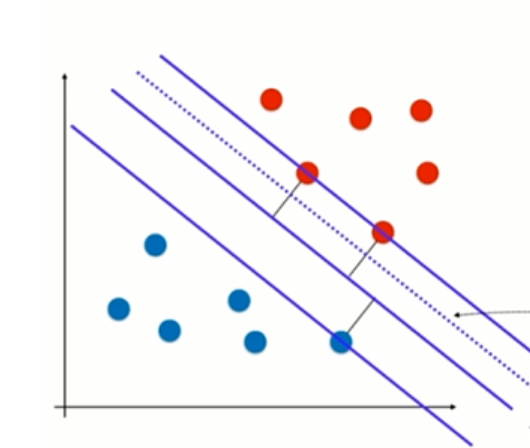
想一想,这里如果ξ取正无穷,也就是虚线在分离平面下面无限远的地方,此时所有的数据点都满足条件,那么容错空间就是无限大,这种情况显然不行,应该避免。ξ应该是让Soft Margin SVM有一定的容错空间,但是容错空间又不至于过大,怎么表征容错空间不至于过大呢?用下面的公式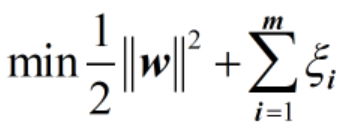
这里需要理解两个问题
(1)为什么用加号连接两个表达式
如上图所示,有一个异常红点,如果我们将这个异常红点所在的平面作为支撑平面的话,那么分离平面就是红色虚线这个分离平面,此时的margin就变小了。SVM要做的是什么?找到最大的margin,于是我们应该容忍一定的误差,允许这个样本有一定的误差,这个误差我们用ξ来表示。那么此时如果还是和先前一样,只求表达式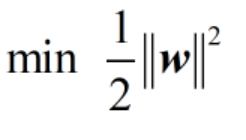
最小值的话,肯定是不行的,还应该带上这个误差ξ(注意在margin取得最大值的时候,||w||的取值是最小的)。也即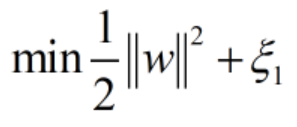
如果此时有另外一个点,给它的容错空间是ξ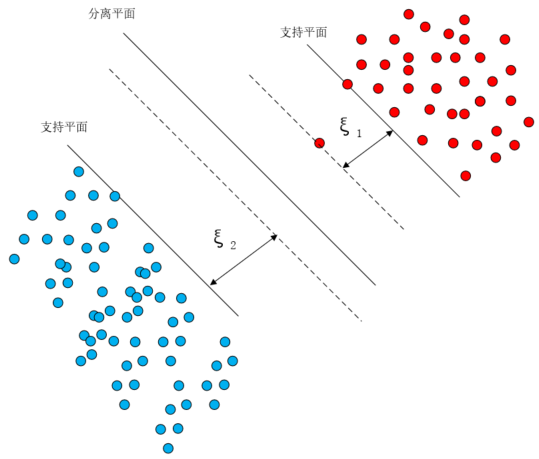
那么此时应该是再加上ξ,还是在ξ和ξ之间求一个最大值呢,注意是求和,而不是求最大值,求大值的话就会覆盖掉其中一个错误。这里我们不是要再求一个支持平面,而是在确定分离平面和支持平面的基础上,把所有的错误弥补,因此需要考虑每一个错误的样本,此时的表达式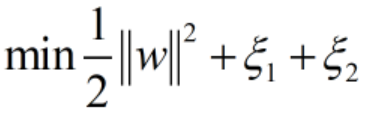
我们可以把这个公式理解为为了得到最大的间隔margin而付出的代价,此时的margin还是那个margin,并没有变,变的只是我们的寻优值,它变大了。到这里我们终于得到了公式
有了这个公式还不够,我们还应该考虑二者的配比,这里将配比定为C,并将公式写成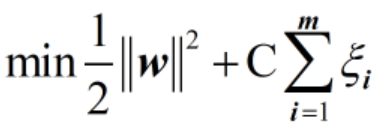
C越大,margin-violation的惩罚越大,要尽可能少犯错误。当C趋近于正无穷的时候,soft margin SVM变成了hard margin SVM。C越小,容错空间越大,允许一些样本不满足约束。很多点犯错没什么大关系,因为惩罚很小
12.SVM算法用于回归
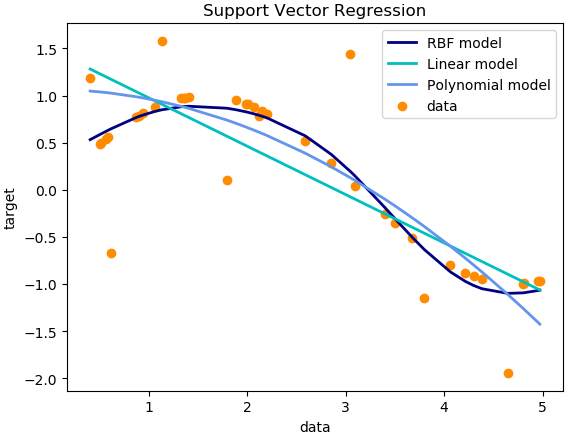
我们知道,最简单的线性回归模型是要找出一条曲线使得残差最小。同样的,SVR也是要找出一个超平面,使得所有数据到这个超平面的距离最小。和线性回归不同的是,在SVR中定义一个ε,如下图所示,定义虚线内区域的数据点的残差为0,而虚线区域外的数据点(支持向量)到虚线的边界的距离为残差(ζ)。与线性模型类似,我们希望这些残差(ζ)最小。所以,SVR就是要找出一个最佳的条状区域(2ε宽度),再对区域外的点进行回归。https://zhuanlan.zhihu.com/p/33692660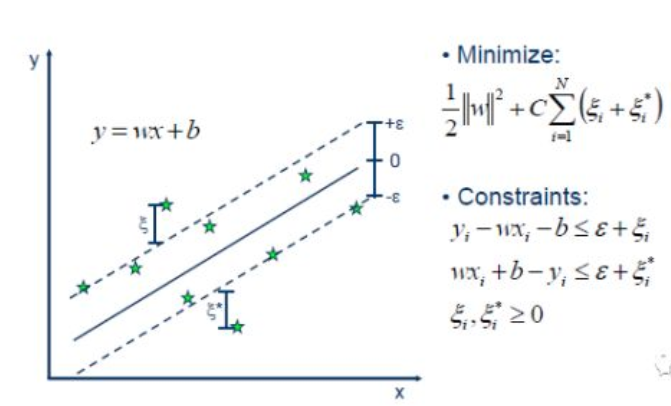
以下是sklearn官网上的SVR算法的python实现
# -*- coding: utf-8 -*-import numpy as npfrom sklearn.svm import SVRimport matplotlib.pyplot as plt# Generate sample dataX = np.sort(5 * np.random.rand(40, 1), axis=0)y = np.sin(X).ravel()# Add noise to targetsy[::5] += 3 * (0.5 - np.random.rand(8))# Fit regression modelssvr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.2)svr_lin = SVR(kernel='linear', C=1e3)svr_poly = SVR(kernel='poly', C=1e3, degree=2)y_rbf = svr_rbf.fit(X, y).predict(X)y_lin = svr_lin.fit(X, y).predict(X)y_poly = svr_poly.fit(X, y).predict(X)# Resultlw = 2plt.scatter(X, y, color='darkorange', label='data')plt.hold('on')plt.plot(X, y_rbf, color='navy', lw=lw, label='RBF model')plt.plot(X, y_lin, color='c', lw=lw, label='Linear model')plt.plot(X, y_poly, color='cornflowerblue', lw=lw, label='Polynomial model')plt.xlabel('data')plt.ylabel('target')plt.title('Support Vector Regression')plt.legend()plt.show()

若有收获,就点个赞吧
0 人点赞
