一、算法思想
用当前时间点和前面两点建立模型,并且这个模型可以用多个岭函数(平滑曲线)之和来表示。
二、建模过程
1.基本数据准备:将连续的实测功率值表示为如下形式,前两行为输入x,最后一行为输出y。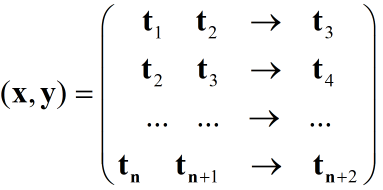
2.对输出y进行标准化处理,处理成y΄
3.找投影方向α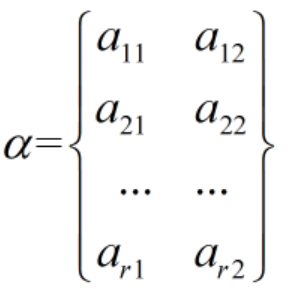
投影向量的行数为岭函数的个数,列数为输入x的维度。
找第一个投影方向(a,a),这个投影方向并不是随机的,由输入x以及输出y的协方差(x和y的关系)和自方差(x和x的关系)之间的关系来确定确定权重,权重就是投影方向的系数,这样就找到第一个投影方向。(github上的α是随机的)。
4. 求岭函数f
有了第一个投影方向(a,a)之后,用所有的输入和这个投影方向作向量乘,将向量乘后的结果作为横坐标和y΄一一对应,这样就有了多对散点(αx, y),拟合这些散点的过程就是求岭函数f的过程。求岭函数f首先是确定一个窗口,每个窗口里包含的点数是一致的,并且和光滑系数有关,每个窗口的点数=总点数0.5光滑系数+0.5(向下取整)。每次滑动的距离为一个窗口,每个窗口里包含多少点,就要平滑出多少点,最后的岭函数f其实就是这些平滑之后的散点。
5.求权重系数β
它等于协方差和除以自方差和,自方差和是岭函数的预测值的平方和,协方差和是岭函数和y΄的乘积和
6.找第二个岭函数的α,β,f
用第一轮每一个标准化后的实际值y΄和岭函数的预测值ŷ的偏差,用来作为下一轮的输出y
7. 迭代停止条件
(1)迭代次数>岭函数个数
(2)残差收敛:前一次的残差<后一次的残差
三、电场测试
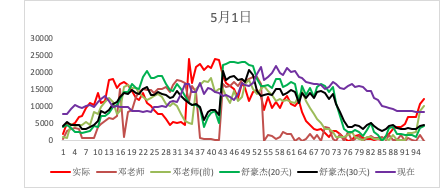
江苏盐城大丰润龙
20天:0.579,30天:0.592,现在:0.564,邓老师(前):0.704,邓老师:0.315,平滑:0.527,加入预测功率:0.654
5月调和平均准确率对比(20天数据建模)
| 电场名 | ppr | 现在 |
|---|---|---|
| 江苏大丰润龙 | 0.572 | 0.581 |
| 苜蓿台 | 0.606 | 0.688 |
| 望洋台 | 0.593 | 0.639 |
| 华电草湖二场 | 0.487 | 0.559 |
四、后续计划
| 处理方式 | 20天 | 30天 | 直接预测第8点 | 加入短期预测功率 | 平滑处理 |
|---|---|---|---|---|---|
| 调和平均准确率 | 0.579 | 0.592 | 0.515 | 0.653 | 0.514 |
复现邓老师的ppr算法基础上进行改进:
(1)参数测试,特别是建模时长和输入维数对超短期的准确率有一定的影响:
有提升,但是提升不太多。
(2)直接预测第8点:效果不好,没有直接对第一点进行建模效果好。
(3)和纯时序的超短期预测算法进行对比,看ppr算法是否是纯时序算法中效果最好的:由于现有的算法都加了短期预测功率,不是纯时序,从纯时序角度对比较困难。
(4)预测功率数据参与建模,方式是将这个预测功率数据加入到输入中:提升较多。
(5)数据预处理一:补断点,处理得比较简单,两点之间的均值。
(6)数据预处理二:实测数据进行平滑处理,避免波动较大的数据干扰模型:准确率比没有平滑更低,有可能和采用的平滑方式效果不佳有关,目前采用的是卷积平滑(np.convolve)。
对github上的ppr算法的改进
(7)测试github的ppr算法进行迭代训练、预测和加上短期预测功率的效果。
(8)对调和平均准确率异常的分析,华电草湖二场(652112)5月12日调和平均准确率0.088,现在的算法是0.272。
github的代码
# -*- coding: utf-8 -*-import numpyfrom scipy.interpolate import UnivariateSplinefrom sklearn.base import BaseEstimator, RegressorMixin, TransformerMixinfrom sklearn.utils.validation import check_X_y, check_is_fittedfrom sklearn.utils import as_float_array, check_random_state, check_arrayfrom matplotlib import pyplotimport numpy as npimport MySQLdbimport pandas as pdimport datetimeimport timedef mysql_conn(db='exportdb'): # 数据库连接信息user = 'dbadmin'pwd = 'Goldwind@123'ip = '10.12.17.97'port = 3306conn_modeling = MySQLdb.connect(host=ip, db=db, user=user, passwd=pwd, port=port, charset="utf8")return conn_modelingdef get_data(start_, end_): # 获取实测数据export_data = pd.read_sql("select rectime, power, predict_power from `%s` where rectime>='%s' and rectime<='%s'" %('factory_' + wfid, start_, end_), mysql_conn())return export_datadef get_expand_data(data, dimension_): # 将一维数据变为多维,最后一维为输出,前面为输入refactor_sam = []for i in range(dimension_ - 1, len(data)):block = dimension_ * [0]for j in range(dimension_):block[j] = data[i]i -= 1block = list(reversed(block))refactor_sam.append(block)col = []for i in range(dimension_):if i != dimension_ - 1:col.append(data.name + '_%s' % i)else:col.append('output')expand_df = pd.DataFrame(refactor_sam, columns=col)return expand_dfdef update_input(predict_result_, array_input_): # 对输入值进行更新array_input_ = np.delete(array_input_, 0) # 删除掉numpy.ndarray的第一个值array_input_ = np.append(array_input_, predict_result_) # 插入预测值return array_input_def rmse(real, pred, cap_=49500.0): # 均方根误差准确率s = 1 - np.sqrt(np.mean((real - pred) ** 2)) / cap_return s * 100def harmonic_mean(sc, pre, cap_): # 计算超短期准确率index = (sc < 0.03 * cap_) & (pre < 0.03 * cap_)sc = sc[~index]pre = pre[~index]if len(sc) > 0:a = np.abs(sc / (sc + pre) - 0.5)b = abs(sc - pre) / sum(abs(sc - pre))th = 1 - 2 * sum(a * b)else:th = 1return thdef get_predict_data(ptime):predict_power = pd.read_sql("select predict_power from `%s` where rectime='%s'" %('factory_' + wfid, ptime),mysql_conn()).iloc[0, 0]return predict_powerdef smooth_data(df): # 数据平滑x = df['power'].valuesbox = np.ones(10) / 10y = np.convolve(x, box, mode='same') # 两个数组长度可以不一样,参数为same时取更长的一个y[:5], y[-5:] = x[:5], x[-5:]df['new_power'] = yreturn dfdef compensate_data(df, start, end): # 补缺值time_list = pd.date_range(start, end, freq='15min').tolist()time_df = pd.DataFrame({'rectime': time_list}) # 首先构造一个时间完整的dfmerge_df = pd.merge(time_df, df, on='rectime', how='outer') # merge外链接merge_df = merge_df.reset_index(drop=True)for m in range(len(merge_df)):if m == 0 and merge_df.iloc[0, 1] == np.nan:merge_df.iloc[0, 1] = (merge_df.iloc[1, 1]+merge_df.iloc[2, 1])/2elif m == len(merge_df) and merge_df.iloc[-1, 1] == np.nan:merge_df.iloc[-1, 1] = (merge_df.iloc[-2, 1]+merge_df.iloc[-3, 1])/2elif merge_df.iloc[m, 1] == np.nan:merge_df.iloc[m, 1] = (merge_df.iloc[m+1, 1]+merge_df.iloc[m-1, 1])/2# merge_df = merge_df.fillna(merge_df.mean()) # NAN值用平均来补return merge_dfclass ProjectionPursuitRegressor(BaseEstimator, TransformerMixin, RegressorMixin):def __init__(self, r=10, fit_type='polyfit', degree=3, opt_level='high',example_weights='uniform', out_dim_weights='inverse-variance',eps_stage=0.0001, eps_backfit=0.01, stage_maxiter=100,backfit_maxiter=10, random_state=None, show_plots=False,plot_epoch=50):if not isinstance(r, int) or r < 1: # 如果r不是int或者r<1,报错raise ValueError('r must be an int >= 1.')if fit_type not in ['polyfit', 'spline']:raise NotImplementedError('fit_type ' + fit_type + ' not supported')if not isinstance(degree, int) or degree < 1:raise ValueError('degree must be >= 1.')if opt_level not in ['low', 'medium', 'high']:raise ValueError('opt_level must be either low, medium, or high.')if not (isinstance(example_weights, str) and example_weights == 'uniform'):try:example_weights = as_float_array(example_weights)except (TypeError, ValueError) as error:raise ValueError('example_weights must be `uniform`, or array-like.')if numpy.any(example_weights < 0):raise ValueError('example_weights can not contain negatives.')if not (isinstance(out_dim_weights, str) and out_dim_weights in['inverse-variance', 'uniform']):try:out_dim_weights = as_float_array(out_dim_weights)except (TypeError, ValueError) as error:raise ValueError('out_dim_weights must be either ' + \'inverse-variance, uniform, or array-like.')if numpy.any(out_dim_weights < 0):raise ValueError('out_dim_weights can not contain negatives.')if eps_stage <= 0 or eps_backfit <= 0:raise ValueError('Epsilons must be > 0.')if not isinstance(stage_maxiter, int) or stage_maxiter <= 0 or \not isinstance(backfit_maxiter, int) or backfit_maxiter <= 0:raise ValueError('Maximum iteration settings must be ints > 0.')# Save parameters to the objectparams = locals()for k, v in params.items():if k != 'self':setattr(self, k, v)def transform(self, X):check_is_fitted(self, '_alpha')X = check_array(X)return numpy.dot(X, self._alpha)def predict(self, X):P = self.transform(X)Y = sum([numpy.outer(self._f[j](P[:, j]), self._beta[:, j]) for j in range(self.r)])return Y if Y.shape[1] != 1 else Y[:, 0]def fit(self, X, Y):X, Y = check_X_y(X, Y, multi_output=True) # 标准估算器的输入验证,检查X和y的长度是否一致,强制X为2D和y为1Dif Y.ndim == 1: # standardize Y as 2D so the below always works 判断Y的维度Y = Y.reshape((-1, 1)) # reshape returns a view to existing dataself._random = check_random_state(self.random_state) # 随机产生随机数, 没有限制if isinstance(self.example_weights, str) and self.example_weights == 'uniform':self._example_weights = numpy.ones(X.shape[0])elif isinstance(self.example_weights, numpy.ndarray):if X.shape[0] != self.example_weights.shape[0]:raise ValueError('example_weights provided to the constructor' +' have dimension ' + str(self.example_weights.shape[0]) +', which disagrees with the size of X: ' + str(X.shape[0]))else:self._example_weights = self.example_weightsif isinstance(self.out_dim_weights, str) and self.out_dim_weights == 'inverse-variance':variances = Y.var(axis=0)# There is a problem if a variance for any column is zero, because# its relative scale will appear infinite.if max(variances) == 0: # if all zeros, don't readjust weightsvariances = numpy.ones(Y.shape[1])else:# Fill zeros with the max of variances, so the corresponding# columns have small weight and are not major determiners of loss.variances[variances == 0] = max(variances)self._out_dim_weights = 1. / varianceselif isinstance(self.out_dim_weights, str) and \self.out_dim_weights == 'uniform':self._out_dim_weights = numpy.ones(Y.shape[1])elif isinstance(self.out_dim_weights, numpy.ndarray):if Y.shape[1] != self.out_dim_weights.shape[0]:raise ValueError('out_dim_weights provided to the constructor' +' have dimension ' + str(self.out_dim_weights.shape[0]) +', which disagrees with the width of Y: ' + str(Y.shape[1]))else:self._out_dim_weights = self.out_dim_weightsself._alpha = self._random.randn(X.shape[1], self.r) # p x rself._beta = self._random.randn(Y.shape[1], self.r) # d x rself._f = [lambda x: x * 0 for j in range(self.r)] # zero functionsself._df = [None for j in range(self.r)] # no derivatives yetfor j in range(self.r): # for each term in the additive modelself._fit_stage(X, Y, j, True)if self.opt_level == 'high':self._backfit(X, Y, j, True)elif self.opt_level == 'medium':self._backfit(X, Y, j, False)return selfdef _fit_stage(self, X, Y, j, fit_weights):P = self.transform(X) # the n x r projections matrixR_j = Y - sum([numpy.outer(self._f[t](P[:, t]), self._beta[:, t].T) for tin range(self.r) if t is not j]) # the n x d residuals matrix# main alternating optimization loopitr = 0 # iteration counterprev_loss = -numpy.infloss = numpy.infp_j = P[:, j] # n x 1, the jth column of the projections matrix# 总的投影次数不能大于stage_maxiter,并且前后两次的损失差值不能小于eps_stagewhile abs(prev_loss - loss) > self.eps_stage and itr < self.stage_maxiter:# To understand how to optimize each set of parameters assuming the# others remain constant, see math.pdf section 3.# find the f_jbeta_j_w = self._out_dim_weights * self._beta[:, j] # weighted betatargets = numpy.dot(R_j, beta_j_w) / (numpy.inner(self._beta[:, j], beta_j_w) + 1e-9)# Fit the targets against projections.self._f[j], self._df[j] = self._fit_2d(p_j, targets, j, itr)# find beta_jf = self._f[j](p_j) # Find the n x 1 vector of function outputs.f_w = self._example_weights * f # f weighted by examplesself._beta[:, j] = numpy.dot(R_j.T, f_w) / (numpy.inner(f, f_w) + 1e-9)# find alpha_jif fit_weights:# Find the part of the Jacobians that is common to allJ = -(self._df[j](p_j) * numpy.sqrt(self._example_weights) * X.T).TJTJ = numpy.dot(J.T, J)A = sum([self._out_dim_weights[k] * (self._beta[k, j] ** 2) * JTJfor k in range(Y.shape[1])])# Collect all g_jk vectors in to a convenient matrix G_jG_j = R_j - numpy.outer(self._f[j](p_j), self._beta[:, j].T)b = -sum([self._out_dim_weights[k] * self._beta[k, j] *numpy.dot(J.T, G_j[:, k]) for k in range(Y.shape[1])])delta = numpy.linalg.lstsq(A.astype(numpy.float64, copy=False),b.astype(numpy.float64, copy=False), rcond=-1)[0]# TODO implement halving step if the loss doesn't decrease with# this update.alpha = self._alpha[:, j] + delta# normalize to avoid numerical driftself._alpha[:, j] = alpha / numpy.linalg.norm(alpha)# Recalculate the jth projection with new f_j and alpha_jp_j = numpy.dot(X, self._alpha[:, j])# Calculate mean squared error for this iterationprev_loss = loss# Subtract updated contribution of the jth term to get the# difference between Y and the predictions.diff = R_j - numpy.outer(self._f[j](p_j), self._beta[:, j].T)# square the difference, multiply rows by example weights, multiply# columns by their weights, and sum to get the final lossloss = numpy.dot(numpy.dot(self._example_weights, diff ** 2),self._out_dim_weights)itr += 1def _backfit(self, X, Y, j, fit_weights):itr = 0prev_loss = -numpy.infloss = numpy.infwhile abs(prev_loss - loss) > self.eps_backfit and itr < self.backfit_maxiter:for t in range(j):self._fit_stage(X, Y, t, fit_weights)prev_loss = lossdiff = Y - self.predict(X).reshape(Y.shape)loss = numpy.dot(numpy.dot(self._example_weights, diff ** 2), self._out_dim_weights)itr += 1def _fit_2d(self, x, y, j, itr):if self.fit_type == 'polyfit':coeffs = numpy.polyfit(x.astype(numpy.float64, copy=False),y.astype(numpy.float64, copy=False), deg=self.degree,w=self._example_weights)fit = numpy.poly1d(coeffs)deriv = fit.deriv(m=1)elif self.fit_type == 'spline':order = numpy.argsort(x)fit = UnivariateSpline(x[order], y[order], w=self._example_weights, k=self.degree, s=len(y) * y.var(),ext=0)deriv = fit.derivative(1)if self.show_plots and (itr % self.plot_epoch == 0):pyplot.scatter(x, y)pyplot.title('stage ' + str(j) + ' iteration ' + str(itr))pyplot.xlabel('projections')pyplot.ylabel('residuals')xx = numpy.linspace(min(x), max(x), 100)yy = fit(xx)pyplot.plot(xx, yy, 'g', linewidth=1)pyplot.show()return fit, derivif __name__ == '__main__':# 需要配置如下6个变量wfid = '320907'ridge_number = 20 # 岭函数个数dimension = 5 # 需要的数据总维度,如果是二阶输入的话,就是2+8=10,后面8个为输出train_data_sets = 96 * 30 # 训练的时候用到的输入和输出对数predict_start = '2019-05-01 00:00:00' # 要预测的开始时间predict_points = 96*2 # 要预测的点数(一天96点)start_time = time.time()cap = pd.read_sql("select powercap from `wind_farm_info` where wfid='%s'"% wfid, mysql_conn('WindFarmdb')).iloc[0, 0]train_end = datetime.datetime.strptime(str(predict_start), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(hours=-2) # 超短期提前两小时预测当前的# train_start由train_end和train_data_sets以及dimension决定,保证有192对输入输出train_start = datetime.datetime.strptime(str(train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=-15 * (train_data_sets + dimension - 2))predict_result_dict = {}for i in range(predict_points): # 每次训练和预测1个点new_train_start = datetime.datetime.strptime(str(train_start), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15 * i)new_train_end = datetime.datetime.strptime(str(train_end), '%Y-%m-%d %H:%M:%S') + datetime.timedelta(minutes=15*i)predict_result_list = []for j in range(1, 9): # 每一个时间点进行8次迭代训练和预测(之前16次,节约时间)predict_power_time_t = datetime.datetime.strptime(str(new_train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15 * (j - 1)) # 取预测功率的时间,用于训练predict_power_time_p = datetime.datetime.strptime(str(new_train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15 * j) # 取预测功率的时间,用于预测if j == 1: # 第1个点进行训练和预测train_data = get_data(new_train_start, new_train_end)expanded_real_data = get_expand_data(train_data['power'], dimension) # 首先取实测功率数据并扩展为dimension-1维predict_data = train_data['predict_power'].iloc[dimension - 1:].reset_index(drop=True) # 预测功率的时间和输出的时间一致expanded_data = pd.merge(expanded_real_data, predict_data.to_frame(), left_index=True,right_index=True)expanded_data.insert(dimension - 1, 'p_power', expanded_data['predict_power'],allow_duplicates=False)expanded_data = expanded_data.drop(['predict_power'], axis=1)train_input = expanded_data.iloc[:, 0: -1] # 前几列为训练的输入,最后一列为训练的输出train_output = expanded_data.iloc[:, -1]estimator = ProjectionPursuitRegressor(ridge_number)estimator.fit(train_input.values, train_output.values) # 建立模型init_predict_input = expanded_data.iloc[-1, np.r_[1:dimension - 1, dimension]].values.tolist()predict_power = get_predict_data(predict_power_time_p) # 预测数据的预测功率部分init_predict_input.append(predict_power)predict_input_array = np.array(init_predict_input).reshape(1, -1) # 转换为数组并reshapepredict_result = estimator.predict(predict_input_array)predict_result_list.append(predict_result[0])else: # 第2~16个点进行训练和预测if j == 2: # 第一次取j=1时expanded_data最后一行last_col = {}for k in range(dimension): # 先构建dictif 0 <= k < dimension-2:last_col['power_%s' % k] = expanded_data.iloc[-1, k + 1]elif k == dimension-2:last_col['power_%s' % (dimension - 2)] = expanded_data.iloc[-1, -1]else:last_col['output'] = predict_resultpredict_power = get_predict_data(predict_power_time_t)last_col['p_power'] = predict_powercolumns = ['power_%s' % i for i in range(dimension - 1)]columns.append('p_power') # 最后一行的columnscolumns.append('output')last_df = pd.DataFrame(last_col, columns=columns, index=[0])new_expanded_data = pd.concat([expanded_data, last_df]) # 新构建的和前面的expanded_data连接new_expanded_data = new_expanded_data.iloc[1:, :].reset_index(drop=True) # 删掉第一行并更新索引else:last_col = {}for k in range(dimension): # 先构建dictif 0 <= k < dimension - 2:last_col['power_%s' % k] = new_expanded_data.iloc[-1, k + 1]elif k == dimension - 2:last_col['power_%s' % (dimension - 2)] = new_expanded_data.iloc[-1, -1]else:last_col['output'] = predict_resultpredict_power = get_predict_data(predict_power_time_t)last_col['p_power'] = predict_powercolumns = ['power_%s' % i for i in range(dimension - 1)]columns.append('p_power') # 最后一行的columnscolumns.append('output')last_df = pd.DataFrame(last_col, columns=columns, index=[0])new_expanded_data = pd.concat([new_expanded_data, last_df]) # 新构建的和前面的expanded_data连接new_expanded_data = new_expanded_data.iloc[1:, :].reset_index(drop=True) # 删掉第一行并更新索引train_input = new_expanded_data.iloc[:, 0: -1] # 前几列为训练的输入,最后一列为训练的输出train_output = new_expanded_data.iloc[:, -1]estimator = ProjectionPursuitRegressor(ridge_number)estimator.fit(train_input.values, train_output.values) # 建立模型predict_input = new_expanded_data.iloc[-1, np.r_[1:dimension - 1, dimension]].values.tolist()predict_power = get_predict_data(predict_power_time_p) # 预测数据的预测功率部分predict_input.append(predict_power)predict_input_array = np.array(predict_input).reshape(1, -1)predict_result = estimator.predict(predict_input_array)predict_result_list.append(predict_result[0])for p in range(len(predict_result_list)): # 最后对小于0和大于cap的情况进行处理if predict_result_list[p] > cap:predict_result_list[p] = capelif predict_result_list[p] < 0:predict_result_list[p] = 0predict_result_dict[new_train_end + datetime.timedelta(hours=2)] = predict_result_listprint predict_result_dictkey_list = []predict_list_1, predict_list_2, predict_list_3, predict_list_4, predict_list_5, predict_list_6, predict_list_7, \predict_list_8 = [], [], [], [], [], [], [], []for k, v in predict_result_dict.items():key_list.append(str(k))predict_list_1.append(v[0])predict_list_2.append(v[1])predict_list_3.append(v[2])predict_list_4.append(v[3])predict_list_5.append(v[4])predict_list_6.append(v[5])predict_list_7.append(v[6])predict_list_8.append(v[7])df = pd.DataFrame({'time': key_list, 'predict_1': predict_list_1, 'predict_2': predict_list_2,'predict_3': predict_list_3, 'predict_4': predict_list_4,'predict_5': predict_list_5, 'predict_6': predict_list_6,'predict_7': predict_list_7, 'predict_8': predict_list_8})df = df[['time', 'predict_1', 'predict_2', 'predict_3', 'predict_4', 'predict_5','predict_6', 'predict_7', 'predict_8']].sort_values('time').reset_index(drop=True)df.to_csv(r"C:\Users\35760\PycharmProjects\LocalProject\PPR\datas\320907\predict_df_%s.csv" %datetime.datetime.now().strftime('%m_%d_%H_%M'))# df.to_csv(r"predict_df_%s.csv" % wfid) # 服务器部署df['time'] = pd.to_datetime(df['time'], format="%Y-%m-%d %H:%M:%S")df['day'] = df['time'].apply(lambda x: '%s-%02d-%02d' % (x.year, x.month, x.day))df = df.rename(columns={'predict_8': 'predict_power'})harmonic_acc_list = []day_list = []rmse_list = []data = pd.read_sql("select rectime, power from `%s` where rectime>='2019-05-01' and rectime<='2019-05-31'" %('factory_' + wfid), mysql_conn('exportdb'))data = data.rename(columns={'rectime': 'time'})merge_data = pd.merge(data, df, on='time', how='inner')print merge_datafor day, df_ in merge_data.groupby('day'): # 计算调和平均准确率harmonic_acc = harmonic_mean(df_['power'], df_['predict_power'], cap)accuracy = rmse(df_['power'], df_['predict_power'], cap)harmonic_acc_list.append(harmonic_acc)rmse_list.append(accuracy)day_list.append(day)df_harv = pd.DataFrame({'day': day_list, 'harv': harmonic_acc_list[0], 'rmse': rmse_list[0]})df_harv.to_csv(r"C:\Users\35760\PycharmProjects\LocalProject\PPR\datas\320907\ppr_result_%s.csv" %datetime.datetime.now().strftime('%m_%d_%H_%M'))# df_harv.to_csv(r"ppr_result_%s.csv" % wfid)end_time = time.time()print 'time:%s' % (end_time - start_time) # 计算一下程序执行的时间,如果过长,要考虑优化代码
邓老师的ppr算法改写
# -*- coding: utf-8 -*-"""@author: Haojie Shu@time:@description:ppr算法加入风速特征"""import numpy as npimport MySQLdbimport pandas as pdimport datetimeimport mathimport timefrom sklearn.metrics import make_scorerfrom sklearn.metrics import r2_scorefrom sklearn import svmfrom sklearn.model_selection import GridSearchCVdef mysql_conn(db='exportdb'): # 数据库连接信息user = 'dbadmin'pwd = 'Goldwind@123'ip = '10.12.17.97'port = 3306conn_modeling = MySQLdb.connect(host=ip, db=db, user=user, passwd=pwd, port=port, charset="utf8")return conn_modelingdef get_data(start_, end_): # 获取实测数据export_data = pd.read_sql("select rectime, power, predict_power from `%s` where rectime>='%s' and rectime<='%s'" %('factory_' + wfid, start_, end_), mysql_conn())return export_datadef get_expand_data(data, dimension_): # 将一维数据变为多维,最后一维为输出,前面为输入refactor_sam = []for i in range(dimension_ - 1, len(data)):block = dimension_ * [0]for j in range(dimension_):block[j] = data[i]i -= 1block = list(reversed(block))refactor_sam.append(block)col = []for i in range(dimension_):if i != dimension_ - 1:col.append(data.name + '_%s' % i)else:col.append('output')expand_df = pd.DataFrame(refactor_sam, columns=col)return expand_dfdef update_input(predict_result_, array_input_): # 对输入值进行更新array_input_ = np.delete(array_input_, 0) # 删除掉numpy.ndarray的第一个值array_input_ = np.append(array_input_, predict_result_) # 插入预测值return array_input_def rmse(real, pred, cap_=49500.0): # 均方根误差准确率s = 1 - np.sqrt(np.mean((real - pred) ** 2)) / cap_return s * 100def harmonic_mean(sc, pre, cap_): # 计算超短期准确率index = (sc < 0.03 * cap_) & (pre < 0.03 * cap_)sc = sc[~index]pre = pre[~index]if len(sc) > 0:a = np.abs(sc / (sc + pre) - 0.5)b = abs(sc - pre) / sum(abs(sc - pre))th = 1 - 2 * sum(a * b)else:th = 1return thdef get_predict_data(ptime):predict_power = pd.read_sql("select predict_power from `%s` where rectime='%s'" %('factory_' + wfid, ptime),mysql_conn()).iloc[0, 0]return predict_powerdef smooth_data(df): # 数据平滑x = df['power'].valuesbox = np.ones(10) / 10y = np.convolve(x, box, mode='same') # 两个数组长度可以不一样,参数为same时取更长的一个y[:5], y[-5:] = x[:5], x[-5:]df['new_power'] = yreturn dfdef compensate_data(df, start, end): # 补缺值time_list = pd.date_range(start, end, freq='15min').tolist()time_df = pd.DataFrame({'rectime': time_list})merge_df = pd.merge(time_df, df, on='rectime', how='outer')merge_df = merge_df.reset_index(drop=True)merge_df = merge_df.fillna(merge_df.mean()) # NAN值用平均来补return merge_dfclass PPR:def __init__(self, r):"""r:岭函数个数, int"""self.r = rif not isinstance(self.r, int) or self.r < 1:raise ValueError('r>1')self.smooth_ratio = 0.1 # 拟合岭函数的光滑系数def fit(self, x, y): # 训练"""1. x:输入数组, numpy.ndarray2. y:输出数组, numpy.ndarray"""ave = np.average(y)std = np.std(y)y_list = []for i in range(y.shape[0]): # 进行标准化处理new_y = (y[i] - ave) / stdy_list.append(new_y)y = np.array(y_list)# 投影, 岭函数模型, 权重, 损失, 拟合值, x带索引的listprojection_list, ridge_weight_list, loss_list, smo_list, enu_x_list, x_list_list = [], [], [], [], [], []projection = self.find_projection(x, y) # 第一个投影方向projection_list.append(projection)x_list, y_list, smo, loss, enu_x = self.create_one_f(x, y) # smo,拟合值列表(list), enu_x带顺序的列表loss_list.append(loss)smo_list.append(smo) # smo_list是list的listenu_x_list.append(enu_x) # enu_x_list也是list的listx_list_list.append(x_list)ridge_weight = self.get_ridge_weight(x, y) # 第一个权重ridge_weight_list.append(ridge_weight)for i in range(1, self.r): # 从第二个岭函数开始循环(如果是4个岭函数,不能这么循环)new_y_list = []for j in range(y.shape[0]):for k in range(len(enu_x_list[i-1])):if enu_x_list[i-1][k][0] == j: # k用来找索引new_y = y[j] - ridge_weight_list[i-1] * smo_list[i-1][k] # 偏差 = y- 权重*smonew_y_list.append(new_y) # 每一行得到一个新的ynew_y_array = np.array(new_y_list) # 转为一维数组projection = self.find_projection(x, new_y_array) # 将偏差作为下一轮的yprojection_list.append(projection)x_list, y_list, smo, loss, enu_x = self.create_one_f(x, new_y_array)loss_list.append(loss)smo_list.append(smo)enu_x_list.append(enu_x)x_list_list.append(x_list)ridge_weight = self.get_ridge_weight(x, new_y_array)ridge_weight_list.append(ridge_weight)if loss_list[i] > loss_list[i-1]: # 后一次的残差大于前一次的残差,迭代停止breakreturn projection_list, ridge_weight_list, ave, std, smo_list, x_list_listdef predict(self, x, y, input_data_): # ppr函数里的predict函数projection_list, ridge_weight_list, ave, std, new_smo_list, x_list_list = self.fit(x, y)# 判断是哪种方式迭代停止的if len(x_list_list) == self.r: # 岭函数个数=routput_list = []for j in range(len(x_list_list)): # 遍历每一个岭函数input_sum = 0for k in range(input_data_.shape[1]):input_sum += input_data_[0][k] * projection_list[j][k] # 投影*输入# print 'input_sum:%s' % input_summin_x, max_x = min(x_list_list[j]), max(x_list_list[j])# 都是等比例输出if input_sum > max_x:if x_list_list[j][-1] == x_list_list[j][-2]: # 最大的两个值刚好相等(防止分母为0)output = new_smo_list[j][-1]new_output = output * ridge_weight_list[j]output_list.append(new_output)else:ratio = (input_sum - x_list_list[j][-2]) / (x_list_list[j][-1] - x_list_list[j][-2])output = ratio * (new_smo_list[j][-1] - new_smo_list[j][-2]) + new_smo_list[j][-2]# print 'max_output:%s' % outputnew_output = output * ridge_weight_list[j]output_list.append(new_output)elif input_sum < min_x:if x_list_list[j][1] == x_list_list[j][0]:output = new_smo_list[j][0]new_output = output * ridge_weight_list[j]output_list.append(new_output)else:ratio = (x_list_list[j][1]-input_sum)/(x_list_list[j][1]-x_list_list[j][0])output = new_smo_list[j][1]-(new_smo_list[j][1]-new_smo_list[j][0])*ratio# print 'min_output:%s' % outputnew_output = output * ridge_weight_list[j]output_list.append(new_output)else: # 最大最小之间for h in range(len(x_list_list[j])):if x_list_list[j][h] == input_sum: # input_sum和x_list_list某个值刚好相等output_list.append(new_smo_list[j][h] * ridge_weight_list[j])# print 'mid_output:%s' % ridge_weight_list[j]break # 有可能相同的不止一个,取第一个就行elif x_list_list[j][h] < input_sum < x_list_list[j][h + 1]: # 如果不相等,必定在两个之间ratio = (input_sum - x_list_list[j][h]) / (x_list_list[j][h+1] - x_list_list[j][h])output = (new_smo_list[j][h+1] - new_smo_list[j][h]) * ratio + new_smo_list[j][h]# print 'mid_output:%s' % outputnew_output = output * ridge_weight_list[j]output_list.append(new_output)else:passelse:output_list = []for j in range(len(x_list_list)): # 遍历每一个岭函数input_sum = 0for k in range(input_data_.shape[1]):input_sum += input_data_[0][k] * projection_list[j][k] # 投影*输入min_x, max_x = min(x_list_list[j]), max(x_list_list[j])# 都是等比例输出if input_sum > max_x:if x_list_list[j][-1] == x_list_list[j][-2]:output = new_smo_list[j][-1]new_output = output * ridge_weight_list[j]output_list.append(new_output)else:ratio = (input_sum - x_list_list[j][-2]) / (x_list_list[j][-1] - x_list_list[j][-2])output = ratio * (new_smo_list[j][-1] - new_smo_list[j][-2]) + new_smo_list[j][-2]new_output = output * ridge_weight_list[j]output_list.append(new_output)elif input_sum < min_x:ratio = (x_list_list[j][0] - input_sum) / (x_list_list[j][1] - input_sum)output = (ratio * new_smo_list[j][1] - new_smo_list[j][0]) / ratio - 1new_output = output * ridge_weight_list[j]output_list.append(new_output)else: # 最大最小之间for h in range(len(x_list_list[j])):if x_list_list[j][h] == input_sum: # input_sum和x_list_list某个值刚好相等output_list.append(new_smo_list[j][h] * ridge_weight_list[j])elif x_list_list[j][h] < input_sum < x_list_list[j][h + 1]: # 如果不相等,必定在两个之间ratio = (input_sum - x_list_list[j][h]) / (x_list_list[j][h+1] - x_list_list[j][h])output = (new_smo_list[j][h+1] - new_smo_list[j][h]) * ratio + new_smo_list[j][h]new_output = output * ridge_weight_list[j]output_list.append(new_output)else:passult_output = sum(output_list)*std+avereturn ult_output@staticmethoddef cal_var(x, y):avg_x = np.mean(x, axis=0) # 求数组x每一列的均值cov_x_y_list = []for p in range(x.shape[1]):s = 0.0for q in range(x.shape[0]):s = s + y[q] * (x[q, p] - avg_x[p])cov_x_y_list.append([p, s / x.shape[0]]) # 计算x/y协方差var_x_x_list = []for i in range(x.shape[1]):for j in range(i, x.shape[1]):s = 0.0for k in range(x.shape[0]):tt = (x[k, j] - avg_x[j]) * (x[k, j] - avg_x[i])s = s + ttvar_x_x_list.append([i, j, s / x.shape[0]])return cov_x_y_list, var_x_x_listdef find_projection(self, x, y): # 由自方差和协方差来寻找投影方向(权重系数)cov_list, var_list = self.cal_var(x, y)project_dict = {} # 投影方向的dictfor i in range(x.shape[1]):project_dict[i] = 1for i in range(x.shape[1]):k1 = i + (i * (i + 1) / 2) # 取自方差的索引,按照C#代码写的sum_var = project_dict[i] * var_list[k1][2]for j in range(i + 1, x.shape[1]):k2 = i + (j * (j + 1) / 2)sum_var += project_dict[i] * var_list[k2][2]for k in range(i):k3 = i + (k * (k + 1) / 2)sum_var += project_dict[i] * var_list[k3][2]project_dict[i] = cov_list[i][1] / sum_var'''用自方差和协方差求完投影方向后,还要进行一个简单的处理'''sum_project = 0new_projection_dict = {}for v in project_dict.values():sum_project += v * vsum_project = 1.0 / math.sqrt(sum_project)for k, v in project_dict.items():new_projection = v * sum_projectnew_projection_dict[k] = new_projectionreturn new_projection_dictdef get_project_label(self, x, y): # 获取投影后的坐标list, x和y是对应起来的project_dict = self.find_projection(x, y)x_list, y_list = [], []for i in range(x.shape[0]):x_label = 0for j in range(x.shape[1]):x_label += x[i][j] * project_dict[j] # 投影方向和输入作乘法,得到的值作为横坐标x_list.append(x_label)y_list.append(y[i])return x_list, y_list@staticmethoddef performance_metric(y_true, y_predict):score = r2_score(y_true, y_predict)return scoredef fit_curve(self, x, y): # 拟合曲线x_list, y_list, smo_list, loss, index_list = self.create_one_f(x, y)x_array = np.array(x_list)smo_array = np.array(smo_list)reshape_x_array = x_array.reshape(x_array.shape[0], -1)scorig_fnc = make_scorer(self.performance_metric)params = {'C': [10], 'gamma': [0.1]}svc = svm.SVR()grid = GridSearchCV(svc, param_grid=params, scoring=scorig_fnc, cv=5) # 网格搜索model = grid.fit(reshape_x_array, smo_array)return model, lossdef create_one_f_back(self, x, y): # 创建一个岭函数x_list, y_list = self.get_project_label(x, y)enu_x = list(enumerate(x_list))df = pd.DataFrame({'x': x_list, 'y': y_list, 'enu_x': enu_x})sorted_df = df.sort_values(by='x') # 按照x进行升序排序new_x_list = sorted_df['x'].tolist()new_y_list = sorted_df['y'].tolist()new_enu_x = sorted_df['enu_x'].tolist()smo_list = self.super_filter(new_x_list, new_y_list) # 岭函数拟合后的纵坐标loss_sum = 0for j in range(len(smo_list)):loss = math.pow((new_y_list[j] - smo_list[j]), 2)loss_sum += loss # 总的误差return new_x_list, new_y_list, smo_list, loss_sum, new_enu_xdef create_one_f(self, x, y): # 创建一个岭函数x_list, y_list = self.get_project_label(x, y)enu_x = list(enumerate(x_list))df = pd.DataFrame({'x': x_list, 'y': y_list, 'enu_x': enu_x})sorted_df = df.sort_values(by='x') # 按照x进行升序排序new_x_list = sorted_df['x'].tolist()new_y_list = sorted_df['y'].tolist()new_enu_x = sorted_df['enu_x'].tolist()smo_list = self.super_filter(new_x_list, new_y_list) # 岭函数拟合后的纵坐标loss_sum = 0for j in range(len(smo_list)):loss = math.pow((new_y_list[j] - smo_list[j]), 2)loss_sum += loss # 总的误差avg_smo_list = sum(smo_list)/len(smo_list)v = 0.0for k in range(len(smo_list)):smo_list[k] = smo_list[k]-avg_smo_listv += smo_list[k]*smo_list[k]if v > 0:v = 1/math.sqrt(v/len(smo_list))for s in range(len(smo_list)):smo_list[s] = smo_list[s]*vreturn new_x_list, new_y_list, smo_list, loss_sum, new_enu_xdef super_filter(self, x_list, y_list): # 超级滤波器""":param x_list: 经过排序的list,投影方向和输入x的乘积:param y_list: y_list和x_list是对应的在c#中:return:"""len_list = len(x_list)scale = x_list[3 * len_list / 4] - x_list[len_list / 4]vsm = scale * scalesmo_list = self.smooth_window(x_list, y_list, vsm)new_y_list = []for i in range(len_list):new_y_list.append(smo_list[i])new_smo_list = self.smooth_window(x_list, new_y_list, vsm) # 调用两次,增加平滑度return new_smo_listdef smooth_window(self, x_list, y_list, vsm): # 对窗口内的点作平滑处理""":param x_list:经过排序的list,投影方向和输入x的乘积:param y_list:y_list和x_list是对应的:param vsm:滑动距离参数需要注意的是,在C#中smooth_window函数虽然有smo_list,acvr_list这两个参数,但是它们并不起作用:return:"""win_x, win_y, fbw, xvar, cvar = 0.0, 0.0, 0.0, 0.0, 0.0 # 岭函数滑动窗口的一些初始值n_points = int(0.5 * self.smooth_ratio * len(x_list) + 0.5) # 每次窗口滑动要包含的点数if n_points < 2: # 每个窗口内的点数不能少于2n_points = 2n_iter = int(2 * n_points + 1) # 循环次数if n_iter > len(x_list): # 循环次数不能大于横坐标的总个数n_iter = len(x_list)for i in range(n_iter): # 第一次循环滤波处理, 计算波型边界参数list_index = i # 取x_list, y_list的一个索引xti = x_list[list_index]if list_index < 1:list_index = len(x_list) - 1 + list_indexxti = x_list[list_index] - 1.0fbo = fbwfbw = fbw + 1if fbw > 0:win_x = (fbo * win_x + xti) / fbwwin_y = (fbo * win_y + y_list[list_index]) / fbwtmp = 0.0if fbo > 0:tmp = fbw * (xti - win_x) / fboxvar = xvar + tmp * (xti - win_x)cvar = cvar + tmp * (y_list[list_index] - win_y)smo_list, acvr_list = [], []for p in range(len(x_list)): # 第二次循环滤波处理,计算SMO[0..N],ACVR[0..N]out = p - n_points - 1inp = p + n_pointsif out >= 1 and inp <= len(x_list):if out < 1:out = len(x_list) + outxto = x_list[out] - 1.0xti = x_list[inp]else:if inp > len(x_list) - 1:inp = inp - len(x_list)xti = x_list[inp] + 1.0xto = x_list[out]else:xto = x_list[out]xti = x_list[inp]fbo = fbwfbw = fbw - 1tmp = 0.0if fbw > 0.0:tmp = fbo * (xto - win_x) / fbwxvar = xvar - tmp * (xto - win_x)cvar = cvar - tmp * (y_list[out] - win_y)if fbw > 0.0:win_x = (fbo * win_x - xto) / fbwwin_y = (fbo * win_y - y_list[out]) / fbwfbo = fbwfbw = fbw + 1if fbw > 0.0:win_x = (fbo * win_x + xti) / fbwwin_y = (fbo * win_y + y_list[inp]) / fbwtmp = 0.0if fbo > 0.0:tmp = fbw * (xti - win_x) / fboxvar = xvar + tmp * (xti - win_x)cvar = cvar + tmp * (y_list[inp] - win_y)a = 0.0if xvar > vsm:a = cvar / xvarsmo = a * (x_list[p] - win_x) + win_ysmo_list.append(smo)h = 0.0if fbw > 0.0:h = 1.0 / fbwif xvar > vsm:h = h + (x_list[p] - win_x) * (x_list[p] - win_x) / xvaracvr = 0a = 1.0 - hif a > 0.0:acvr = abs(y_list[p] - smo_list[p]) / aelse:if a > 1:acvr = acvr_list[p - 1]acvr_list.append(acvr)jj = 0while jj <= len(x_list) - 1:jo = jjsy = smo_list[jj]j = jjfbw = 1while True:j = j + 1if j >= len(x_list) - 1:breakif x_list[j - 1] <= x_list[j]:breaksy = sy + smo_list[j - 1]fbw = fbw + 1if j > jo:a = 0.0if fbw > 0.0:a = sy / fbwfor q in range(j):smo_list[q] = ajj = jj + 1return smo_listdef get_ridge_weight(self, x, y): # 岭函数的权重,也即β参数x_list, y_list, smo_list, loss, index_list = self.create_one_f(x, y)var_sum, cov_sum = 0.0, 0.0for i in range(len(smo_list)):cov_sum += y_list[i] * smo_list[i] # 协方差和var_sum += smo_list[i] * smo_list[i] # 自方差和ridge_weight = cov_sum / var_sumreturn ridge_weightif __name__ == '__main__':# 需要配置如下6个变量wfid = '320907'ridge_number = 4 # 岭函数个数dimension = 5 # 需要的数据总维度,如果是二阶输入的话,就是2+8=10,后面8个为输出train_data_sets = 96*30 # 训练的时候用到的输入和输出对数predict_start = '2019-05-01 00:00:00' # 要预测的开始时间predict_points = 96*1 # 要预测的点数(一天96点)start_time = time.time()cap = pd.read_sql("select powercap from `wind_farm_info` where wfid='%s'"% wfid, mysql_conn('WindFarmdb')).iloc[0, 0]train_end = datetime.datetime.strptime(str(predict_start), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(hours=-2) # 超短期提前两小时预测当前的# train_start由train_end和train_data_sets以及dimension决定,保证有192对输入输出train_start = datetime.datetime.strptime(str(train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=-15*(train_data_sets+dimension-2))predict_result_dict = {}for i in range(predict_points): # 每次训练和预测1个点new_train_start = datetime.datetime.strptime(str(train_start), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15*i)new_train_end = datetime.datetime.strptime(str(train_end), '%Y-%m-%d %H:%M:%S') + datetime.timedelta(minutes=15*i)predict_result_list = []for j in range(1, 9): # 每一个时间点进行8次迭代训练和预测(之前16次,节约时间)predict_power_time_t = datetime.datetime.strptime(str(new_train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15*(j-1)) # 取预测功率的时间,用于训练predict_power_time_p = datetime.datetime.strptime(str(new_train_end), '%Y-%m-%d %H:%M:%S') + \datetime.timedelta(minutes=15*j) # 取预测功率的时间,用于预测if j == 1: # 第1个点进行训练和预测train_data = get_data(new_train_start, new_train_end)expanded_real_data = get_expand_data(train_data['power'], dimension) # 首先取实测功率数据并扩展为dimension-1维predict_data = train_data['predict_power'].iloc[dimension-1:].reset_index(drop=True) # 预测功率的时间和输出的时间一致expanded_data = pd.merge(expanded_real_data, predict_data.to_frame(), left_index=True, right_index=True)expanded_data.insert(dimension-1, 'p_power', expanded_data['predict_power'], allow_duplicates=False)expanded_data = expanded_data.drop(['predict_power'], axis=1)train_input = expanded_data.iloc[:, 0: -1] # 前几列为训练的输入,最后一列为训练的输出train_output = expanded_data.iloc[:, -1]estimator = PPR(ridge_number)estimator.fit(train_input.values, train_output.values) # 建立模型init_predict_input = expanded_data.iloc[-1, np.r_[1:dimension-1, dimension]].values.tolist()predict_power = get_predict_data(predict_power_time_p) # 预测数据的预测功率部分init_predict_input.append(predict_power)predict_input_array = np.array(init_predict_input).reshape(1, -1) # 转换为数组并reshapepredict_result = estimator.predict(train_input.values, train_output.values, predict_input_array)predict_result_list.append(predict_result)else: # 第2~16个点进行训练和预测if j == 2: # 第一次取j=1时expanded_data最后一行last_col = {}for k in range(dimension): # 先构建dictif 0 <= k < dimension-2:last_col['power_%s' % k] = expanded_data.iloc[-1, k+1]elif k == dimension-2:last_col['power_%s' % (dimension-2)] = expanded_data.iloc[-1, -1]else:last_col['output'] = predict_resultpredict_power = get_predict_data(predict_power_time_t)last_col['p_power'] = predict_powercolumns = ['power_%s' % i for i in range(dimension-1)]columns.append('p_power') # 最后一行的columnscolumns.append('output')last_df = pd.DataFrame(last_col, columns=columns, index=[0])new_expanded_data = pd.concat([expanded_data, last_df]) # 新构建的和前面的expanded_data连接new_expanded_data = new_expanded_data.iloc[1:, :].reset_index(drop=True) # 删掉第一行并更新索引else:last_col = {}for k in range(dimension): # 先构建dictif 0 <= k < dimension-2:last_col['power_%s' % k] = new_expanded_data.iloc[-1, k+1]elif k == dimension-2:last_col['power_%s' % (dimension-2)] = new_expanded_data.iloc[-1, -1]else:last_col['output'] = predict_resultpredict_power = get_predict_data(predict_power_time_t)last_col['p_power'] = predict_powercolumns = ['power_%s' % i for i in range(dimension-1)]columns.append('p_power') # 最后一行的columnscolumns.append('output')last_df = pd.DataFrame(last_col, columns=columns, index=[0])new_expanded_data = pd.concat([new_expanded_data, last_df]) # 新构建的和前面的expanded_data连接new_expanded_data = new_expanded_data.iloc[1:, :].reset_index(drop=True) # 删掉第一行并更新索引train_input = new_expanded_data.iloc[:, 0: -1] # 前几列为训练的输入,最后一列为训练的输出train_output = new_expanded_data.iloc[:, -1]estimator = PPR(ridge_number)estimator.fit(train_input.values, train_output.values) # 建立模型predict_input = new_expanded_data.iloc[-1, np.r_[1:dimension-1, dimension]].values.tolist()predict_power = get_predict_data(predict_power_time_p) # 预测数据的预测功率部分predict_input.append(predict_power)predict_input_array = np.array(predict_input).reshape(1, -1)predict_result = estimator.predict(train_input.values, train_output.values, predict_input_array)predict_result_list.append(predict_result)for p in range(len(predict_result_list)): # 最后对小于0和大于cap的情况进行处理if predict_result_list[p] > cap:predict_result_list[p] = capelif predict_result_list[p] < 0:predict_result_list[p] = 0predict_result_dict[new_train_end + datetime.timedelta(hours=2)] = predict_result_list"""计算调和平均准确率"""key_list = []predict_list_1, predict_list_2, predict_list_3, predict_list_4, predict_list_5, predict_list_6, predict_list_7, \predict_list_8 = [], [], [], [], [], [], [], []for k, v in predict_result_dict.items():key_list.append(str(k))predict_list_1.append(v[0])predict_list_2.append(v[1])predict_list_3.append(v[2])predict_list_4.append(v[3])predict_list_5.append(v[4])predict_list_6.append(v[5])predict_list_7.append(v[6])predict_list_8.append(v[7])df = pd.DataFrame({'time': key_list, 'predict_1': predict_list_1, 'predict_2': predict_list_2,'predict_3': predict_list_3, 'predict_4': predict_list_4,'predict_5': predict_list_5, 'predict_6': predict_list_6,'predict_7': predict_list_7, 'predict_8': predict_list_8})df = df[['time', 'predict_1', 'predict_2', 'predict_3', 'predict_4', 'predict_5','predict_6', 'predict_7', 'predict_8']].sort_values('time').reset_index(drop=True) # 调整df列的顺序并按照time进行排序# df.to_csv(r"C:\Users\35760\PycharmProjects\LocalProject\PPR\datas\320907\predict_df_%s.csv" %# datetime.datetime.now().strftime('%m_%d_%H_%M'))df.to_csv(r"predict_df_%s.csv" % wfid) # 服务器部署df['time'] = pd.to_datetime(df['time'], format="%Y-%m-%d %H:%M:%S")df['day'] = df['time'].apply(lambda x: '%s-%02d-%02d' % (x.year, x.month, x.day))df = df.rename(columns={'predict_8': 'predict_power'})harmonic_acc_list = []day_list = []rmse_list = []data = pd.read_sql("select rectime, power from `%s` where rectime>='2019-05-01' and rectime<='2019-05-31'" %('factory_' + wfid), mysql_conn('exportdb'))data = data.rename(columns={'rectime': 'time'})merge_data = pd.merge(data, df, on='time', how='inner')for day, df_ in merge_data.groupby('day'): # 计算调和平均准确率harmonic_acc = harmonic_mean(df_['power'], df_['predict_power'], cap)accuracy = rmse(df_['power'], df_['predict_power'], cap)harmonic_acc_list.append(harmonic_acc)rmse_list.append(accuracy)day_list.append(day)df_harv = pd.DataFrame({'day': day_list, 'harv': harmonic_acc_list, 'rmse': rmse_list})# df_harv.to_csv(r"C:\Users\35760\PycharmProjects\LocalProject\PPR\datas\320907\ppr_result_%s.csv" %# datetime.datetime.now().strftime('%m_%d_%H_%M'))df_harv.to_csv(r"ppr_result_%s.csv" % wfid)end_time = time.time()print 'time:%s' % (end_time - start_time) # 计算一下程序执行的时间,如果过长,要考虑优化代码

若有收获,就点个赞吧
0 人点赞
