1.算法简介
(1)Boosting算法
Boosting算法是将“弱学习算法“提升为“强学习算法”的过程,主要思想是“三个臭皮匠顶个诸葛亮”。常见的Boosting算法有AdaBoost(Adaptive Boosting,自适应提升)和Gradient Boosting(梯度提升)。
(2)Adaptive Boosting
Adaptive Boosting的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器;同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
(3)Gradient Boosting
Gradient Boosting每一次计算是为了减少上一次的残差,而为了消除残差,可以在残差减少的梯度(Gradient)方向上建立一个新的模型。就像准备考试前的复习,先做一遍习题册,然后把做错的题目挑出来,再做一次,然后把做错的题目挑出来再做一次,经过反复多轮训练,取得最好的成绩。
基于Gradient Boosting思想的算法有很多,常见的有GBDT,XgBoost,LightGBM,GradientBoostingRegressor
(4)Bagging
集成学习中还有个常见的名词就是Bagging,关于Boosting和Bagging,这篇博客讲得很清楚。
(1)样本选择:Bagging采用的是有放回的取样,而Boosting训练样本则是固定的。
(2)样本权重:Bagging采取的是均匀取样,且每个样本的权重相同,Boosting根据错误率调整样本权重,错误率越大的样本权重会变大。
(3)算法组成:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- gradient + 决策树 = GDBT
2.算法过程
(1)初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
3.算法例子
以李航的《统计学习方法》中的例子为例,这里有10个样本,y=1为正例,y=-1为反例
(1)第一个学习器:首先认为x的权重是一样的,即每一个数据同等重要
对阈值进行遍历,阈值v取2.5(红线)时分类误差率最低(此时x=6,7,8的数据被错分为反例),误差为它们的权重之和e=0.1+0.1+0.1=0.3,此时的学习器为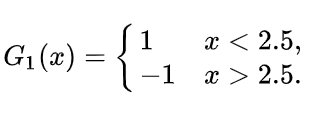
(2)根据误差e计算公式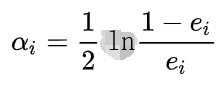
得到系数α=0.4236
(3)更新训练数据的权值分布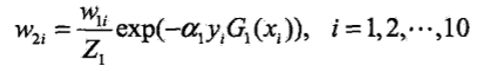
Z是规范化因子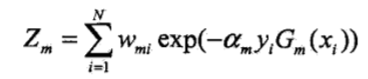
这里Z计算式子的各个符号如下:
【1】w表示权重,第一轮均为0.1
【2】α表示系数,均为α=0.4236
【3】y表示真实值,例如y=1
【4】G(x)表示将样本x分到哪一类了,例如这里G(x)=1,表示被分到正类了
这样就完成了对第一轮系数的更新,更新后的系数如下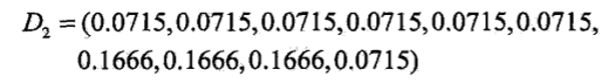
注意观察系数,可以看到前面被正确分类的系数小,被错误分类的系数大,这是希望能把之前经常分类错误的数据能在下一个个体学习器分类正确。
可以写出第一轮之后的分类器(G(x)表达式前面已给出)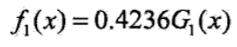
自此,第一个学习器完成。按照这个步骤完成第二个学习器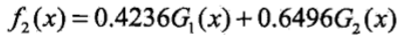
第二个学习器由于有三个仍旧是被错误分类,因此需要继续往下走,第三个分类器为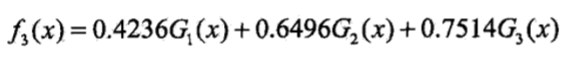
由于第三个学习器错误样本数为0,因此可以得到最终分类器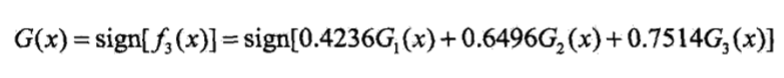

若有收获,就点个赞吧
0 人点赞
