1.随机梯度下降SGD
(1)产生背景
在前面的梯度下降(PS:前面的那种梯度下降其实也称之为BGD,Batch Gradient Descent)中,我们将损失函数写为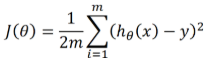
然后对这个函数求关于θ的偏导。它的最大劣势在于计算量太大,因为它要做m个加法运算,试想我们的功率预测业务中,用30天的数据进行建模,那么就要进行30*96次加法才能得到这个求和,得到这个求和求完偏导之后并没有完事儿,这只是进行了一次的寻参迭代。事实上,在随机梯度下降中,是需要进行多次的迭代,才能找到最佳的参数θ的,所以必须得对BGD进行一个改进,才能最终实际运用。
(2)算法过程及原理
随机梯度下降算法一共分为两步:
(1)将m个训练样本随机打乱,重新排列
(2)对m个训练样本进行遍历,不断调整参数θ
具体什么意思呢?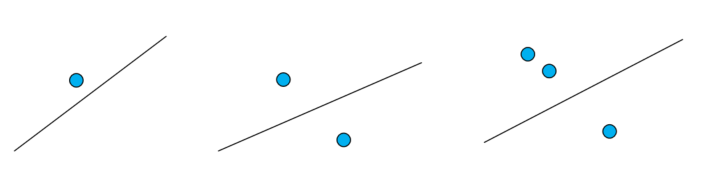
上图中,最开始一个样本的时候,我们的直线如图所示;增加一个样本,直线调整;再增加一个样本,再调整直线。在下山模型中,它在找最低点的过程可能是这样的,最后可能移动的位置非常靠近全局最小值,这样的θ值其实也是非常不错的。
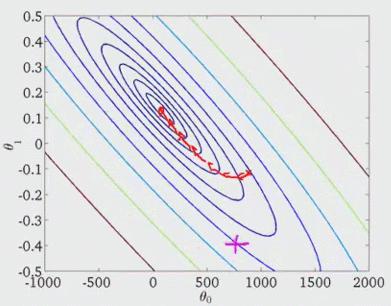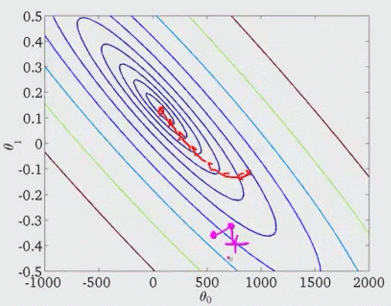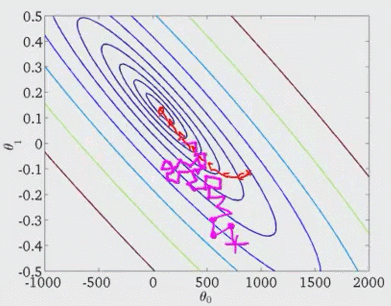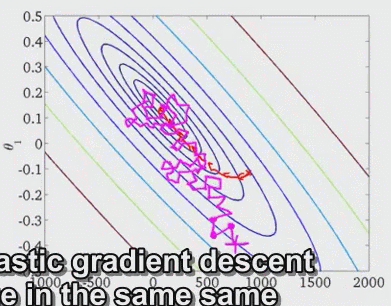
(3)mini-batch SGD
SGD随机梯度下降法对经典的梯度下降法有了极大速度的提升。但有一个问题就是由于过于自由导致训练的loss波动很大。于是小批量梯度下降法, mini-batch gradient descent 便被提了出来。其主要思想就是每次只拿总训练集的一小部分来训练,比如一共有5000个样本,每次拿100个样本来计算loss,更新参数。50次后完成整个样本集的训练,为一轮(epoch)。由于每次更新用了多个样本来计算loss,就使得loss的计算和参数的更新更加具有代表性。不像原始SGD很容易被某一个样本给带偏 。loss的下降更加稳定,同时小批量的计算,也减少了计算资源的占用。
2.AdaGrad
AdaGard(adaptive gradient algorithm,自适应梯度下降),它的学习率α是一直在不断变化中的。
(1)产生背景
在SGD算法中,学习率α是固定不变的,这样有什么不好呢?
假设我们的下山过程如图所示,它可以看作是沿着纵轴b和横轴w的下降,并且此时沿着纵轴b的下降是大于沿着横轴的下降的,由于沿着纵轴的下降是无效的(山底在红点),如何调整呢?
(2)AdaGrad算法

AdaGrad算法与普通的sgd算法差别就在于标黄的哪部分,采取了累积平方梯度,采取AdaGrad算法之后,我们在算法中使用了累积平方梯度r=:r + g.g,那么在下次计算更新的时候,r是作为分母出现的,越大的反而更新越小,越小的值反而更新越大,那么后面的更新则会像下面绿色线更新一样,明显就会好于蓝色更新曲线。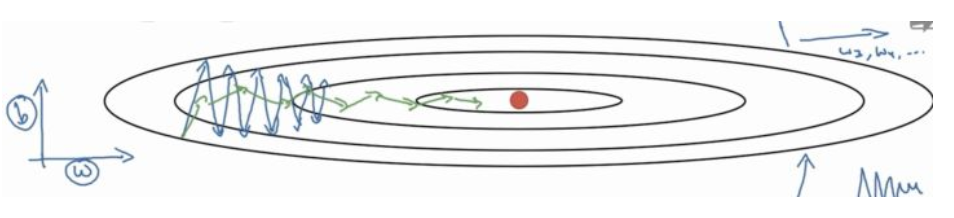
(3)算法优缺点
优点:在参数空间更为平缓的方向,会取得更大的进步:因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小。
缺点:使得学习率过早,过量的减少。
AdaGrad在某些模型上效果不错。
3.RMSProp
(1)RMSProp算法
RMSProp(Root Mean Square Propagation,均方根传播)优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,相比于AdaGrad的历史梯度:
RMSProp增加了一个衰减系数来控制历史信息的获取多少:
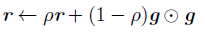

(2)算法优点
4.Adam
(1)Adam算法是什么?
Adam(adaptive moment estimation,适应性矩估计),是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。Adam算法综合了适应性梯度算法(AdaGrad)和均方根传播(RMSProp)的优点。
(2)Adam为啥更好?
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点。Adam 不仅如 RMSProp 算法那样基于一阶矩均值计算适应性参数学习率,它同时还充分利用了梯度的二阶矩均值(即有偏方差/uncentered variance)。具体来说,算法计算了梯度的指数移动均值(exponential moving average),超参数 beta1 和 beta2 控制了这些移动均值的衰减率。移动均值的初始值和 beta1、beta2 值接近于 1(推荐值),因此矩估计的偏差接近于 0。该偏差通过首先计算带偏差的估计而后计算偏差修正后的估计而得到提升。
Adam算法的作者经验性地证明了 Adam 算法的收敛性符合理论性的分析。Adam 算法可以在 MNIST 手写字符识别和 IMDB 情感分析数据集上应用优化 logistic 回归算法,也可以在 MNIST 数据集上应用于多层感知机算法和在 CIFAR-10 图像识别数据集上应用于卷积神经网络。他们总结道:“在使用大型模型和数据集的情况下,我们证明了 Adam 优化算法在解决局部深度学习问题上的高效性。”
5.Momentum
Momentum称之为动量梯度下降法(gradient descent with momentum) ,该算法的迭代更新公式如下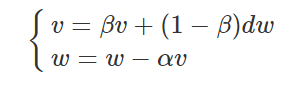
dw是我们计算出来的原始梯度,v则是用指数加权平均计算出来的梯度。这相当于对原始梯度做了一个平滑,然后再用来做梯度下降。实验表明,相比于标准梯度下降算法,Momentum算法具有更快的收敛速度。为什么呢?看下面的图,蓝线是标准梯度下降法,可以看到收敛过程中产生了一些震荡。这些震荡在纵轴方向上是均匀的,几乎可以相互抵消,也就是说如果直接沿着横轴方向迭代,收敛速度可以加快。Momentum通过对原始梯度做了一个平滑,正好将纵轴方向的梯度抹平了(红线部分),使得参数更新方向更多地沿着横轴进行,因此速度更快。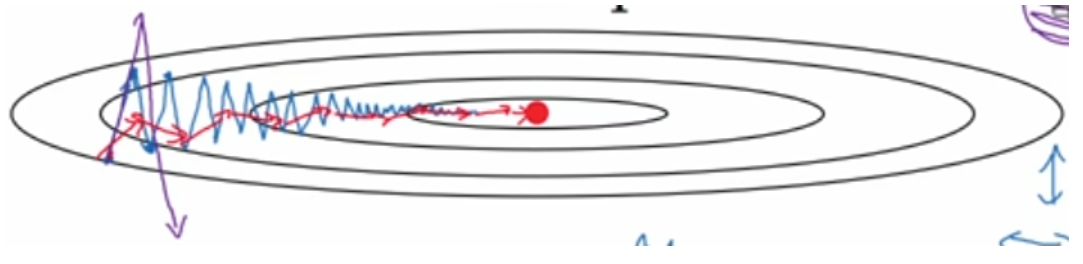
说明:目前对于Momentum,包括mini-batch SGD都是只做了简单的了解,并没有深究。
6.一图总结
梯度下降算法按照batch_size和优化目标可以分类成如下的形式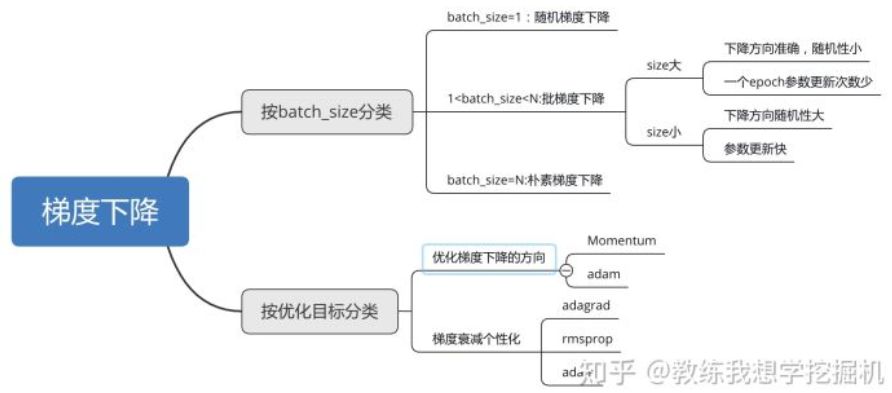

若有收获,就点个赞吧
0 人点赞
