正则表达式一句话概括就是用来对字符串根据自己的规则进行匹配的,可以匹配(返回)出符合自己要求的匹配结果,有人说字符串类的函数也可以,确实是这样,但是字符串的函数对于字符串更多的是处理层面,且不是那么的灵活。而正则表达式的匹配就非常灵活了。
一,C#中使用正则表达式经常使用的类(Regex,MatchCollection,Match)
基本上我们使用正则表达式都会使用到这三个类:
Regex类,这是一个作用于匹配的类,用来定义一个匹配对象,即以何种规则进行匹配。
MatchCollection,这是一个作用于匹配结果集的类,因为既然涉及到匹配那么就可能会匹配出多个结果,这多个结果就可以赋值给匹配结果集(MatchCollection)的对象。
Match,这是一个匹配结果的类,多个匹配结果(Match)组成一个匹配结果集(MatchCollection)。
以上三个类都在命名空间:System.Text.RegularExpressions下,所以在使用正则表达式的时候我们要先引用这个命名空间。
二,正则表达式的简单使用案例:从一个字符串中匹配出所有的邮箱。
比如我们要从字符串“23794大富科世纪东方了djfkasdl@qq.com9548dhf28340385@163.comsdfjsd
2349@sina.com305983&&2”中匹配出所有的邮箱。这要通过字符串自带函数来解决就有点难了,使用正则表达式就非常容易。
解法如下:
//声明这个要被匹配的字符串
string content=”23794大富科世纪东方了djfkasdl@qq.com9548dhf28340385@163.comsdfjsd 2349@sina.com305983&&2”;
//声明匹配规则对象,并设定匹配规则
Regex regex=new Regex(@”[a-zA-Z0-9]+@[a-zA-z0-9]+.com”);//构造方法里面的参数就是匹配规则。
//声明匹配结果集对象
MatchCollection matchs;
//调用匹配多个出多个结果的方法进行匹配,将返回的匹配结果集对象赋值给matchs
matchs=regex.Matches(content);
//输出所有匹配结果
foreach(Match match in matchs)
{
Console.WriteLine(match);
}
Console.ReadKey();
输出结果如下: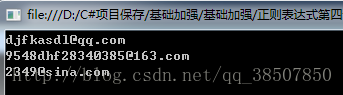
就这样,我们将所有的邮箱匹配出来了,这就是正则表达式的使用的妙处,正则表达式其实最难的就是匹配规则。
下面我们详细介绍正则表达式:
三,正则表达式的匹配规则介绍
所谓正则表达式的匹配规则其实就是一个字符串(充满了各种通配符,各种符号的字符串),这个字符串用来说明要匹配到的字符串的规则,然后匹配过程就是根据自己定义的这个字符串进行匹配去了。
1,正则表达式的通配符。
(1)”\d”这个符号代表从0-9的数字字符。
(2)”\w”代表所有单词字符,包括:大小写字母a-z、数字0-9、汉字(其实我认为是各国文字字符都可以但是身为中国人应该只用到了汉字)、下划线。
(3)”\s”代表任何空白字符,所谓空白字符就是打出来是空白的字符,包括:空格、制表符、换页符、换行符、回车符等等。
(4)”\D”代表任何非数字字符。
(5)”\W”代表任何非单词字符。
(6)”\S”代表任何非空白字符。
(7)”.”代表除换行符(\n)之外的任何字符。
以上这些都是通配符,匹配的范围可以说是很广。需要特别说明的有三点:
第一:通配符”.”因为代表除\n之外的所有字符,所以我们在匹配的时候如果要匹配到”.”就应该用”.“代替,如上面我们匹配邮箱的案例,因为每个邮箱格式肯定是”XXX@XXX.com”里面有一个点,这个点我就用”.“代替了,而不是直接用”.”。
第二:既然我们所用的通配符都有”\”那么在定义正则规则的时候我们肯定要在正则规则字符串前面加@,以表示所有的\都不转义。
第三:正则表达式学起来非常容易,但是无论是几年的程序员还是新手,写正则表达式很容易出错,这些错误笔者总结很大部分来源于通配符的使用,因为通配符实在是表示的范围比较广,我们没有办法掌握,所以在实际使用过程中应该尽量减少通配符的使用而使用我下面介绍的(可选字符集)形式。
2,可选字符集
可选字符集就是定义在某个字符位上允许出现的字符,使用可选字符集的好处就是我们可以对匹配的结果进行更灵活的掌握,弥补了通配符匹配范围太广的不足。这就有点像我们国家对于某些敏感行业的控制,如金融。如果国家方对于这个行业不进行控制,那么以我们国人的智慧不知道会出现多少诈骗犯,多少非法集资。所以我国对于金融是准入制的,就是给你拍照你才能开类似的金融公司,不给你拍照你就不能,这样便于掌握。国家方只需要知道发出去多少牌照就知道有多少个金融的企业在运作。而我们的可选字符集与这个有异曲同工之妙。
可选字符集就是把某个字符位允许出现的字符用[]括起来,[]里面的字符之外的其他字符不就不匹配。
下面介绍一些可选字符集的案例:
案例一:[abc],指定这个字符位可以出现a或者b或者c。
案例二:[123],指定这个字符位可以出现1或者2或者3。
案例三:[a-d],指定这个字符位可以出现a到d的任何字符之一。
案例四:[a-zA-Z],指定这个字符位可以出现大小写字符的a-z
案例五:[a-t1-7],指定这个字符位可以出现小写字母a-t,数字1-7中的任何一个字符。
案例六:[\w\s],指定这个字符位可以出现任何单字字符和任何空白字符之一。
备注:所以所谓的可选字符集就是指定一个字符位可以出现哪个字符。
那么问题又来了,如果我们要指定除0之外的所有字符呢,这样怎么指定,难道把除0之外的字符都写进可选字符集吗,于是就诞生了一个新概念—反向字符集。
3,反向字符集:
反向字符集就是指定一个字符位是除某些字符之外的其他任何字符之一。
案例一:[^a],指定这个字符位可以出现除a之外的任何字符,注意是任何字符,不止是b-z。
案例二:[^abc],指定这个字符位可以出现除小写字母abc之外的任何字符之一。
案例三:[^0-9],指定这个字符位可以出现除0到9之外的任何字符之一。
案例四:[^#],指定这个字符位可以出现除井号之外的任何字符之一。
案例五:[^\w],指定这个字符位可以出现除单词字符之外的任何字符之一。
好,有了以上的知识我们就可以对很多种字符串形式进行匹配了,如我们可以从一个字符串中匹配出”thankyou”,结尾是任何一从2到9个的结果。
案例:从字符串”ashdfkthankyou239523&(&(&(^^^#sjlsdfj29304jd”匹配出”thankyou”。
代码:
//定义要被匹配的字符串
string content1=”ashdfkthankyou239523&(&(&(^^^#sjlsdfj29304jd”;
//定义匹配规则
Regex regex1=new Regex(@”thankyou[2-9]”);
//声明一个匹配结果集对象,并将匹配结果赋值给这个对象
MatchCollection matchs1=regex1.Matches(content1);
//输出匹配结果集
foreach(Match match in matchs1)
{
Console.WriteLine(match);
}
Console.ReadKey();
输出结果: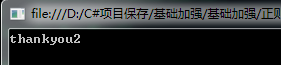
以上是通过对匹配字符串的每个字符位进行限定,那么如果我们想要对几个字符位进行限定,不想一个个的字符进行限定,这样怎么处理呢。
这就需要引入,“或”匹配和限定符了。
4,“或”匹配。
或匹配用来匹配可以出现的某个字符串子串。
案例一:thanyou|thankher,这个指定匹配出thankyou或者thankher。
案例二:(b|tr)ee,这个指定匹配出bee或者tree。
案例三:th(i|a)nk,这个指定匹配出thank或者think。
案例四:book one|two,这个指定匹配出,book one或者two。注意不是book one或者book two。
案例五:book (one|two),这个指定匹配出book one或者book two。
5,限定符
限定符用来限定字符(串)出现的次数。
““限定符:将前面的(一个字符)字符重复零次到多次。
注意是一个字符:如我们用ds对字符串进行匹配,匹配的是d后面跟0到n个s,而不是0到n个ds。
“+”限定符:将前面的(一个字符)字符重复一次到多次。
注意:与唯一的区别就是重复至少一次。
“?”限定符:将前面的(一个字符)重复零次到一次。
“{n}”限定符:将前面的字符重复n次。
“{n,}”限定符:将前面的字符重复至少n次。
“{n,m}”限定符:将前面的字符重复n到m次。
补充:
限定符的懒惰修饰符,以上的限定符默认都是重复尽量多,而在以上的符号后面加”?”就重复尽量少。
如:”?”就是将前面的字符尽量少重复。
案例一:我们用”5?”去匹配字符串”25255255525555”匹配出来的结果是:空,因为后面加了?,这样的匹配规则就是匹配5零次到多次尽量少重复,这样他当然就优先匹配出现零次,这样匹配出来的结果全部是””。
案例二:我们用”5*”去匹配字符串”25255255525555”的话匹配出来的结果不是这样了,因为默认是尽量多重复,所以匹配出来的结果是:
25、255、2555、25555。
通过以上的学习大家肯定就理解了我前面匹配邮箱的那个正则表达式的意义。
下面接着讲:
如果我们要匹配从字符串的开头开始匹配,比如,我们要匹配某个字符串开头的四个字符组成的子串,这个用正则表达式怎么实现呢。
用目前的的正则表达式实现不了,当然,用字符串的函数能够实现,但是如果要用正则表达式的话就得引入一个新概念—-定位符。
6,定位符
定位符用来在正则规则中确定匹配对应的字符串的位置。
“^”定位符,^在定位符中代表匹配字符串的开头位置,注意是开头位置,不是字符串的第一个字符,可以理解为字符串第一个位置之前的小空隙。
“$”定位符,$定位符代表匹配字符串的末尾位置,可以理解为字符串最后一个字符末尾的空隙。
“\b”定位符,匹配单词的边界位置,也是空隙位置,单词的空隙位置可以是:空格,逗号,句号,开头,末尾,”-“等等。
有了定位符的概念我们就可以完成以上的对字符串四个字符的匹配了。
代码:
Regex regex=new Regex(@”^\w{4}”);
7,分组的概念
在匹配邮箱的时候我们也可以使用分组的概念,比如,我们要一次将邮箱全址、邮箱用户名都匹配出来,就可以用到分组的概念。
此时匹配的正则表达式为:@”([a-zA-Z0-9]+)@([a-zA-Z0-9])+.com”。
这个正则表达式我们用到了两个括号,这两个括号就是分组,将正则表达式分成了三组,第0组是整个匹配结果,第1组是第一个括号里面的内容,第二组是第二个括号里面的内容,显而易见,第一个括号里面的内容是用户名(即邮箱地址的@前面的字符串是用户名)。
这样在匹配结果集的每个结果中都有可以通过访问这些分组来访问里面的数据,通过结果Match对象的Groups属性进行访问。
下面是具体案例:从字符串”nihao123@qq.com myemail@163.comasjdfjsdf”中匹配出邮箱和邮箱账号。
代码:
//定义匹配规则
Regex regex=new Regex(@”([a-zA-Z0-9]+)@([a-zA-Z0-9])+.com”);
//定义要被匹配的字符串
string content=”nihao123@qq.com myemail@163.comasjdfjsdf”;
//进行匹配,并返回结果集
MatchCollection matchs=regex.Matches(content);
//输出结果
for(int i=0;i
Console.WriteLine(“匹配到的第{0}个邮箱结果是{1},对应用户名是{2}”,i+1,matchs[i],matchs[i].Groups[1]);
}
Console.ReadKey();
执行截图:
上面的例子我使用了括号进行分组,把用户名写进了第一个括号内,这样就分成了1组,要访问用户名的时候我只需要访问特定结果的Groups分组集合里面的下标为1的元素即可。
事实上在正则表达式中只要出现括号我们就对括号里面的内容开辟了分组,但是分组是额外需要资源的,所以在我们不得不用到小括号,而又不希望对这个括号里面的匹配内容进行分组的时候我们就需要“非捕获分组”这个概念。
比如在上面的匹配邮箱地址和邮箱用户名的例子中我们希望括号里面不匹配到用户名的话正则表达式就可以这样改:
正则表达式:@”(?:[a-zA-Z0-9_]+)@(?:[a-zA-Z0-9])+.com
8,非捕获分组
“?:”此符号放在括号中代表非捕获分组,意思是指定的括号不进行分组功能。
9,”正向预查”和”负正向预查”
在实际开发中比如我们有这样的需求:在信息字符串”张三 性别:男 电话号码:13699866695 李四 性别:女 电话号码:13522693356 王五 性别:男 电话号码:13859596459”中匹配出所有男性的姓名。
当然,这个需求我们用本篇前面的知识是做不到的,因为前面的知识我们仅仅对匹配的字符串进行规则限定,而没有提到对要匹配到的字符串的前面或者后面的字符进行限定。这就需要用到”预查”的概念。
正向预查是对要匹配到的字符串后面的字符或者字符串进行规则限定。
“?=”正向预查:字符串后面的字符(串)进行限定。指定能够出现的字符(串)。
“?!”负正向预查:对字符串后面的字符(串)进行限定,指定不能够出现的字符(串)。
下面我们用”正向预查”来解决上面的问题:
//定义要被匹配的字符串
string content=”张三 性别:男 电话号码:13699866695 李四 性别:女 电话号码:13522693356 王五 性别:男 电话号码:13859596459”;
//定义匹配规则,用正向预查指定要匹配的字符串后面的子串是”性别:男”。
Regex regex=new Regex(@”\b\w+\b(?=\s+性别:男)”);
/正则表达式说明:
第一个\b指要匹配的字符(串)前面的空隙,第二个\b指要匹配的字符(串)后面的空隙。两个\b分隔出一个单词字符串\w+
括号里面的内容代表要匹配的字符串后面必须出现的字符串:\s+代表一个或者多个空字符,后面跟”性别:男”
/
//匹配,并返回匹配结果集进行保存
MatchCollection matchs=regex.Matches(content);
//输出所有匹配结果:
foreach(Match match in matchs)
{
Console.WriteLine(match);
}
//等待用户输出,结束程序
Console.ReadKey();
执行结果:
根据上面的例子不难理解正向预查的概念,那么负正向预查也就自然而然的了解了,负正向预查就是限定匹配结果后面不能出现的字符串。
10,”反向预查”和”负反向预查”
上面的需求如果我们进行修改,修改成匹配出所有性别为男的人的电话号码,正向预查就解决不了这个问题了,因为正向预查是对匹配内容之后的内容进行限定,而我们要对匹配结果之前的内容进行限定的话就不行了。此时我们就需要用到反向预查的概念。
“?<=”反向预查,限定匹配结果之前的字符串,(指定匹配结果之前的字符串必须是哪些)。
“?<!”负反像预查,限定匹配结果之前的字符串,(指定匹配结果之前的字符串必须不是哪些)。
代码:
//定义要被匹配的字符串
string content=”张三 性别:男 电话号码:13699866695 李四 性别:女 电话号码:13522693356 王五 性别:男 电话号码:13859596459”;
//定义匹配规则
Regex regex=new Regex(@”(?<=性别:男\s+\b\w+\b:)\b\w+\b”);
/正则表达式说明:
正则表达式小括号里面的内容指定要匹配的字符串前面必须出现的字符串的正则规则
“?<=”是反向预查符号;”性别:男”是必须出现的字符串;性别男后面跟的”\s+”是”性别:男”后面跟的n(1个或多个)个空格;接着后面的两个\b代表中间的单词的字符分界,在匹配中也就是代表”电话号码”;接着后面跟的”:”代表”电话号码”后面的”:”。
小括号后面的\b\w+\b代表电话号码字符串,其实更准确的应该用”\b\d+\b”因为电话号码肯定都是数字。
*/
//进行匹配并返回结果
MatchCollection matchs=regex.Matches(content);
//输出所有返回结果
foreach(Match match in matchs)
{
Console.WriteLine(match);
}
//等到用户输入任何字符结束程序
Console.ReadKey();
执行结果:
四:正则表达式的相关方法和属性。
1,Regex类的方法和属性
Match()方法:匹配出符合匹配要求的第一个结果,并返回一个Match匹配结果对象。
Matches()方法:匹配出符合匹配要求的所有结果,形成一个结果集,并返回一个MatchCollection匹配结果集对象
IsMatch()方法:进行匹配并返回一个布尔型代表是否有匹配的结果,有则返回true,无则返回false。
以上三个方法的参数都是要被匹配的字符串,也可以是两个参数,两个参数的第一个参数依然是要匹配的字符串,第二个参数是匹配选项。(匹配选项是一个枚举型,指定是否区分大小写等。下面例举一下匹配的选项。)
注意:以上方法都有对应的静态方法,静态方法在这里就只说一个小例子,因为静态方法和动态的方法差不多,只是静态方法是将要匹配的字符串作为第一个参数传入,第二个参数传入参与匹配的正则表达式,第三个是可选参数,指定匹配模式。
静态方法案例:使用正则表达式的静态方法从字符串”你好,我是C#新手,我的姓名是张三”中匹配出姓名。
代码:
//定义要匹配的字符串
string content=”你好,我是C#新手,我的姓名是张三”;
//使用静态方法匹配并返回匹配的结果集
MatchCollection matchs=Regex.Matches(content,@”(?<=我的姓名是)\w+$”);
//输出匹配结果
foreach(Match match in matchs)
{
Console.WriteLine(match);
}
//等待用户输入结束程序
Console.ReadKey();
执行结果: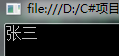
2,RegexOptions选项的枚举的常用值:
RegexOptions.IgnorePatternWhitespace:消除匹配正则中的所有非转义空白。
RegexOptions.IgnoreCase:指定该正则表达式不区分大小写。
RegexOptions.Multiline:多行模式,使用该模式会改变^和$的含义,^和$将不再是匹配字符串的开头和结尾,而是匹配每行的开头和结尾,系统默认的是单行模式。
RegexOptions.RightToLeft:匹配从右到左进行,而不是从左到右进行。
Split()方法:匹配出对应的字符串,并用这些字符串进行分割,返回的是一个string类型的数组。
案例:将字符串”内容一(内容二%&内容三#内容四/内容五”分解成N多个子串,去掉所有的符号。
代码:
//定义要分解的字符串
string content=”内容一(内容二%&内容三#内容四/内容五”;
//使用Split静态方法分解,并返回字符串数组
string[] newContents=Regex.Split(content,@”[%&#/
]+”);
//输出分解结果:
for(int i=0;i
Console.WriteLine(newContents[i]);
}
//等待用户输入任意字符结束程序
Console.ReadKey();
执行结果: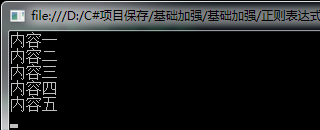
Replace()方法:用指定的字符串替换字符串中符合匹配规则的子串,返回替换后的新字符串。
案例:将上例字符串中的”内容”替换为”姓名”。使用正则表达式。这个例子用正则表达式的非静态方法解决。
代码:
//定义要被匹配的字符串
string content=”内容一(内容二%&内容三#内容四/内容五”;
//定义要匹配的正则
Regex regex=new Regex(@”内容”);
//匹配内容,并进行替换,接收返回的替换后的字符串
string result=regex.Replace(content,”姓名”);
//输出匹配内容
Console.WriteLine(result);
//等待用户输入任何字符结束程序
Console.ReadKey();
执行结果:
3,MatchCollection类的常用属性和方法
对于MatchCollection类的常用属性和方法我们经常用到的只有Count属性。返回MatchCollection集合的Match对象个数,该属性常用于查询符合要求的匹配的个数。
4,Match类的常用属性和方法:
常用属性:
Value属性:匹配的的值。前面我们用Console.WriteLine(match);语句输出的其实都是Value属性的值。语句Console.WriteLine(match)等价于Console.WriteLine(match.Value)。
Groups属性:该属性是一个string类型的集合,保存匹配时候用小括号匹配的内容,用小括号匹配的内容用分组的形式储存在了对应Match对象的Groups属性中作为一个元素储存了。我们可以通过Match对象.Groups[下标]的形式访问分组的数据。
Length属性:该属性对应匹配到的子串的长度。
常用方法:
Match类对象的常用方法只有一个:
NextMatch()方法。用来从前面的匹配的位置进行下一个匹配。
关于正则表达式笔者已经详细介绍完了,相信从头到尾阅读了本篇文章的朋友能够使用正则表达式了。

若有收获,就点个赞吧
0 人点赞
