- 提纲
- 学习获得
- 学习路径
- 培训目标
- 互联网发展的四个阶段
- 面向安全的类的总结
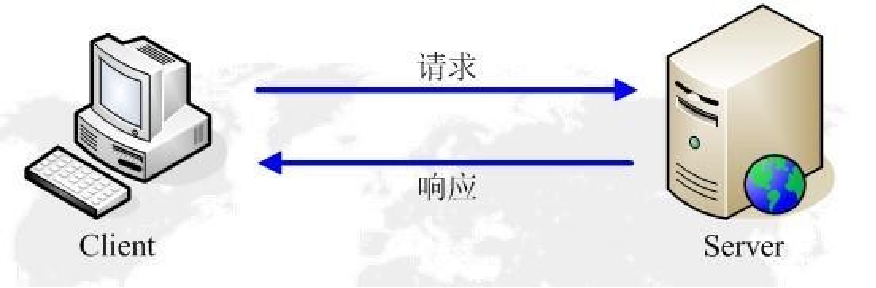
- 网络基础知识篇之HTTP与TCPIP协议
- HTTP举例
- HTTP协议概述
提纲
- 从历史看本质网络协议http深入讲解与剖析
(上)网络协议http深入讲解与剖析 (下)http字段安全及分析要点
- http 输出与交互的安全分析
- http 工具类软件演示
- http安全防护+waf合并讲解安全类产品含waf(选讲)
- http延展+websocket安全其他安全延展(选讲)
学习获得
1.通过本次学习,可以对安全学习方向和脉络有详细的认识和把控
2.通过本次学习,可以更加深刻的认识和理解HTTP协议的本质
3.通过本次学习,可以帮助学习者对SQL注入攻击的本质有深刻的了解
4.通过本次学习,可以让学习者深刻理解HTTP类的应用数据交互对网络安全的风险认知
5.通过本次学习,学员可以定向学习到HTTP方面的主流安全工具,从而面向实战和分析HTTP的安全问题
6.通过本次学习,学员可以从本质上认识HTTP类的防护的选型方向及各种优缺点
7.通过本次学习,学员可以对HTTP类的攻击形态及攻击手法有了本质的认识,对未来的web安全类防护打下扎实的基础
学习路径
开源防护框架及OWASP TOP 10 安全实践网络协议概要及综述
视频分享
实用类工具的教学演示
Wiresharks
Tcpdump+wireshark结合
Etherdect
Network Monitor
培训目标
让培训者从系统的角度来学习网络安全,打好思维的基础
让不懂网络安全的人,明白网络安全的来龙去脉
让略懂网络安全的人,更加确定自己的学习方向
让懂网络安全的人可以延展自己的其他安全方向
互联网发展的四个阶段
(互联网的发展历程,实际上就是互联网、大数据、人工智能与实体经济融合发展过程。具体来说,互联网发展经历了四个阶段)
第一 互联网1.0阶段完成了传统广告业数据化
第一个阶段,互联网1.0阶段,也称为只读互联网阶段。在这一阶段,互联网与传统广告业结合,通过数据化,使传统广告业转化为数字经济。雅虎,谷歌,网易为代表的企业。特点:网站少,都是企业级别的网站,个人网站处于发展初期。
第二 互联网2.0阶段完成了内容产业数据化
互联网2.0阶段:内容产业数据化(重点认知)。第二个阶段,互联网2.0阶段,也称为可读写互联网阶段。在这一阶段,内容产业完成数据化改造。
(一)维基百科 (二)微博和微信朋友圈
总之,在互联网2.0阶段,数字技术对内容产业完成了数据化改造,使内容产业的产和销由分离趋于融合,基本达到产销合一。各大类网站层出不穷,门户站,行业站,个人站,娱乐站等等。。。
第三 移动互联网阶段完成了生活服务业数据化
第三个阶段称为移动互联网阶段。在这一阶段,移动互联网对几乎所有的生活服务业进行了数据化改造。特点:手机应用,APP商城,公众号,小程序等服务生活类应用。
第四 万联网阶段,就是万物皆可相连,一切皆被数据化
前三个阶段,互联网都是围绕人在发展,统称为人联网。那么接下来的问题是,既然人都联网了,那一只猪、一条狗要不要联网,一张桌子、一把椅子要不要联网,世界上的万事万物要不要联网?答案是要。这是一个发展趋势,未来很可能会出现猪联网、狗联网、桌联网等。所以说,未来是一个万物互联的万联网阶段。在这一阶段,可能会在猪联网的基础上诞生猪付宝这样的新兴业务,也可能在狗联网的基础上出现滴滴打狗这样的平台,等等。数据会慢慢赋予本没有生命的东西以生命,会让已经有生命的东西变得更加有灵性。也就是说,所有一切在这一阶段都有可能被数据化。特点:万物互联,物联网协议!
附加:物联网协议了解(注意:应用层协议里也含有HTTP WEB类协议)
总而言之,推动互联网、大数据、人工智能与实体经济深度融合,将会产生新动能,开辟新领域,也必将会使我国发展迎来新篇章。
面向安全的类的总结
Web承载了互联网发展的整个过程,占据一席之地。其体量不可小觑。必须重点认知和对待。Web化企业,WEB端口,web承载业务。
网络基础知识篇之HTTP与TCPIP协议
HTTP
HTTP:HyperText Transfer Protocol 超文本传输协议。
web使用一种名为HTTP的协议作为规范,完成客户端到服务器端等一系列运作流程。而协议是指规则的约定。可以说,web是建立在HTTP协议上通信的。
通常使用的网络是在TCP/IP协议族的基础上运作的。而HTTP属于它内部的一个子集。
TCP/IP协议族
- 计算机与网络设备要相互通信,双方就必须基于相同的方法。
- 比如,如何探测到通信目标,由哪一边先发起通信,使用哪种语言进行通信,怎样结束通信等规则都需要事先确定。不同的硬件,操作系统之间的通信,所有的这一切都需要一种规则。而我们就把这种规则称为协议。
- 像这样把与互联网相关的协议集合起来总称为TCP/IP。
TCP/IP的分层管理
TCP/IP协议族按层次分别分为四层:应用层,传输层,网络层,数据链路层。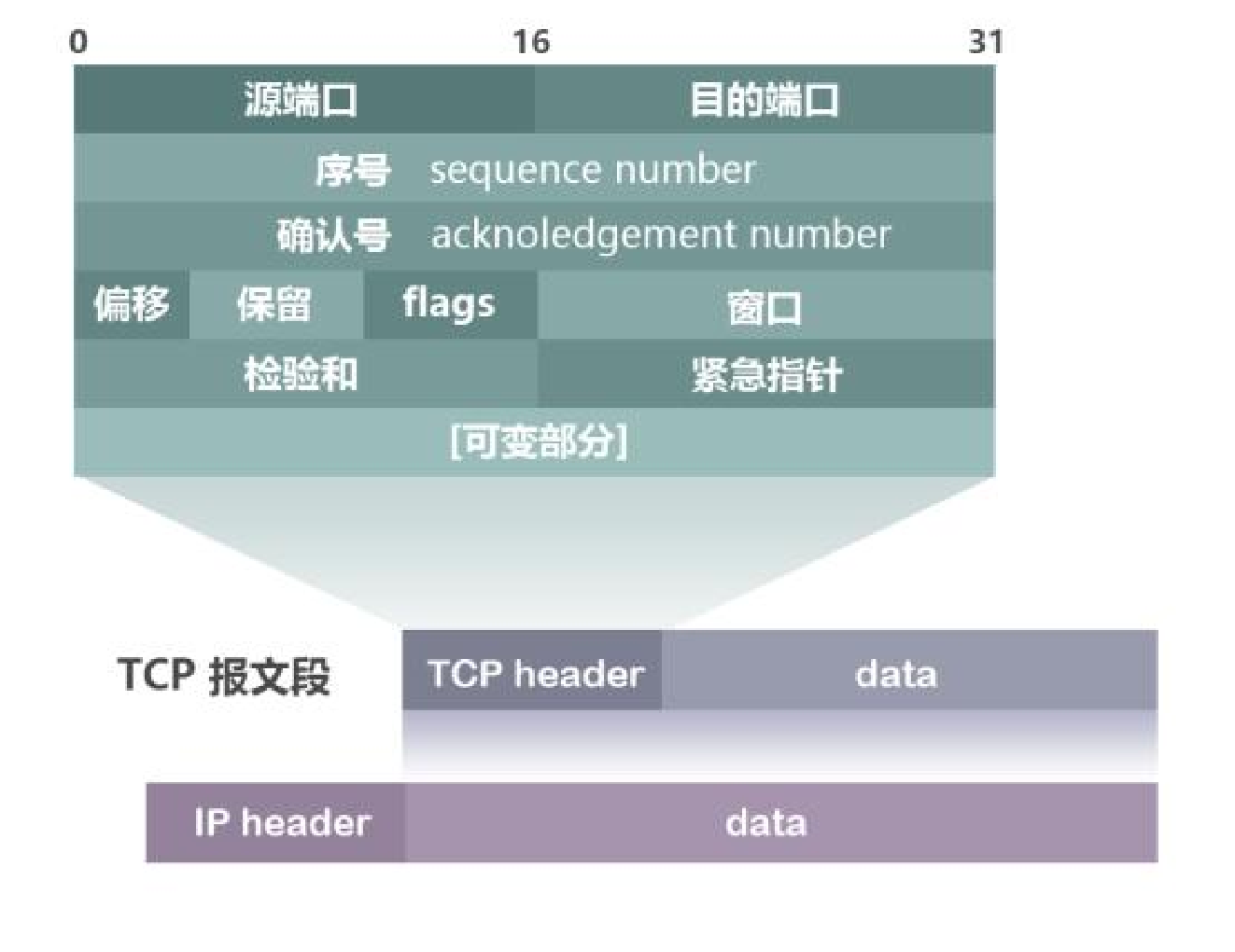
应用层
应用层决定了向用户提供应用服务时通信的活动。
TCP/IP协议族内预存了各类通用的应用服务。比如,FTP(File Transfer Protocol,文件传输协议)和DNS(Domain Name System,域名系统)服务就是其中两类。HTTP协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。在传输层有两个性质不同的协议:TCP(Transmission Control Protocol,传输控制协议)和UDP(User Data Protocol,用户数据报协议)。
网络层:(又名网络互联层)
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,并把数据包传送给对方。
与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输路线。
链路层:(又名数据链路层,网络接口层)
用来处理连接网络的硬件部分。包括控制操作系统,硬件的设备驱动,NIC(Network Interfa Card,网络适配器,即网卡),即光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
TCP/IP通信传输流
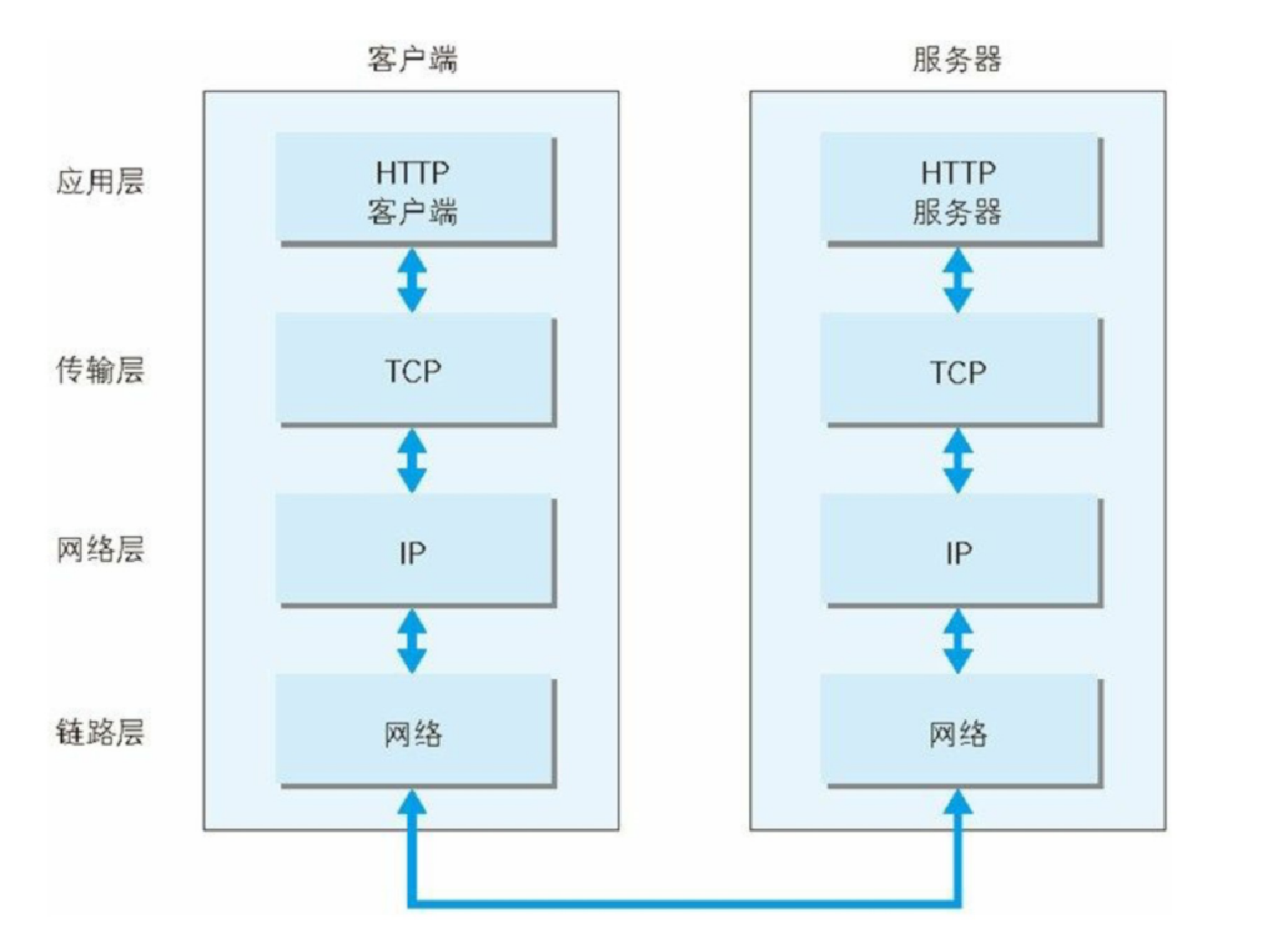
利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行沟通。发送端从应用层往下走,接收端则往应用层往上走。认真理解,有助于我们后面的协议分析!
HTTP举例
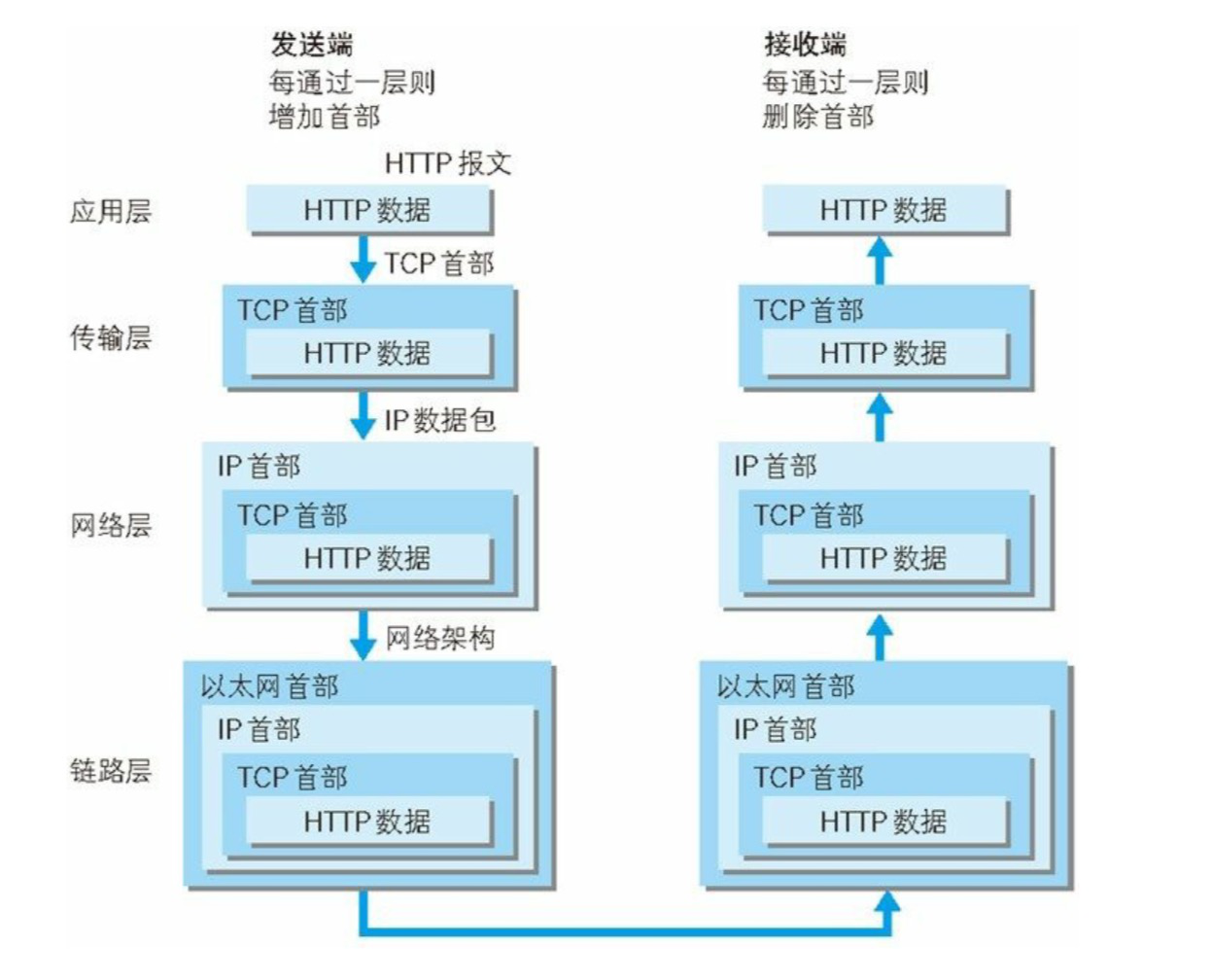
- 首先作为发送端的客户端在应用层(HTTP协议)发出一个想看某个web页面的HTTP请求。
- 接着,为了传输方便,在传输层(TCP协议)把从应用层收到的数据(HTTP请求报文)进行分割,并在各个报文上打上标记序号及端口号后转发给网络层。
- 在网络层(IP协议),增加作为通信目的地的MAC地址后转发给链路层。这样一来,发往网络的通信请求就准备齐全了。
- 接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层。当传输到应用层,才能算真正接收到由客户端发送过来的HTTP请求。
换个方式去理解HTTP
一次HTTP操作称为一个事务,其工作过程可分为四步:
- 首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
- 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
- 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
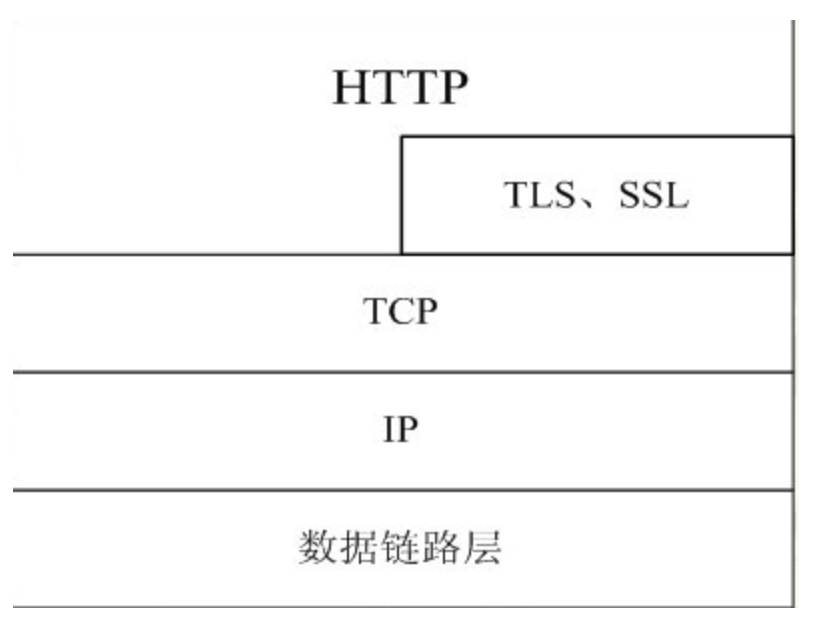
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
封装(encapsulate)
- 发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部信息去掉。(特别注明:用具体的长度字段来分割,路由器后续怎么处理?!)
- 这种把数据信息包装起来的做法称为封装(encapsulate)(inˈkæpsjuleɪt) 。
HTTP协议概述
TCP上层的应用层协议
- HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
- HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
- HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。
- HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
主要特点
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。更多的方法后面说。
- 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。支持B/S及C/S模式。
HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息。
URL(Uniform Resource Identifiers, URI)
http://www.qq.com:8080/news/index.jsp?boardID=5&ID=24618&page=1#name
从上面的URL可以看出,一个完整的URL包括以下几部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在”HTTP”后面的“//”为分隔符
- 域名部分:该URL的域名部分为“www.qq.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
- 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源。
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。URL一般由三部组成:
①协议(或称为服务方式) ②存有该资源的主机IP地址(有时也包括端口号) ③主机资源的具体地址。如目录和文件名等
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的,URI一般由三部组成:
- 访问资源的命名机制
- 存放资源的主机名
- 资源自身的名称,由路径表示,着重强调于资源。
URN,uniform resource name,统一资源命名,是通过名字来标识资源, 比如 mailto:java-net@java.sun.com
- URI是以一种抽象的,高层次概念定义统一资源标识,而URL和URN则是具体的资源标识的方式。URL和URN都是一种URI。笼统地说,每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源。上面的 mailto、news都是 URN 的示例。
- 在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
- 在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。
- 相反的是,URL类可以打开一个到达资源的流。
HTTP之请求消息Request
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。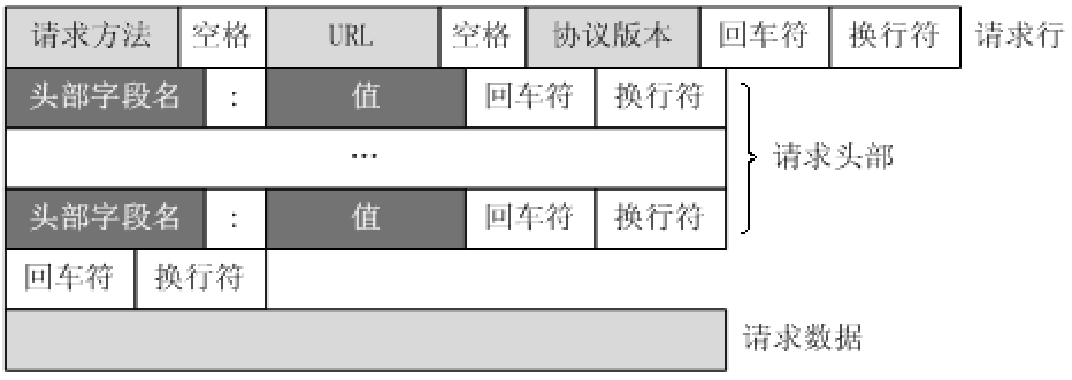
Get请求文字示例
GET /562f25980001b1b106000338.jpg HTTP/1.1 Host: img.mukewang.com User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36Accept: image/webp,image/,/*;q=0.8 Referer: http://www.qq.com/ Accept-Encoding: gzip, deflate, Accept-Language: zh-CN,zh;q=0.8
GET示例释义
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本。GET说明请求类型为GET, /562f25980001b1b106000338.jpg为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。从第二行起为请求头部,HOST将指出请求的目的地,User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的,即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。
HTTP头: Accept-Language
Accept-Language:表示浏览器所支持的语言。
当我们在开发国际化的网站时,后端接口的信息需要根据用户所使用的语言返回对应的内容。作为后端我需要前端在请求头的Accept-Language属性声明需要返回的语言。
Accept-Language: zh-cn,zh;q=0.5意思: 支持的语言分别是简体中文和中文,优先支持简体中文。zh-cn:表示简体中文,zh:表示中文(包括简体中文,繁体中文)
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8意思:优先支持中文,如果没有中文则支持英文。q:表示他之前语言的权重, 0 <= q <= 1
Accept-Language: zh-cn;q=0.8,en-US;q=0.9意思:优先支持英文,如果没有英文则支持中文。
Accept-Language: zh-cn;q=0.8,en-US;q=0.6意思:优先支持中文,如果没有中文则支持英文。
Accept-Language: *意思: 支持所有语言
POST请求例子
POST / HTTP1.1 Host: www.163.com User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type: application/x-www-form-urlencoded Content-Length: 40 Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
POST请求释义
第一部分:请求行,第一行说明了是post请求,以及http1.1版本。
第二部分:请求头部,第二行至第六行。
第三部分:空行,第七行的空行。
第四部分:请求数据,红色字体部门,第八行。
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。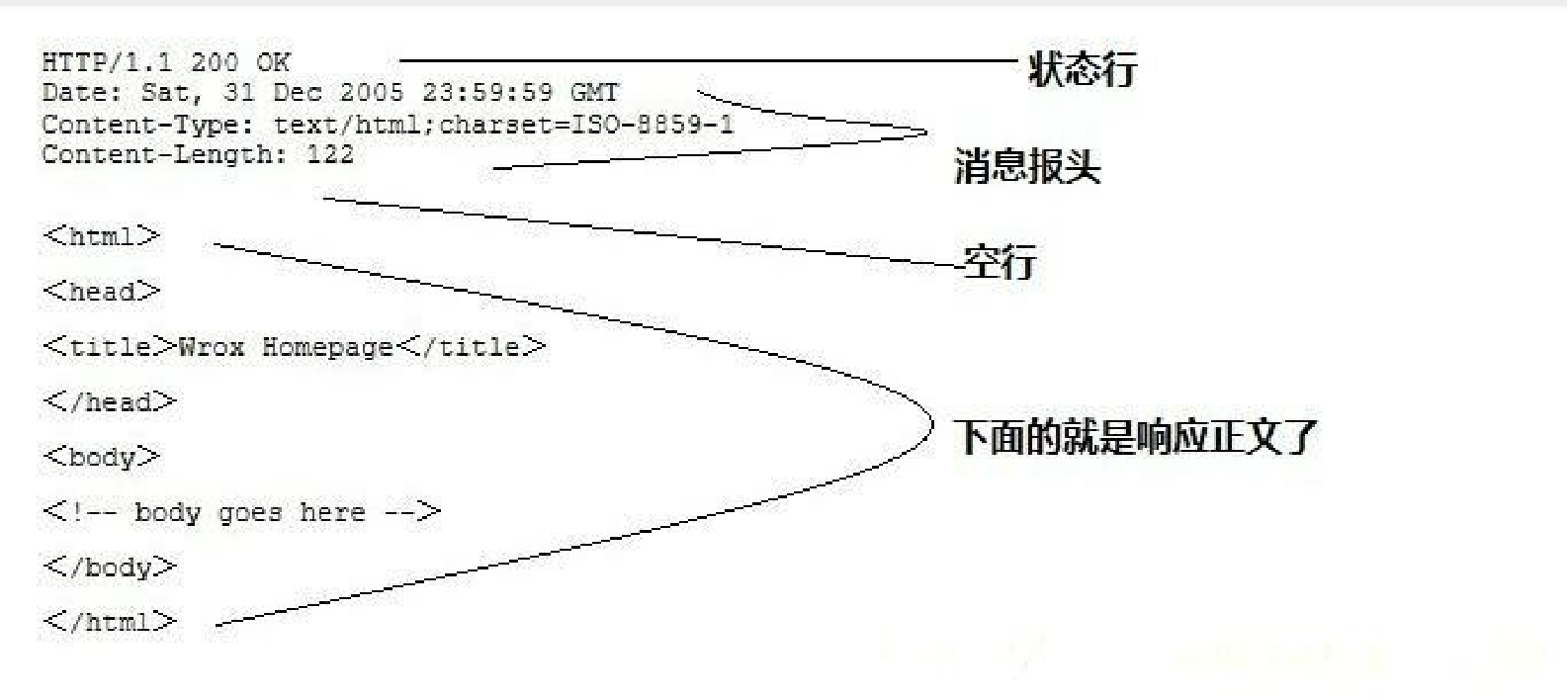
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)。
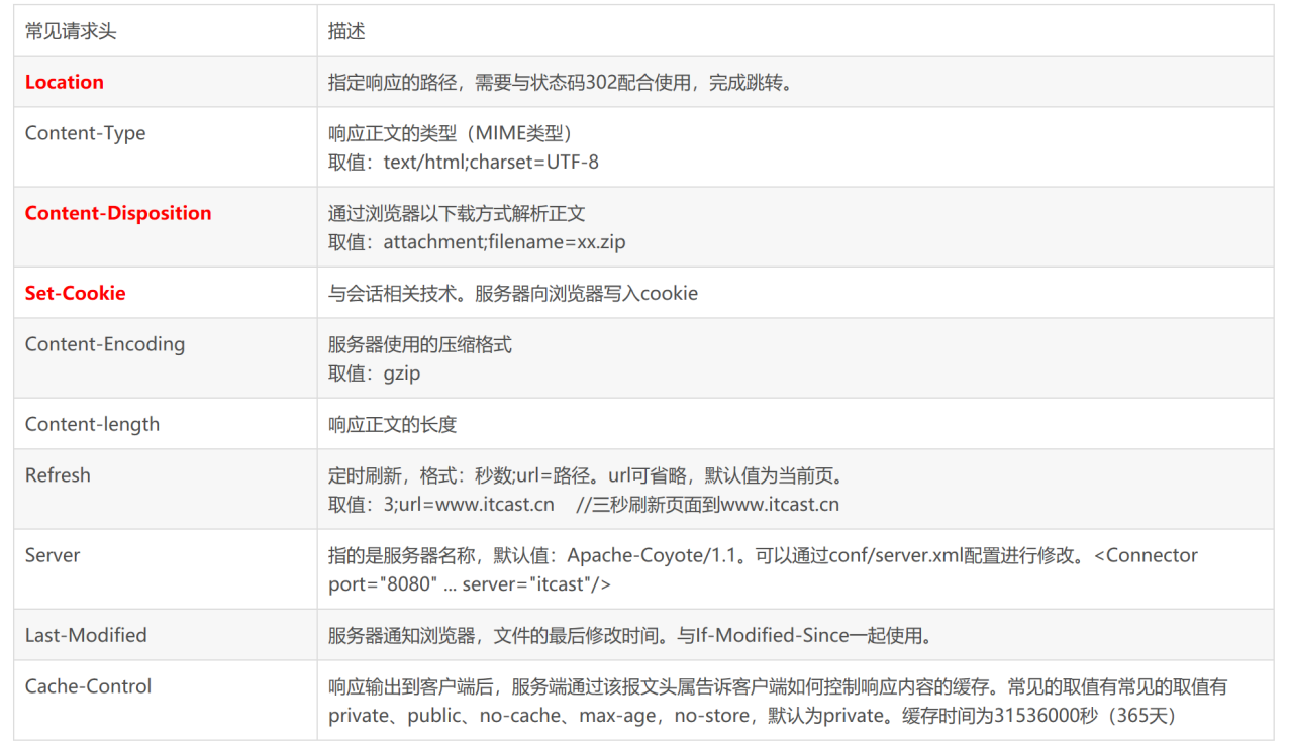
第二部分:消息报头,用来说明客户端要使用的一些附加信息 第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8。
第三部分:空行,消息报头后面的空行是必须的。
第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
Firefox F12 响应头实看
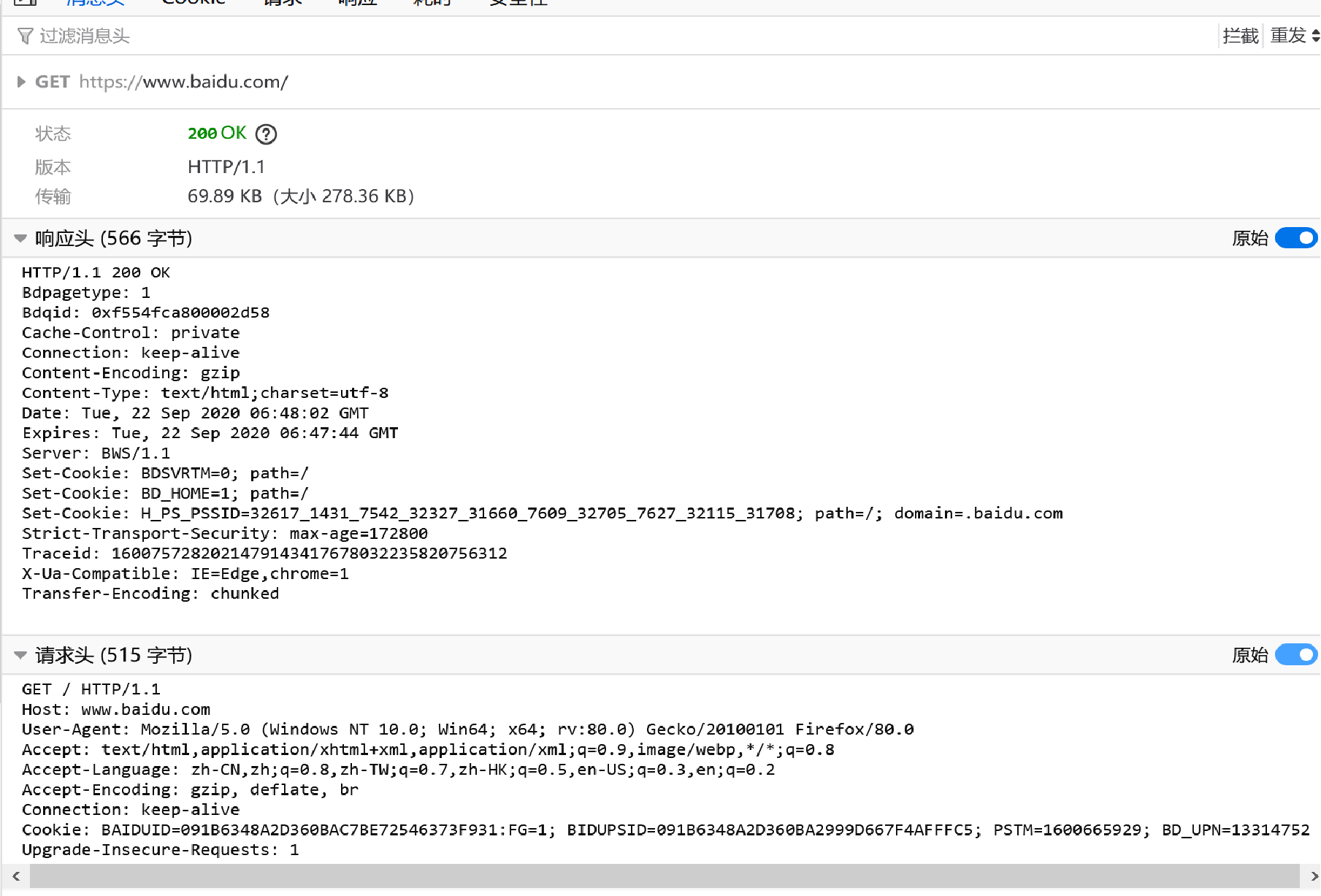
HTTP之状态码
获得此次请求的状态信息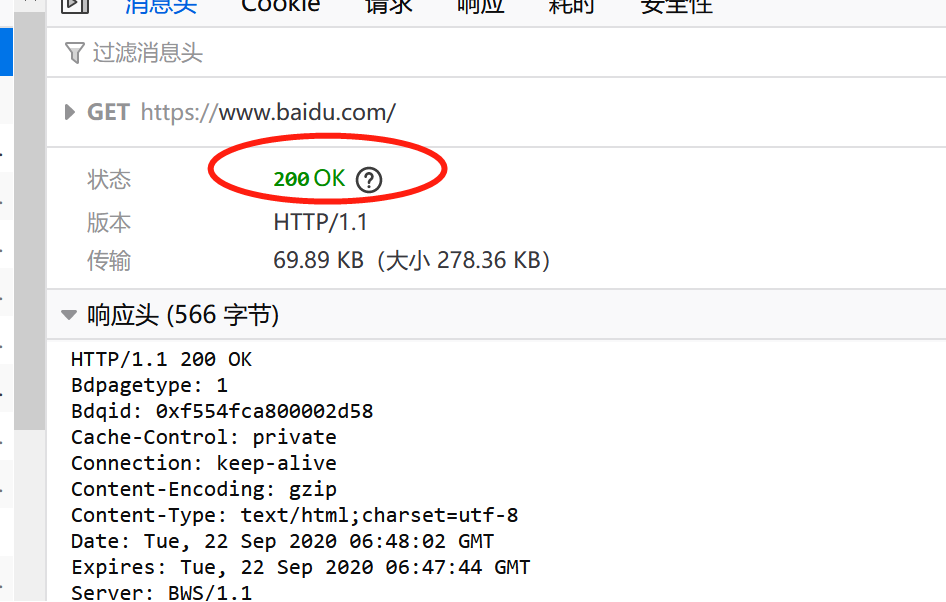
状态码 200 OK 表明请求已经成功. 默认情况下状态码为200的响应可以被缓存。
不同请求方式对于请求成功的意义如下:
- GET: 已经取得资源,并将资源添加到响应的消息体中。
- HEAD: 响应的消息体为头部信息。
- POST: 响应的消息体中包含此次请求的结果。
- TRACE: 响应的消息体中包含服务器接收到的请求信息。
- PUT 和 DELETE 的请求成功通常并不是响应200 OK的状态码而是 204 No Content 表示无内容(或者 201 Created表示一个资源首次被创建成功)。
HTTP响应报文

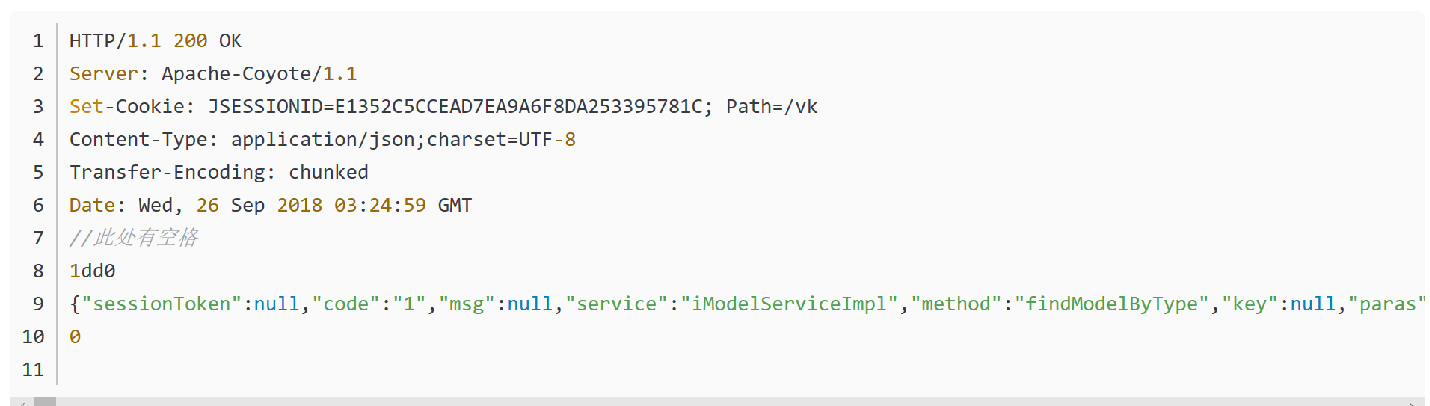
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息—表示请求已接收,继续处理 2xx:成功—表示请求已被成功接收、理解、接受 3xx:重定向—要完成请求必须进行更进一步的操作 4xx:客户端错误—请求有语法错误或请求无法实现 5xx:服务器端错误—服务器未能实现合法的请求
重点延展学习: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status/200
常见具体状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解 401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden //服务器收到请求,但是拒绝提供服务 404 Not Found //请求资源不存在,eg:输入了错误的URL 500 Internal Server Error //服务器发生不可预期的错误 503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
HTTP请求方法(附加学习,不作要求)
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法: OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
延展学习:课后学习HTTP 2.0的新特性
HTTP2.0性能增强的核心:二进制分帧https://blog.csdn.net/u011904605/article/details/53012844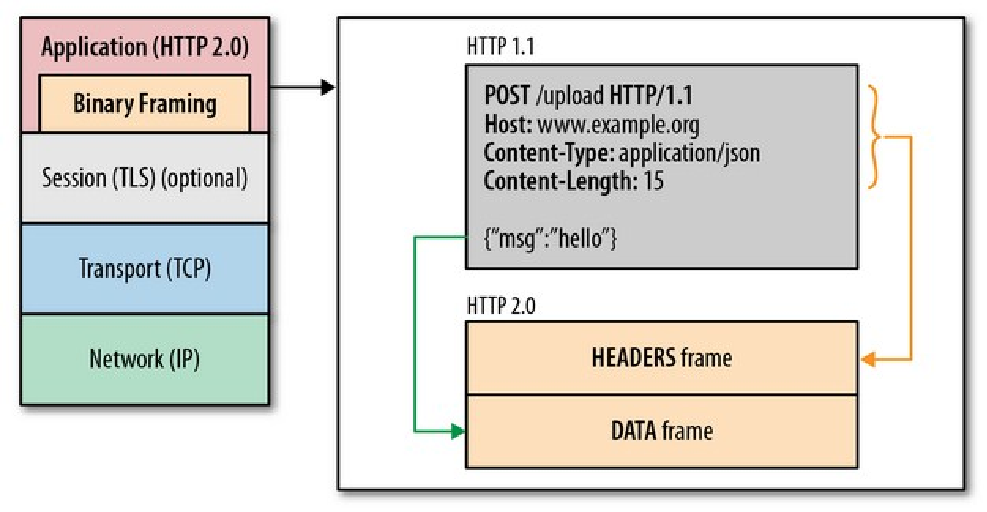
HTTP工作原理详解
- 客户端连接到Web服务器一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.mysite.cn。
- 发送HTTP请求通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
- 服务器接受请求并返回HTTP响应Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
- 释放连接TCP连接若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
- 客户端浏览器解析HTML内容客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;6、浏览器将该 html 文本并显示内容;
GET和POST请求的区别
GET请求
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
[空行]
注意最后一行是空行
POST请求
POST / HTTP/1.1Host: www.mysite.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alivename=Professional%20Ajax&publisher=Wiley
1.GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456。POST方法是把提交的数据放在HTTP包的Body中;
2.GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制; 3.GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值; 4.GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码。
GET提交数据会在地址栏中显示出来,POST提交地址栏不会改变。
GET提交
请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。
如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据。
传输数据的大小
首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET: 特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。因此对于GET提交时,传输数据就会受到URL长度的限制。
POST: 由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
GET & POST 安全性对比(相对)
POST的安全性要比GET的安全性高。
比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为:
- 登录页面有可能被浏览器缓存
- 其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了
除此之外,使用GET提交数据还可能会造成Cross-site request forgery(csrf)攻击(后面会提及)
get,post,soap协议运行在http上
- get:请求参数是作为一个key/value对的序列(查询字符串)附加到URL上的查询字符串的长度受到web浏览器和web服务器的限制(如IE最多支持2048个字符),不适合传输大型数据集同时,它很不安全
- post:请求参数是在http标题的一个不同部分(名为entity body)传输的,这一部分用来传输表单信息,因此必须将Content-type设置为:application/x-www-form- urlencoded。post设计用来支持web窗体上的用户字段,其参数也是作为key/value对传输。但是:它不支持复杂数据类型,因为post没有定义传输数据结构的语义和规则。
- soap:是http post的一个专用版本,遵循一种特殊的xml消息格式.Content-type设置为: text/xml,任何数据都可以xml化。xml用的多了,soap的名分给它。
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET,POST,PUT,DELETE. 一个URL地址用于描述一个网络上的资源,而HTTP中的GET, POST, PUT, DELETE就对应着对这个资源的查,改,增,删4个操作。 我们最常见的就是GET和POST了。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息.
安全总结:上述讲述的http协议组成的方方面面,在每一处都存在其安全风险点。回顾一下,列举你能想到的安全风险点。

若有收获,就点个赞吧
0 人点赞
