命令启动spider
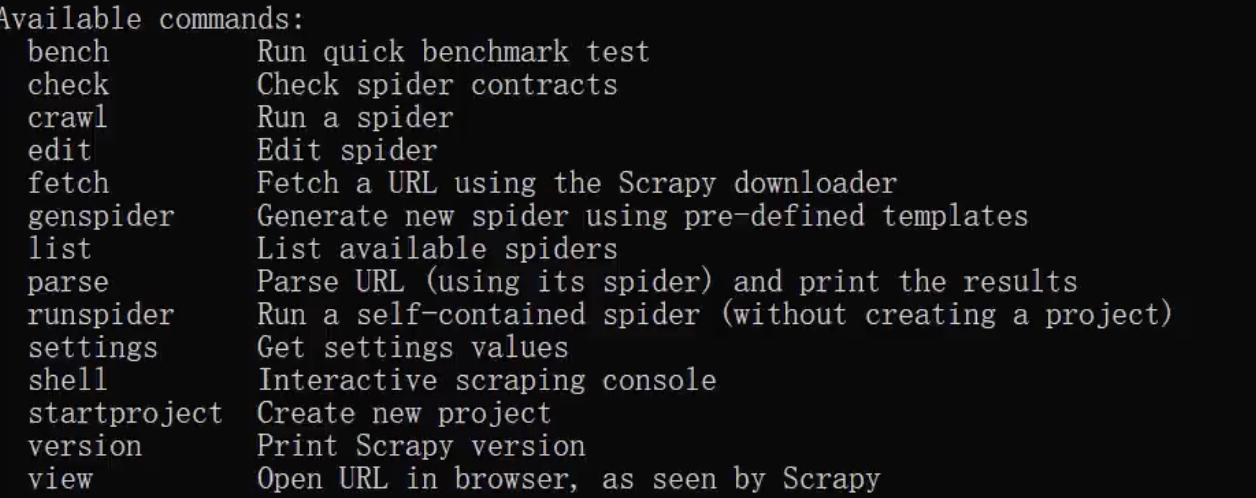
crawl命令
启动spider爬虫
scrapy crawl 爬虫名
脚本启动spider
脚本启动要比命令启动方便,因为脚本启动就归pycharm管理,更方便我们进行调试
from scrapy.cmdline import executeimport sysimport ossys.path.append(os.path.dirname(__file__))execute(["scrapy","crawl","jobbole"])# _file_ 函数会返回当前python文件的绝对路径# os.path.dirname() 函数返回当前文件所在目录的绝对路径
注意:在有的python版本中,file函数可能不返回当前文件的绝对路径,而是返回文件名,最保险的方式是用os.path.abspath(__file__)来替代file。
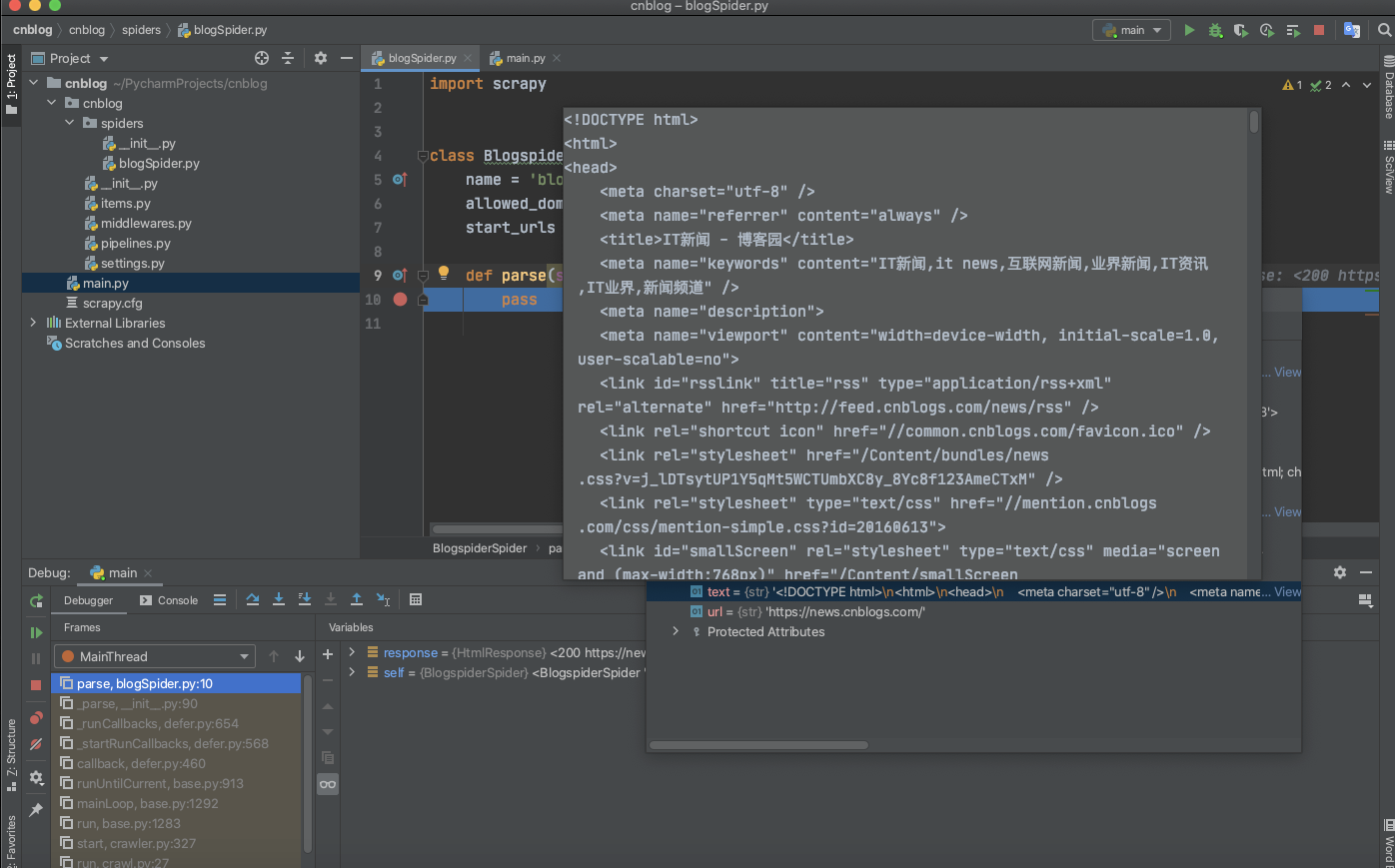
debug试试
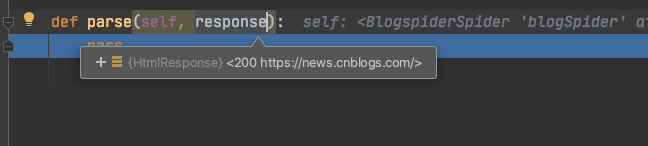
debug一下脚本看看这个程序大概发生了什么?
目标页面的源码被scrapy下载下来了,并且保存在response参数中。
import scrapyclass BlogspiderSpider(scrapy.Spider):name = 'blogSpider'allowed_domains = ['news.cnblogs.com']start_urls = ['http://news.cnblogs.com/']def parse(self, response):pass

若有收获,就点个赞吧
0 人点赞
