简介
css选择器和xpath选择器都属于lxml,lxml是c语言开发的,最接近底层的东西运行效率很高,所以css选择器也可以学习一下,它的选择器语法和我们前端的选择器语法是如出一辙的,对于学过css的人来说,这块学习起来基本就是0成本,但是xpath应该作为首选,在scrapy底层中也基本上是将css选择器转换成xpath选择器
案例
这边调用的是css方法
import scrapyclass BlogspiderSpider(scrapy.Spider):name = 'blogSpider'allowed_domains = ['news.cnblogs.com']start_urls = ['http://news.cnblogs.com/']def parse(self, response):url = response.css("div#news_list h2 a::attr(href)").extract()[0]print(url)pass
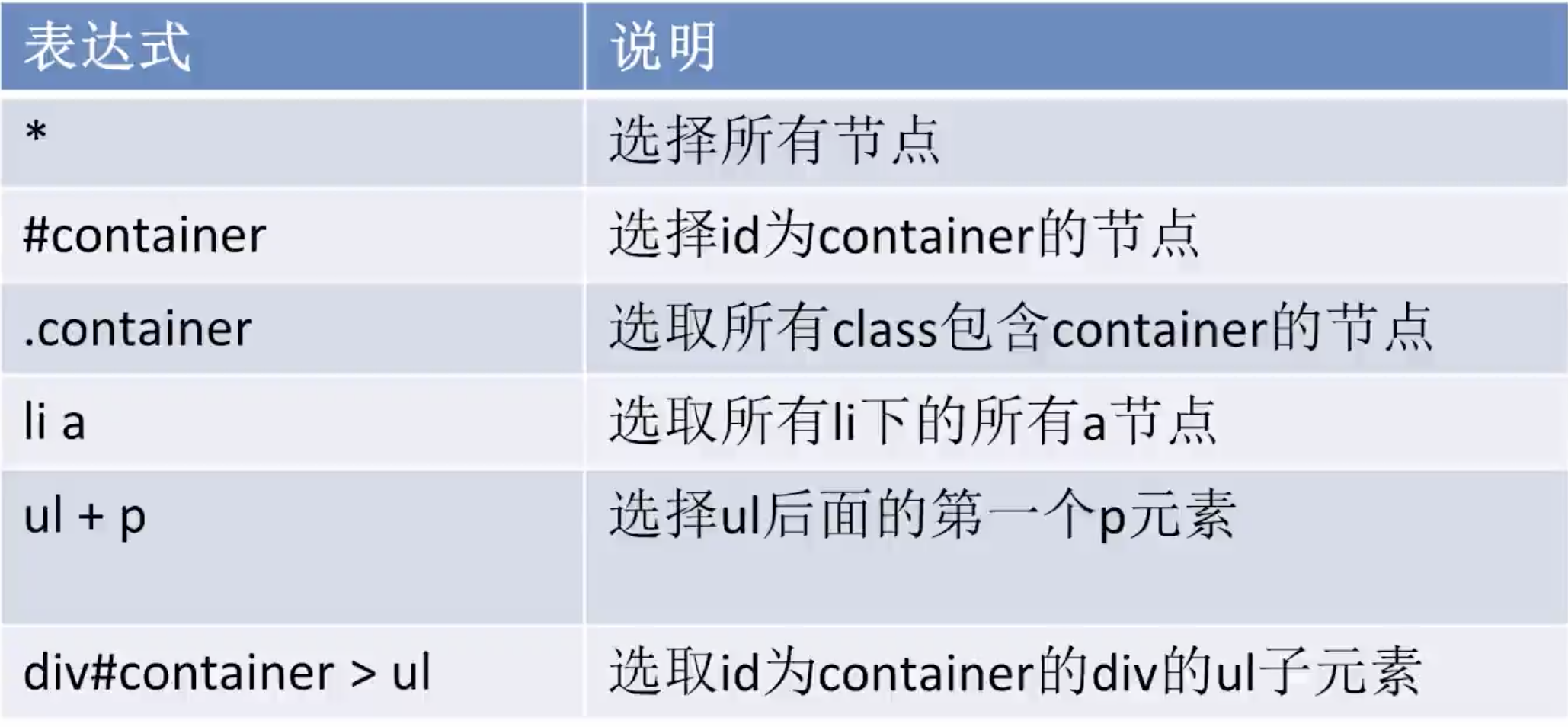
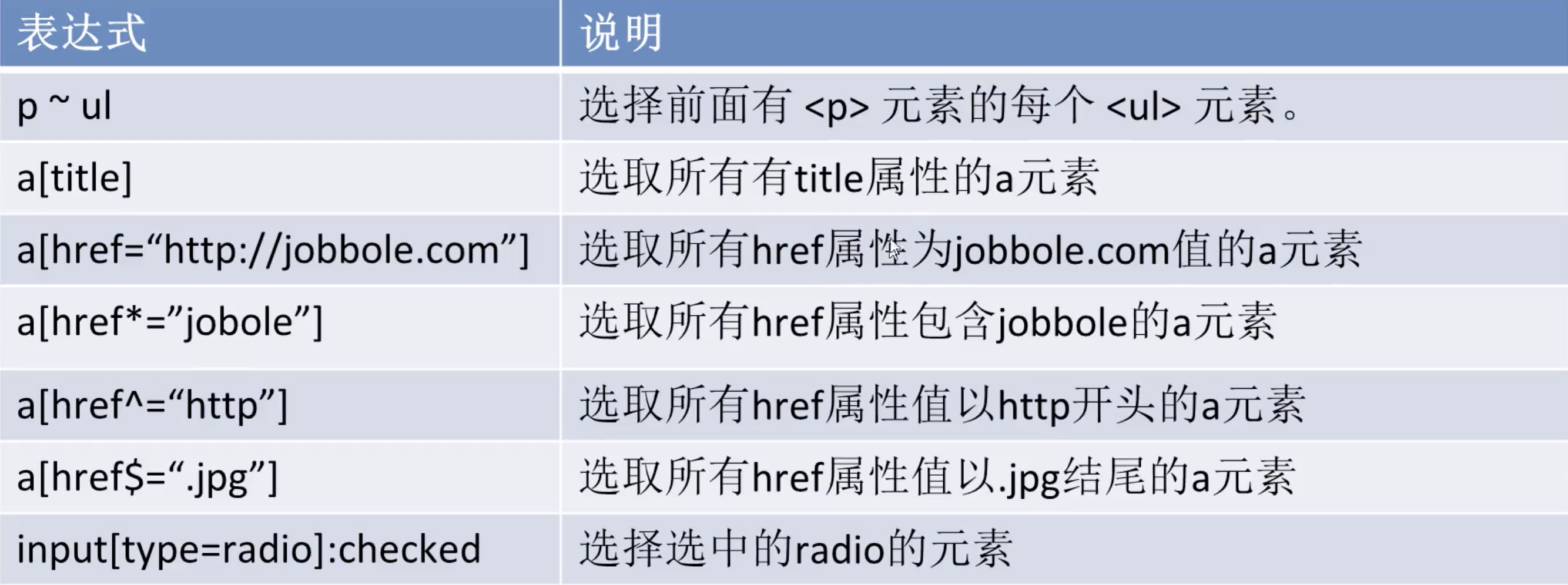
语法


若有收获,就点个赞吧
0 人点赞
