Item
Item定义
它让我们的数据面向对象,这个文件在scrapy初始化项目的时候就有
class CnblogItem(scrapy.Item):title = scrapy.Field()create_date = scrapy.Field()content = scrapy.Field()tag_list = scrapy.Field()tag = scrapy.Field()totalView = scrapy.Field()front_image_url = scrapy.Field()pass
Item使用
from ``item的父目录.items ``import ``类名 导包
1.索引方式
# 传递给ItemCnblogItemEntity = CnblogItem()CnblogItemEntity["create_date"] = create_dateCnblogItemEntity["content"] = contentCnblogItemEntity["title"] = titleCnblogItemEntity["tag_list"] = tag_listCnblogItemEntity["tag"] = tagCnblogItemEntity["totalView"] = totalViewCnblogItemEntity["url"] = response.urlCnblogItemEntity["front_image_url"] = [response.meta.get("front_image_url", "")]
2.get方式
get有什么优点,get可以防空指针,后面一个双引号就是默认值,下面案例把默认值设置为了空字符串
CnblogItemEntity.get("create_date","")
url缩减成md5 - hashlib
1.创建一个utils包和spiders同级
2.创建一个文件common
import hashlibdef get_md5(url):if isinstance(url,str):url = url.encode("utf-8")m = hashlib.md5()m.update(url)return m.hexdigest()if __name__ == "__main__":print(get_md5("www.baidu.com"))# 结果:dab19e82e1f9a681ee73346d3e7a575e
两大协议(pip,robots)
robot
这个协议是网站的一个规约,网站会在robots.txt中告知有哪些是不允许爬的,我们这设置为True就是遵守规约,就会自动略过这些规约目录
我们通过 域名/robots.txt 就可以看到这些规约,但我们一般把它关掉。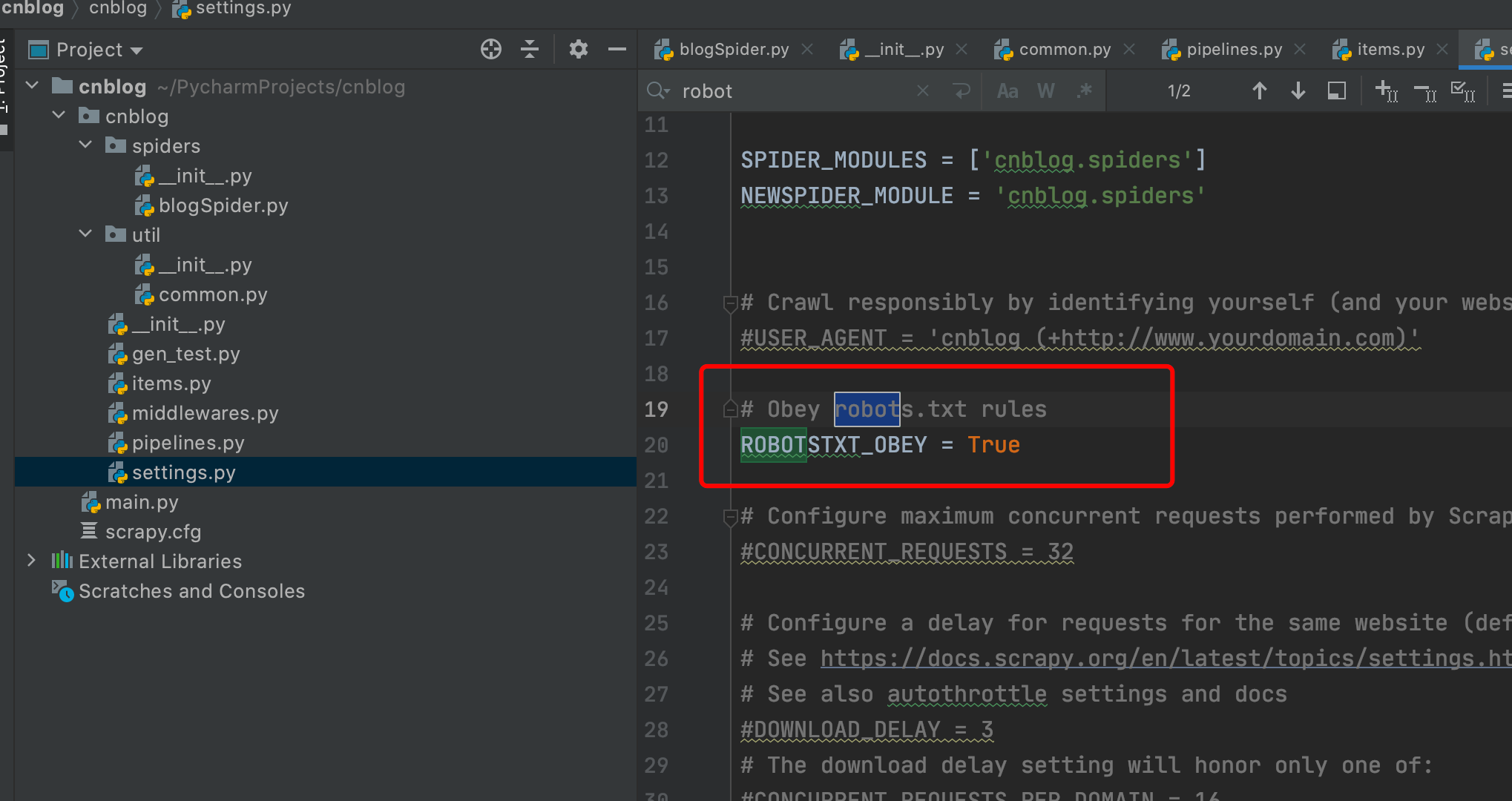
博客园规约是全都可爬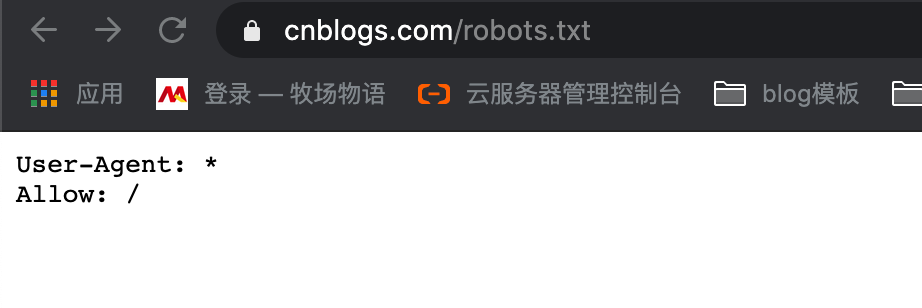
慕课网规约有部分不可爬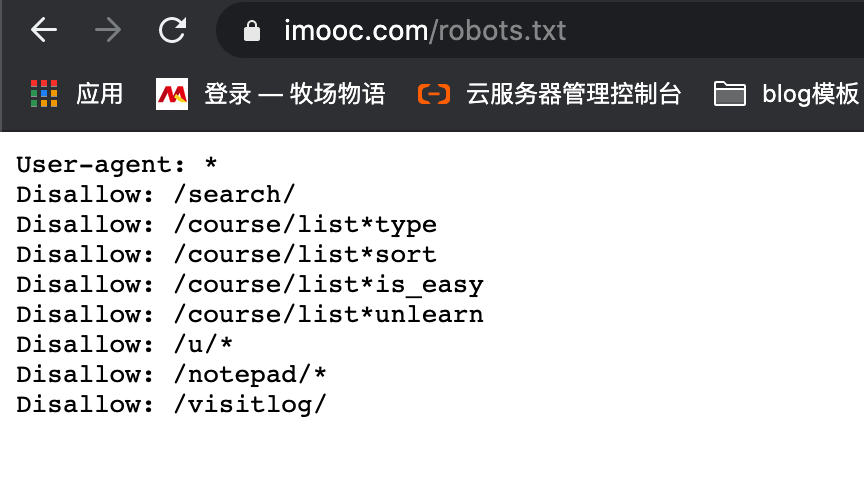
pipeline
pipeline是设置管道方法的优先级的,也就是pipelines里的函数,数字越小优先级越高
怎样下载图片
配置1 - setting
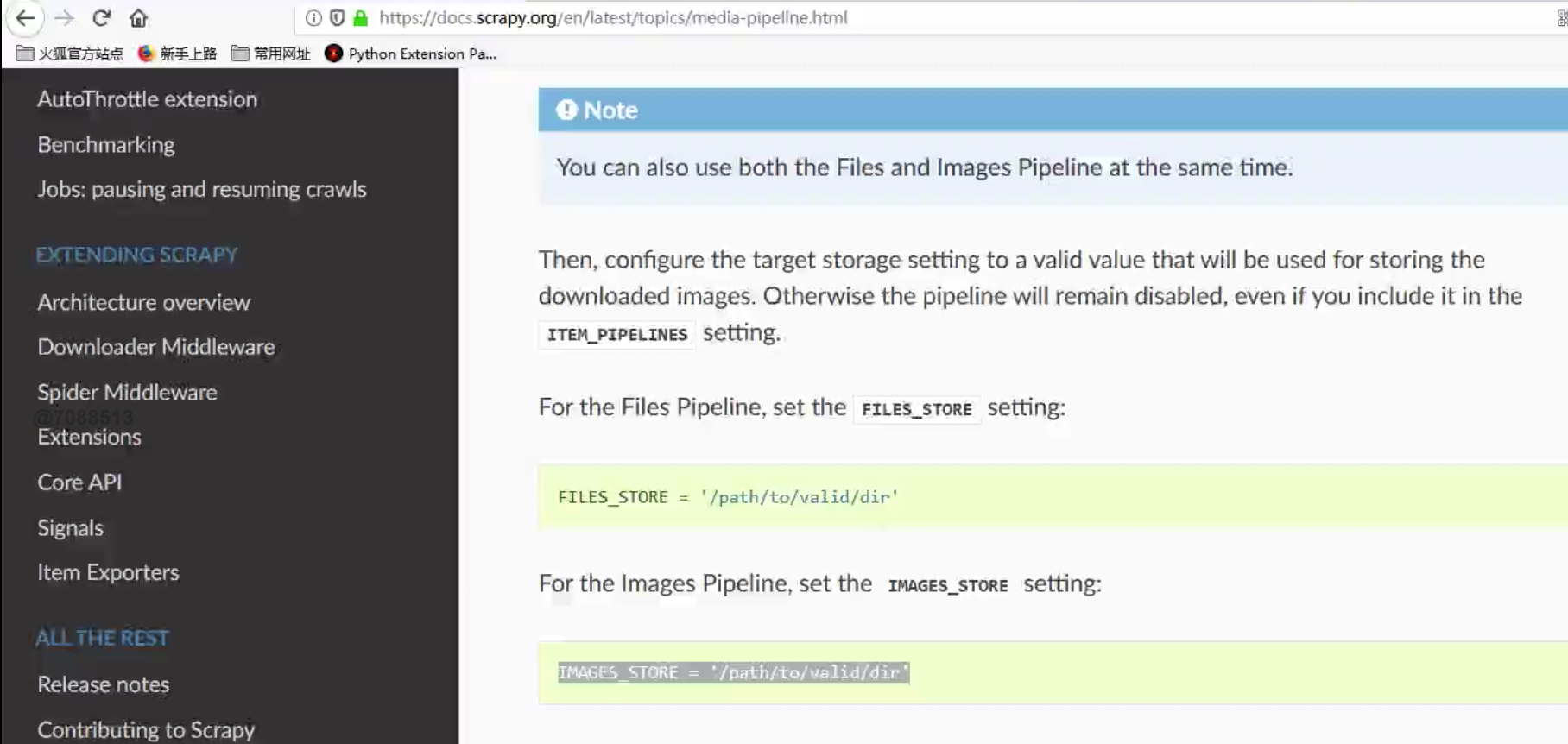
IMAGES_URLS_FIELD 这个必须对应到Item中的key,key对应的value是一个图片链接,因为程序结束我们yield出来的是一个Item,配置完以后,程序运行结束的时候就会帮我们去下载图片,并保存到IMAGES_STORE中定义文件夹中
IMAGES_URLS_FIELD = "front_image_url"project_dir = sys.path.append(os.path.dirname(__file__))IMAGES_STORE = os.path.join(project_dir, "images")
配置2 - pillow
下载pillowpip install -i https://pypi.douban.com/simple pillow
注意
图片的路径一定要是有中括号括起来的,代表它是一个数组,这样图片才能正常下载
接下来运行程序就可以在指定目录下载图片了。
CnblogItemEntity["front_image_url"] = [response.meta.get("front_image_url", "")]
下载图片到本地
光下载图片不行,我们还得把图片的路径保存起来,数据保存都在pipeline进行操作
配置管道
配置管道都是两步走,1.在pipeline中书写代码 2.在setting中配置管道以及优先级(让python知道你配置的管道)
1.书写管道逻辑代码
class ArticleImagePipeline(ImagesPipeline):def item_completed(self, results, item, info):image_file_path = ''if "front_image_url" in item:for ok, value in results:image_file_path = value["path"]item["front_image_path"] = image_file_pathreturn item
在setting中配置管道
ITEM_PIPELINES = {'cnblog.pipelines.CnblogPipeline': 300,'cnblog.pipelines.ArticleImagePipeline': 1 #配置这条语句}
Json格式导出数据(方式一)
process_item名字一定不要变,w是覆盖写,a是追加写。
dump方法 将dict类型转字符串类型(方便写入文件)
导包 import ``codecsimport ``json
class JsonWithEncodingPipeline(object):# 自定义Json文件的导出def __init__(self):self.file = codecs.open("article.json", "w", encoding="utf-8")def process_item(self,item,spider):lines = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(lines)return itemdef spider_closed(self, spider):self.file.close()
Json格式导出数据(方式二)
导包 from ``scrapy.exporters ``import ``JsonItemExporter
class JsonExporterPipeline(object):def __init__(self):self.file = open('articleExport.json', 'wb')self.exporter = JsonItemExporter(self.file, encoding='utf-8', ensure_ascii=False)self.exporter.start_exporting()def process_item(self, item, spider):self.exporter.export_item(item)return itemdef spider_closed(self, spider):self.exporter.finish_exporting()self.file.close()
导入数据库

建表(表名:article)
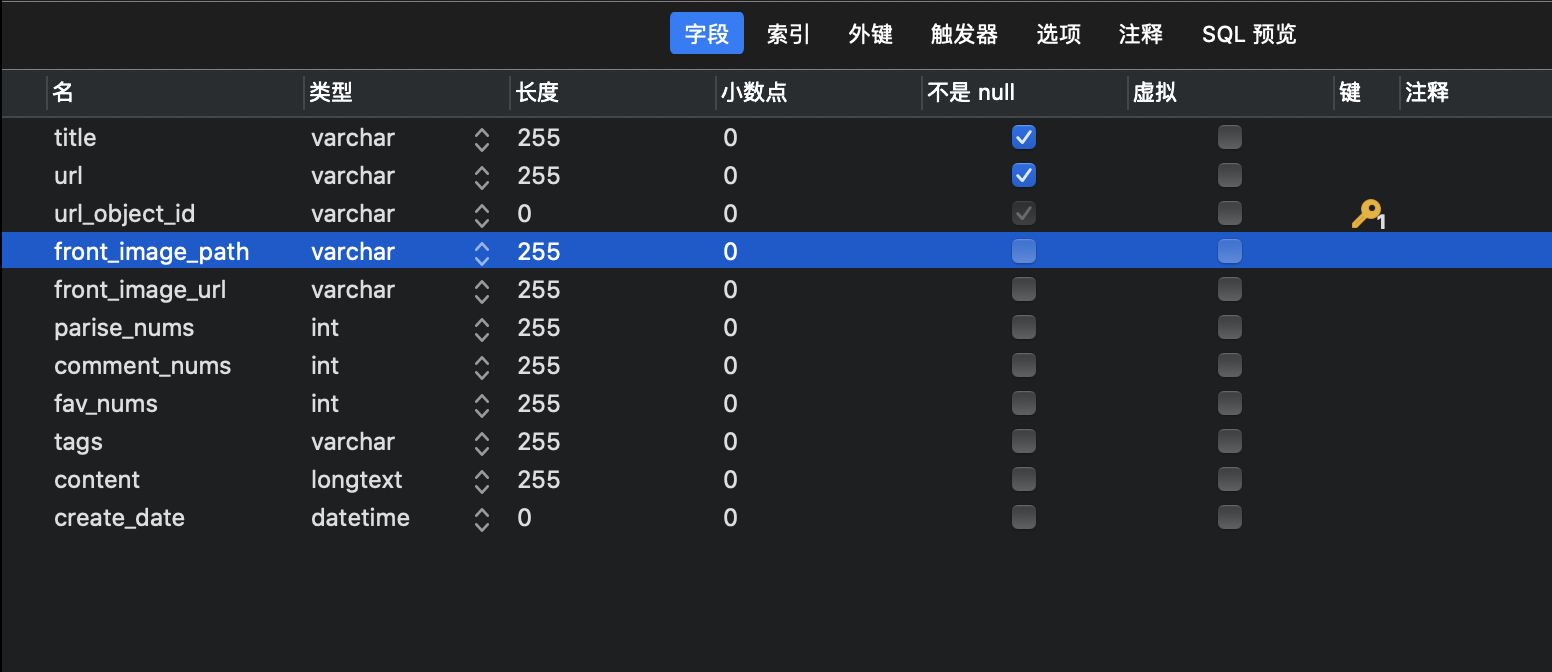
需要导入的包
详细剖析步骤
# 第一步 获得数据库连接self.conn = pymysql.connect("127.0.0.1", 'root', 'zxc123456', "article_spider", charset='utf8',# 第二步 将管道的链接赋值给指针self.cursor = self.conn.cursor# 第三步 写sql语句,参数部分用占位符代替insert_sql = """INSERT INTO `article_spider`.`article`(`url_object_id`, `title`, `url`, `front_image_path`, `front_image_url`, `parise_nums`, `comment_nums`, `fav_nums`, `tags`, `content`, `create_date`)VALUES (%s , %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""# 第四步 给占位符赋值 最后匹配sql要转元组params = list()params.append(item.get("title", ""))params.append(item.get("url", ""))params.append(item.get("url_object_id", ""))params.append(item.get("front_image_path", ""))front_image = ",".join(item.get("front_image_url", []))params.append(front_image)params.append(item.get("praise_nums", 0))params.append(item.get("comment_nums", 0))params.append(item.get("fav_nums", 0))params.append(item.get("tags", ""))params.append(item.get("content", ""))params.append(item.get("create_date", "1970-07-01"))self.cursor.execute(insert_sql, tuple(params))self.conn.commit()
完整案例
相当于把详细剖析的代码放进了管道的这种固定结构里,最后返回item是为了丢出去给其它管道接着使用。至于为什么要把数据库导入的这样一个操作放在管道中,是因为管道就是有做数据保存的这个事的。
class MysqlPipeline(object):def __init__(self):self.conn = pymysql.connect("127.0.0.1", 'root', 'zxc123456', "article_spider", charset='utf8',use_unicode=True)self.cursor = self.conn.cursor()def process_item(self, item, spider):insert_sql = """INSERT INTO `article_spider`.`article`(`url_object_id`, `title`, `url`, `front_image_path`, `front_image_url`, `parise_nums`, `comment_nums`, `fav_nums`, `tags`, `content`, `create_date`)VALUES (%s , %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""params = list()params.append(item.get("title", ""))params.append(item.get("url", ""))params.append(item.get("url_object_id", ""))params.append(item.get("front_image_path", ""))front_image = ",".join(item.get("front_image_url", []))params.append(front_image)params.append(item.get("praise_nums", 0))params.append(item.get("comment_nums", 0))params.append(item.get("fav_nums", 0))params.append(item.get("tags", ""))params.append(item.get("content", ""))params.append(item.get("create_date", "1970-07-01"))self.cursor.execute(insert_sql, tuple(params))self.conn.commit()return item
配置管道
管道配置两步走,第一步书写逻辑代码,第二步在setting中配置管道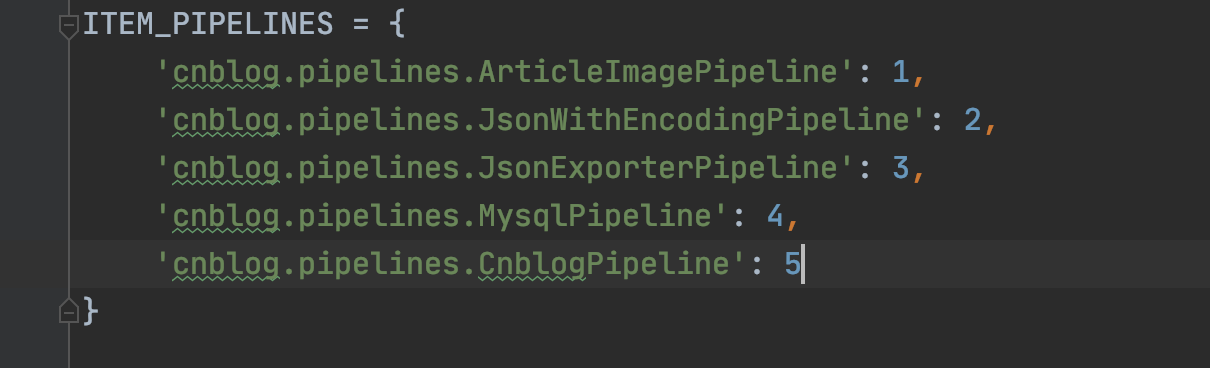
异步方式导入数据库(异步方式)
导包:
twisted包(scrapy本质上能实现异步是因为twisted模块)from ``twisted.enterprise ``import ``adbapi
第一步:配置setting
MYSQL_HOST = "127.0.0.1"MYSQL_DBNAME = "article_spider"MYSQL_USER = "root"MYSQL_PASSWORD = "zxc123456"
第二步:逻辑代码
class MysqlTwistedPipeline(object):def __init__(self, dbpool):self.dbpool = dbpool@classmethoddef from_settings(cls, settings):dbparms = dict(host=settings["MYSQL_HOST"],db=settings["MYSQL_DBNAME"],user=settings["MYSQL_USER"],password=settings["MYSQL_PASSWORD"],charset='utf8',cursorclass=pymysql.cursors.DictCursor,use_unicode=True)dbpool = adbapi.ConnectionPool("pymysql", **dbparms)return cls(dbpool)def process_item(self, item, spider):query = self.dbpool.runInteraction(self.do_insert, item)query.addErrback(self.handle_error, item, spider)def handle_error(self, failure, item, spider):print(failure)def do_insert(self, cursor, item):insert_sql = """INSERT INTO `article_spider`.`article`(`url_object_id`, `title`, `url`, `front_image_path`, `front_image_url`, `parise_nums`, `comment_nums`, `fav_nums`, `tags`, `content`, `create_date`)VALUES (%s , %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""params = list()params.append(item.get("title", ""))params.append(item.get("url", ""))params.append(item.get("url_object_id", ""))params.append(item.get("front_image_path", ""))front_image = ",".join(item.get("front_image_url", []))params.append(front_image)params.append(item.get("praise_nums", 0))params.append(item.get("comment_nums", 0))params.append(item.get("fav_nums", 0))params.append(item.get("tags", ""))params.append(item.get("content", ""))params.append(item.get("create_date", "1970-07-01"))cursor.execute(insert_sql, tuple(params))
第三步 配置管道
在setting文件中进行管道配置
主键重复
主键相同会报重复,但是我们在应用爬虫的时候,需要进行更新数据的操作,那更新的数据如果没有变化,就会造成数据库主键重复,我们通过sql语句特判来实现“当目标数据不变,也一样能更新数据”,下面这个语句的意思就是当主键重复的时候,采用更新操作,更新的是点赞数这个参数,点赞数采用原记录的参数
一步到位
在插入语句后加上on DUPLICATE KEY UPDATE PARISE_NUMS = VALUES(PARISE_NUMS)"""
insert_sql = """INSERT INTO `article_spider`.`article`(`url_object_id`, `title`, `url`, `front_image_path`, `front_image_url`, `parise_nums`, `comment_nums`, `fav_nums`, `tags`, `content`, `create_date`)
VALUES (%s , %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) on DUPLICATE KEY UPDATE PARISE_NUMS = VALUES(PARISE_NUMS)"""

若有收获,就点个赞吧
0 人点赞
