爬取文章详情
parse包
urljoin 用于拼接url连接
join 用于将数组处理成带间隔的字符串
",".join(tag_list)parse.urljoin(response.url, post_url)
特殊分析
通过下面两种结果可以发现,如果待拼接连接没有/斜杠的话,会直接拼接在url后面,如果有斜杠则会直接拼接在域名后面(这是浏览器机制决定的)
url = parse.urljoin("www.baidu.com/hi", "NewsAjax/GetAjaxNewsInfo")结果:www.baidu.com/hi/NewsAjax/GetAjaxNewsInfourl = parse.urljoin("www.baidu.com/hi", "/NewsAjax/GetAjaxNewsInfo")结果:www.baidu.com/NewsAjax/GetAjaxNewsInfo
Requests包(request请求)
request请求是同步的 , 它的作用和前后端交互的Ajax一致,在回调调用的函数中,通过response可以获得request的请求参数
url 连接
meta 请求参数
callback 回调函数
请求完成以后,会调用回调函数,这边注意不能写括号,写括号就是赋返回值了,但是不写就是赋值这个方法,我们想要的是赋值这个方法,而不是返回值,所以不加括号
应用场景:
scrapy是异步的,request是同步的,这样高并发场景肯定不行。我们怎么让request也变成异步的,通过yield
yield
和return对比学习,return是直接返回并结束,yield也返回,但它不会立马结束该函数,而是会把程序全部执行完才结束
from urllib import parseimport scrapyfrom scrapy import Requestdef parse(self, response):# 拿到每个父节点post_nodes = response.css("#news_list .news_block")# 通过for循环挨个获取父节点for post_node in post_nodes:# 获取每个父节点下的图片urlimage_url = post_node.css('.entry_summary a img::attr(href)').extract_first("")post_url = post_node.css("h2 a::attr(href)").extract_first("")yield Request(url=parse.urljoin(response.url, post_url),meta={"front_image_url":image_url})pass
生成器
生成器的一大特征就是yield 生成器是一个可迭代的对象,可以理解成一个可以终止的函数,它是可以迭代的那么我们可以使用迭代器来对它进行一个遍历,next()函数,指针概念
#生成器def myGen():yield 1yield 2yield 3return 4print(myGen())for data in myGen():print(data)结果:<generator object myGen at 0x10f7035f0>123
mygen = myGen();print(next(mygen))print(next(mygen))结果12
调试 (安全)
如果我们用pycharm不断的debug调试的话,可能会引发目标网站的系统监测,有没有不引发多访问的情况下,又能调试。那么我们就要使用shell命令,shell命令只会单次访问,我们用shell命令调试出来了直接把代码粘贴到代码中就可以,使用:scrapy shell命令
scrapy shell 页面
案例
(venv) user3@user3deMacBook-Pro cnblog % scrapy shell https://news.cnblogs.com/n/675408/
输入命令以后,scrapy给了我们一些可用的对象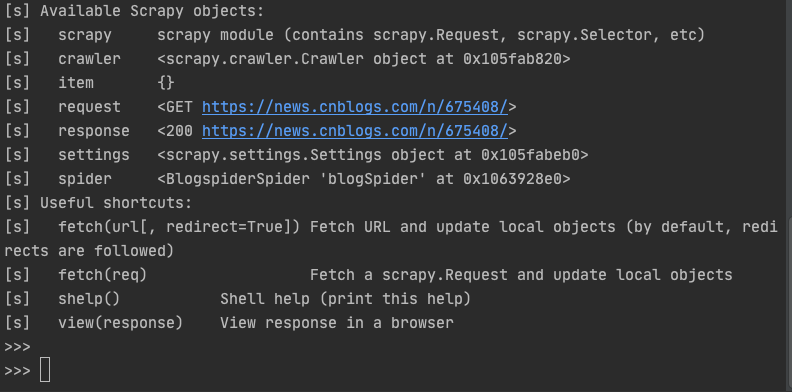
着重说一下response,因为response页面就是整个单页的html元素,所以我们针对这个页面进行调试,把调试结果放进spider代码中就可以
这样我们只需要访问一次网页,就可以针对该单页重复调试,而不像在编译器中,每次调试都要访问页面。
特殊爬取场景
Js生成的数据
如果页面某个内容是由Js生成的,那么我们就不能直接用选择器获取。使用request请求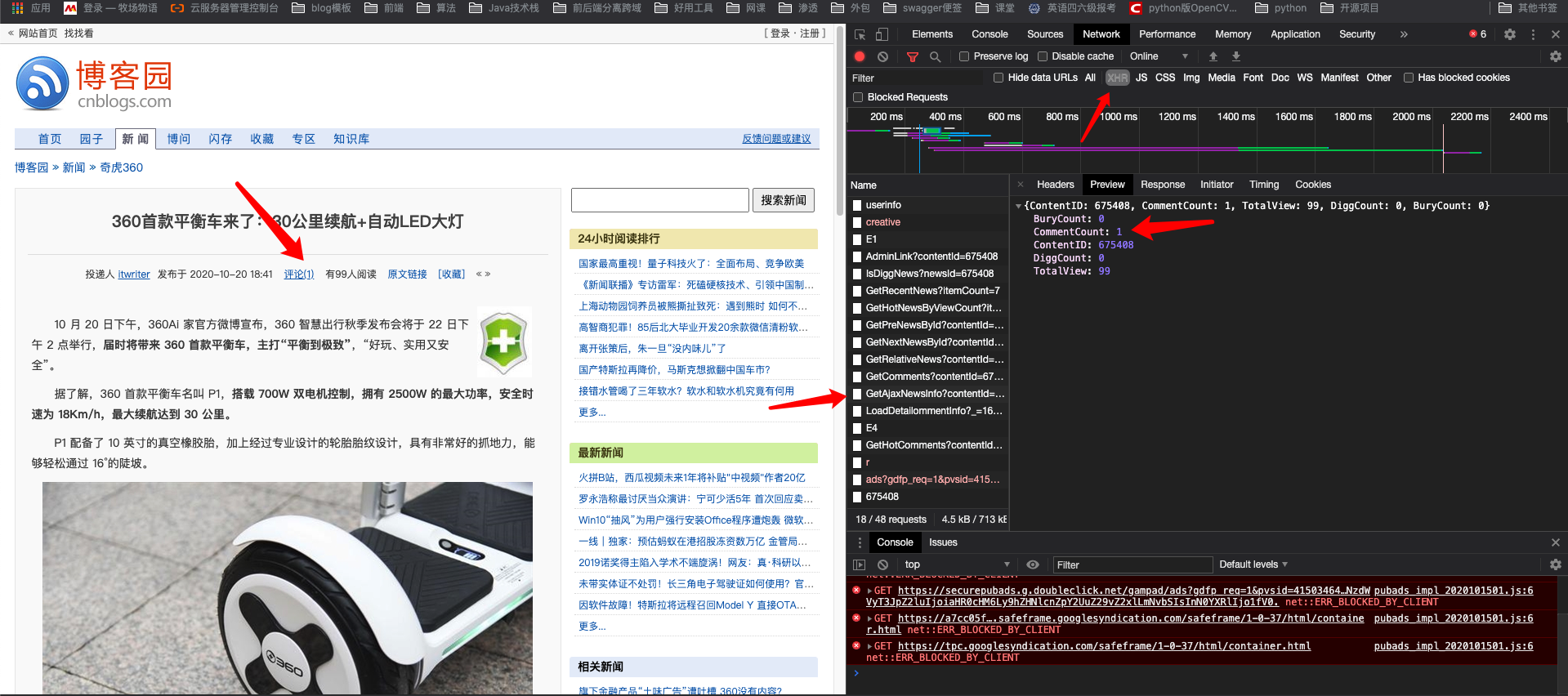
pip install -i https://pypi.douban.com/simple requests
>>> response = requests.get("https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=675408")>>> response<Response [200]>>>> response.text'{"ContentID":675408,"CommentCount":1,"TotalView":103,"DiggCount":0,"BuryCount":0}'>>> import json>>> json.loads(response.text){'ContentID': 675408, 'CommentCount': 1, 'TotalView': 103, 'DiggCount': 0, 'BuryCount': 0}>>> j_data = json.loads(response.text)>>> j_data['TotalView']103
Requests包
pip install -i https://pypi.douban.com/simple requests
# 发起请求request.get("接口地址")
https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=675408
案例
>>> response = requests.get("https://news.cnblogs.com/NewsAjax/GetAjaxNewsInfo?contentId=675408")>>> response<Response [200]>>>> response.text'{"ContentID":675408,"CommentCount":1,"TotalView":103,"DiggCount":0,"BuryCount":0}'>>> import json>>> json.loads(response.text){'ContentID': 675408, 'CommentCount': 1, 'TotalView': 103, 'DiggCount': 0, 'BuryCount': 0}>>> j_data = json.loads(response.text)>>> j_data['TotalView']103
完整爬取详情案例
import jsonfrom urllib import parseimport scrapyfrom scrapy import Requestimport requestsimport reclass BlogspiderSpider(scrapy.Spider):name = 'blogSpider'allowed_domains = ['news.cnblogs.com']start_urls = ['http://news.cnblogs.com/']def parse(self, response):post_nodes = response.css("#news_list .news_block")[:1]for post_node in post_nodes:image_url = post_node.css('.entry_summary a img::attr(href)').extract_first("")post_url = post_node.css("h2 a::attr(href)").extract_first("")yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},callback=self.parse_detail)def parse_detail(self, response):match_re = re.match(".*?(\d+)", response.url)if match_re:title = response.xpath('//*[@id="news_title"]/a/text()').extract_first("")create_date = response.xpath('//*[@id="news_info"]/span[2]').extract_first("")content = response.xpath('//*[@id="news_content"]').extract_first("")tag_list = response.xpath('//*[@id="link_source2"]/text()').extract()tag = ",".join(tag_list)totalView = response.xpath('//*[@id="News_TotalView"]')post_id = match_re.group(1)yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),callback=self.parse_nums)passdef parse_nums(self, response):j_data = json.loads(response.text)praise_nums = j_data["DiggCount"]fav_nums = j_data["TotalView"]comment_nums = j_data["CommentCount"]pass

若有收获,就点个赞吧
0 人点赞
