scrapy安装和配置
国内镜像仓库源
阿里云 https://mirrors.aliyun.com/pypi/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
豆瓣(douban) https://pypi.douban.com/simple/
中国科学技术大学 https://pypi.mirrors.ustc.edu.cn/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
windows安装
构造虚拟环境是因为我们一台电脑里面可能会有多个python,但是每个版本的python可能都还不太一样,这样构造虚拟环境就可以为我们实现定制化,我们想把scrapy安装在哪个python下都可以实现。-i命令是一个代理镜像的命令,能让我们的下载加速。
mkvirtualenv -p (python的可执行文件绝对路径)pip install -i https://pypi.douban.com/simple scrapy
mac安装
1.安装xcode工具xcode-select --install2.进入虚拟环境详见下面3.安装scrapypip install scrapy
window安装出错(待补充)
上面的win安装方式其实很容易出错,因为这个下载方式可能会依赖windows的很多包,比如c++的一些包,如果我们电脑环境不是那么丰富的话,有可能就会出错。
那可能就需要以下这个网址的安装包,用安装包的方式挨个安装依赖包 , 这是最保险的做法。
lxml , twisted , pywin32 依赖包
第三方包网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
ps:打开网站后有很多版本,主要依据几个关键点,cp关键字要对应自己本地python版本,win关键字要对应自己系统的位数。以这两个关键字确定要下载的包。下载完以后放在python项目根目录,然后通过pip进行安装
pip install -i https://pypi.douban.com/simple
pycharm安装
如果命令觉得太麻烦,不妨可以试试这个,让编译器去适配命令给电脑安装环境。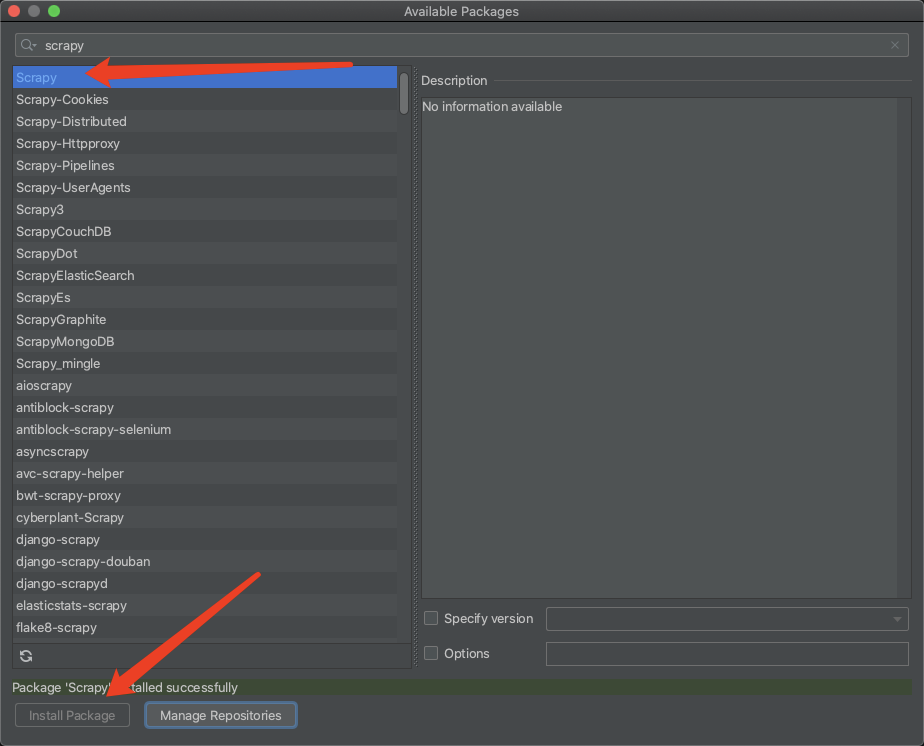
检测一下安装结果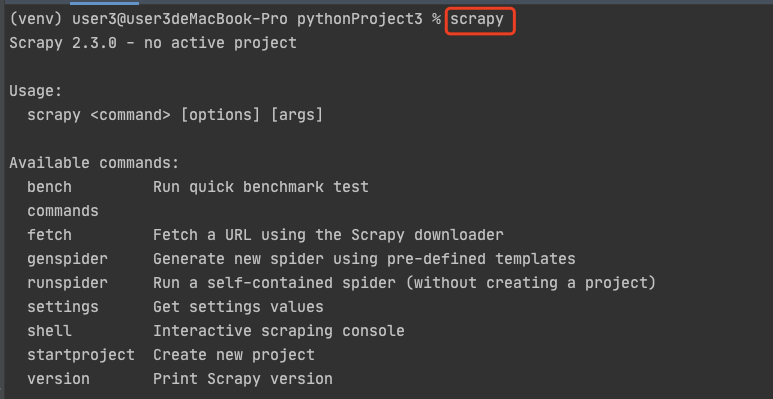
pycharm interpreter镜像配置
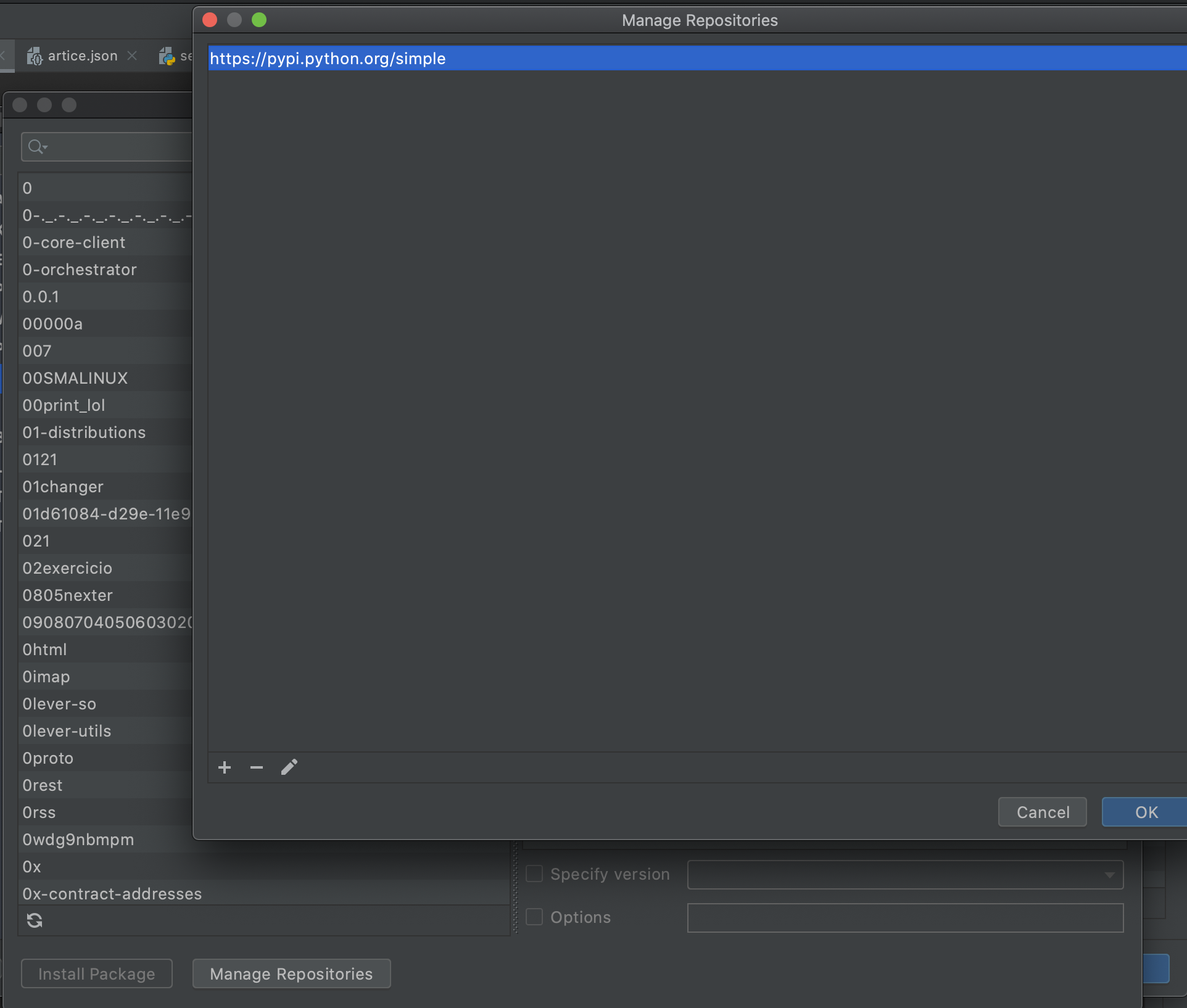
怎样进入虚拟环境
我们安装的框架一般情况下都是装在虚拟环境中的,也就是某个python构造的虚拟环境中,它不会是一个作用于电脑全局的,所以我们就要进入到虚拟环境中,才能使用该环境下的框架。
查看虚拟环境所在目录
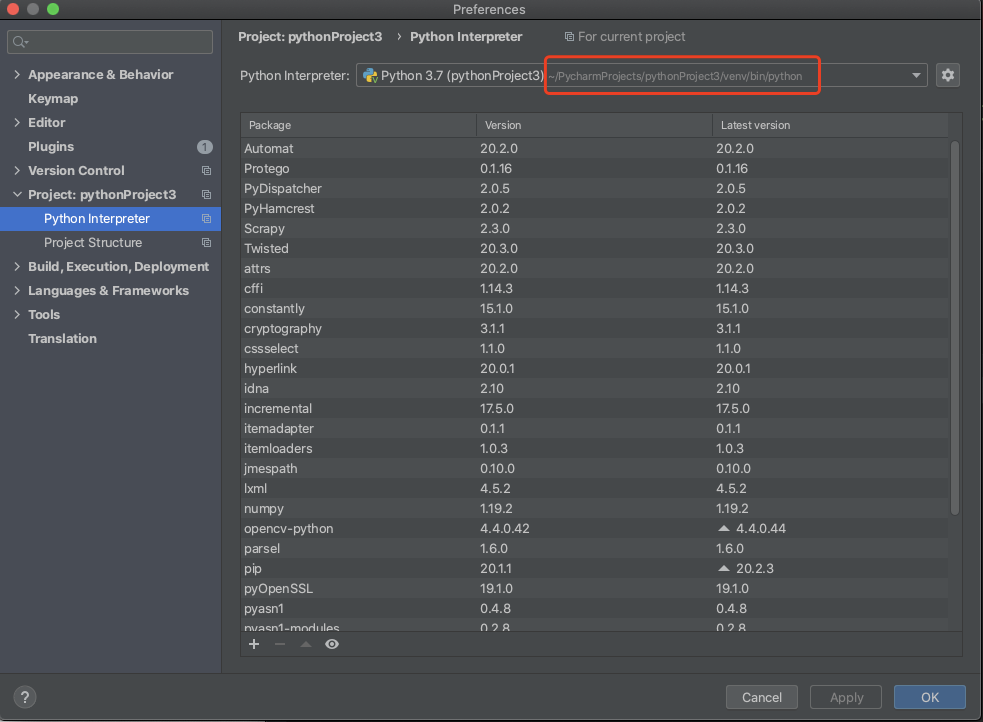
进入虚拟环境 (mac)
cd /Users/manmanxiaowugui/PycharmProjects/AI_test/venv/binsource activate
小试牛刀
进入指定目录
cd /Users/xxx/Desktop
生成scrapy项目
scrapy startproject 项目名

ps:注意图示红框表示已进入虚拟环境,并且发现生成项目后,scrapy给了我们一些提示用来生成爬虫文件/
初始化项目
cd spiderscrapy genspider 爬虫名 域名

初始化成功后,会发现我们的项目目录下多了一个cnblog的python文件。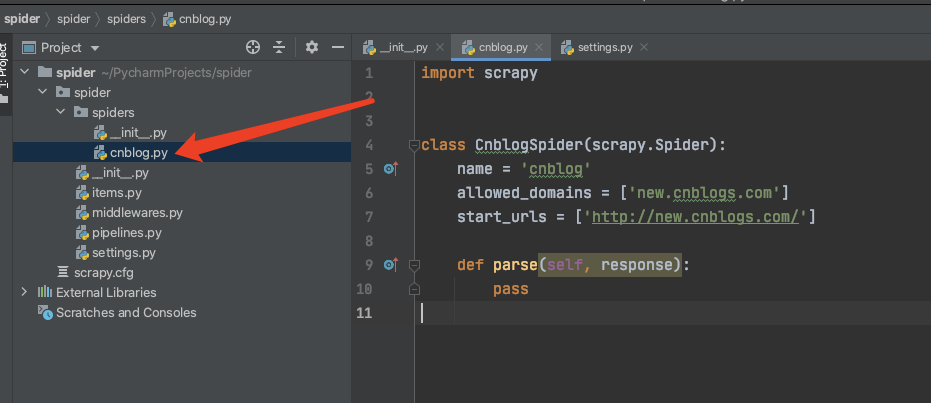
这边有可能导包会报错,是因为打开项目的时候解释器可能初始化错误,我们需要重新指向一个scrapy所在的那个解释器。如果列表中没有展示出来,需要点击右边齿轮进行一个新增解释器的操作,再做下拉框选择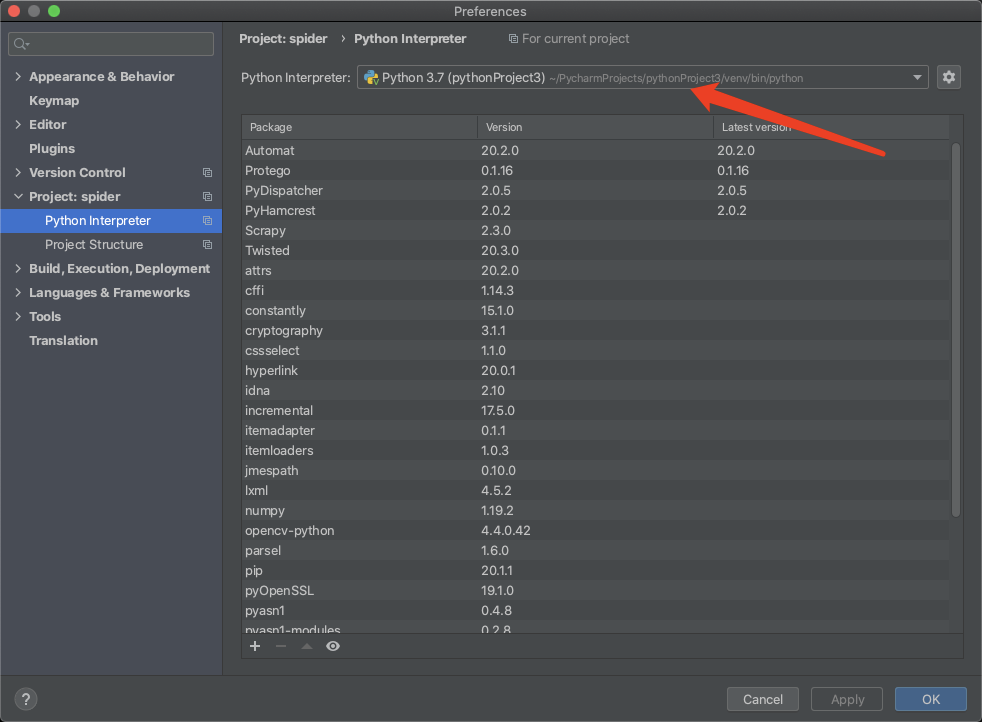
需求分析
为什么要做需求分析,爬虫其实就是在模拟人的操作在做一些自动化的事情,这个自动化的模型是需要我们写的,如果我们不知道目标信息所在一些基本页面结构,那这个爬虫很可能匹配度比较差。
分页策略分析
https://news.cnblogs.com/
1.可以发现分页这个url是规则的/n/page/x的模式
2.分页的最大页是100,起始页是1。我们需要判断100页是每个搜索都是100页吗,还是网站就想让我们看100页面。如果是,那这个100是基本上固定了。
3.如果它是动态的,终止页面都不一样呢,我们可以通过next按钮进行下一页,这样就是一种通用的策略,无论有多少页,我通过这个按钮一定能走完所有页面

番外pip
强制删除类库
这两个方式是找到虚拟环境的目录,进入到目录里的lib文件夹删除指定模块所属文件夹即可
方式1
pythonimport site;site.getsitepackages()
方式2
1、终端打开python,输入import numpy2、然后输入import inspect3、然后输入inspect.getfile(numpy)

若有收获,就点个赞吧
0 人点赞
