概念
非常重要!只要爬虫就避不开,它可以从html dom树上,获取目标节点。
节点分类
语法


函数大全
xpath还有很多实用的函数,在比较复杂的应用场景中会非常方便。
text() 获取节点的text
提取几个元素看看?
response这个形参在初始化项目的时候就已经有了,它里面封装了很多东西,当然也包括xpath。
import scrapyclass CnblogSpider(scrapy.Spider):name = 'cnblog'allowed_domains = ['new.cnblogs.com']start_urls = ['http://new.cnblogs.com/']def parse(self, response):response.xpath(这里写html节点路径)pass
1.笨方法
一个个往下分析着手写
缺点:如果我们的页面树节点关系只要变化一点,这个模型就会失效,不灵活。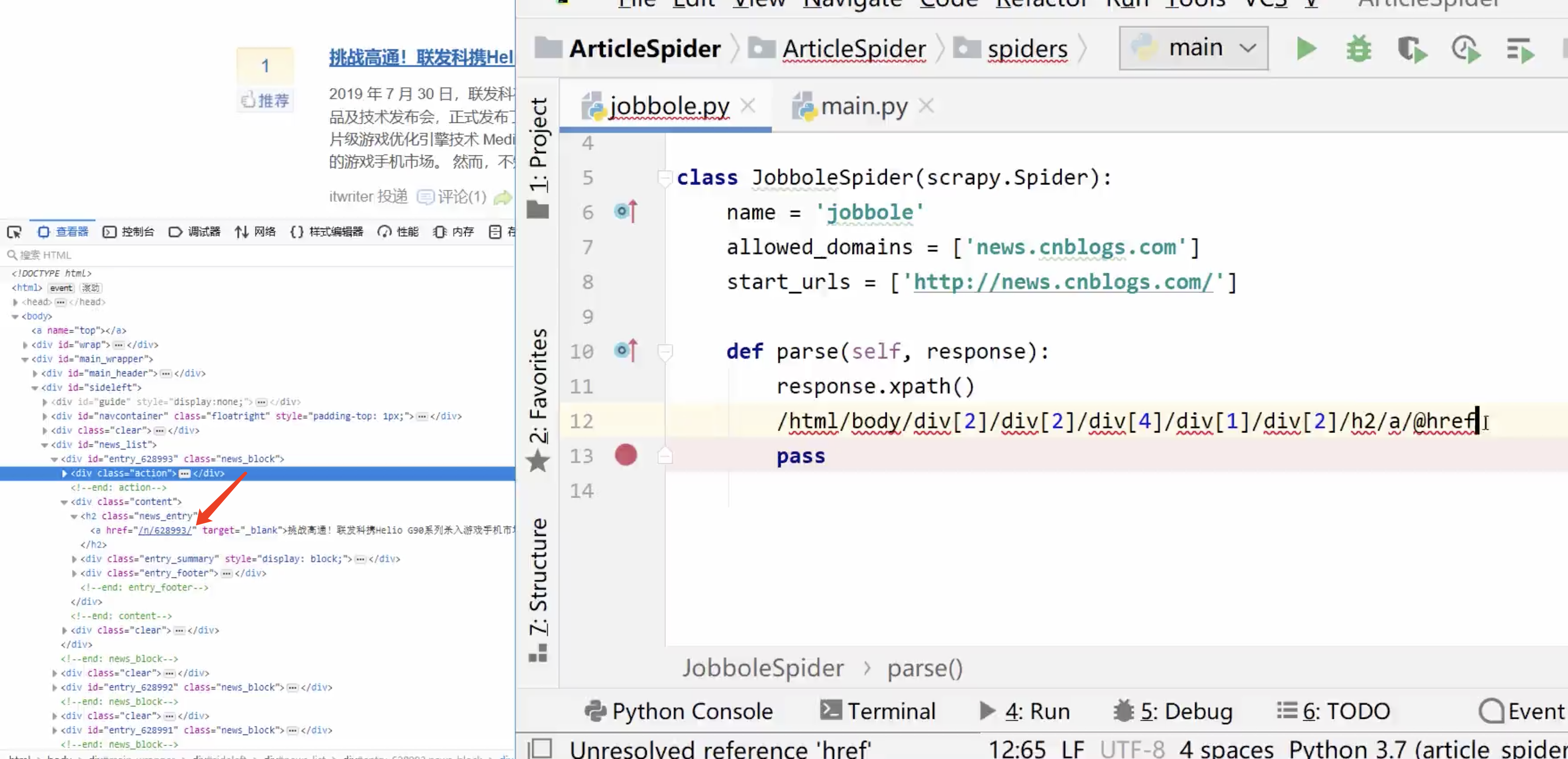
2.巧方法
浏览器其实提供给了我们一个便捷功能,可以拷贝某一个元素的xpath路径
会发现火狐和谷歌其实提供的xpath并不一样,谷歌的明显是更方便的。
谷歌 //*[@id="entry_674396"]/div[2]/h2/a
火狐 /html/body/div[2]/div[2]/div[4]/div[1]/div[2]/h2/a
火狐
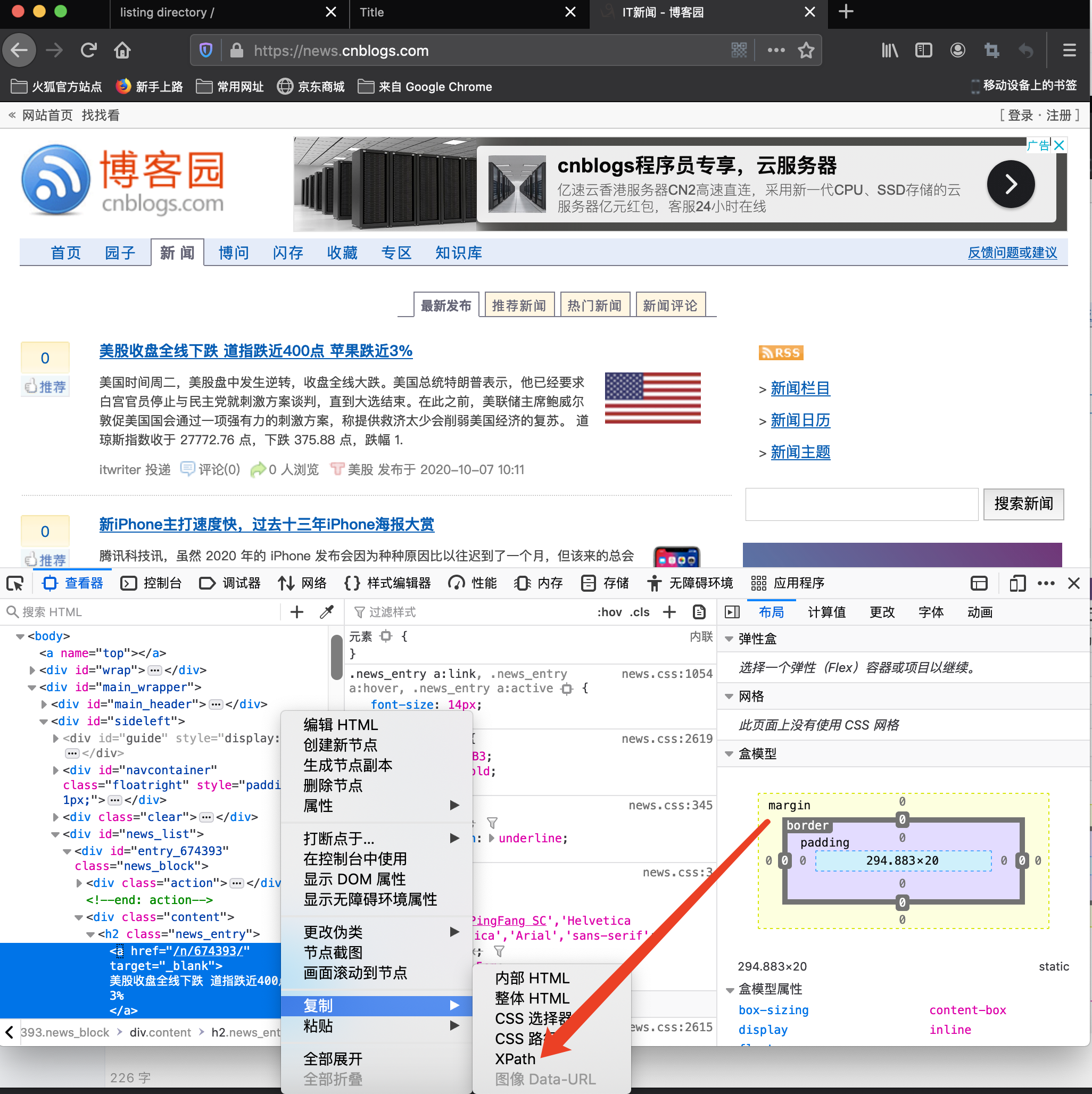
谷歌
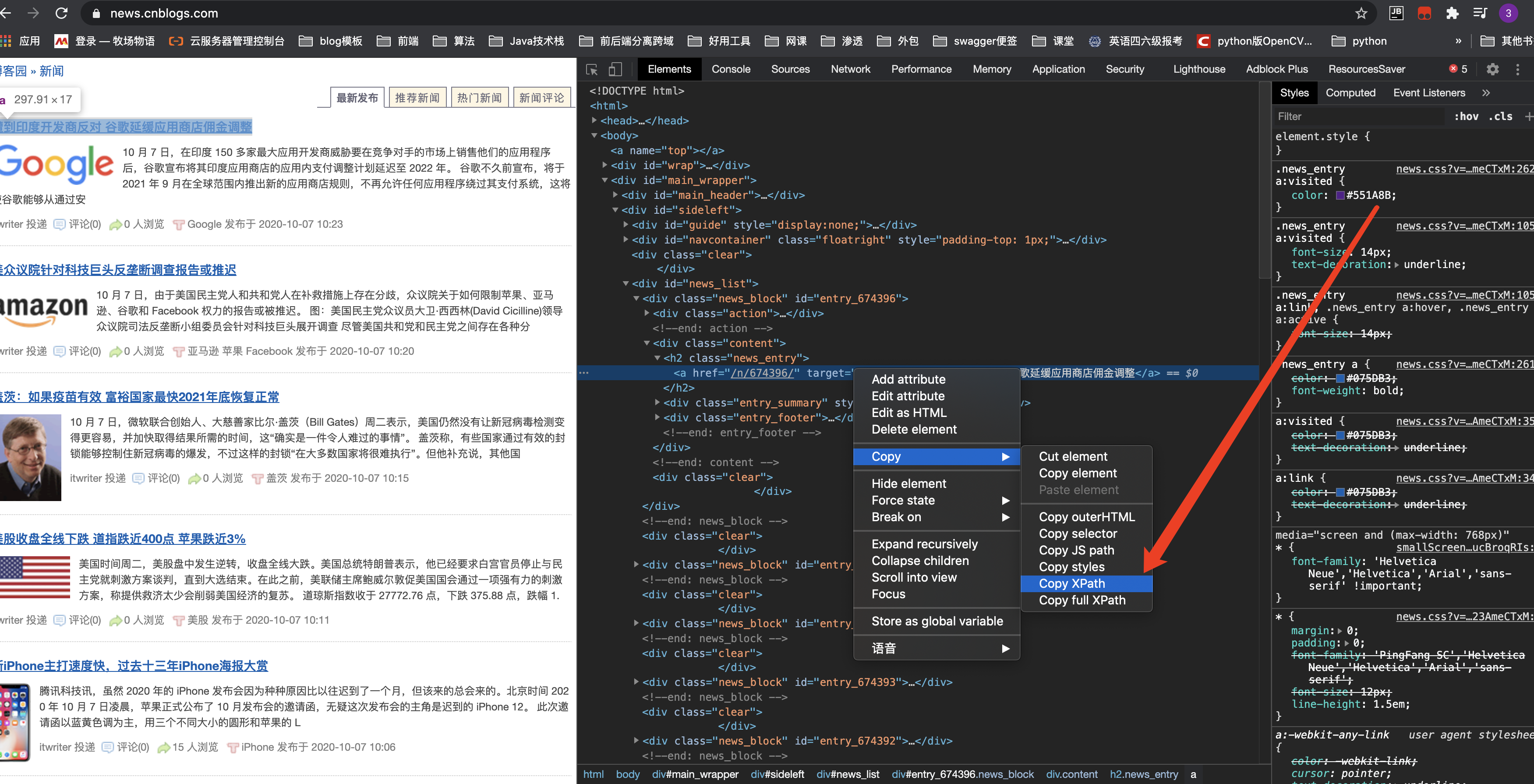
运行一下
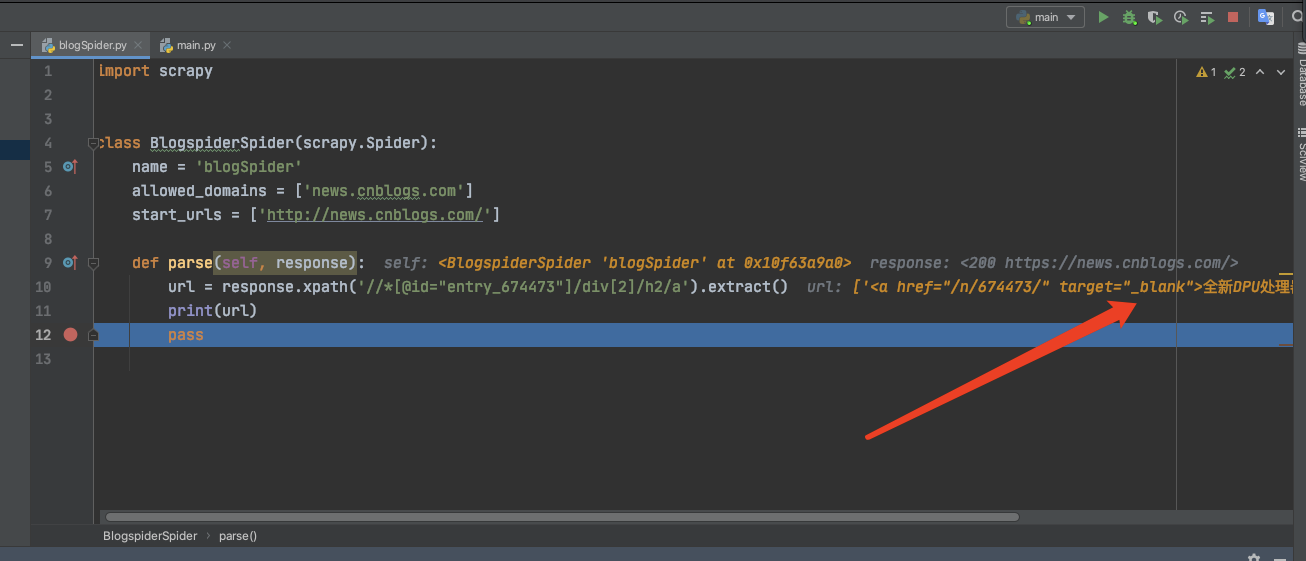
将xpath运行一下看看。
注意:scrapy会在news.cnblogs.com这个单页去找,如果该节点是在其他分页,就会抓不到。
import scrapyclass BlogspiderSpider(scrapy.Spider):name = 'blogSpider'allowed_domains = ['news.cnblogs.com']start_urls = ['http://news.cnblogs.com/']def parse(self, response):if response.xpath('//*[@id="entry_674473"]/div[2]/h2/a').extract():url = response.xpath('//*[@id="entry_674473"]/div[2]/h2/a').extract()[0];print(url)pass
extract方法须知
这个方法需要规避空list异常的情况。有两种解决方案
1.可以先做特判 - 如果数组不为空,再取索引
2.或者直接用extract_first() - 这个方法会直接返回list第一个元素,如果为空也不会报数组溢出异常
extract()extract_first("")
成功拿到单个树节点
适配博客园新闻Xpath
可以发现单页中的一个规律,class = new_entry下的a标签就是我们要的目标信息。
def parse(self, response):url = response.xpath("//div[@id='news_list']//h2[@class='news_entry']/a/@href").extract()print(url)pass


若有收获,就点个赞吧
0 人点赞
