itemLoader
三种方法
addValue(Item参数名,值) 给参数添加值,比如response中的url,或者上一个方法yield传递的值addXpath(Item参数名,xpath语法) 匹配Xpath选择器addCss(Item参数名,css语法) 匹配css选择器
导包
from ``scrapy.loader ``import ``ItemLoaderfrom scrapy.loader.processors import MapCompose,TakeFirst,Join,Identity
使用案例
item顾名思义就是一个item类
response和parse的形参response一样,都是一个响应的对象,里面会有网址等等一些信息
# ItemLoader(实例化item,response)item_loader = ItemLoader(item=CnblogItem(), response=response)item_loader.add_xpath("title", '//*[@id="news_title"]/a/text()')item_loader.add_xpath("create_date", '//*[@id="news_info"]/span[2]/text()')item_loader.add_xpath("content", '//*[@id="news_content"]')item_loader.add_xpath("tags", '//*[@id="link_source2"]/text()')item_loader.add_xpath("totalView", '//*[@id="News_TotalView"]')item_loader.add_value("url", response.url)item_loader.add_value("front_image_url", response.meta.get("front_image_url", ""))# 将配置好的item再赋值给一个新对象CnblogItemEntity = item_loader.load_item()
运行一下
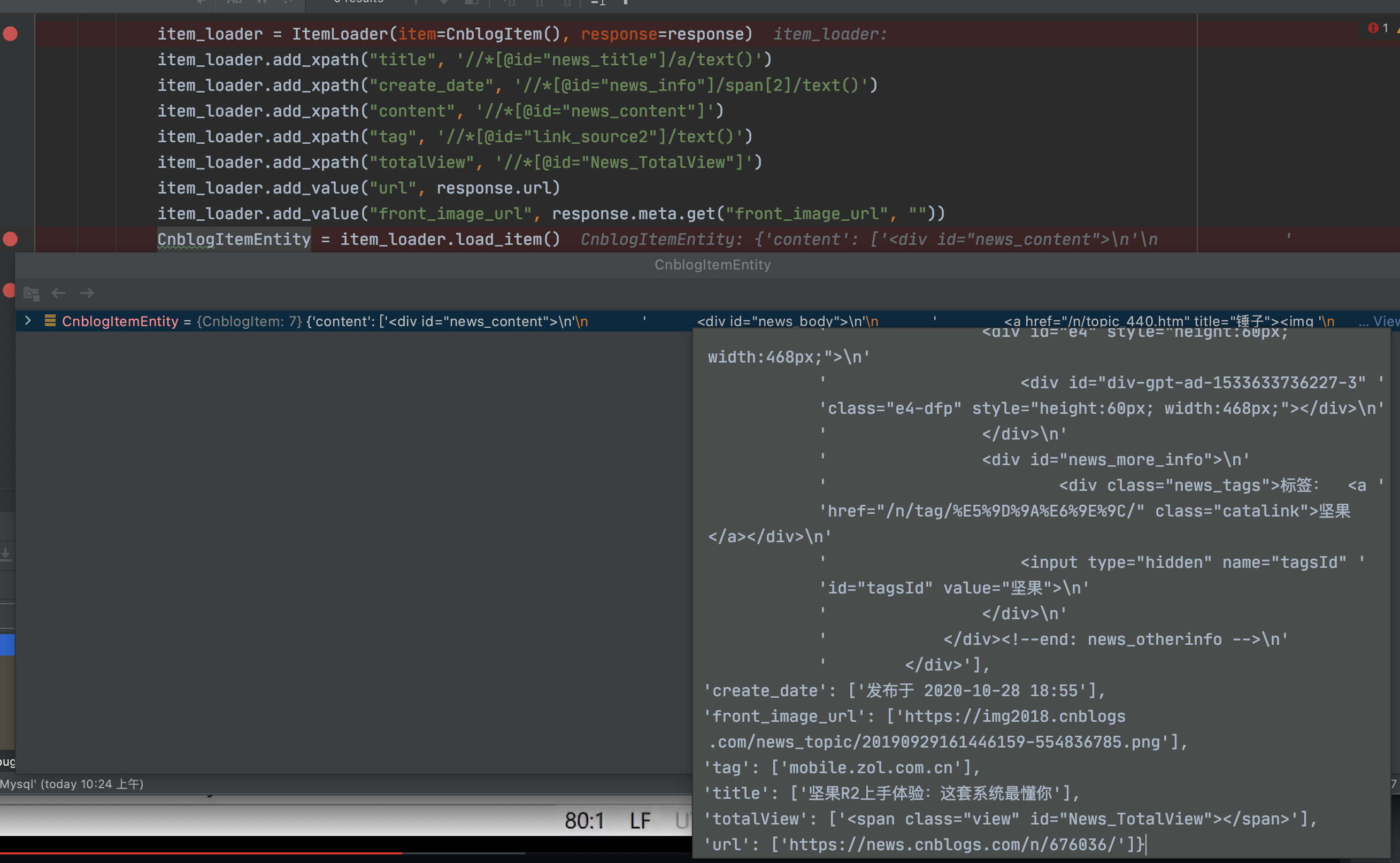
如何处理
TakeFirst
我们已经拿到List了,但是我们常常不需要list,因为像content内容,一篇文章就一个文章内容,不会出现多个,所以怎么样去掉中括号让它回归成一个字符串。那么就用到Take_first,和extract_first道理一样
title = scrapy.Field(output_processor=TakeFirst())
MapCompose
我们把需要定制的逻辑都封装成方法,然后通过MapCompose进行调用,这个item属性在生成的时候就自动会调用方法进行参数处理。需要注意的是,这个定制方法(add_Article)形参是value,这个形参就是我们爬到的数据,一般针对这个形参进行处理。
def add_Article(value):return value + 'bobby'title = scrapy.Field(input_processor=MapCompose(add_Article),)
Identity
Identity方法让数据回归到原先的list。比如我们做了默认操作,也就是下面的【继承ItemLoader】,将所有数组都默认处理成了字符串。但图片路径是不允许字符串的,只有数组scrapy才识别,否则会报错,那么就需要用到Identity
front_image_url = scrapy.Field(output_processor=Identity())
Join
它可以把一个数组做成一个按照间隔符拼接的字符串,比如[1,2,3,4] 如果我们想去掉数组中括号,保留”1,2,3,4”字符串结果,Join可以帮我们实现
tag = scrapy.Field(output_processor=Join(separator=","))
继承ItemLoader
不直接用ItemLoader,而是继承ItemLoader,这样我们就可以做定制化处理,比如,直接默认每一个数据爬过来就提取数组中第一个字符串。那我们进行如下操作即可
class ArticleItemLoader(ItemLoader):default_output_processor = TakeFirst()

若有收获,就点个赞吧
0 人点赞
