URL结构
为什么学它
url树结构非常重要,它是我们爬虫需要的一个策略,需要用深度优先或者广度优先方式来遍历网站的所有内容。scrapy默认就是一种深度优先算法,通过递归来实现。
编码
保存是将Unicode 转换 utf-8编码
读取是将utf-9 转换 Unicode编码
也就是python编程时,所有字符python都是默认处理成Unicode编码,
windows环境下, 是gb2312
linux环境下, 是utf8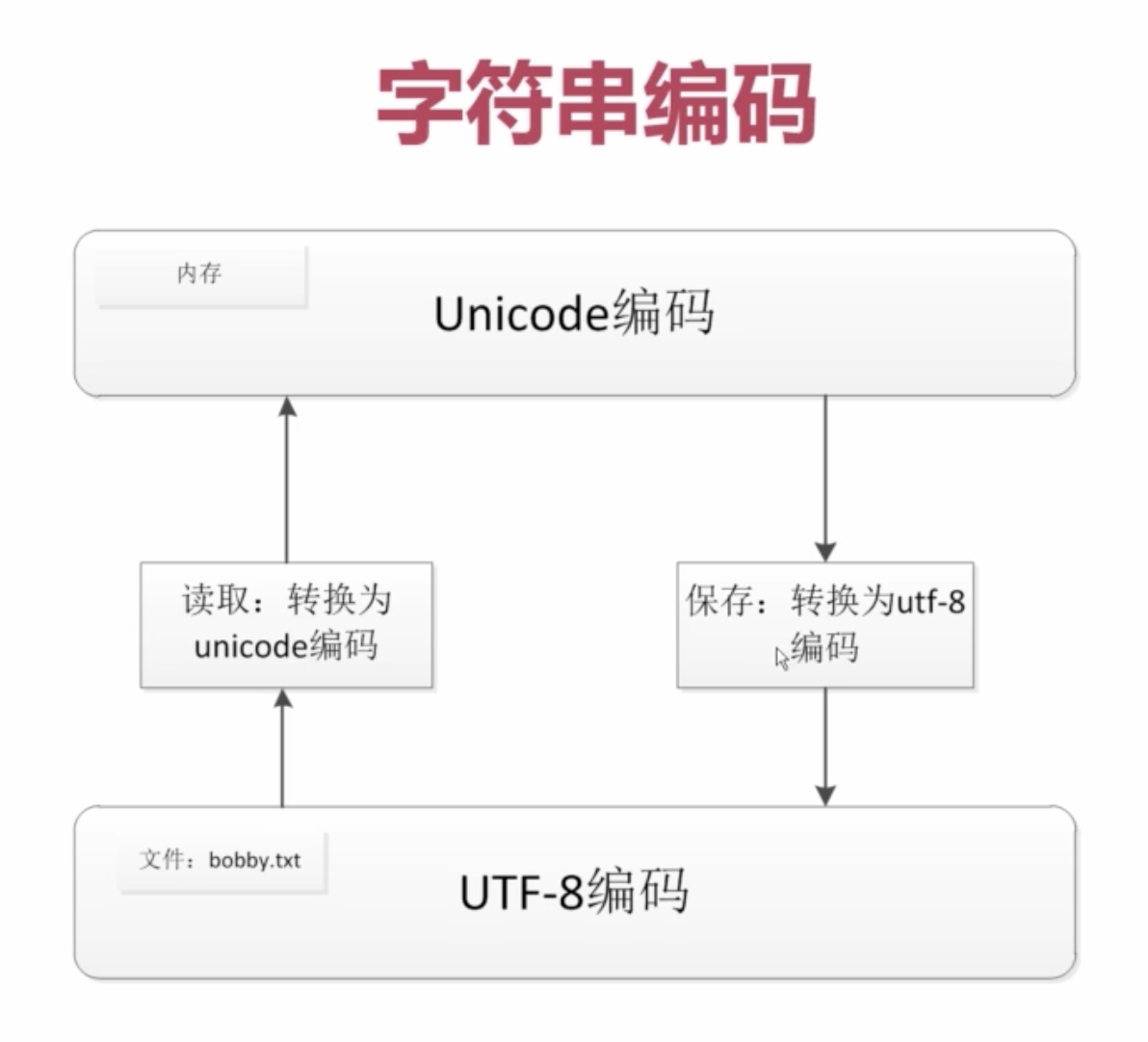
decode
将其他编码的字符,转换成Unicode编码
下面案例中s初始化时在windows下是gb2312编码,temp就是将gb2312编码转成Unicode编码
s = "python编码"temp = s.decode("gb2312")
encode
将Unicode编码转换成其他编码
//方式1s = u"python编码"temp = s.encode("utf8")//方式2s.decode("gb2312").encode("utf8")

若有收获,就点个赞吧
0 人点赞
