用到的类库
mouse类库
方法树
mouse
move(x,y) 移动鼠标
click 点击左键
应用场景
点击方式的验证码
自动化测试。。。
屏幕坐标获取工具
pickle类库
新建一个spider
新建一个爬虫文件
import scrapyfrom selenium import webdriverimport timeclass ZhihuSpider(scrapy.Spider):name = "zhihu"allowed_domains = ["www.zhihu.com"]start_urls = ["https://www.zhihu.com/"]def start_requests(self):browser = webdriver.Chrome(executable_path="/Users/user3/python/selenium/chromedriver")browser.get("https://www.zhihu.com/#signin")browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[1]/div/form/div[1]/div[2]').click()browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[1]/div/form/div[2]/div/label/input').send_keys("15208961314")browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[1]/div/form/div[3]/div/label/input').send_keys("15208961314")browser.find_element_by_xpath('//*[@id="root"]/div/main/div/div/div/div[1]/div/form/button').click()time.sleep(60)
配置到main中
在main文件中,把原先的spider类名换成当前创建的spider类名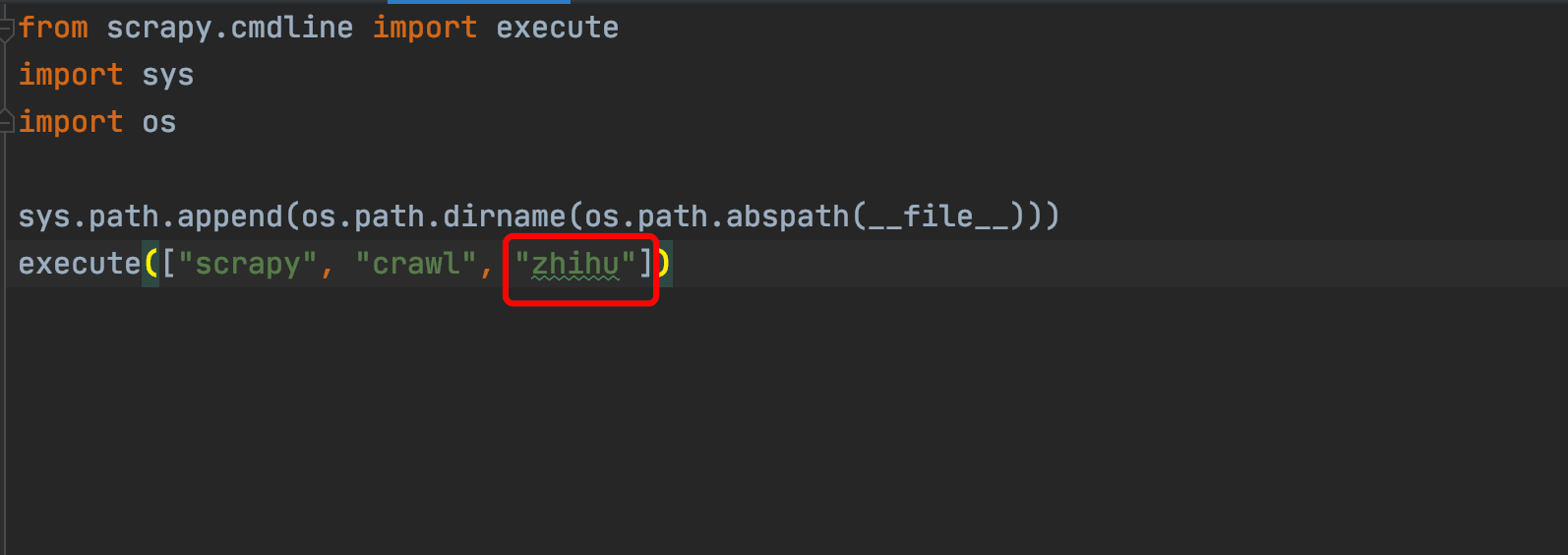
网站防御机制(对于selenium)
有的网站会识别到我们chromedriver,因为有一些js变量带chromedriver字符串,所以网站识别出来了,会对我们的行为做一些限制。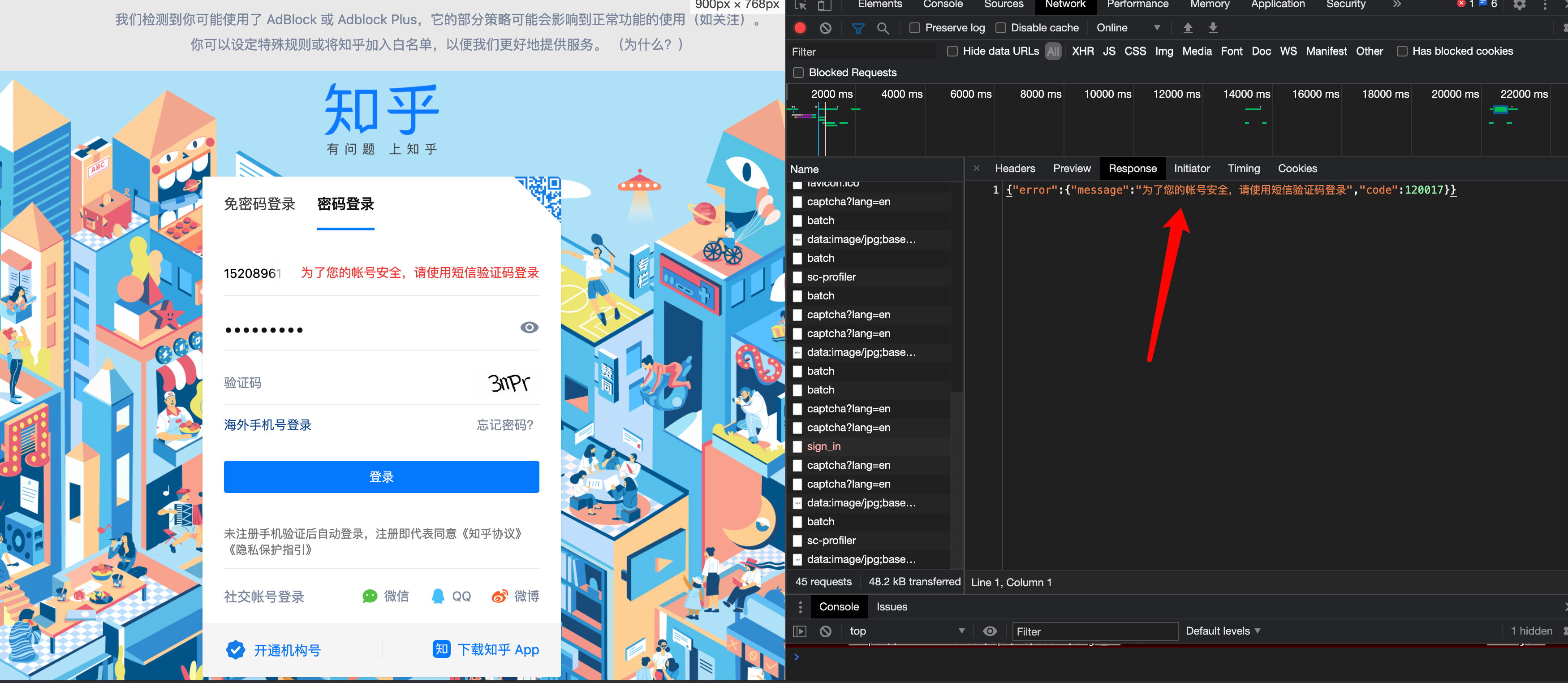
下载chrome60 driver2.33
驱动远程监听端口 (推荐)
命令行
注意:启动前把所有chrome实例都关掉
通过命令行将驱动通过远程监听端口命令打开
绝对路径/chrome --remote-debugging-port=9222
# mac则把exe去掉/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222
打开网页
127.0.0.1:9222/json 测试是否启动成功
代码形式
from selenium.webdriver.chrome.options import Optionschrome_option = Options()chrome_option.add_argument("--disable-extensions")chrome_option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")browser = webdriver.Chrome(executable_path="/Users/user3/python/selenium/chromedriver",chrome_options=chrome_option)
去掉特性(推荐)
option = webdriver.ChromeOptions()option.add_experimental_option('excludeSwitches', ['enable-automation'])browser = webdriver.Chrome(executable_path="/Users/user3/python/selenium/chromedriver",chrome_options=option)
selenium防止追加字符串
当有cookie的情况下,可能浏览器会自动填充文本框,这不是我们想要的
send_keys(Keys.CONTROL+"a')
模拟cookie
有的时候,我们已经登陆过账号了,在爬虫时,则需要模拟cookie来登陆
代码
初次
cookies = browser.get_cookies()pickle.dump(cookies,open(cookies文件夹绝对路径))cookie_dict={}for cookie in cookies:cookie_dict[cookie["name"]] = cookie["value"]return [scrapy.Request(url=self.start_urls[0],dont_filter=True,cookies=cookie_dict)]
非初次 - 因为初次我们已经把cookie 输出成文件了,所以以后都只需要从文件中load就行
cookies = pickle.load(open("cookie文件的绝对路径"))cookie_dict={}for cookie in cookies:cookie_dict[cookie["name"]] = cookie["value"]return [scrapy.Request(url=self.start_urls[0],dont_filter=True,cookies=cookie_dict)]
setting设置
# 从浏览器某个请求的request中可以获取这串参数USER_AGENT("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36")
# 有了这个设置,后续的request不需要添加cookieCOOKIES_ENABLED = TrueCOOKIES_DEBUG = True
整个模拟登陆流程
有cookie直接配置cookie自动会登陆上
没cookie则用selenium模拟操作,模拟操作中为了避免cookie的自动填充,需要模拟“全选后再输入”的行为,要去掉chrome驱动的特性,否则请求会被浏览器驳回。

若有收获,就点个赞吧
0 人点赞
