指针与常量
某一个变量是指针数组还是数组指针,只需要看*修饰的到底是哪个变量!
int main(){int a[3] = { 1,2,3 };//数组int* b[3];//指针数组int(*c)[3];//数组指针int(*e[3]);//指针数组,跟b一样void (*funcName)(int a);//函数指针funcName = getName;funcName(1);void (*funcNameArr[3])(int a);//函数指针的一维数组void (**funcNameArr1[3])(int a);//函数指针的二维数组int randomNum = 1997;int randomNum2 = 1998;const int* constp1 = &randomNum;//指针常量constp1 = &randomNum2;//编译通过//*cosstp1 = 1;//编译失败int* const constp2 = &randomNum;//常量指针*constp2 = 2;//编译通过//constp2 = &randomNum2;//编译失败cout << "end!" << endl;}
指针常量、常量指针
有的时候稍不注意就会将两者混淆,即便再去看一下资料,过一段时间又会忘掉,于是今天就用实际代码来看看两者到底有什么区别。
方法1: const double ptr;//const读作常量,读作指针,按照顺序读作常量指针
方法 2: double const ptr;//const读作常量,读作指针,按照顺序读作常量指针
double const ptr;//const读作常量,读作指针,按照顺序读作指针常量,
首先,在C/C++中,常量是什么意思?
常量的关键词是const,即,无法被改变。在编译阶段,编译器若发现对常量进行了修改,就会出现提示。基于此,常量在声明时就必须初始化,而且之后都不能改变,见下:
若不初始化: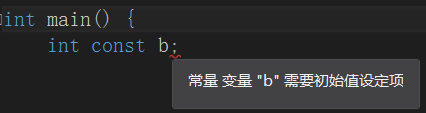
若尝试改变: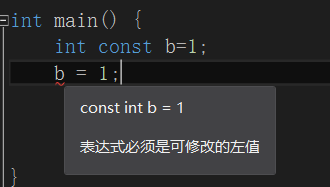
ok,现在我们明白了常量是什么意思:初始化之后无法被改变的值。在进行下一步之前,先解决一个小问题:指针是什么?
简单来说,指针就是一个盒子,里边放着的东西是一把钥匙,我们可以通过这把钥匙去打开一个对应的保险箱并取出东西。
盒子=指针,根据系统位数32/64位数不同,这个盒子的大小可能为4/8字节大小;
钥匙=内存地址,根据系统位数32/64不同,这个钥匙大小也是4/8字节;
那,保险箱是什么?
保险箱=内存空间,利用钥匙中隐藏至高奥秘——内存地址,访问对应内存地址的内存空间,取出其中的宝藏!
盒子、钥匙、保险箱,这三者哪个能变呢?
答曰:钥匙和保险箱可以变,盒子不能变。
为什么盒子不能变?
——因为盒子即是指针这个对象自身的地址,在声明这个指针的时候它就已经确定下来了(确定将这个指针盒子“放在”哪个内存位置)。就像下图所示,p1这个指针盒子,自出生的时候,它的位置就已经确定了,不存在重排座次的问题: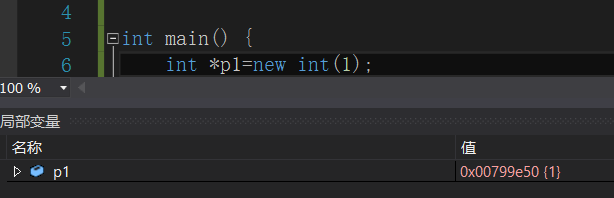
慢慢捋一捋,我们能改变的只有盒子里的钥匙和钥匙对应的保险箱。
怎么改变钥匙?
——简单,打开盒子,把钥匙换成其他的就行了,比如: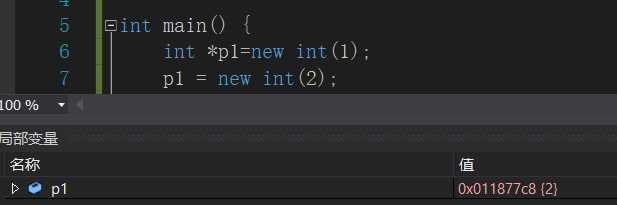
上图p1这个盒子中本来放的打开“1”保险箱的钥匙,被换成打开“2”的了。
PS:new 之后记得delete,例子那么写是会内存溢出的;
怎么改变保险箱?
——在回答之前,我们需要注意,钥匙和保险箱是配套的!如果改变了钥匙,那么打开的保险箱也就不同了,而且保险箱和钥匙本身的对应关系是无法被改变的(一般情况下)。
于是,我们所说的改变“保险箱”,其实说的是改变保险箱里的东西,打开保险箱,把箱子里的东西换一下,见下: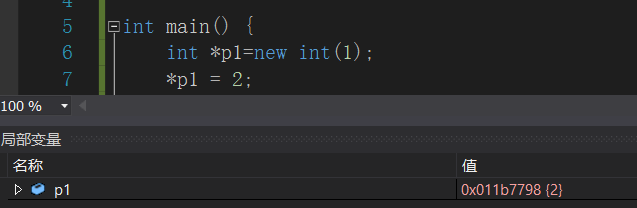
上图,就是打开保险箱,将里边存的“一只鹅”换成了“两只鹅”!
好了好了,回到正题,什么是指针常量和常量指针?
指针常量:指针本身是常量。
这不废话嘛,刚刚不是才说指针这个盒子是不能变的嘛!?
且慢,这里说的“指针本身是常量”,是说指针内部存的钥匙是无法改变的!你想想,盒子不变+盒子里的钥匙不变,不就等于指针不变么?这种情况下,保险箱里的东西可以更改。
常量指针:指针指向常量。
此话可解?
——(都说了只有钥匙和保险箱可以变,前面已经提到了钥匙不变的情况,所以…)常量指针是说钥匙对应的保险箱,它里面的东西不能变!保险箱一开始存的是“一只鹅”,到死也只能是“一只鹅”!
来看看下面两个例子,想一想哪一个是指针常量,哪一个是常量指针?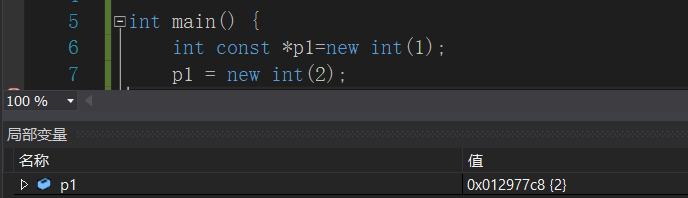
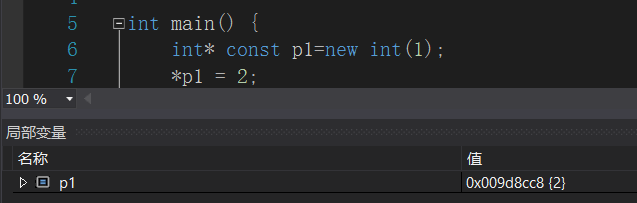
好好结合刚刚那几句话——钥匙、盒子、保险箱,应该就很简单了。
图一是常量指针,不能改变保险箱里的东西,但是——可以改变盒子里的钥匙;
图二是指针常量,不能改变盒子里的钥匙,但是——可以改变保险箱里的东西;
这两个东西语法上怎么定义的?
简单,看看const之后跟的是什么就可以了,跟的*,那就是常量指针,否则是指针常量,如下:
int* const p1=new int(1);
上面是指针常量,下面都是常量指针:
int const *p1=new int(1); const int *p1=new int(1);
字符串和字符串数组
字符串是存储在代码段的字符串数组,无法修改;
字符串数组是存在栈区的数组;
全局变量、全局函数同名
全局变量和全局函数不能同名(函数可以同名,因为重载)
全局函数可以和局部变量同名;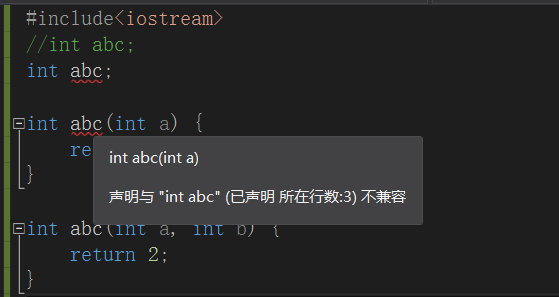
二、迭代器、失效
迭代器有什么用?
我们知道,STL标准库一共有六大部件:分配器、容器、迭代器、算法、仿函数、适配器。其中,迭代器就是用来“联结”算法、仿函数与容器的纽带。 除此之外,在设计模式中有一种模式叫迭代器模式,简单来说就是提供一种方法,在不需要暴露某个容器的内部表现形式情况下,使之能依次访问该容器中的各个元素,这种设计思维在STL中得到了广泛的应用,是STL的关键所在,通过迭代器,容器和算法可以有机的粘合在一起,只要对算法给予不同的迭代器,就可以对不同容器进行相同的操作。(参考:blog.csdn.net/shudou/arti… 比如下面这个find函数,展示了容器、算法和迭代器如何合作:
template<typename InputIterator, typename T>InputIterator find(InputIterator first, InputIterator last, const T &value){while (first != last && *frist != value)++first;return first;}
上述的find函数,只需要传递容器的迭代器,就可以实现对不同的容器实现相同的算法,这其实是一种泛型编程的思想。
不同容器的迭代器实现
vector
我们来看看在vector中对于iterator的实现:
template<typename T,class Alloc = alloc >class vector{public:typedef T value_type;typedef value_type* iterator;······};
在此可以看到iterator在vector中也只是简单的被定义成了我们传入的类型参数T的指针。
List
下面是某位博主自己实现的一个简单List 迭代器,供大家学习使用: @wengle
#ifndef CPP_PRIMER_MY_LIST_H#define CPP_PRIMER_MY_LIST_H#include <iostream>template<typename T>class node {public:T value;node *next;node() : next(nullptr) {}node(T val, node *p = nullptr) : value(val), next(p) {}};template<typename T>class my_list {private:node<T> *head;node<T> *tail;int size;private:class list_iterator {private:node<T> *ptr; //指向list容器中的某个元素的指针public:list_iterator(node<T> *p = nullptr) : ptr(p) {}//重载++、--、*、->等基本操作//返回引用,方便通过*it来修改对象T &operator*() const {return ptr->value;}node<T> *operator->() const {return ptr;}list_iterator &operator++() {ptr = ptr->next;return *this;}list_iterator operator++(int) {node<T> *tmp = ptr;// this 是指向list_iterator的常量指针,因此*this就是list_iterator对象,前置++已经被重载过++(*this);return list_iterator(tmp);}bool operator==(const list_iterator &t) const {return t.ptr == this->ptr;}bool operator!=(const list_iterator &t) const {return t.ptr != this->ptr;}};public:typedef list_iterator iterator; //类型别名my_list() {head = nullptr;tail = nullptr;size = 0;}//从链表尾部插入元素void push_back(const T &value) {if (head == nullptr) {head = new node<T>(value);tail = head;} else {tail->next = new node<T>(value);tail = tail->next;}size++;}//打印链表元素void print(std::ostream &os = std::cout) const {for (node<T> *ptr = head; ptr != tail->next; ptr = ptr->next)os << ptr->value << std::endl;}public://操作迭代器的方法//返回链表头部指针iterator begin() const {return list_iterator(head);}//返回链表尾部指针iterator end() const {return list_iterator(tail->next);}//其它成员函数 insert/erase/emplace};#endif //CPP_PRIMER_MY_LIST_H
迭代器分类
在STL中,除了原生指针以外,迭代器被分为五类:
- Input Iterator 顾名思义,input——此迭代器不允许修改所指的对象,即是只读的。支持==、!=、++、*、->等操作。
- Output Iterator 允许算法在这种迭代器所形成的区间上进行只写操作。支持++、*等操作。
- Forward Iterator 允许算法在这种迭代器所形成的区间上进行读写操作,但只能单向移动,每次只能移动一步。支持Input Iterator和Output Iterator的所有操作。
- Bidirectional Iterator 允许算法在这种迭代器所形成的区间上进行读写操作,可双向移动,每次只能移动一步。支持Forward Iterator的所有操作,并另外支持—操作。
- Random Access Iterator 包含指针的所有操作,可进行随机访问(vector容器支持),随意移动指定的步数。支持前面四种Iterator的所有操作,并另外支持it + n、it - n、it += n、 it -= n、it1 - it2和it[n]等操作。
上述五种迭代器的分类和联系可参考下图:
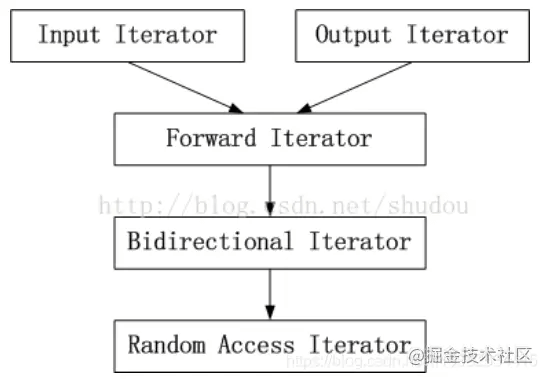
了解了迭代器的类型,我们就能解释vector的迭代器和list迭代器的区别了。
显然vector的迭代器具有所有指针算术运算能力,而list由于是双向链表,因此只有双向读写但不能随机访问元素。故vector的迭代器种类为Random Access Iterator,list 的迭代器种类为Bidirectional Iterator。
我们只需要根据不同的迭代器种类,利用traits编程技巧萃取出迭代器种类,然后由C++的重载机制就能够对不同型别的迭代器采用不同的处理流程了。为此,对于每个迭代器都必须定义类型iterator_category,也就是源码中的typedef std::forward_iterator_tag iterator_category; 实际中可以直接继承STL中定义的iterator模板,模板后三个参数都有默认值,因此继承时只需要指定前两个模板参数即可。如下所示,STL定义了五个空类型作为迭代器的标签:
template<class Category,class T,class Distance = ptrdiff_t,class Pointer=T*,class Reference=T&>class iterator{typedef Category iterator_category;typedef T value_type;typedef Distance difference_type;typedef Pointer pointer;typedef Reference reference;};struct input_iterator_tag{};struct output_iterator_tag{};struct forward_iterator_tag:public input_iterator_tag{};struct bidirectional_iterator_tag:public forward_iterator_tag{};struct random_access_iterator_tag:public bidirectional_iterator_tag{};
迭代器失效?
当使用一个容器的insert或者erase函数通过迭代器插入、删除或者修改元素(如map、set,因为其底层是红黑树)“可能”会导致迭代器失效,因此为了避免危险,应该重新获取的新的有效的迭代器进行正确的操作。
plus
vector
1、当插入(push_back)一个元素后,end操作返回的迭代器肯定失效。
2、当插入(push_back)一个元素后,capacity返回值与没有插入元素之前相比有改变,则需要重新加载整个容器,此时first和end操作返回的迭代器都会失效。
3、当进行删除操作(erase,pop_back)后,指向删除点的迭代器全部失效;指向删除点后面的元素的迭代器也将全部失效。
list
1、插入操作(insert)和接合操作(splice)不会造成原有的list迭代器失效,这在vector中是不成立的,因为vector的插入操作可能造成记忆体重新配置,导致所有的迭代器全部失效。
2、list的删除操作(erase)也只有指向被删除元素的那个迭代器失效,其他迭代器不受影响。(list目前只发现这一种失效的情况)
关联容器 对于关联容器(如map, set,multimap,multiset),删除当前的iterator,仅仅会使当前的iterator失效,只要在erase时,递增当前iterator即可。 这是因为map之类的容器,使用了红黑树来实现,插入、删除一个结点不会对其他结点造成影响(虽然删除了一个元素,整棵树也会调整,以符合红黑树或者二叉树的规范,但是单个节点在内存中的地址没有变化,变化的是各节点之间的指向关系)。
erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以要采用erase(iter++)(分三步走,先把iter传值到erase里面,然后iter自增,然后执行erase,所以iter在失效前已经自增了)的方式删除迭代器。
三、a++和++a的代码实现
a++和++a的区别在于,前者是值,后者是引用先看一个问题,以下代码的输出是什么?
#include <iostream>using namespace std;int main(){int a = 10;printf("%d\n",a++);printf("%d\n",++a);a = a++;printf("%d\n",a);return 0;}
答案应该是:10 12 12 最容易错的可能是最后一个,注意后增符号传回去的是原值。 后缀实现:
下面是 ++ 和 -- 的后缀实现形式:T T::operator++(int){ T T::operator--(int){T old(*this); T old(*this);*this=*this+1; --*this;return old; return old;}
前缀实现:
下面是 ++ 和 -- 的前缀实现形式:T& T::operator++(){ T& T::operator--(){*this=*this+1; --*this;return *this; return *this;} }
四、C语言与汇编
不知道gcc/g++怎么查看汇编代码?学一手!
在做一个测试博客的时候发现自己对使用gcc/g++ 查看汇编代码以及C/C++的汇编等阶段还有一点模糊,特此记录一下。
编译过程
1.预处理
C/C++的预处理其实就是一个词法(而不是语法)预处理器,其主要完成文本替换、宏展开以及删除注释等,完成这些操作之后,将会获得真正地“源代码”。
常见的include语句即是一个预处理器命名,在预处理器中它将所有的头文件包含进来。(该步骤的文件扩展名为.i)
2.编译
在这一步骤,将.i文件翻译为.s,得到汇编程序语言,值得注意的是所有的编译器输出的汇编语言都是同一种语法。
注:内联函数就是在这一环节“膨胀”进源码的,它的作用即在于:不是在调用时发生控制转移,而是在编译时将函数体嵌入在每一个调用处,适用于功能简单,规模较小又使用频繁的函数。递归函数无法内联处理,内联函数不能有循环体,switch语句,不能进行异常接口声明。仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。(什么调用开销?看看后边)
3.汇编
将.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件.o中(把汇编语言翻译成机器语言的过程)。
4.链接
链接(ld):gcc会到系统默认的搜索路径”/usr/lib”下进行查找,也就是链接到libc.so.6库函数中去。
函数库一般分为静态库和动态库两种。 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为”.a”。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统存储的开销。 动态库一般后缀名为”.so”,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。
查看汇编
复习了基础知识,用实例来介绍如何使用gcc/g++查看各阶段代码(限于篇幅只介绍汇编):
建立一个源文件如下:
#include <stdio.h>int main(){int a=1;int b=2;int c=a+b;return c;}
使用指令编译成汇编代码:
cat/gedit/vim等方式查看汇编代码:
.file "test_gcc.c".text.globl main.type main, @functionmain://.L前缀表示标签是本文件的本地,因此不会与其他文件中的同名标签冲突。//GCC通常使用.L作为自动生成的标签。“FB”表示“函数开始”//“FE”表示“函数结束”//之后的序号是程序自动生成的.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $1, -12(%rbp)movl $2, -8(%rbp)movl -12(%rbp), %edxmovl -8(%rbp), %eaxaddl %edx, %eaxmovl %eax, -4(%rbp)movl -4(%rbp), %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE0:.size main, .-main.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609".section .note.GNU-stack,"",@progbits
根据命令选项的不同,可以生成各个阶段的文件,详细指令如下:
| 参数 | 说明 |
|---|---|
| -c | 只编译不链接,生成*.o文件 |
| -S | 生成汇编代码*.s文件 |
| -E | 预编译 生成*.i文件 |
| -g | 在可执行程序里包含了调试信息,可用 gdb 调试 |
| -o | 把输出文件输出到指定文件里 |
| -static | 链接静态链接库 |
| -library | 链接名为library的链接库 |
参考资料
https://blog.csdn.net/alps1992/article/details/44737839
内联函数减调用开销
我们知道,在学习内联函数inline的时候会说“内联函数是以代码膨胀为代价,减小函数调用的开销”。
——那么,问题来了,函数调用开销是什么?内联函数是怎样减小调用开销的呢?
——别急,一个一个来。
函数调用开销
调用函数的开销大致可分两个部分:传递参数的开销和保存当前程序上下文信息所花费的开销。
对于传递参数的开销而言,传递的参数越多开销就越大;对于保存当前程序上下文所花费的开销而言,函数越复杂需要花费的开销就越大。
不太理解?
——那我们从汇编代码入手,看看所谓的函数调用开销是什么。对比一下函数调用和不借助函数调用实现同一个功能有什么区别?
探究
有函数调用的源文件:
#include <stdio.h>int add(int a, int b){return a + b;}int main(){int a = 1;int b = 2;int c;c = add(a, b);return 0;}
查看汇编代码:
不知道怎么生成?参考:https://juejin.cn/post/6953787367710785567

.file "test_inline_call.c".text.globl add.type add, @functionadd:.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl %edi, -4(%rbp)movl %esi, -8(%rbp)movl -4(%rbp), %edxmovl -8(%rbp), %eaxaddl %edx, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE0:.size add, .-add.globl main.type main, @functionmain:.LFB1:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6subq $16, %rspmovl $1, -12(%rbp)movl $2, -8(%rbp)movl -8(%rbp), %edxmovl -12(%rbp), %eaxmovl %edx, %esimovl %eax, %edicall addmovl %eax, -4(%rbp)movl $0, %eaxleave.cfi_def_cfa 7, 8ret.cfi_endproc.LFE1:.size main, .-main.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609".section .note.GNU-stack,"",@progbits
无函数调用版本的源代码:
#include <stdio.h>int main(){int a = 1;int b = 2;int c;c = a + b;return 0;}
汇编代码为:
.file "test_inline_nocall.c".text.globl main.type main, @functionmain:.LFB0:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $1, -12(%rbp)movl $2, -8(%rbp)movl -12(%rbp), %edxmovl -8(%rbp), %eaxaddl %edx, %eaxmovl %eax, -4(%rbp)movl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE0:.size main, .-main.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609".section .note.GNU-stack,"",@progbits
对比
仔细对比这两个汇编代码,发现真正的区别就在于(忽略add函数的汇编代码)——带函数调用的版本在四个地方多了部分汇编代码:
- 39-40行
将函数参数入栈,显而易见,若参数越多,则开销越大;movl %edx, %esimovl %eax, %edi
2. 41行
调用add函数,转移程序控制权;call add
3. 8、11行
建立新的栈帧,即add函数使用的栈空间,使用rbp的值来标识新的栈帧,因此要将原栈帧首地址保存下来,方便回到原来的即调用者的栈帧。pushq %rbpmovq %rsp, %rbp
4. 18、20行
恢复原栈帧,然后将控制权转移至调用者,实现函数调用返回。popq %rbpret
因此,函数调用和非函数调用的版本开销区别就在于这几行汇编代码,主要是参数入栈、控制权转移、栈帧恢复这三个部分。
那么如果使用内联函数,会有什么区别?
内联函数版本的源代码修改如下: ```cppinclude
attribute( ( always_inline ) ) inline int add(int a, int b) { return a + b; }
int main() { int a = 1; int b = 2; int c; c = add(a, b); return 0; }
> 注意,我在add()函数前加上了**attribute**( ( always_inline ) ),这是告诉编译器这个函数必须内联!因为inline这个关键字只是“建议”编译器内联,如果不加上述关键字,该内联无效。<br />汇编代码如下:```cpp.file "test_inline.c".text.globl main.type main, @functionmain:.LFB1:.cfi_startprocpushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl $1, -20(%rbp)movl $2, -16(%rbp)movl -20(%rbp), %eaxmovl %eax, -8(%rbp)movl -16(%rbp), %eaxmovl %eax, -4(%rbp)movl -8(%rbp), %edxmovl -4(%rbp), %eaxaddl %edx, %eaxmovl %eax, -12(%rbp)movl $0, %eaxpopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc.LFE1:.size main, .-main.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609".section .note.GNU-stack,"",@progbits
跟函数调用版本对比一下有什么区别???
——主要区别就在于少了函数调用call造成的栈帧更新、控制权转移这一部分操作,现在add的代码直接放在了函数调用处,将对应的参数放入栈中即可。
综上,内联函数是以代码膨胀为代价,将调用函数代码放入调用处以减少部分函数调用的开销。
注:inline只是对编译器的建议,编译器不一定采纳。而且如今的编译器优化很强,有时你不写inline,它都可能对部分函数进行优化,详见参考链接。
参考链接
https://blog.csdn.net/imred/article/details/48865359
https://blog.csdn.net/u011760195/article/details/100828112
https://zhuanlan.zhihu.com/p/353151788
汇编代码中cfi(呼叫帧信息)的介绍:
https://blog.csdn.net/jtli_embeddedcv/article/details/9321253
五、数组名居然是常量指针?
看这个:
char *s="abc";char a[];s=a;//1a=s;//2
请问,1和2语句有问题么?哪个有问题?为什么?
2有问题。
因为a表示数组名,而数组名是一个常量指针,它所指向的地址是个常量,你无法更改其指向。
涨姿势了。
那么,再请问,数组名在哪些情况下不是常量指针?
C中的数组名为常量指针,但两种情况下,数组名不用常量指针来表示:
1、当数组名作为sizeof操作符的操作数时,数组名表示整个数组,而不表示指向数组第一个元素的常量指针。 举例来说:
int arr[5] = {1, 2, 3, 4, 5};
int arrSize = sizeof(arr);
此时,arr表示的是整个数组,而非常量指针。所以arrSize = 4 5 = 20。如果arr表示的是常量指针,则arrSize的结果就不会是20, 而是4。
如下所示:
int arr[5] = {1, 2, 3, 4, 5}; //此处指针p指向数组的首元素
int p = arr;
int arrSize = sizeof(p); 综上所述,可以支持论点1;
2、当数组名作为&操作符的操作数时,数组名表示整个数组,而不表示指向数组第一个元素的常量指针。
举例来说:
int arr[5] = {1, 2, 3, 4, 5};
int p = &arr;
此时,arr表示的是整个数组,而非常量指针。所以p的值为数组首元素的地址。如果arr表示的是常量指针,则p的值就不会是数组首元素的地址, 而是指向现在指针p的一个指针,如下所示:
int arr[5] = {1, 2, 3, 4, 5}; //此处p为指向数组首元素的指针
int p = &arr; //如果在这种情况下,数组名表示常量指针,则&arr相当于&p(这是错的)
综上所述,可以支持论点2。
六、char p[4]与char (p)[4]的爱恨纠葛
请问,这两个到底有什么区别?
先说结论,前者是指针数组,p指向的是一个数组,里面存的是4个指针;
后者是数组指针,p是指向一个数组首地址,这个数组里的每个元素都是char;

若有收获,就点个赞吧
0 人点赞
