自我介绍
面试官你好,我叫雷磊,来自四川遂宁,现就读于四川大学电子与通信工程专业。接下来我将分两个部分对研究生期间的学习工作做一个简要说明。
在实习的时候,阿里巴巴,负责钉钉文档同构表的开发。后端负责根据前端用户的操作对数据库的内容进行相应的修改,并为前端提供相应的服务接口如聚合、分组、搜索等。实习前期我主要是补充项目的单测测试并熟悉业务流程,之后参与主链路的写入重构,最后参与基于ElasticSearch的实现表格的搜索服务的开发工作,这个部分主要负责是基于Akka的actor模型实现MongoDB数据库到ES的增量同步。
在实验室的时候,我主要负责了两个项目的开发,一个项目是基于目标检测与行为分类的值班室智能检测系统,在华为海思嵌入式设备上实现对监控室等场景下的事件监测,如人脸识别、睡岗检测、脱岗检测、入侵检测等等,并将相应的检测结果上报至中心端进行汇总。这个项目基于百度的Cyber框架实现节点式开发。
另一个是基于深度学习语义分割算法河长制视频监控算法,实现对水利视频的事件监测与消息报警,比如水色检测、水尺检测、钓鱼检测或者漂浮检测等,这个项目主要运行在linux docker环境下。
除了这些项目之外,为了拓阔知识面,在课余时间还学习了一些开源项目,比如阅读Redis的源码,了解其底层数据结构的实现与应用;基于C语言实现的轻量级服务器项目,简单来讲,使用epoll监听端口,采用反应堆式进行事件处理,解析报文,并将数据返还给客户端。生活方面,从本科到研究生,我一直都担任班长和团支书,主要处理常规事务或举行班级活动,和同学和老师相处的都很融洽;在兴趣爱好方面,主要有两个,一个是阅读,技术类、哲学类、历史类都看,意在滋养心灵;另一个是运动,例如健身、游泳、羽毛球等等,一方面是为了保持身体健康,另一方面可以和朋友有很多的交流机会。
目前已经完成了论文的盲审和答辩工作,如果有幸能够拿到offer的话随时都可以入职。很高兴有机会能参加这次面试,还请面试官多多指教!
钉钉文档-实习项目
单元测试
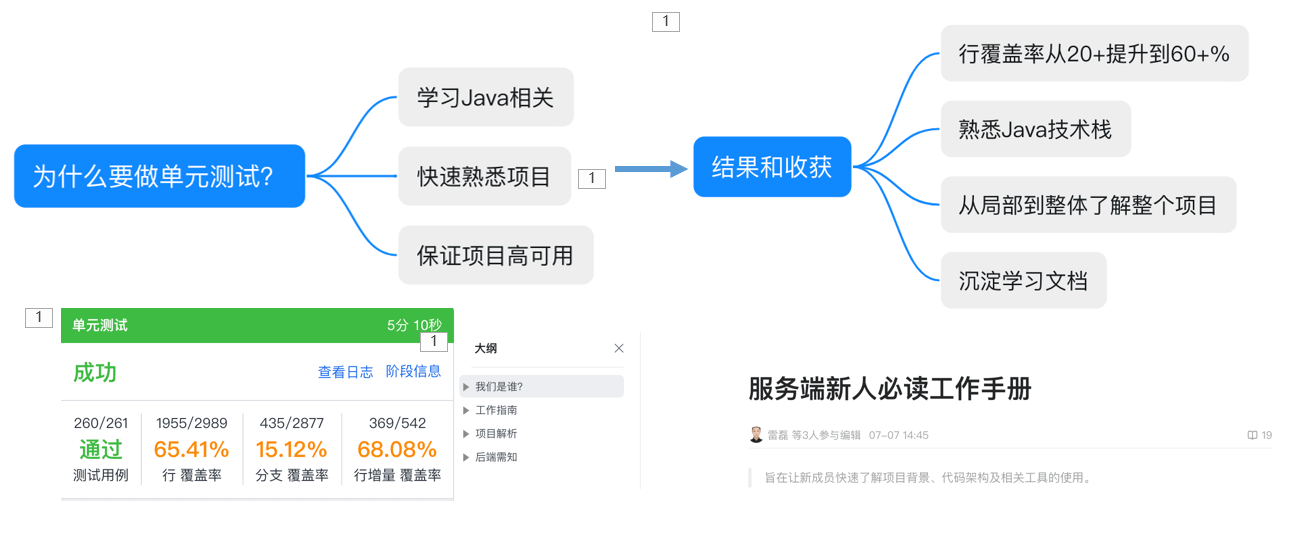
单元测试最佳实践
——单元测试是项目开发阶段必备的阶段,良好的单元测试可以提高代码的可用性,提高软件开发效率。
单元测试框架:Junit、Mockito
——java最常用的两个测试框架就是Junit和Mockito。
1、准备测试类,设置参数
新建一个测试类,这点可以依靠编程工具的插件自动生成测试类(比如IDEA的JUnit Generator),也可以自己手动建立。
2、执行测试的业务,执行流程
在测试类中引入你所需要的类与包,测试时可以使用junit jar包辅助也可以不用,直接main方法运行要测试的代码、业务。
3、验证测试的数据,验证结果(Assertion)
文档写入(同构表/多维表格)
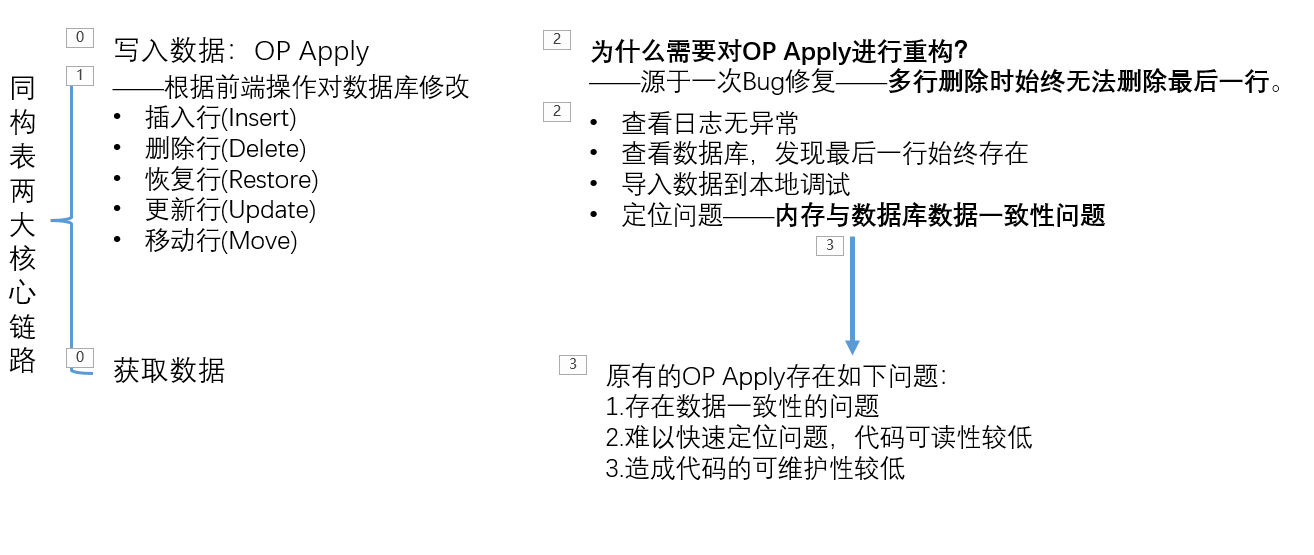
MongoDB数据库是一种文档性数据库,多维表格的每一个单元格都具有一定的类型和范围限制,前端和后端分别进行验证。
表格中每一行称为一行记录,每一列被当成一个字段。每列字段的数据格式是固定的,保证输入的数据规范有序。
常规表格视图、看板视图、甘特试图、表单视图
权限问题
目前项目还没有上线(可能已经被裁掉了)
不过在设计时,对使用者的权限都做了限制。
文档同步(Akka、Actor模型)
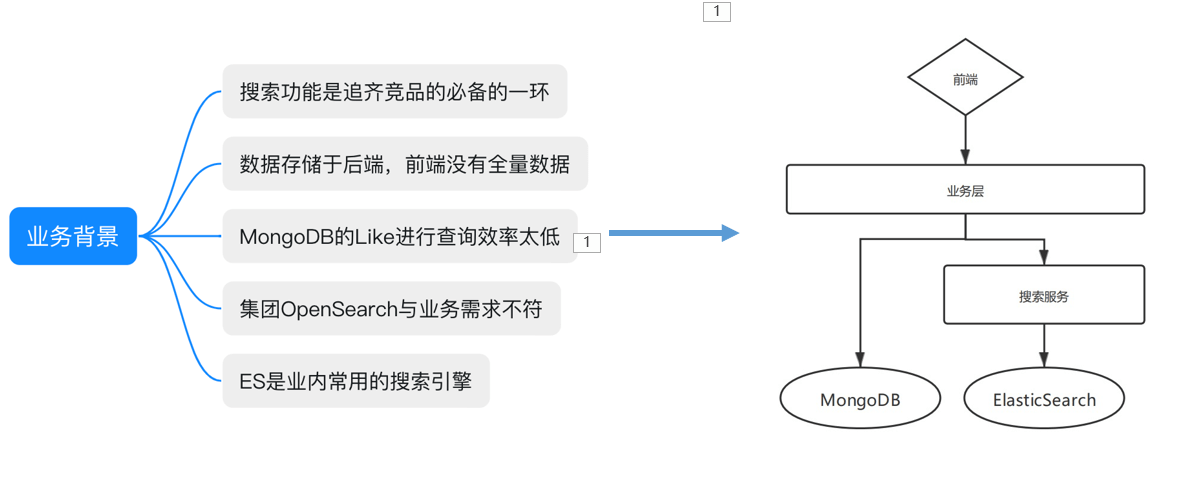
主要是为了实现文档的搜索功能,由于在同构表的架构中,前端仅有部分数据,后端数据都存储于MongoDB中,而搜索功能是一个比较重要的功能,而MongoDB数据库对全文搜索的支持不太好,因此就利用ES来提供了一个搜索功能。
MongoDB—->ElasticSearch
全量同步是指是一个兜底的方案,实现思路是利用一个定时任务在特定时间进行更新数据的替换,使用ScheduleX;
增量同步是指在用户对MongoDB数据库进行操作,利用MongoDB change stream进行同步更新至ElasticSearch。这个部分是基于Akka来进行Actor开发的。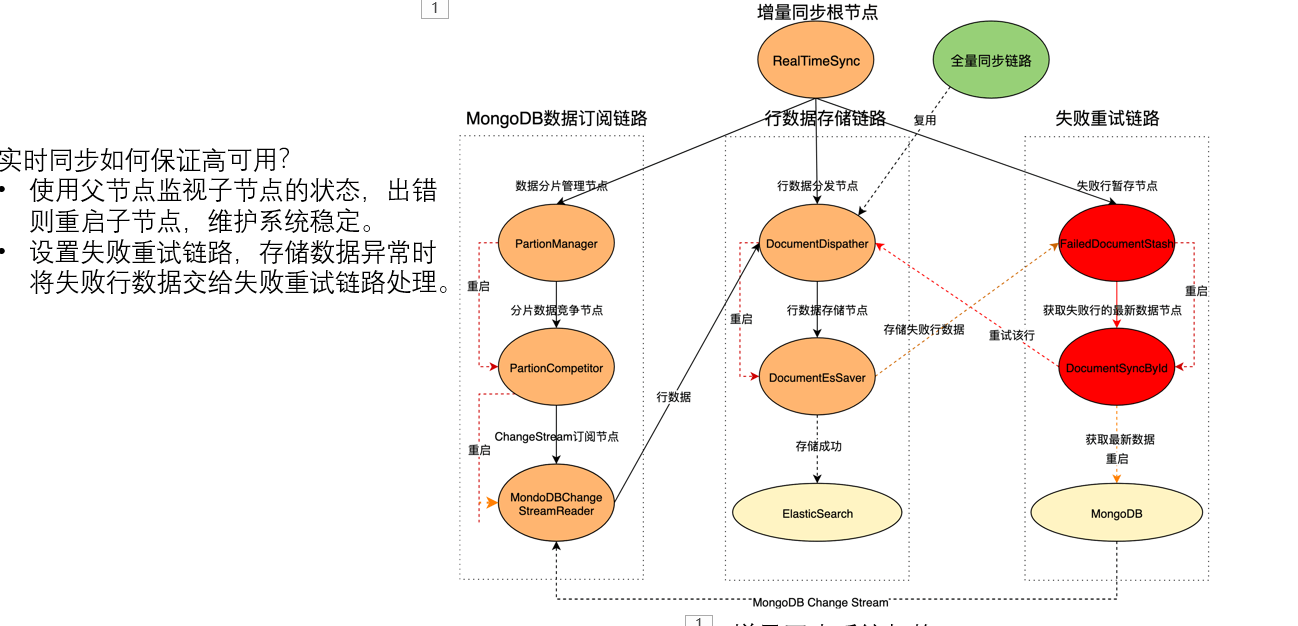
如何容灾? 如果失败了,将rowid发送给失败暂存节点,由失败暂存节点继续拉去最新数据进行重试,所以就不会有先后问题; 如果多次失败,那就只能丢掉了,等到全量同步来保证最终一致性。 如果某个实例挂掉了,其他的实例会通过竞争分片数据来重复它的操作,并且会将changestream的时间往前移动,尽量保证数据不丢失。这个过程还可以设置具体的时间戳来进行哦同步。
在并发程序中线程是并发程序的基本执行单元,但在Akka中执行单元是Actor。
Akka特点: 对并发模型进行了更高的抽象
对并发模型进行了更高的抽象 是异步、非阻塞、高性能的事件驱动编程模型
是异步、非阻塞、高性能的事件驱动编程模型 是轻量级事件处理(1GB内存可容纳百万级别个Actor)
是轻量级事件处理(1GB内存可容纳百万级别个Actor) 它提供了一套容错机制,允许在Actor出现异常时进行一些恢复或重置操作。
它提供了一套容错机制,允许在Actor出现异常时进行一些恢复或重置操作。
在Actor模型中并不是通过Actor对象的某个方法来告诉Actor需要做什么,而是给Actor发送一条消息。当一个Actor收到消息后,它根据消息的内容做出某些行为,如更改自身状态,此时这个状态的更改是Actor自身进行的,并非由外界干预进行的。
OT算法
在协同引擎部分进行OP的融合,OT算法的全称是Operation Transformation,是在线协作系统中经常使用的操作合并算法。
为什么多人编辑需要OT算法?
我们假设小贾和小王同时编辑一个文档。文档的初始内容是“123”,这时小贾先在123后面添加一个4,小王后在123后面添加一个5。 如果没有合并算法,小贾本地文档的内容变化过程是:
- 小贾把“123”改成了“1234”。
- 接收到消息,小王在3后面加了一个5。
- 小贾本地的字符串变成了“12354”。
小王本地文档的内容变化过程是:
- 小王把“123”改成了“1235”。
- 接收到消息,小贾在3后面加了一个4。
- 小王本地的字符串变成了“12345”。
此时,小王看到的字符串是正确的,小贾看到的字符串是错误的。所以我们需要一种合并算法,保证小贾和小王看到的最终结果都正确。当更多人同时编辑文档时,需要所有人的本地操作结果都是正确的,OT算法刚好适用于解决此问题。
保持内容一致性的基本思想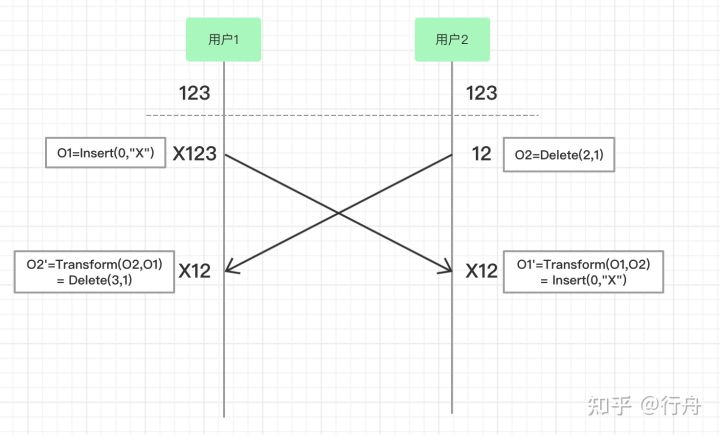
如上图,两个用户在浏览器中打开了同一个在线文档,文档的初始内容是“123”。
- 用户1和用户2同时操作,用户1的操作是O1=Insert(0,”X”),表示在位置0,插入字符串X;用户2的操作是O2=Delete(2,1),表示从第二个位置开始删除元素,删除长度是1。
- 用户1浏览器中字符串先变成“X123”,O2操作到达用户1的浏览器之后,和O1发生转换O2’=Transform(O2,O1)= Delete(3,1),O2’虽然也是执行删除操作,但是因为O1已经插入了X字符串,所以删除的位置+1,O2’变成了删除起始位置为3的元素,删除长度是1。对“X123”执行O2’操作,用户1本地的字符串变成“X12”。
- 用户2浏览器中字符串先变成“12”,O1操作到达用户2的浏览器之后,和O2发生转换O1’=Transform(O1,O2)=Insert(0,”X”),因为O2删除的元素是从第二个位置开始的,对O1’添加元素没有影响,所以O1’=O1。对“12”执行O1’操作,用户2本地的字符串变成“X12”。
总之,OT通过转换方法产生一个新的操作,使当前字符串应用到转换算法之后两个浏览器的内容保持一致。
撤销操作的基本思想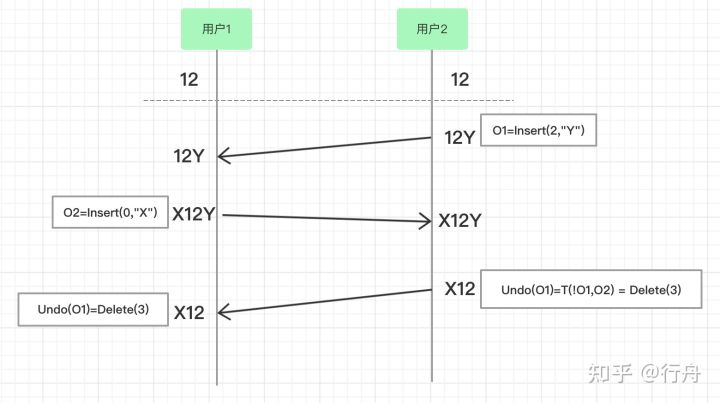
如上图,两个用户在浏览器中打开了同一个在线文档,文档的初始内容是“12”。
- 用户2执行操作O1=Insert(2,”Y”),在位置2插入字符串Y,用户2本地的字符串变成了“12Y”。
- 用户2的操作到达用户1的浏览器,此时用户1没有做任何操作,所以O1原样执行,用户1浏览器的字符串也变成了“12Y”。
- 用户1执行操作O2=Insert(0,”X”),在位置0插入字符串“X”,用户1本地的字符串变成了“X12Y”。
- 用户1的操作到达用户2的浏览器,此时用户2没有其他操作,所以O2原样执行,用户2浏览器的字符串变成了“X12Y”。
- 随后用户2执行撤销操作,此时撤销操作表示为Undo(O1)=T(!O1,O2) = Delete(3)。!O1是O1的逆向操作,本来应该是Delete(2),因为O2在字符串中增加了一个字符,所以此时的撤销操作是Delete(3),删除位置是3的元素,所以用户2本地的字符串变成了“X12”。
- 用户2的操作到达用户1的浏览器,用户1执行Delete(3)之后本地的字符串也变成了“X12”。
总之,撤销操作需要正确执行自己操作的逆向操作,还要保留其他客户端传来的执行结果。
操作压缩的基本思想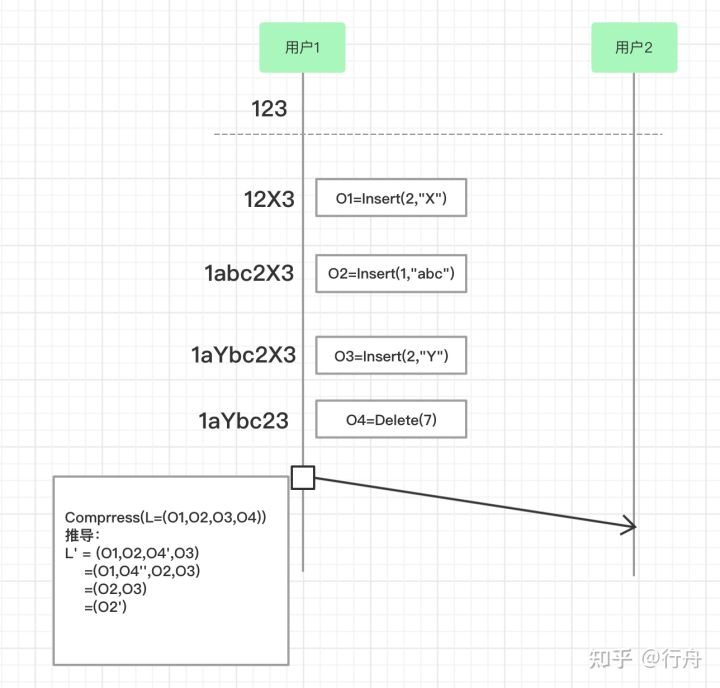
如上图,用户1和用户2看到的初始字符串是“123”。用户1依次进行了4次操作:
- O1=Insert(2,”X”)
- O2=Insert(1,”abc”)
- O3=Insert(2,”Y”)
- O4=Delete(7)
我们在传输之前,先压缩这四次操作,我们用L=(O1,O2,O3,O4)表示对4次操作的压缩。
压缩的步骤是从右往左,相邻两个操作依次进行换位(transpose)。具体步骤如下:
- O4和O3换位,transpose(O3,O4) = (O4’,O3’),此时O4‘=Delete(6),O3’ = O3,L’=(O1,O2,O4’,O3)。 O4‘和O3’是如何计算出来的呢?因为O4是删除位置为7的元素,也就是“1aYbc2X3”中的“X”,O3是在位置2插入字符串“Y”。交换两个操作之后先进行O4’再进行O3’。为了保证结果一致,O4’需要删除位置是6的元素,因为要删除的字符串“X”在6的位置。O3是在位置2插入字符串“Y”,和O4交换执行顺序后不受影响,所以O3’=O3。
- 继续执行,O4’和O2换位操作,transpose(O2,O4’) = (O4’’,O2’),为了保持结果一致,也就是O4’’还是要删除“Y”字符串,此时O4’’=Delete(3),O2’还是在位置1开始插入字符串“abc”,语意保持不变,O2’=O2。此时L’=(O1,O4’’,O2,O3)。
- 继续执行,O4’’和O1比较发现,这两个操作是互斥的,O1在位置2后添加了字符串“X”,O4’’又删除了此字符串,所以两个操作互相抵消,此时L’=(O2,O3) 。
- 继续执行,O2是在位置1后面添加字符串“abc”,O3是在位置2后面添加字符串“Y”,两个插入操作可以合并为在位置1后面添加“aYbc”,可以用O2’=Insert(1,”aYbc”)表示,L’=(O2’)。
- 最终合并完的操作就变成了O2’。数据传输时,把O2’直接发送给用户2就等价于发送O1,O2,O3,O4四步操作。
总之,数据合并的基本思想就是从右向左,通过操作的两两换位(transpose),寻找到可以合并或淘汰的操作,达到compose的目的。
开源项目-TinyWebserver
可以直接点开这两个链接去看看!
Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器。
- 使用 线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和模拟Proactor均实现) 的并发模型
- 使用状态机解析HTTP请求报文,支持解析GET和POST请求
- 访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件

IO复用的原理以及几种函数(epoll、poll、select)的理解?
IO复用是Linux中的IO模型之一,IO复用就是进程预先告诉内核需要监视的IO条件,使得内核一旦发现进程指定的一个或多个IO条件就绪,就通过进程处理,从而不会在单个IO上阻塞了。Linux中,提供了select、poll、epoll三种接口函数来实现IO复用。
epoll详解!底层api!https://mp.weixin.qq.com/s/OmRdUgO1guMX76EdZn11UQ
Select
select(默认水平触发)的缺点:
1、select支持的文件描述符太小,默认1024。
2、select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;
3、每次调用select都需要将fd集合从用户态拷贝到内核态,且要在内核遍历所有传递进来的fd,这个开销在fd很多时,开销也很大。
Poll
与select相比,poll使用链表保存文件描述符,没有了监视文件数量的限制,但其他三个缺点依然存在。
Epoll
epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。上面所说的select缺点在epoll上不复存在,
Epoll是事件触发的,不是轮询查询的。没有最大的并发连接限制。
网上总结:epoll是Linux下多路复用IO接口select/poll的增强版本,①它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率,因为它会复用文件描述符集合来传递结果而不用迫使开发者每次等待事件之前都必须重新准备要被侦听的文件描述符集合,②另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。③epoll除了提供select/poll那种IO事件的电平触发 (Level Triggered)外,还提供了边沿触发(Edge Triggered),这就使得用户空间程序有可能缓存IO状态,减少epoll_wait/epoll_pwait的调用,提高应用程序效率。
epoll的 LT 和 ET 模式
epoll对文件描述符的操作有两种模式:LT(level trigger水平触发)和ET(edge trigger边沿触发),
区别:
LT模式:是默认/缺省的工作方式,同时支持 block和no_block socket。这种工作方式下,内核会通知你一个fd是否就绪,然后才可以对这个就绪的fd进行I/O操作。就算你没有任何操作,系统还是会继续提示fd已经就绪,不过这种工作方式出错会比较小,传统的select/poll就是这种工作方式的代表。
ET(edge-triggered) 是高速工作方式,仅支持no_block socket,这种工作方式下,当fd从未就绪变为就绪时,内核会通知fd已经就绪,并且内核认为你知道该fd已经就绪,不会再次通知了,除非因为某些操作导致fd就绪状态发生变化。如果一直不对这个fd进行I/O操作,导致fd变为未就绪时,内核同样不会发送更多的通知,因为only once。所以这种方式下,出错率比较高,需要增加一些检测程序。
面试官:
epoll内核用什么数据结构?
RBTree与双向队列
epoll怎么处理信号?管道。
epoll怎么监听事件?epoll_wait()
三者的细分
1. 用户态将文件描述符传入内核的方式
select:创建3个文件描述符集并拷贝到内核中,分别监听读、写、异常动作。这里受到单个进程可以打开的fd数量限制,默认是1024。
poll:将传入的struct pollfd结构体数组拷贝到内核中进行监听。
epoll:执行epoll_create会在内核的高速cache区中建立一颗红黑树以及就绪链表(该链表存储已经就绪的文件描述符)。接着用户执行的epoll_ctl函数添加文件描述符会在红黑树上增加相应的结点。
2. 内核态检测文件描述符读写状态的方式
select:采用轮询方式,遍历所有fd,最后返回一个描述符读写操作是否就绪的mask掩码,根据这个掩码给fd_set赋值。
poll:同样采用轮询方式,查询每个fd的状态,如果就绪则在等待队列中加入一项并继续遍历。
epoll:采用回调机制。在执行epoll_ctl的add操作时,不仅将文件描述符放到红黑树上,而且也注册了回调函数,内核在检测到某文件描述符可读/可写时会调用回调函数,该回调函数将文件描述符放在就绪链表中。
3. 找到就绪的文件描述符并传递给用户态的方式
select:将之前传入的fd_set拷贝传出到用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。
poll:将之前传入的fd数组拷贝传出用户态并返回就绪的文件描述符总数。用户态并不知道是哪些文件描述符处于就绪态,需要遍历来判断。
epoll:epoll_wait只用观察就绪链表中有无数据即可,最后将链表的数据返回给数组并返回就绪的数量。内核将就绪的文件描述符放在传入的数组中,所以只用遍历依次处理即可。
4. 重复监听的处理方式
select:将新的监听文件描述符集合拷贝传入内核中,继续以上步骤。
poll:将新的struct pollfd结构体数组拷贝传入内核中,继续以上步骤。
epoll:无需重新构建红黑树,直接沿用已存在的即可。
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是同步阻塞IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间,比如linux的AIO。
为什么epoll更高效?
八、epoll更高效的原因
select和poll的动作基本一致,只是poll采用链表来进行文件描述符的存储,而select采用fd标注位来存放,所以select会受到最大连接数的限制,而poll不会。
select、poll、epoll虽然都会返回就绪的文件描述符数量。但是select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
select、poll都需要将有关文件描述符的数据结构拷贝进内核,最后再拷贝出来。而epoll创建的有关文件描述符的数据结构本身就存于内核态中。
select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多。
epoll的边缘触发模式效率高,系统不会充斥大量不关心的就绪文件描述符,但是代码编写难度也大,需要一次读/写完,有时会遗漏。
PS:虽然epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
epoll的使用流程
原文链接:https://blog.csdn.net/qq_35590267/article/details/122983150
三个函数API
epoll_create(int size);创建epoll描述符:size用来告诉内核这个监听的数目一共有多大。(在后来的Linux版本中已经被弃用,这个参数只要大于0就可以了哈!)
epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);事件注册函数,
它不同与select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,即epoll描述符, 第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd,第四个参数是告诉内核需要监听什么事,比如常用的epoll事件描述如下:
EPOLLIN:描述符处于可读状态 EPOLLOUT:描述符处于可写状态 EPOLLET:将epoll event通知模式设置成edge triggered EPOLLONESHOT:第一次进行通知,之后不再监测 EPOLLHUP:本端描述符产生一个挂断事件,默认监测事件 EPOLLRDHUP:对端描述符产生一个挂断事件 EPOLLPRI:由带外数据触发 EPOLLERR:描述符产生错误时触发,默认检测事件;
epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout)等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
内部数据结构红黑树?为什么?
核心数据结构是:1个红黑树和1个链表,附上了三个API的使用过程。
为什么需要用红黑树? 一棵红黑树。为了支持对海量连接的高效查找、插入和删除,eventpoll 内部使用了一棵红黑树。通过这棵树来管理用户进程下添加进来的所有 socket 连接。 其实红黑树的作用是仅仅是在管理大量连接的情况下,添加和删除 socket 非常的高效。如果 epoll 管理的 socket 固定的话,在数据收发的事件管理过程中其实红黑树是没有起作用的。内核在socket上收到数据包以后,可以直接找到 epitem(epoll item),并把它插入到就绪队列里,然后等用户进程把事件取走。这个过程中,红黑树的作用并不会得到体现。 其实我觉得这个解释不够全面,要说查找效率树哪能比的上 HASHTABLE。我个人认为觉得更为合理的一个解释是为了让 epoll 在查找效率、插入效率、内存开销等等多个方面比较均衡,最后发现最适合这个需求的数据结构是红黑树。
同步/异步,阻塞与非阻塞
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
这样,在网络IO中,同步异步,阻塞非阻塞,就可以形成2x2 = 4种情况,
(1)同步阻塞: 调用者发出某调用之后(比如调用了read函数),如果函数不能立即返回,则挂起所在线程,等待结果;
(2)同步非阻塞:调用者发出调用之后(比如read),如果当时有数据可读,则读取并返回,如果没有数据可读,则线程继续向下执行。在实际使用时,read调用会在一个循环中,这样就可以不断的读取数据(尽管可能某次read操作并不能获得任何数据);
(3)异步阻塞:调用者发出调用之后(如async_recv),线程挂起,被调用的读操作由系统(或者库)来进行,等待有结果之后,系统(或者库)通过某种机制来通知调用者(在调用者获得结果之前,调用者所在线程一直阻塞,这个看起来和同步阻塞很像,但可以这样理解,同步阻塞相当于调用者A调用了一个函数F,F是在调用者A所在的线程中完成的,而异步阻塞相当于调用者A发出对F的调用,然后A所在线程挂起,而实际F是在另一个线程中完成,然后另一个线程通知给A所在的线程,更准确的是将两个线程分别换成用户进程和内核);
(4)异步非阻塞:调用者发出调用之后(如async_recv),线程继续进行别的操作,被调用的读操作由系统(或者库)来进行,等待有结果之后,系统(或者库)通过某种机制(一般为调用调用者设置的回调函数)来通知调用者。
中航油智能行为检测系统
Cyber介绍
简单来说,cyber是一个分布式收发消息,和调度框架。着重讲一下消息处理机制即数据流程,每一个节点都可以创建和监听通道channel,类似于订阅和发布者关系中的topic;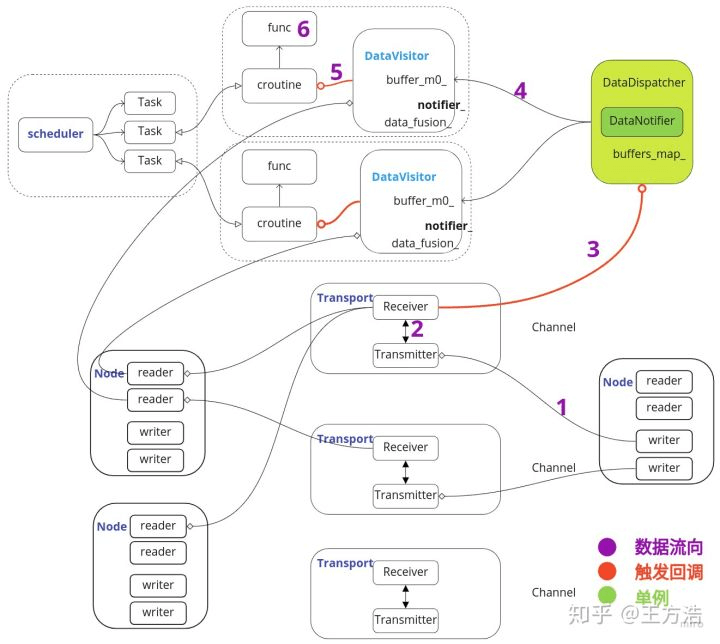
如上图所示,cyber的数据流程可以分为6个过程。
- Node节点中的Writer往通道里面写数据。
- 通道中的Transmitter发布消息,通道中的Receiver订阅消息。
- Receiver接收到消息之后,触发回调,触发DataDispather进行消息分发。
- DataDispather接收到消息后,把消息放入CacheBuffer,并且触发Notifier,通知对应的DataVisitor处理消息。
- DataVisitor把数据从CacheBuffer中读出,并且进行融合,然后通过notifier_唤醒对应的协程。
- 协程执行对应的注册回调函数,进行数据处理,处理完成之后接着进入睡眠状态。
(通过上述分析,数据处理的过程实际上就是通过协程完成的,每一个协程被称为一个Task,所有的Task(任务)都由Scheduler进行调度。从这里我们可以分析得出实际上Cyber的实时调度由协程去保障,并且可以灵活的通过协程去设置对应的调度策略,当然协程依赖于进程,Apollo在linux中设置进程的优先级为实时轮转,先保障进程的优先级最高,然后内部再通过协程实现对应的调度策略。)
这种分布式开发的最主要是方便后续算法更新(甲方的业务逻辑还在微调),另外无需担心多线程可能造成的死锁或者资源冲突问题。还有一点就是据说协程的效率更高。每一个节点都是一个动态库,方便更新。
详细介绍: https://zhuanlan.zhihu.com/p/115046708 https://www.pianshen.com/article/29641500401/ Cyber和Ros的对比: ROS 应用于自动驾驶领域的不足:
- 调度的不确定性:各节点以独立进程运行,节点运行顺序无法确定,因而业务逻辑的调度顺序无法保证;
Cyber的协程(Reader\Writer)
https://blog.csdn.net/A707471534/article/details/123444867
https://blog.csdn.net/A707471534/article/details/123299634 直接看文章! 太牛逼!
使用mysql(后期可能会改成sqlite),包括人脸id、人脸名字、人脸特征信息(计算好了之后下发给设备终端);
启动设备的时候,加载数据库的数据到一个结构体中,而后在比对时对该结构体数组进行遍历比较(必须遍历),取值最大的人脸作为匹配点;
google 的 glog.
在”task.h”中定义了异步调用的方法包括“Async”,”Yield”,”SleepFor”,”USleep”异步调用方法,用户可以通过上述方法实现异步调用。下面我们逐个看下上述方法的实现。
Async方法
template <typename F, typename... Args>static auto Async(F&& f, Args&&... args)-> std::future<typename std::result_of<F(Args...)>::type> {return GlobalData::Instance()->IsRealityMode()? TaskManager::Instance()->Enqueue(std::forward<F>(f),std::forward<Args>(args)...): std::async(std::launch::async,std::bind(std::forward<F>(f), std::forward<Args>(args)...));}
如果为真实模式,则采用”TaskManager”的方法生成协程任务,如果是仿真模式则创建线程。
TaskManager实际上实现了一个任务池,最大执行的任务数为scheduler模块中设置的TaskPoolSize大小。超出的任务会放在大小为1000的有界队列中,如果超出1000,任务会被丢弃。
Cyber中的调度器,SchedulerClassic代表着全局队列模型,SchedulerChoreography则代表着本地队列加全局队列模型。SchedulerChoreography模型和go语言的模型稍微有点区别,全局队列和本地队列是隔离的,也就是说本地队列不会去全局队列中取任务。(GPM模型是go语言中的概念,G代表协程,P代表执行器,M代表线程。P代表协程执行的环境,一个P绑定一个线程M,协程G根据不同的上下文环境在P中执行)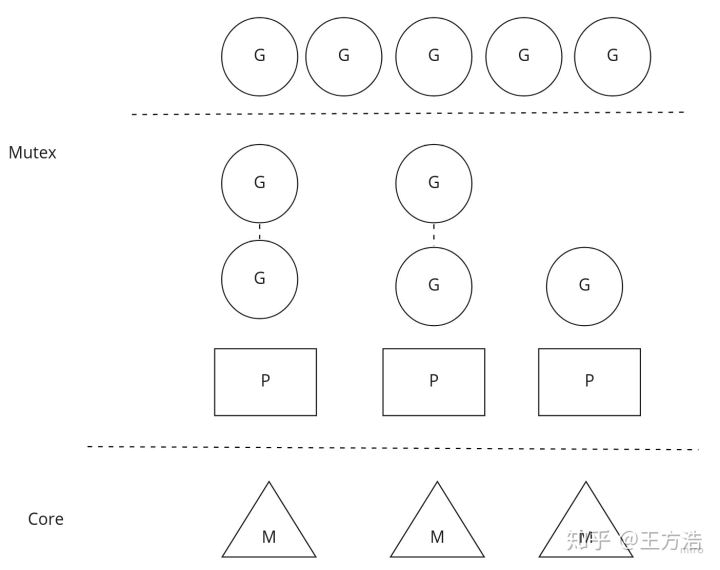
协程承载运行具体的任务,也就是说如果任务队列中有任务,则调用协程去执行,如果队列中没有任务,则让出协程,并且设置协程为等待数据的状态,那么让出协程之后唤醒是谁去触发的呢?
答:每次在任务队列中添加任务的时候,会唤醒协程执行任务。
项目过程中遇到了哪些问题?
项目各种问题:
调试困难,无法通过HDMI接口进行显示(需要需要自己编写底层opengl接口),选择使用nfs网络挂载,结果本地保存;
模型转换部署,RGB、BGR格式,以及转置,最终实现yolo、resnet、mtcnn的转换;
在进行视频流硬解码的时候,由于yuv的格式;
视频流延时,10s种,最后采用发送图片的格式;
交叉编译造成库版本问题;
河长制智能算法
项目主要为了实现对视频流进行算法分析,完成水色检测、钓鱼检测等业务功能,并把最终的结果传递给对方,部署在docker,以后会部署在政务云上。
线程如何管理?
所有的线程都派生于RiverThread类,每一个摄像头是一个RiverThread,其上运行的每一个算法也是RiverThread类,当检测到线程崩溃时,进行线程重启.
启动一个守护进程,当发现程序整体崩溃,会重启
项目中的日志系统?
是用什么实现的呢?glog?
遇到了什么问题?
可移植性,在自己电脑上安装,在对方服务器上远程配置,编译库及其复杂,特别是tensorflow的动态库,最后采用docker的方式统一更新;
运行一段时间程序会崩溃,刚开始以为是互斥锁造成资源冲突,最后排查了很久发现问题出在opencv中ffmepg在对海康摄像头的rtsp视频流进行解码的时候会发生不可预料的错误,查阅一些博客并测试后发现是海康视频流会出现偶尔断流等问题,最后在进程之外新建一个守护进程,定时判断算法是否在运行,若断掉则更新;
视频提供方基于安全考虑需要五分钟变更一次视频流地址,基于http歇协议来获取json信息,最终完成数据的更新。
Dockerfile命令
- FROM构建镜像基于哪个镜像
- RUN 构建镜像时运行的指令
- CMD 运行容器时执行的shell环境
CMD 在docker run 时运行。
RUN 是在 docker build。如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
- VOLUME 指定容器挂载点到宿主机自动生成的目录或其他容器
- WORKDIR 为 RUN、CMD、ENTRYPOINT、COPY 和 ADD 设置工作目录,就是切换目录
- EXPOSE 声明容器的服务端口(仅仅是声明)
- ENV 设置容器环境变量
- COPY 拷贝文件或目录到容器中,跟ADD类似,但不具备自动下载或解压的功能
云原生
云原生:一套新的技术体系、一种新的工作方法论、云计算发生的必然导向。大致包括四个部分: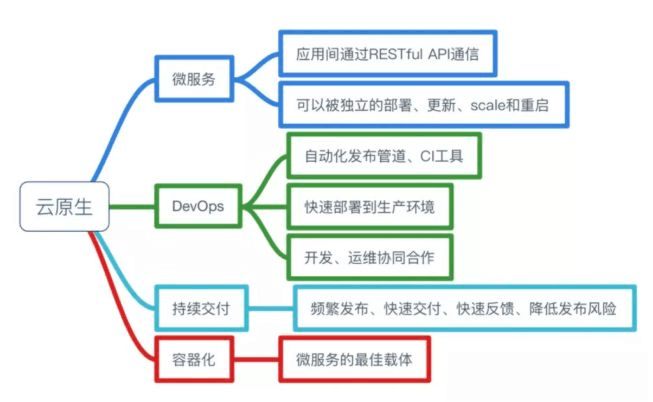
深度学习相关
语义分割,deeplabv3+介绍:https://blog.csdn.net/qq_39210987/article/details/120176546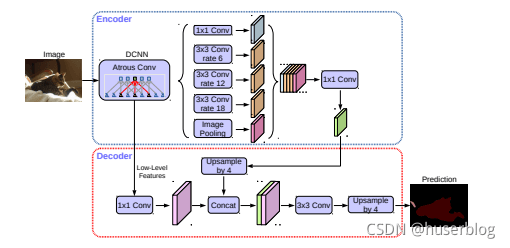
这里的结构分为了两部分:encoder和decoder。
encoder中连接的第一个模块是DCNN, 他代表的是用于提取图片特征的主干网络,DCNN右边是一个ASPP网络,他用一个11的卷积、3个33的 空洞卷积和一个全局池化来对主干网络的输出进行处理。然后再将其结果都连接起来并用一个11的卷积 来缩减通道数。
然后是decoder部分。他会将主干网络的中间输出和ASPP的输出变换成相同形状,然后将 其连接在一起,再进行33的卷积。最后利用这个结果来继续语义分割。
(调整了一个block,略微提高了一些速度);
项目中的算法?
1、漂浮物
传统:背景建模;
机器学习:聚类(通过像素点的值分为几类)
2、水岸线
边缘检测:二值化,先膨胀腐蚀去噪,再用candy算子检测直线。
3、水尺:
传统:定义hsv空间值(水尺颜色只有红蓝),用能量函数找出水尺和水面的分割。
机器学习:分割(定位准,无关照影响)
4、水位:
机器学习,分割出水尺
5、入侵
背景建模
6、钓鱼检测
人体检测与鱼竿之间的连接;
Mqtt了解多少?
MQTT协议运行在TCP/IP或其他网络协议,提供有序、无损、双向连接。其特点包括:
使用的发布/订阅消息模式,它提供了一对多消息分发,以实现与应用程序的解耦。
对负载内容屏蔽的消息传输机制。
对传输消息有三种服务质量(QoS):使用的是1.
Paho_mqtt:https://blog.csdn.net/programguo/article/details/100125177
QoS 0 At most once是一种 “fire and forget” 的消息发送模式:Sender (可能是 Publisher 或者 Broker) 发送一条消息之后,就不再关心它有没有发送到对方,也不设置任何重发机制。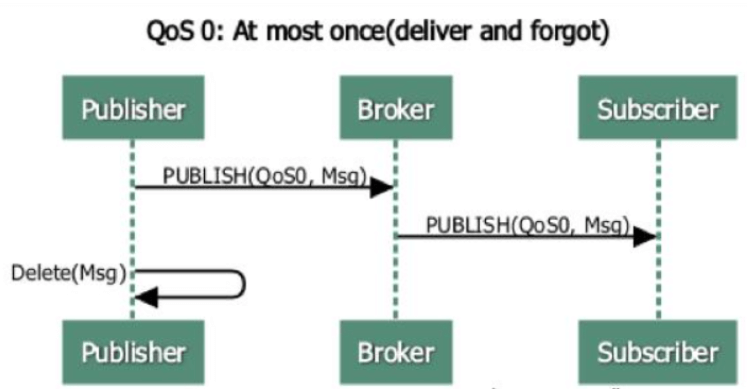
QoS 1 At least once包含了简单的重发机制,Sender 发送消息之后等待接收者的 ACK,如果没收到 ACK 则重新发送消息。这种模式能保证消息至少能到达一次,但无法保证消息重复。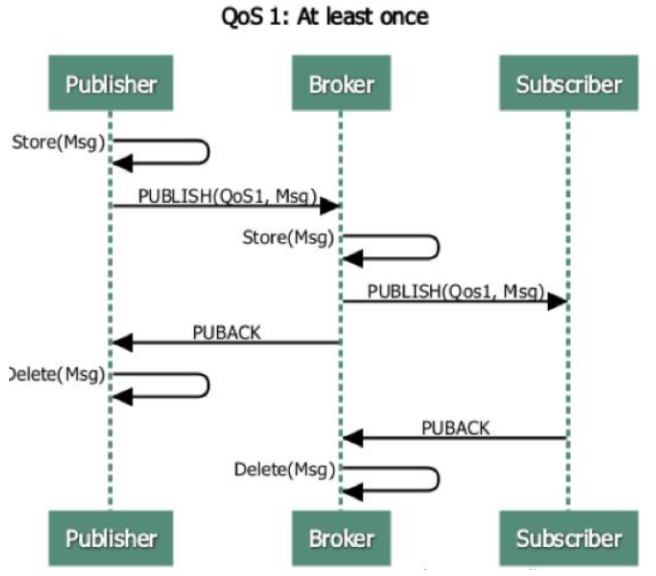
QoS 2 Exactly once设计了略微复杂的重发和重复消息发现机制,保证消息到达对方并且严格值到达一次。数据传输和协议交换的最小化(协议头部只有2字节),以减少网络流量。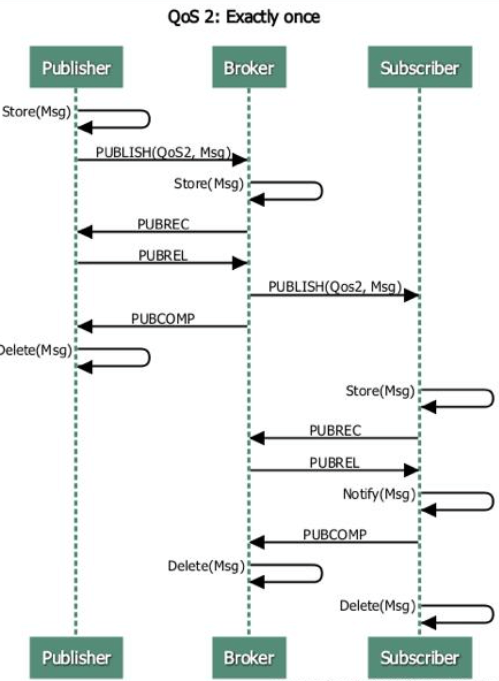
通知机制,异常中断时通知传输双方。
Qos1 和Qos2的消息收发机制是怎么实现的呢?
简单来说,Qos1多了一个ACK的确认;
Qos2相比之下更复杂,它存在确认消息的重发,但不会存在发送消息的重复接收。
https://blog.csdn.net/zerooffdate/article/details/78950907
会话保持
MQTT没有假设设备或Broker使用了TCP的保活机制,而是设计了协议层的保活机制:在 CONNECT 报文里可设置 Keepalive 字段,来设置保活心跳包 PINGREQ/PINGRESP 的发送时间间隔。当长时间无法收到设备的 PINGREQ 的时候,Broker 就会认为设备已经下线。
总的来说,Keepalive 有两个作用:
·发现对端死亡或者网络中断
·在长时间无消息交互的情况下,保持连接不被网络设备断开
对于那些想要在重新上线后,重新收到离线期间错过的消息的设备,MQTT 设计了持久化连接:在 CONNECT 报文里可设置 CleanSession 字段为 False,则 Broker 会为终端存储:
·设备所有的订阅
·还未被设备确认的 QoS1 和 QoS2 消息
·设备离线时错过的消息
在线状态感知
MQTT 设计了遗愿(Last Will) 消息,让 Broker 在发现设备异常下线的情况下,帮助设备发布一条遗愿消息到指定的主题。
实际上在某些 MQTT 服务器的实现里 (比如 EMQ X),设备上线或下线的时候 Broker会通过某些系统主题发布设备状态更新,更符合实际应用场景。
FFmpeg的视频解码过程
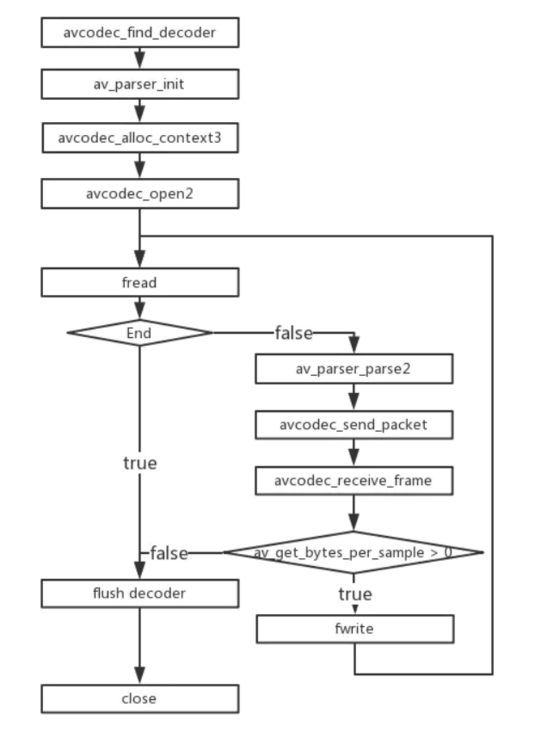
1.3 关键函数说明
avcodec_find_decoder:根据指定的AVCodecID查找注册的解码器。
av_parser_init:初始化AVCodecParserContext。
avcodec_alloc_context3:为AVCodecContext分配内存。
avcodec_open2:打开解码器。
av_parser_parse2:解析获得一个Packet。
avcodec_send_packet:将AVPacket压缩数据给解码器。
avcodec_receive_frame:获取到解码后的AVFrame数据。
av_get_bytes_per_sample: 获取每个sample中的字节数
1.4 关键数据结构说明:
AVCodecParser:用于解析输入的数据流并把它分成一帧一帧的压缩编码数据。比较形象的说法就是把长长的一段连续的数据“切割”成一段段的数据。
1.5 Avcodec编解码API介绍
avcodec_send_packet、avcodec_receive_frame的API是FFmpeg3版本加入的。为了正确的使用它们,有必要阅读FFmpeg的文档说明。FFmpeg提供了两组函数,分别用于编码和解码:
解码:avcodecsend_packet()(将编码后的数据送出去)、 avcodec_receive_frame()(获取解码后的帧)。
编码:avcodec_send_frame()(送数据过去)、avcodec_receive_packet()(获取编码后的数据)。
建议的使用流程如下:
像以前一样设置并打开AVCodecContext。
输入有效的数据:
·解码:调用avcodec_send_packet()给解码器传入包含原始的压缩数据的AVPacket对象。
·编码:调用avcodec_send_frame()给编码器传入包含解压数据的AVFrame对象。
两种情况下推荐AVPacket和AVFrame都使用refcounted(引用计数)的模式,否则libavcodec可能需要对输入的数据进行拷贝。
1.6 如何在一个循环体内去接收codec的输出?
即周期性地调用avcodec_receive()来接收codec输出的数据:
·解码:调用avcodec_receive_frame(),如果成功会返回一个包含未压缩数据的AVFrame。
·编码:调用avcodec_receive_packet(),如果成功会返回一个包含压缩数据的AVPacket。
反复地调用avcodecreceive_packet()直到返回 AVERROR(EAGAIN)或其他错误。返回AVERROR(EAGAIN)错误表示codec需要新的输入来输出更多的数据。对于每个输入的packet或frame,codec一般会输出一个frame或packet,但是也有可能输出0个或者多于1个。
流处理结束的时候需要flush(洗刷) codec。因为codec可能在内部缓冲多个frame或packet,出于性能或其他必要的情况(如考虑B帧的情况)。 处理流程如下:
**调用avcodec_send()传入的AVFrame或AVPacket指针设置为NULL。 这将开启draining mode(排水模式)。
反复地调用avcodecreceive()直到返回AVERROR_EOF的错误,这个方法这个时候不会返回AVERROR(EAGAIN)的错误,除非你忘记了开启draining mode。
codec可以重新开启,但是需要先调用 avcodec_flush_buffers()**来重置codec。
在同一个AVCodecContext上混合使用新旧API是不允许的,这将导致未定义的行为。
H264基本介绍
视频文件用封装格式封装起来的,封装格式的作用是什么呢?封装格式的作用就是把视频和音频打包起来。所以我们先要解封装格式,看有哪些视频流和哪些音频流,此时的音频流和视频流都还是压缩数据,不能直接用于显示的,这就需要解码。下面是播放一个视频文件时的流程图: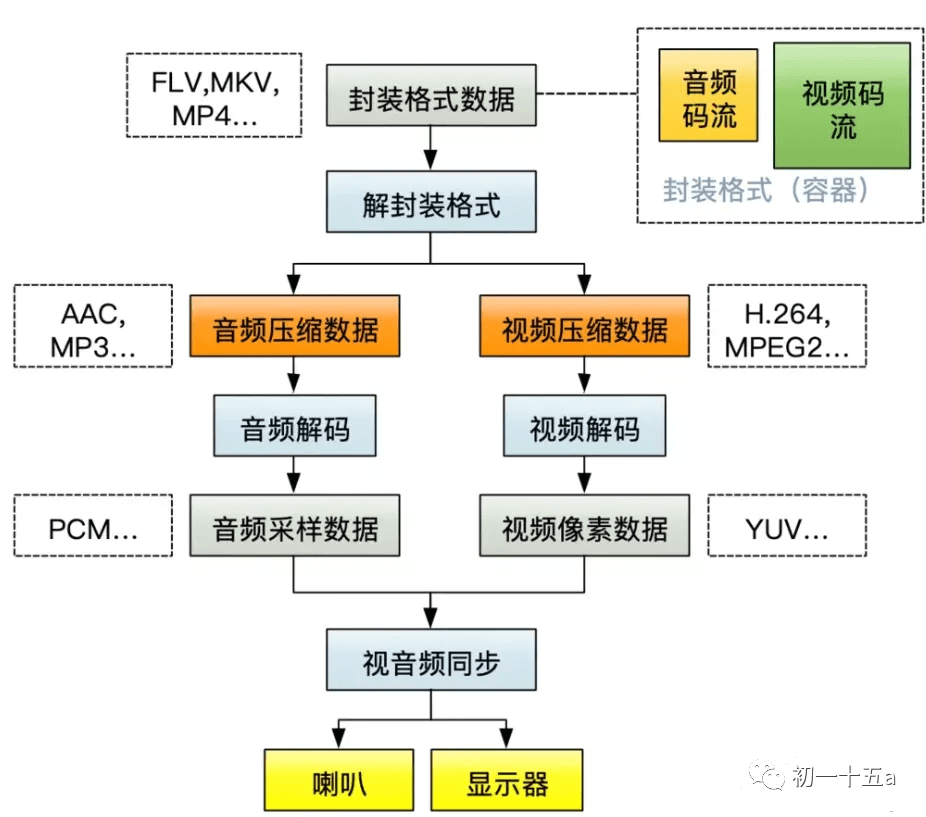
PS:PCM(Pulse Code Modulation,脉冲编码调制)音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准数字音频数据。
描述PCM数据的6个参数:
Sample Rate : 采样频率。8kHz(电话)、44.1kHz(CD)、48kHz(DVD)。
Sample Size : 量化位数。通常该值为16-bit。
Number of Channels : 通道个数。常见的音频有立体声(stereo)和单声道(mono)两种类型,立体声包含左声道和右声道。另外还有环绕立体声等其它不太常用的类型。
Sign : 表示样本数据是否是有符号位,比如用一字节表示的样本数据,有符号的话表示范围为-128 127,无符号是0 255。
Byte Ordering : 字节序。字节序是little-endian还是big-endian。通常均为little-endian。字节序说明见第4节。
Integer Or Floating Point : 整形或浮点型。大多数格式的PCM样本数据使用整形表示,而在一些对精度要求高的应用方面,使用浮点类型表示PCM样本数据。
常见的视频编码格式: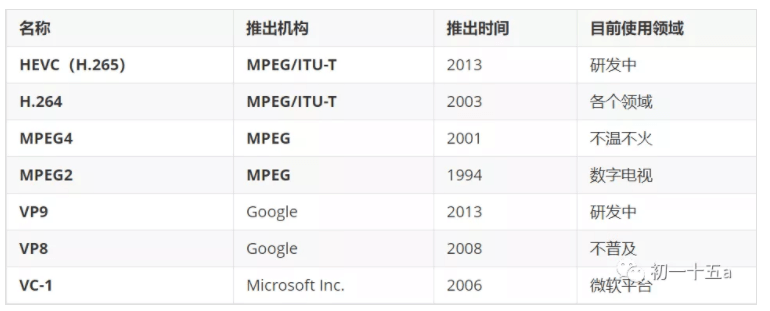
H264编码原理?
为什么要编码?
数据量太大了啊!视频是由一帧帧的图像组成,就像gif图片一样。一般视频为了不会让人感觉到卡顿,一秒钟至少需要30帧画面。加入该视频是一个1280x720的分辨率,那么不经过编码一秒钟传输的大小为1280x720x3*30~=90M。所以不经过编码的视频根本没法保存和传输。现在市面上主要将编码分为两大类H.264和MPEG。
编码原则?
·在相邻的几幅画面中,一般有差别的像素是10%以内的点,亮度差值变化不超过20%,而色度差值的变化只有不到1%,所以对于一段变化不大的画面,我们可以先编码成一个完整的图片帧A
·随后的B帧就不编码全部图像,只写入A帧的差别,这样B帧的大小只有完整帧大小的10%或者更小!B帧之后的C帧如果变化不大,我们可以继续以参考B帧的方式进行编码,依次循环下去。
·这段图像我们称之为一个序列:序列就是有相同特点的一段数据。当某个图像与之前的图像变化很大,无法根据前面的帧来生成,我们就结束上一段序列,开启下一段序列,也就是对这个图像生成完整的帧A1,随后的帧将参考A1帧,只写入与A1差别的内容。这个序列就是Gop序列。我们也可以把它当作一个场景,比如场景A和场景B,场景A的背景是红色,场景B的背景是绿色,那么A和B就是两个序列。每个序列是从I帧开始的,并且是唯一的,后面是B帧和P帧。两个I帧之间就是一个序列。
I帧、P帧、B帧是如何生成的呢?
当两个场景差异很大的时候,就会重新开始一个序列,那么这个序列就是从I帧开始的,也称关键帧。那么与I帧相似度极高,到达95%以上,则被编码成B帧;相似度达到70%编码为P帧(这些相似百分比,存疑)。
三种帧的介绍
I帧:帧内编码帧 ,I帧表示关键帧,你可以理解为这一帧画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
P帧:前向预测编码帧。P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)
P帧的预测与重构:P帧是以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
B帧:双向预测内插编码帧。B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别(具体比较复杂,有4种情况,但我这样说简单些),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时CPU会比较累。
B帧的预测与重构:B帧以前面的I或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。
H264的压缩方法
1.分组:把几帧图像分为一组(GOP,也就是一个序列),为防止运动变化,帧数不宜取多。
2.定义帧:将每组内各帧图像定义为三种类型,即I帧、B帧和P帧;
3.预测帧:以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
4.数据传输:最后将I帧数据与预测的差值信息进行存储和传输。
帧内(Intraframe)压缩也称为空间压缩(Spatial compression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码jpeg差不多。
帧间(Interframe)压缩的原理是:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporal compression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Frame differencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
PS:H264是结合帧内和帧间编码的。
详细的公式:
https://mp.weixin.qq.com/s/OA6DV_hnCoWnn_0lcheVbg
Gdb
Gdb的原理:GNU debugger,都是基于ptrace系统调用来实现的。
ptrace系统调用提供了一种方法,让父进程可以观察和控制其它进程的执行,检查和改变其核心映像及寄存器。主要用来实现断点调试和系统调用跟踪。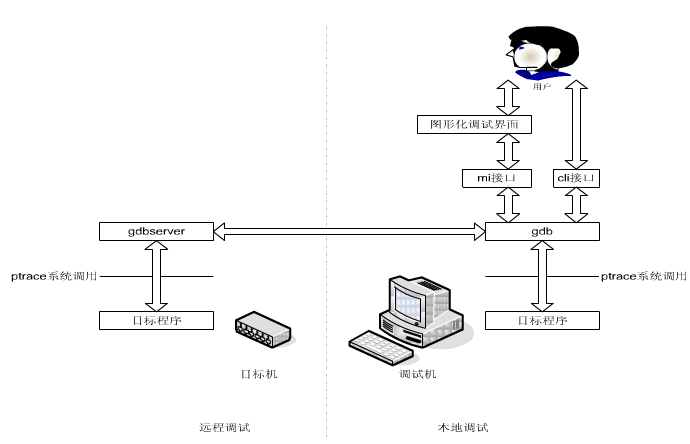
gdb调试的实现都是建立在信号的基础上的,交付给目标程序的任何信号首先都会被gdb截获。
工作中gdb最常用的场景有两个,一个是分析core文件,另一个是调试程序。
ulimit -a可以查看系统core文件的大小限制;
Cmake使用Gdb:
在CMakeLists.txt中添加:
SET(CMAKE_BUILD_TYPE “Debug”)
SET(CMAKE_CXX_FLAGS_DEBUG “$ENV{CXXFLAGS} -O0 -Wall -g2 -ggdb”)
SET(CMAKE_CXX_FLAGS_RELEASE “$ENV{CXXFLAGS} -O3 -Wall”)
分析core文件的方法如下:
1、gdb 程序名 core文件名
2、bt或where命令查看堆栈信息。
3、进入某个栈:f N,f是frame的缩写,N是栈号,如0、1、2。进入到某个栈后,才能通过p命令查看这个栈的临时变量,否则只能查看全局变量。
调试一个正在运行的程序使用gdb -p PID命令,PID即程序的pid。
需要注意的是,gdb调试正在运行的程序会导致程序挂起,因此请记住不要gdb调试正在运行的在线服务。
设置断点的方式有很多种,最常见的有两种:一是设置程序运行到源代码的某一行,二是设置程序运行到某个函数。
设置程序运行到某一行,通过“文件名:行号”的形式:
b test.cpp:100
设置程序运行到某个函数,通过“名字空间::函数名”的形式:
gdb namespace_a::func
查看断点:info b
删除断点:d N,d是delete的缩写,N是断点的编号,可以通过info b查看。
无论哪种方式设置断点,都要执行c命令(continue),让程序继续运行。
在调试程序时,最常用的gdb命令是:n、s、p
n即next,单步执行,执行下一步的意思,遇到函数会调用函数。
s即step,也是单步执行,但是会进入函数内部,然后结合n命令来调试函数。
p即print,打印变量,最常用的命令。p可以打印普通变量、std::string字符串、指针、数组等。
gdb打印字符串支持c_str()、length()等:
std::string str;
p str,p str.c_str()查看字符串内容,p str.length(),查看字符串长度
有时会遇到字符串太长不能显示全,最后显示”…”,可以通过命令取消长度限制:
set print elements 0 这样就能打印完整的字符串。
例如怎么查看线程信息?怎么打印所有线程的当前栈信息?
gdb查看线程信息:info thread,可以查看线程编号和正在执行的函数
进入某个线程:t N,N是线程编号,如1、2、3…
查看所有线程的栈信息:thread apply all bt
这是面试官在考察面试者有没有多线程问题排查经验。
牛客网的输入和输出
include
海量数据如何解决?
https://github.com/arkingc/note/blob/master/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95/%E7%AE%97%E6%B3%95%E9%A2%98%E6%80%BB%E7%BB%93.md#bigdata
位图的解法
https://blog.csdn.net/xxpresent/article/details/56488881
位图的详细介绍以及下标的选择!比较!
https://blog.csdn.net/xxpresent/article/details/56488881
Mqtt原理分析
实现MQTT协议需要客户端和服务器端通讯完成,在通讯过程中,MQTT协议中有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。
两个文件共同的url
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4GB。找出a、b文件共同的url。
hash先分治,而后hash_set来找重复即可。

若有收获,就点个赞吧
0 人点赞
