推荐两个java初学者学习的网站: 一个是java全栈学习,首推,结合代码和知识进行讲解,同时还有许多的实战项目,适合新人学习和java进阶。 另一个是廖雪峰的网站,比较基础的知识,适合用作知识点的查漏补缺。
简介
Java这门语言介于编译型语言和解释型语言之间。
所谓编译型语言,其流程是将源代码编译成可执行的机器码,而后由CPU读取执行,但是不同平台的指令集不同,因此需要不同的编译器来处理不同平台的编译工作。
而解释型语言即是无需编译,由一个被称之为“解释器”的东西直接加载源码进行程序运行,优点是方便快捷,全平台可用,缺点就是运行效率低,相当于在运行的时候还需要进行高级语言和机器语言的转换。
Java对两类语言的特点进行了综合,是一种介于两者之间的一种语言。
首先,将Java源代码编译成所谓的“字节码”,可以理解为一种抽象的CPU指令;而后通过一个叫做“虚拟机JVM”的东西来读取字节码并运行,这需要根据不同的平台编写不同的虚拟机。
这样有什么好处?那就是实现了“一次编写,到处运行”的效果,且JVM的运行字节码的效率远高于解释型语言。
之前提到过,Java是一种介于编译型和解释型之间的高级语言,其工作方式是:源代码—编译器—输出字节码—Java虚拟机。图解如下: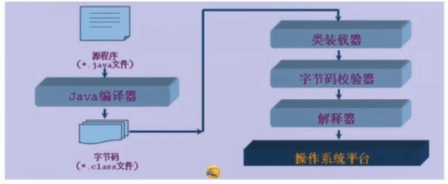
随着Java的发展,一共有三个版本:
- Java SE,即Java Standard Edition
- Java EE,即Java Enterprise Edition
- Java ME,即Java Micro Edition
它们三者之间的关系是Java EE 囊括Java SE囊括Java ME。
简单解释一下:
Java SE是标准版本的Java,包含标准的Java虚拟机和库;
Java EE是为了企业开发大型应用等,添加了大量的API和类库,它的JVM和JavaSE使用的完全相同;
而Java ME是为了适配嵌入式设备而“裁剪”过的版本,它无法运行Java SE版本的代码;
知识点补充: JDK:Java Development Kit,顾名思义,java开发工具,在有了它的前提下才能进行Java的编译、调试等; JRE:Java Runtime Environment,Java运行时态,简单理解就是Java虚拟机,当计算机配置好JRE后就可以运行Java程序了;
环境配置
开发环境配置
工欲善其事必先利其器,先老老实实地把环境配置好吧。
环境配置参见:https://www.runoob.com/java/java-environment-setup.html
至于ide安装参见:https://www.jetbrains.com/idea/download/download-thanks.html?platform=windows&code=IIC。
之后就是具有仪式性的一件事了——hello world!
新建一个project,取名helloworld,添加一个java类,代码如下:
public class helloworld {public static void main(String[] args) {System.out.println("Hello World");}}
利用javac 命令进行编译,再用java命令调用对应的类,结果如下:
设置github远程仓库
首先,需要在github等远程仓库开启一个仓库,而后,使用git clone下载远程仓库,基于下载的文件夹进行相应的代码编写。
也可以先准备好工程代码。而后git clone,不过需要使用git add将所有的文件加入仓库中,最后进行git push。 如何利用Ide新建Java项目?可以参考:https://www.evget.com/article/2020/9/8/38100.html
语法入门
变量类型
Java一共有两种变量类型:基础变量类型和引用类型变量。
基础变量类型跟C/C++类似,如整型、浮点型、布尔变量、字符型;
Java的字符型除了可以保存ASCII码类字符,还可以保存Unicode类字符,即一个中文字符。
引用类型可以类比之前所学C/C++的指针,其中存储着一个某个对象的内存地址。当一个变量所指向的是一个非基础类型的值时,它就是一个引用类型。
较为常见的一个引用类型就是字符串变量,相当于以前C的字符数组,注意,Java中的字符串具有一个特性,那就是“字符串不可变”:
String s = "hello";System.out.println(s); // 显示 hellos = "world";System.out.println(s); // 显示 world
这并不是说明字符串从hello变成了world, 而是s的指向了一个新建的字符串world。
拓展知识:
什么是强/弱类型语言? 强类型语言是一种强制类型定义的语言,即某一变量被定义类型之后,如果不经强制转换,那么就就一直是该类型;弱类型是可以根据环境变化自动进行转换; Java是强类型语言。什么是动态/静态语言? 动态语言在运行期间采取做数据类型检查,即编程时不会给任何变量指定数据类型,例如Python和Ruby; 静态语言需要声明数据类型,在编译时检查; Java是静态语言。
数组
跟C/C++不同的是,Java命名数组的方式有点细微的差别,它是将[]放在数组名的前面:
//如果不初始化,默认是0,而不会像C一样需要考虑是否全局或局部变量int[] data = new int[10];//初始化int[] data = new int[] { 1, 2,3, 4,5,6,7,8,9,10 };
与字符串一样,数组也是一个引用类型,可修改它所指向引用的对象。
另外,数组的遍历有两种方式,跟C一样:
//m1int[] data = new int[] { 1, 2,3, 4,5,6,7,8,9,10 };for (int i=0; i<data.length; i++) {int num = data[i];System.out.println(n);}//m2for(int num:data){System.out.println(n);}
注意,如果只是想打印数组中的内容,可以使用Java标准库中的Array.toString()。
System.out.println(Arrays.toString(data));如果data是多维数组,那么也可以进行循环打印:System.out.println(Arrays.deepToString(data));
面向对象基础
可变参数
Java中也有可变参数的用法:
public void setNames(String... names) {this.names = names;}
调用方法时,可以根据需要传入参数:
g.setNames("Xiao Ming", "Xiao Hong", "Xiao Jun"); // 传入3个Stringg.setNames("Xiao Ming", "Xiao Hong"); // 传入2个Stringg.setNames("Xiao Ming"); // 传入1个Stringg.setNames(); // 传入0个String//可变参数无法传入null
需要注意的是,由于使用的是可变参数,在对应方法的内部一定要对其个数和类型进行检查。
绑定参数
有点类似C中传入形参还是指针的问题
先看代码,想想输出的结果:
import java.util.Arrays;/*** @Author whitedew* @Date 2021/11/6 14:58*///传入的是基本类型、引用类型、数组时的差别public class BindArgs {public static void main(String[] args) {//1Group group = new Group();int num = 25;group.setScore(num);System.out.println(group.getScore());num = 30;System.out.println(group.getScore());//2Person person = new Person();String name = "white0dew";person.setName(name);System.out.println(person.getName());name = "god";System.out.println(person.getName());//m3Book book = new Book();String[] chapters = {"chapter1", "chapter2", "chapter3"};book.setChapters(chapters);System.out.println(Arrays.toString(book.getChapters()));chapters[1] = "endChapter";System.out.println(Arrays.toString(book.getChapters()));}}class Group {private int score;public int getScore() {return this.score;}public void setScore(int score) {this.score = score;}}class Person {private String name;public String getName() {return this.name;}public void setName(String name) {this.name = name;}}class Book {private String[] chapters;public String[] getChapters() {return this.chapters;}public void setChapters(String[] chapters) {this.chapters = chapters;}}
结果如下: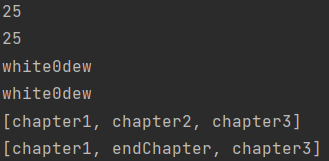
由上图可知,基本类型参数的绑定(赋值),其实是值的复制,而引用类型的绑定类似于C中的指针,指向同一个内存区域。
那么为什么在第二个例子中,修改name,不会影响person.getName()呢?
这是因为,String类型的变量只能修改其指向的对象,name=”god”这个操作其实是JVM在内存中分配了一块新的内存,其中值为”god”,而后让name指向这个新的内存区域。
即“Java字符串不变性”
然而,person.name还是指向的之前的”whiter0dew”。第三个例子就不一样了。
继承
跟C++一样,Java也有类与类之间的继承关系。通过以下方式来表示Student类继承Person类:
class Student extends Person {...}
通过继承的方式,可以使得开发变得更简易、快捷,因为子类可以直接使用父类中的某些字段或者方法。
不过值得一提的是,Java中所有的类都继承自Object类。Object类中提供了三个方法,分别是toString(即返回当前对象的字符串表达)、
子类能够使用父类中的方法、字段时,需要它们是protected或public。如果在父类中是private,那么就无法访问。如下:
class Person{private int age;//nopublic String name;//yesprotected String country;//yes}
值得注意的是,在子类中访问父类的字段或方法时,可以使用this.name、或name,还可以是使用super.name。
super关键词就是提示该字段是来自父类,如果不写,编译器会自动去定位到父类。所以它写不写都没关系,但是在某些情况下,必须使用super关键词,比如父类中的有参构造函数。
public class Main {public static void main(String[] args) {Student s = new Student("Xiao Ming", 12, 89);}}class Person {protected String name;protected int age;public Person(String name, int age) {this.name = name;this.age = age;}}class Student extends Person {protected int score;public Student(String name, int age, int score) {this.score = score;}}
上面的代码运行时,会报错,提示Person的构造函数出问题。
这是因为我们在新建Student实例的时候,会先去调用其父类的构造函数,等同于:
class Student extends Person {protected int score;public Student(String name, int age, int score) {super()//调用父类的构造方法this.score = score;}}
但是此时,父类中只有有参构造,那就必须显示的给定参数,如:
public Student(String name, int age, int score) {super(name,age)//调用父类的构造方法this.score = score;}
这其实说明子类不会继承父类的任何构造函数。
如何阻止一个类被继承?
可以在类上加上final修饰,如下:
public final Person{……}
这样所有类都无法继承Person类。
Java 15的预览状态开启时,可以指定只有谁可以继承:
public sealed class Shape permits Rect, Circle, Triangle {...}
shape类只允许Rect、Circle、Triangle去继承。
向上/向下转型
所谓向上向下转型其实就是C/C++中父类/子类指针能不能指向子类/父类对象的问题。
当将一个引用类型的变量指向子类类型时,就是一个向上转型,如下:
Person p = new Student();
这是因为Student是从Person继承来的,它其实是拥有Person类的所有东西(只不过有的由于权限无法访问)。
当将一个引用类型的变量指向其父类类型时,就是一个向下转型,如下:
DownTest downTest = (DownTest) new Test();
会报错,提示ClassCastException。
为了方便程序员知晓能够进行转型,Java提供了instance of()方法,来帮助判断,仔细看:
Person p = new Person();System.out.println(p instanceof Person); // trueSystem.out.println(p instanceof Student); // falseStudent s = new Student();System.out.println(s instanceof Person); // trueSystem.out.println(s instanceof Student); // trueStudent n = null;System.out.println(n instanceof Student); // false
子类和父类的关系是is,has关系不能用继承。 如果是has关系,那持有一个对应的对象即可。
重载/覆写/隐写
重载(overload),是指在同一个类中,方法名相同,但是传入的参数类型和个数等不同。重载主要是将同类的方法用同一个名字来表示,方便记忆和使用
注意,方法的返回类型无法作为重载的依据
覆写(override),覆写是指子类中定义了与父类方法名完全相同的方法(参数类型和个数完全一样),区别仅在于方法内部的实现,这主要是为了根据子类的需要取实现跟父类不一样的效果。如:
class Animal {public void eat() {System.out.println("Animal eat!");}}class Cat extend Animal {@Override//提示编译器去检查是否这个覆写是否正确,可选项public void eat() {System.out.println("Cat eat!");}}
那如果已经发生了覆写,子类想调用父类的方法怎么办?通过super进行显式的调用。
那如果父类如何禁止某个方法被覆写?在对应的方法前加上final。
总结一下final: 一是禁止类被继承 二是禁止类的方法被覆写 三是可以加在对应字段的前面,表示禁止该字段在初始化之后就不能被修改
值得注意的是,一个引用类型的变量调用的方法是父类的还是子类的?
——这是根据其实际指向的对象来定,而不是引用类型。
这就是所谓的多态(Polymorphic)——程序在运行时根据实际的对象类型来选择相对应的方法。
隐写,当在子类中写的某个方法和父类完全一样时,父类的方法就被子类“隐藏”了。在这种情况下,通过子类对象调用这个方法时,实际调用的方法就是子类的方法。
抽象类/抽象方法/接口
如果一个类中的方法只有方法名,且没有参数,没有具体实现,那就需要加上abstract表示其实一个抽象方法,如:
public abstract void eat();
另外,拥有抽象方法的类,被称之为抽象类,也必须加上abstract,否则无法正常编译:
abstract class Animal{public abstract void eat();}
而且,抽象类是无法实例化的:
Animal animal=new Animal()
上面会报错。都无法实例化,那么抽象类来干嘛?
抽象类的作用就是提供一个规范,让所有继承它的子类,都需要去实现其定义的抽象方法。
当一个抽象类中没有任何实例字段(请看下一节),有且仅有抽象方法,那么可以用interface关键字将其定义为接口。
接口就是比抽象类还要抽象的“类”,它的唯一作用就是制定接口规范,其他所有实现(implement)它的类都必须严格覆写接口中的方法。
一个类仅能继承一个类,但是可以实现多个接口
另外,接口也可以继承(extend)另外的接口,相当于扩展了接口中的方法。
之前提到,接口中的所有的方法都是抽象方法,都需要子类其覆写,也就是说只要对接口进行了修改,那么所有实现该接口的子类都需要进行相应的修改——为了防止对接口的某些修改影响到实现它的子类,出现了default方法。
所谓default方法就是在接口中,有方法实现的方法。
interface Animal {String getType();default void recognize() {System.out.println( " Type is :"+getType());}}
recognize()方法在子类中无需覆写,因为其本身就是为了防止影响到子类。
抽象类、抽象方法、多态、接口等概念,共同构成了面向对象编程的坚实基础。
包与作用域
包
在Java中,如何区分众多的类名、接口名呢?
如果我是接手其他人的工程,难道我取名的时候还要先看一遍项目里到底哪些名字已经取过了?
可以想象,一些常用、直观的类名是最常被用到的,那么我们有没有什么方法可以将自己的类名与其他人的类名进行区分呢,从而避免类名冲突。
可以,那就是包(package)。
简单来理解,包就类似于C++中的命名空间。我们将可以将自己所写的代码都放在Myname这个package中。
当在程序中需要用到某个方法时,有一下三种方式:
//1,先导入,而后直接使用import Myname.Deeplearning;……Deeplearning net=loadNet(path);……//2,直接在使用的地方写出完整的类名Myname.Deeplearning net=loadNet(path);//3,也可以直接导入包中所有类,不建议,因为可能让程序难以阅读,无法确定来自哪个包import Myname.*
另外,使用import static 可以导入类中的静态方法或字段。
注意,package具有层级结构,相当于将方法进行分门别类,在同一个层级的package中的类可以互相使用(不同层级间的方法没有任何继承关系,单纯是分类而已),如:
//类似于Java标准库这种分级import java.util.Arrays;
另外,不同的包,或者相同的包的不同目录下可以有相同名称的class文件,这在很大程度上避免了类名冲突。如果当真出现了类名相同,那么就需要显式著名所使用类来自的包,即上面的第二种使用方法。
静态字段/静态方法
每一个类中的字段分为实例字段和静态字段:
class Animal {public String type;public String hobby;public static bool isMammal;}
所谓静态字段,就是类中用static修饰的变量(一般是public),它属于这个类(class special),而不是独属于某一个实例。可以直接通过类名.字段的方式来访问。
静态方法同上,不需要建立类的实例就可以进行访问,常用的工具类中的方法大都是静态方法,如:
Math.max()Arrays.toString()……
上一节提到,接口中没有任何实例字段,确实如此,但是它可以拥有静态字段,编译器会自动视其为public static final修饰的变量。
内部类
在同一个包之下的类之间没有所谓的父子关系,它们是同等低位。
如果一个类在另外一个类的内部,那就称为内部类(Nested class)。内部类一共有以下几种:
第一种,被称为inner class(内嵌类),即直接在一个类里面定义另外一个类:
class Animal {class Type {// 这个Type// 就是inner class}}
与普通类不同的是,innerl class不能独立存在,它必须依附于包裹它的类,像这样去使用:
public class Main {public static void main(String[] args) {Outer outer = new Outer("Nested"); // 实例化一个OuterOuter.Inner inner = outer.new Inner(); // 实例化一个Innerinner.hello();}}class Outer {private String name;Outer(String name) {this.name = name;}class Inner {void hello() {System.out.println("Hello, " + Outer.this.name);}}}
与此同时,inner class由于处于outer class的内部,它其实拥有访问outer class的private字段和方法的权限。
观察Java编译器编译后的.class文件可以发现,Outer类被编译为Outer.class,而Inner类被编译为Outer$Inner.class。
第二种是匿名类(Anonymous class),直接在方法内部定义某个内部类,比较常见的场景是开启线程:
public class Main {public static void main(String[] args) {Outer outer = new Outer("Nested");outer.asyncHello();}}class Outer {private String name;Outer(String name) {this.name = name;}void asyncHello() {Runnable r = new Runnable() {// 匿名类可以实现接口、也可以继承普通类// 就在{}中定义相关操作即可@Overridepublic void run() {System.out.println("Hello, " + Outer.this.name);}};new Thread(r).start();}}
相比于第一种内部类,匿名类的写法很简单,节省了很多的代码。
观察Java编译器编译后的.class文件可以发现,Outer类被编译为Outer.class,而匿名类被编译为Outer$1.class。如果有多个匿名类,Java编译器会将每个匿名类依次命名为Outer$1、Outer$2、Outer$3……
第三种是静态内部类(static nested class),它和inner class很像——可以访问其包裹类的private属性和方法。但是,它无法引用Outer.this。
可以这样理解,它是一个静态的东西,和静态方法静态属性一样,是类独有的,不依附于某个对象。
classpath和jar
简单来说,classpath就是JVM所使用的一组环境变量,一般是一个文件路径,JVM在执行程序的时候会去classpath中搜索并加载对应的.class。
有两种方式添加classpath,一种是在计算机的系统环境变量中加入,但是会污染环境,不推荐;
第二种是在启动程序的时候传入,如:
java -classpath .\;C:\java\bin; whitedew.javalearning.hi或,简写java -cp .\;C:\java\bin; whitedew.javalearning.hi默认的classpath是 .\,即当前目录
为了便于管理和传递.class文件,可以将其根据package的层级进行打包成jar文件(其实就是压缩成zip之后修改后缀为jar)。
注意,jar包还可以包含一个特殊的/META-INF/MANIFEST.MF文件,MANIFEST.MF是纯文本,可以指定Main-Class和其它信息。 JVM会自动读取这个MANIFEST.MF文件,如果存在Main-Class,我们就不必在命令行指定启动的类名,而是用更方便的命令:
java -jar hello.jarjar包还可以包含其它jar包,这个时候,就需要在MANIFEST.MF文件里配置classpath了。 在大型项目中,不可能手动编写MANIFEST.MF文件,再手动创建zip包。常用的Maven,可以非常方便地创建jar包。
线程安全与并发
什么是线程安全?《Java并发编程实践》中对线程安全的定义:
当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象就是线程安全的。 又或者: 如果一段代码可以保证多个线程访问的时候正确操作共享数据,那么它是线程安全的
简单来说,就是保证多线程环境下共享的、可修改的数据的正确性。
换个角度来看,如果状态不是共享的,或者不是可修改的,也就不存在线程安全问题。
线程安全有三个基本特性:原子性、可见性与有序性。
原子性是指当某一个线程在进行操作时,其他线程不能从中打断、介入;
可见性是指当某一线程进行修改后,其他线程对这个修改可见;
有序性是指,保证代码的顺序执行,主要是防止CPU进行指令重排。
synchronized
Synchronized是由JVM实现的一种实现互斥同步的一种方式,synchronized 代码块是由一对 monitorenter/monitorexit 指令实现的,Monitor 对象是同步的基本实现单元。
在虛拟机执行到monitorenter指令时,首先要尝试获取对象的锁:如果这个对象没有锁定,或者当前线程已经拥有了这个对象的锁,把锁的计数器+1;当执行 monitorexit指令时将锁计数器-1;当计数器为O时,锁就被释放了。
如果获取对象失败了,那当前线程就要阻塞等待,直到对象锁被另外一个线程释放为止。
Java中Synchronize通过在对象头设置标记(Mark Word),达到了获取锁和释放锁的目的。
使用Synchronized可以修饰不同的对象,因此,对应的对象锁可以这么确定。
1. 如果Synchronized明确指定了锁对象,比如Synchronized(变量名)、Synchronized(this)等,说明加解锁对象为该对象。
2. 如果没有明确指定:
若Synchronized修饰的方法为非静态方法,表示此方法对应的对象为锁对象;
若Synchronized修饰的方法为静态方法,则表示此方法对应的类对象为锁对象;
若Sybchronized修饰的为部分代码块,则其仅锁定该代码块而已,对对象和类对象无影响;(Hashtable与concurrentHashMap的实现差别)
注意,当一个对象被锁住时,对象里面所有用Synchronized修饰的方法都将产生堵塞,而对象里非Synchronized修饰的方法可正常被调用,不受锁影响。
在 Java 6 之前,Monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。
锁的升级
现代的(Oracle)JDK 中,JVM 对此进行了大刀阔斧地改进,提供了三种不同的 Monitor 实现,也就是常说的三种不同的锁:偏斜锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。
所谓锁的升级、降级,就是 JVM 优化 synchronized 运行的机制,当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
当没有竞争出现时,默认会使用偏斜锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。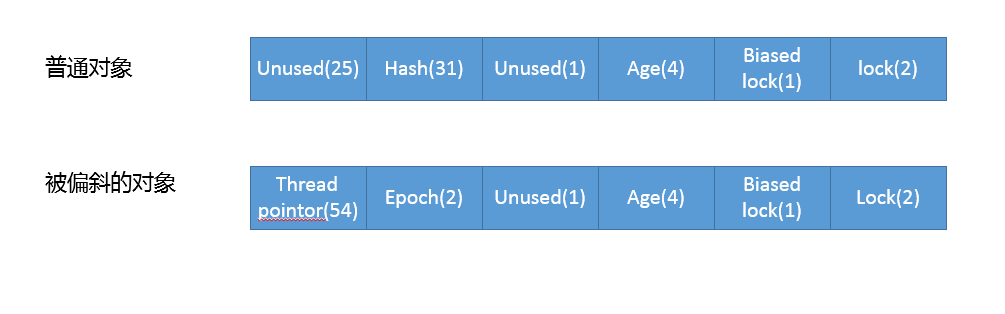
对象头更进一步的讲解: https://www.cnblogs.com/tiancai/p/12630305.html https://www.jb51.net/article/197704.htm
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏斜锁,并切换到轻量级锁实现。
轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
Maven
简介
看看廖老师网站上说的:
我们先来看看一个Java项目需要的东西。
首先,我们需要确定引入哪些依赖包。 例如,如果我们需要用到commons logging,我们就必须把commons logging的jar包放入classpath。如果我们还需要log4j,就需要把log4j相关的jar包都放到classpath中。这些就是依赖包的管理。
其次,我们要确定项目的目录结构。 例如,src目录存放Java源码,resources目录存放配置文件,bin目录存放编译生成的.class文件。
此外,我们还需要配置环境,例如JDK的版本,编译打包的流程,当前代码的版本号。
最后,除了使用Eclipse这样的IDE进行编译外,我们还必须能通过命令行工具进行编译,才能够让项目在一个独立的服务器上编译、测试、部署。 这些工作难度不大,但是非常琐碎且耗时。如果每一个项目都自己搞一套配置,肯定会一团糟。我们需要的是一个标准化的Java项目管理和构建工具。
Maven就是是专门为Java项目所打造的管理和构建工具,可以说,拥有了Maven之后,项目的开发、发布等流程将会变得异常简便。它的功能主要体现在三个方面:
- 标准化的项目结构;
- 标准化的项目构建流程(编译、测试、打包、发布等)
- 便捷的依赖管理机制
Maven的安装可以直接从Maven官网去下载,而后配置好环境变量即可。如果使用的是IDEA,那么默认使用的bundle Maven,即自带的Maven版本,由于IDEA没有自动设置Maven的环境变量,在Terminal中是无法使用mvn命令的,需要自行设置。
一个maven项目的文件结构如下: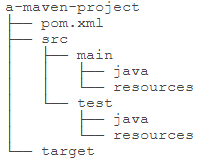
其中,pom.xml是一个项目描述文件,主要是用来唯一标识项目并处理该项目所需要的依赖(即需要下载哪些第三方的库),大致内容类似下面这样:
<project ...><modelVersion>4.0.0</modelVersion><groupId>com.whitedew.learnjava</groupId> //相当于公司名<artifactId>hello</artifactId> //相当于具体的工程项目<version>1.0</version>// 该项目版本<packaging>jar</packaging>// 打包类型<properties> // 其他属性...</properties><dependencies>//管理所有的依赖<dependency>// 第一个依赖<groupId>commons-logging</groupId><artifactId>commons-logging</artifactId><version>1.2</version></dependency></dependencies></project>
依赖关系
maven是如何处理项目的依赖关系的?
——当项目中所使用的的依赖包又依赖于其他依赖时,maven会自动导入相关的依赖包。
最典型的例子就是如果我们导入springboot-boot-starter-web依赖,那么maven会自动导入二十几种相关依赖。如果人工去解决,不仅繁琐,而且极易出错。
maven定义了四种依赖关系compile(编译时需要,默认关系)、test(Test时需要)、provided(编译时需要,运行时由其他提供)、runtime(运行时需要)。如test依赖:
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.3.2</version><scope>test</scope></dependency>
如果访问maven中心仓库较慢,可以使用镜像仓库,百度即可; 另外,如果不知某个依赖应该如何下载,可以进入https://search.maven.org/进行搜索;
Lifecycle/Phase/Goal
使用IDEA并用maven构建项目时,一般在右侧有一个maven按钮可以点击,内容如下: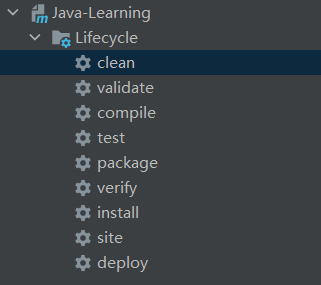
其实maven真正的lifecycle(生命周期)只有三种:
- default,项目构建的核心部分,包括编译、测试、打包等;
- clean,项目构建前的清理工作,如清理之前生成的.class或.jar包之类的;
- site,主要是生成项目报告;
而每一个生命周期又分为多个phase(阶段)。
例如clean分为三个phase:
pre-clean 执行一些需要在clean之前完成的工作
clean 移除所有上一次构建生成的文件
post-clean 执行一些需要在clean之后立刻完成的工作
site也分为三个phase:
pre-site 执行一些需要在生成站点文档之前完成的工作
site 生成项目的站点文档 post-site 执行一些需要在生成站点文档之后完成的工作,并且为部署做准备
site-deploy 将生成的站点文档部署到特定的服务器上
default生命周期的phase就多了: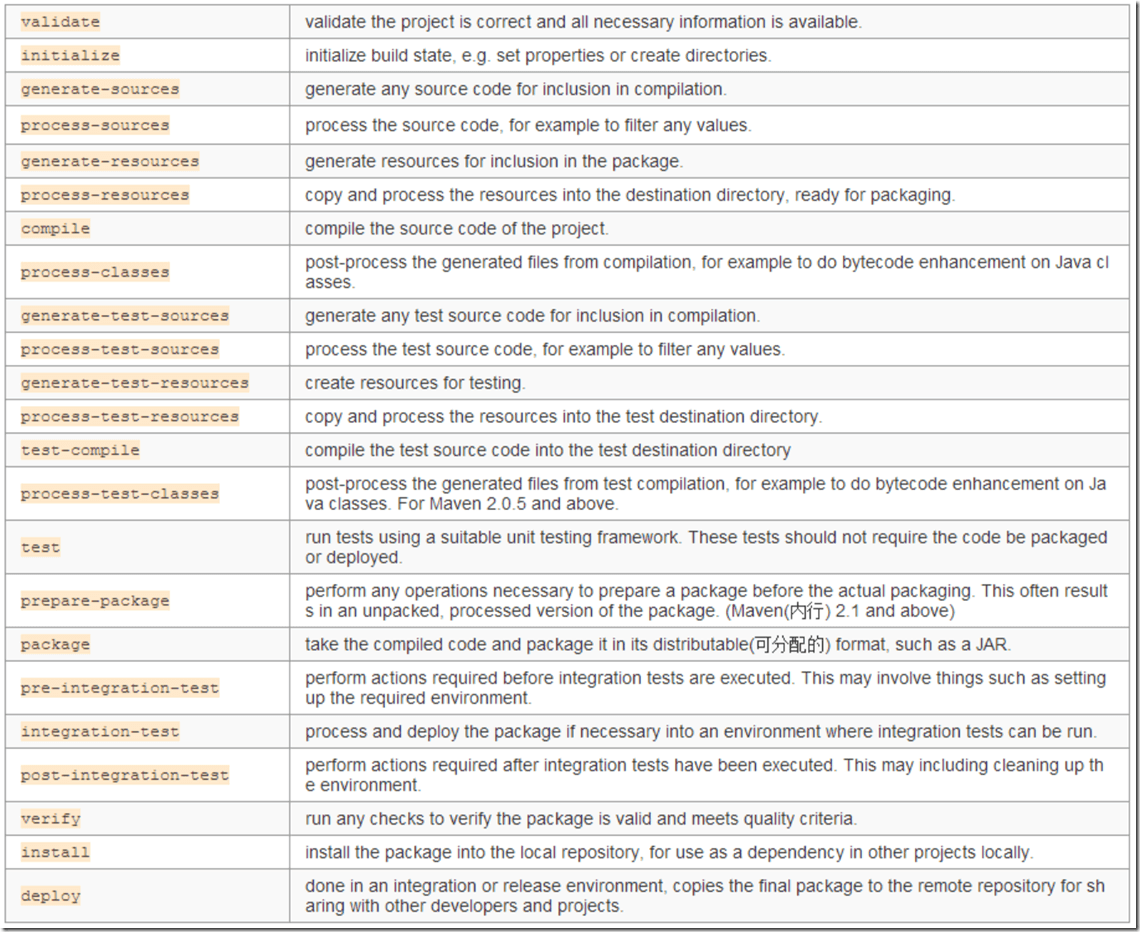
其中主要的phase有:
validate(验证工程信息是否正确完整)、initialize(初始化工程目录)、compile(编译源代码)、test(执行单元测试)、package(将工程打包为指定格式如jar、war)、verify(检查package是否标准)、install(将项目安装至本地仓库以便于其他项目可以使用)、deploy(将包复制到远程仓库以便于共享)。
解释一下Maven中所说的中央仓库、私有仓库、本地仓库。 中央仓库,其实我们使用的大多数第三方模块都是这个用法,例如,我们使用commons logging、log4j这些第三方模块,就是第三方模块的开发者自己把编译好的jar包发布到Maven的中央仓库中。
私有仓库,是指公司内部如果不希望把源码和jar包放到公网上,那么可以搭建私有仓库。
本地仓库,是指把本地开发的项目“发布”在本地,这样其他项目可以通过本地仓库引用它。但是我们不推荐把自己的模块安装到Maven的本地仓库,因为每次修改某个模块的源码,都需要重新安装,非常容易出现版本不一致的情况。更好的方法是使用模块化编译,在编译的时候,告诉Maven几个模块之间存在依赖关系,需要一块编译,Maven就会自动按依赖顺序编译这些模块。
IDEA显示的其实严格来说并不是lifecycle,而是lifecycle中的phase,表示用户需要进行到哪一个阶段(phase)。如常用的命令:
mvn clean 清理mvn clean compile 清理并编译mvn clean test 清理并测试mvn clean package 清理并打包
这些phase的执行都是由对应的插件来进行的。goal是phase的具体执行方法,每一个phase可能有多个goal,看下面的例子: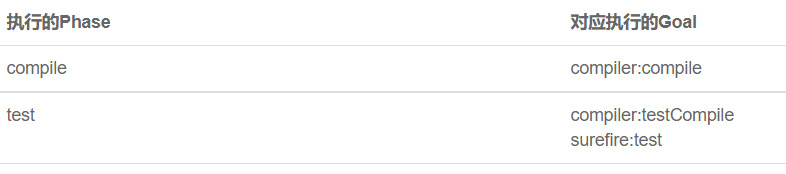
分割子项目
当工程项目过大时,为了便于管理或者分配给不同的程序员进行开发,有必要将整个项目分割为多个不同的子项目或称为模块(module)。
注,这里所说的模块与jdk9所引入的模块并不是一个概念
比如一个项目被分为了三个子项目,那么每一个子项目都拥有其独立的pom.xml以及src文件夹。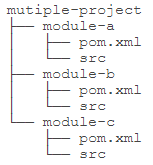
并且,如果某些子项目之间存在相同的依赖,那么可以将这部分依赖单独提取出来作为parent。如下:
其中parent目录下的pom.xml就是子项目的公有配置,而后子项目只需要包含parent的pom.xml即可,简化了重复的配置。
值得注意的是最外面的pom.xml是整个项目的配置文件,其中注明来需要编译的子项目。
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>groupId</groupId><artifactId>Java-Learning</artifactId><version>1.0-SNAPSHOT</version><packaging>pom</packaging><name>build</name><modules><module>parent</module><module>module-a</module><module>module-b</module><module>module-c</module></modules></project>
有关这部分的详情,可参考:链接。 拓展阅读:如何将自己所写的库文件让别人可以引用?
jdk各版本特性
大致了解jdk各个迭代版本之间的区别:
- jdk1.8的新特性:
Lambda 表达式 − Lambda 允许把函数作为一个方法的参数(函数作为参数传递到方法中)。
方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
Date Time API − 加强对日期与时间的处理。
Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
- jdk1.9的新特性
模块系统:模块是一个包的容器,Java 9 最大的变化之一是引入了模块系统。
简单来说模块系统是为了管理各个包之间依赖;从而当程序发布的时候可以按需打包JRE,减小发布体积;另外,使用模块对类的访问权限有了进一步限制。
有关模块系统的详细介绍:链接
HTTP 2 客户端:HTTP/2标准是HTTP协议的最新版本,新的 HTTPClient API 支持 WebSocket 和 HTTP2 流以及服务器推送特性。
改进的 Javadoc:Javadoc 现在支持在 API 文档中的进行搜索。另外,Javadoc 的输出现在符合兼容 HTML5 标准。
集合工厂方法:List,Set 和 Map 接口中,新的静态工厂方法可以创建这些集合的不可变实例。
私有接口方法:在接口中使用private私有方法。我们可以使用 private 访问修饰符在接口中编写私有方法。
改进的 Stream API:改进的 Stream API 添加了一些便利的方法,使流处理更容易,并使用收集器编写复杂的查询。
改进钻石操作符(Diamond Operator) :匿名类可以使用钻石操作符(Diamond Operator)。
改进 Optional 类:java.util.Optional 添加了很多新的有用方法,Optional 可以直接转为 stream。
响应式流(Reactive Streams) API: Java 9中引入了新的响应式流 API 来支持 Java 9 中的响应式编程。
- jdk10新特性
局部变量类型推断:有点类似于C++的auto;
垃圾回收接口:相当于给其他的垃圾回收器快速方便集成的接口;
线程局部管控;
移除Native-Header Generation Tool (javah);
Unicode 标签扩展;
备用内存设备上分配堆内存;
基于实验JAVA 的JIT 编译器;
Root 证书;
基于时间的版本控制;
详情可见:链接
- jdk11新特性
jdk11是一个LTS版本,即长时间支持的java版本。由于该版本的新特性较多,建议直接参考:链接。
参考资料

若有收获,就点个赞吧
0 人点赞
