总览
浏览器原理
总览
浏览器将URL展示在界面上,主要由以下几个过程,如图: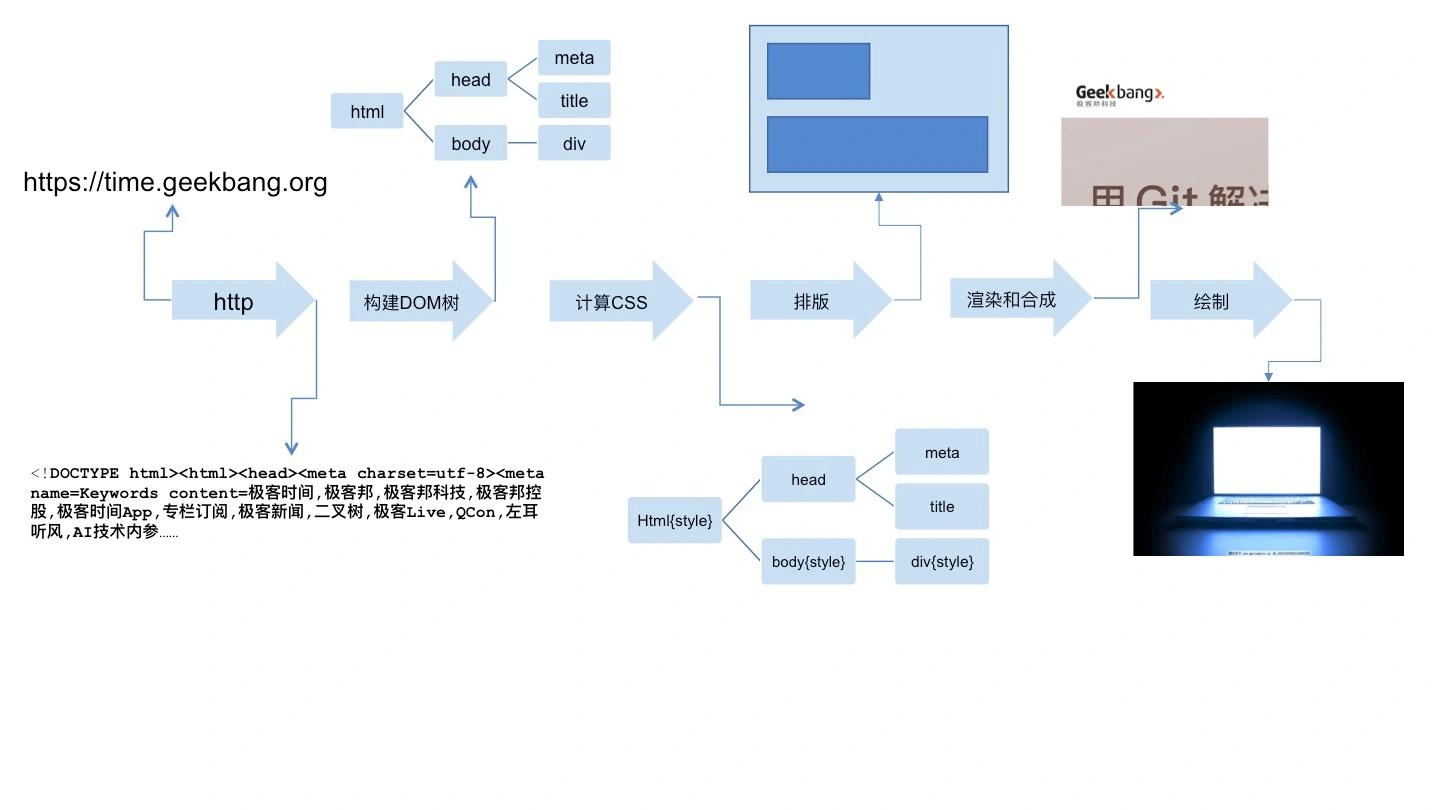
1、浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面;
2、把请求回来的 HTML 代码经过解析,构建成 DOM 树;
3、计算 DOM 树上的 CSS 属性;
4、最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图;
5、一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度;
6、合成之后,再绘制到界面上。
注意,上述过程会尽量保持流水线进行,后续步骤不一定非要等到前者完成才进行。
构建DOM树:状态机
当浏览器接收到服务器发送过来的字符流时,会根据已接收到的字符流进行词法分析,最终构建出DOM树: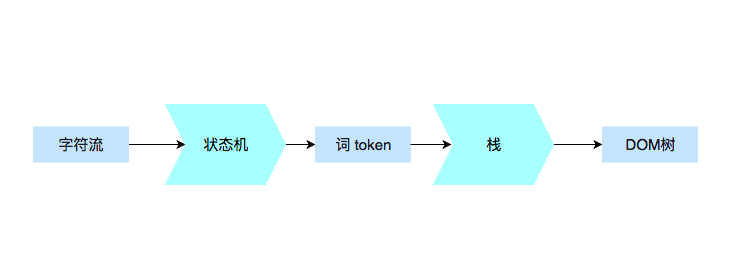
所谓的词token,是指在编译原理中的专业术语,表示最小的有意义单元,以下面的这个ResponseBody内容为例:
<p class="a">text text text</p>
可以把这段代码依次拆成词(token):
> “标签开始”的结束;
text text text 文本;
标签结束。
当只读取一个字符时,浏览器无法准确判断当前的状态,但是随着读取越来越多的字符,当前文本内容的属性愈发明显,整个过程其实是一个有限状态机。
一个js实现的词法parser:https://github.com/aimergenge/toy-html-parser
HTML/CSS
未定

若有收获,就点个赞吧
0 人点赞
