Java异常处理
https://www.liaoxuefeng.com/wiki/1252599548343744/1264738442933472
当程序出现错误时,上层调用方需要知道是否发生了错误或发生了什么错误,一种方法可以通过约定返回值来实现,另一方法是提供一种异常处理机制:Java内置了一套异常处理机制,总是使用异常来表示错误。
Java中的异常是一个class,它的继承关系如下: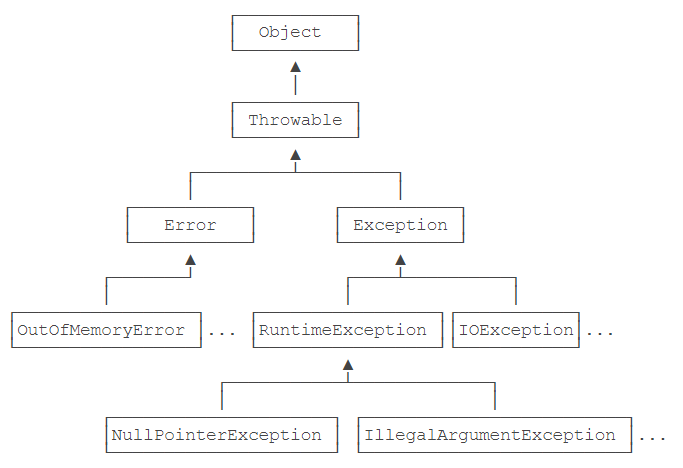
Java规定:
- 必须捕获的异常,包括Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。但是什么是不是应该捕获,需要根据实际业务场景来决定,前面的只是对编译器的要求。
- 不需要捕获的异常,包括Error及其子类,RuntimeException及其子类。
捕获到异常并再次抛出时,一定要留住原始异常,否则很难定位第一案发现场!
因此,即便在上层进行异常转型时,也需要将下层的异常作为参数传递上去,比如:
static void process1() {try {process2();} catch (NullPointerException e) {throw new IllegalArgumentException(e);//重点,把e放进去!}}static void process2() {throw new NullPointerException();}
常见注解
restcontorller
respondbody
requestmapping
Slf4j
configurationEnableTransationManagement
AutoWired
@Entity
@RunWith
@SpringBootTest(classes = AutoconfigurationApplication.class)
Component、Repository、Service、Controlller(RestController) 主要是使用场景的区别,第一个是通用,第二个是数据操作(增删改查)
Logging
JDK Logging:
// loggingimport java.util.logging.Level;import java.util.logging.Logger;public class Hello {public static void main(String[] args) {Logger logger = Logger.getGlobal();logger.info("start process...");logger.warning("memory is running out...");logger.fine("ignored.");logger.severe("process will be terminated...");}}
日志的输出可以设定级别。JDK的Logging定义了7个日志级别,从严重到普通:
- SEVERE
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST
因为默认级别是INFO,因此,INFO级别以下的日志,不会被打印出来。使用日志级别的好处在于,调整级别,就可以屏蔽掉很多调试相关的日志输出。
使用Java标准库内置的Logging有以下局限:
Logging系统在JVM启动时读取配置文件并完成初始化,一旦开始运行main()方法,就无法修改配置;
配置不太方便,需要在JVM启动时传递参数-Djava.util.logging.config.file=
因此,Java标准库内置的Logging使用并不是非常广泛。更方便的日志系统我们稍后介绍。
Commons Logging:
Commons Logging是一个第三方日志库,它是由Apache创建的日志模块。
Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。默认情况下,Commons Loggin自动搜索并使用Log4j(Log4j是另一个流行的日志系统),如果没有找到Log4j,再使用JDK Logging。
使用Commons Logging只需要和两个类打交道,并且只有两步:
第一步,通过LogFactory获取Log类的实例; 第二步,使用Log实例的方法打日志。
import org.apache.commons.logging.Log;import org.apache.commons.logging.LogFactory;public class Main {public static void main(String[] args) {Log log = LogFactory.getLog(Main.class);log.info("start...");log.warn("end.");}}
Commons Logging定义了6个日志级别:
- FATAL
- ERROR
- WARNING
- INFO
- DEBUG
- TRACE
默认级别是INFO。
Log4j:
Log4j是一个组件化设计的日志系统,它的架构大致如下: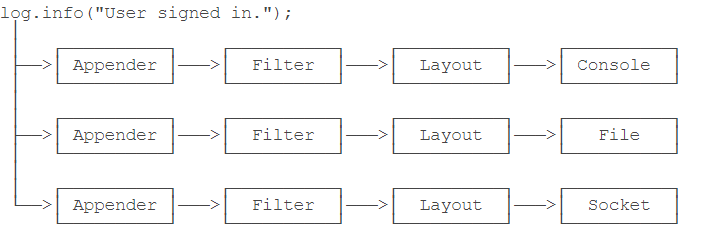
当我们使用Log4j输出一条日志时,Log4j自动通过不同的Appender把同一条日志输出到不同的目的地。例如:
- console:输出到屏幕;
- file:输出到文件;
- socket:通过网络输出到远程计算机;
- jdbc:输出到数据库
Slf4j和Logback:
SLF4J类似于Commons Logging,也是一个日志接口,而Logback类似于Log4j,是一个日志的实现。
Spring Boot
什么是Spring Boot?

有什么特性?
四大核心:
官方文档:https://docs.spring.io/spring-boot/docs/2.6.7/reference/pdf/spring-boot-reference.pdf
SpringBoot自动配置
参考:https://blog.csdn.net/peterwanghao/article/details/87875936

@SpringBootApplication这个注解(查看源码即可发现)其实是一个应用了3个注解的快捷方式:@SpringBootConfiguration:它表示该类是一个配置类,应该对其进行扫描,以获得进一步的配置和bean定义,其实和Configuration一样的。
@EnableAutoConfiguration:此注解用于启用Spring Application Context的自动配置,尝试猜测和配置您可能需要的bean。自动配置类通常基于您的类路径以及您定义的bean来应用。
@ComponentScan:无论是basePackageClasses()或basePackages()可以定义特定的软件包进行扫描。如果未定义特定包,则将从声明此注解的类的包进行扫描。
要创建自定义自动配置,我们需要创建一个注释为@Configuration的类并注册它。
让我们为MySQL数据源创建自定义配置:
@Configurationpublic class MySQLAutoconfiguration {//...}
下一个必须的步骤是通过在标准文件资源/ META-INF / spring.factories中的属性,org.springframework.boot.autoconfigure.EnableAutoConfiguration下添加类的名称,将类注册为自动配置候选者:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.peterwanghao.samples.springboot.autoconfiguration.MySQLAutoconfiguration
如果我们希望我们的自动配置类优先于其他自动配置候选者,我们可以添加@AutoConfigureOrder(Ordered.HIGHEST_PRECEDENCE)注解。
自动配置是使用标有@Conditional注解的类和bean设计的,以便可以替换自动配置或其特定部分。
请注意,只有当应用程序中未定义自动配置的bean时,自动配置才有效。如果您定义了bean,那么将覆盖默认值。
之后可以根据不同的条件来进行自定义配置的激活,主要分为以下六种:
基于类的条件:@ConditionalOnClass(DataSource.class),即只有当类路径中存在DataSource时,才会加载配置类;
基于Bean的条件:@ConditionalOnBean(name=”dataSource”)存在某个Bean才加载,@ConditionalOnMissingBean,当不存某个Bean时才进行加载和配置;
基于属性的条件:@ConditionalOnProperty;
基于资源的条件:@ConditionalOnResource;
自定义条件:如果我们不想使用Spring Boot中的任何可用条件,我们还可以通过扩展SpringBootCondition类并重写getMatchOutcome()方法来定义自定义条件。
申请条件:可以通过添加@ConditionalOnWebApplication或@ConditionalOnNotWebApplication注释来指定只能在Web上下文内部/外部加载配置。
想要从加载中排除自动配置,我们可以将带有exclude或excludeName属性的@EnableAutoConfiguration注解添加到配置类:
@Configuration@EnableAutoConfiguration(exclude={MySQLAutoconfiguration.class})public class AutoconfigurationApplication {//...}
或者:
spring.autoconfigure.exclude=com.peterwanghao.samples.springboot.autoconfiguration.MySQLAutoconfiguration
起步依赖(starter dependency)是什么?
最开始使用Maven构建项目时:
而Spring Boot提供的起步依赖:
如何将Spring Boot应用打包成Docker镜像?
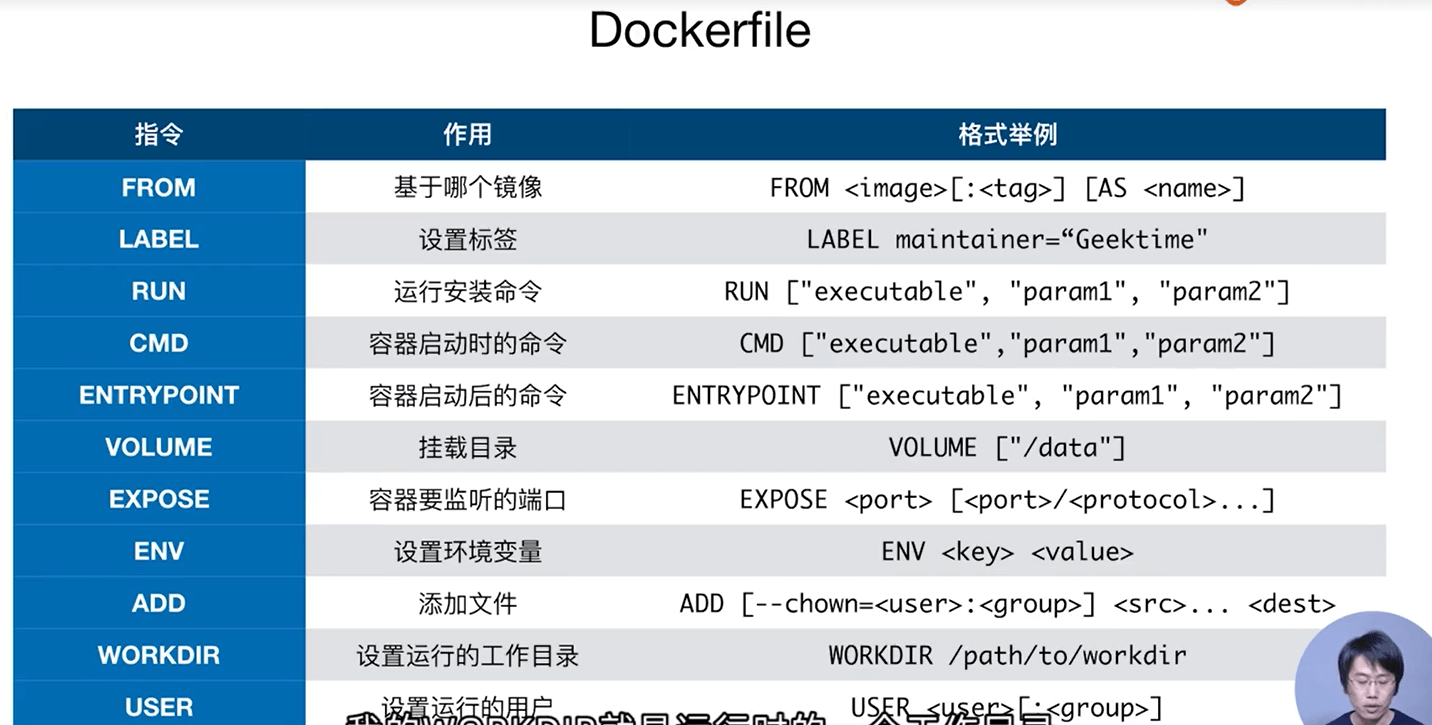
将Spring Boot的应用打包成Docker镜像需要借助一个第三方包:dockerfile-maven-plugin,生成的Dockerfile如下: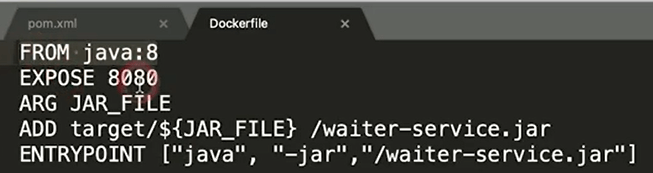
Lombok插件
提供了一些bean常用的注解,方便开发者减少重复性的工作,如添加相应的构造方法,getter/setter,toString(),equals() and hashcode()等方法。
提供的注解如下:链接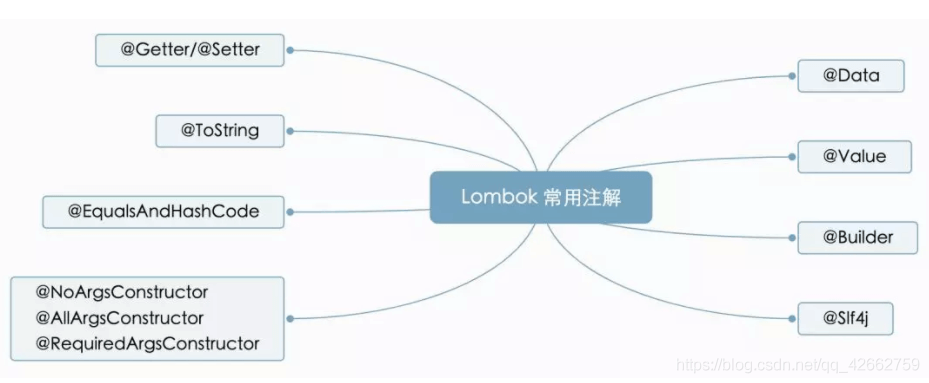
补充一下,
@NonNull //用在类的属性上,限定属性不能为空,否则抛出空指针异常 组合注解
@Data = @Getter + @Setter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor
@Value = @Getter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor
Lombok支持JDK的Log,以及第三 方的Log4j,Slf4j,LogBack等多种日志框架 Lombok会在类中自动添加定义日志变量log的代码,后续代码中可以直接使用log变量。
JDBC简介
https://www.liaoxuefeng.com/wiki/1252599548343744/1305152088703009
什么是JDBC?JDBC是Java DataBase Connectivity的缩写,它是Java程序访问数据库的标准接口。
使用Java程序访问数据库时,Java代码并不是直接通过TCP连接去访问数据库,而是通过JDBC接口来访问,而JDBC接口则通过JDBC驱动来实现真正对数据库的访问。
例如,我们在Java代码中如果要访问MySQL,那么必须编写代码操作JDBC接口。注意到JDBC接口是Java标准库自带的,所以可以直接编译。而具体的JDBC驱动是由数据库厂商提供的,例如,MySQL的JDBC驱动由Oracle提供。因此,访问某个具体的数据库,我们只需要引入该厂商提供的JDBC驱动,就可以通过JDBC接口来访问,这样保证了Java程序编写的是一套数据库访问代码,却可以访问各种不同的数据库,因为他们都提供了标准的JDBC驱动: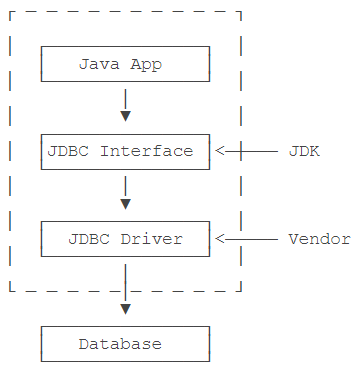
从代码来看,Java标准库自带的JDBC接口其实就是定义了一组接口,而某个具体的JDBC驱动其实就是实现了这些接口的类。
AOP与事务
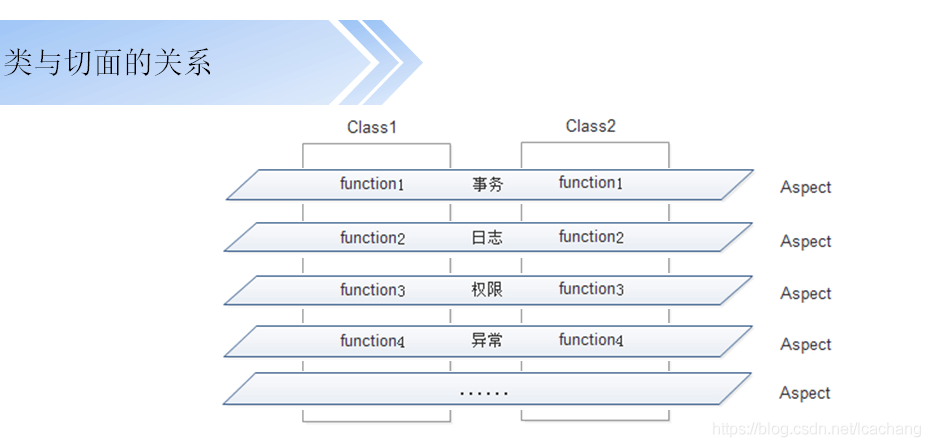
AOP术语: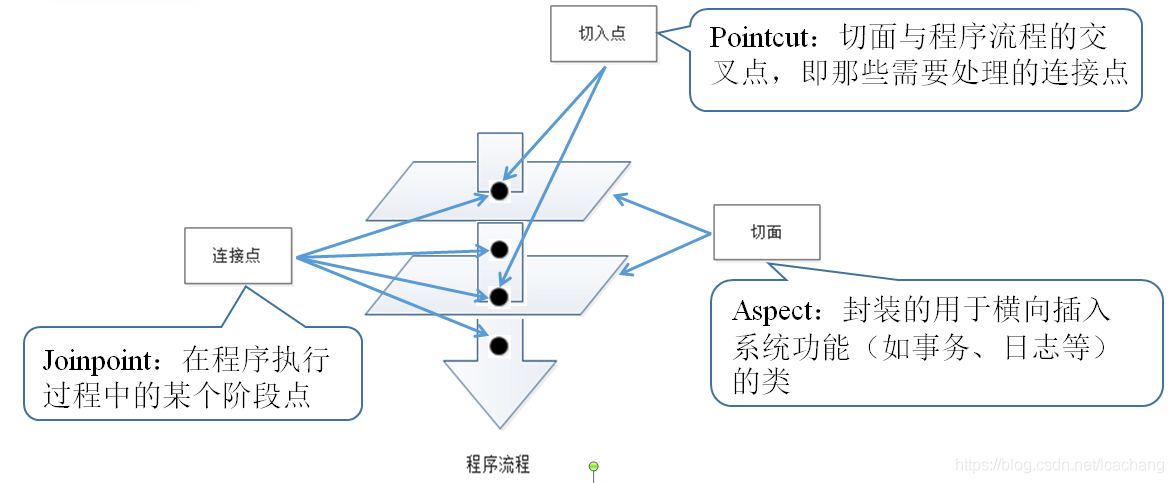
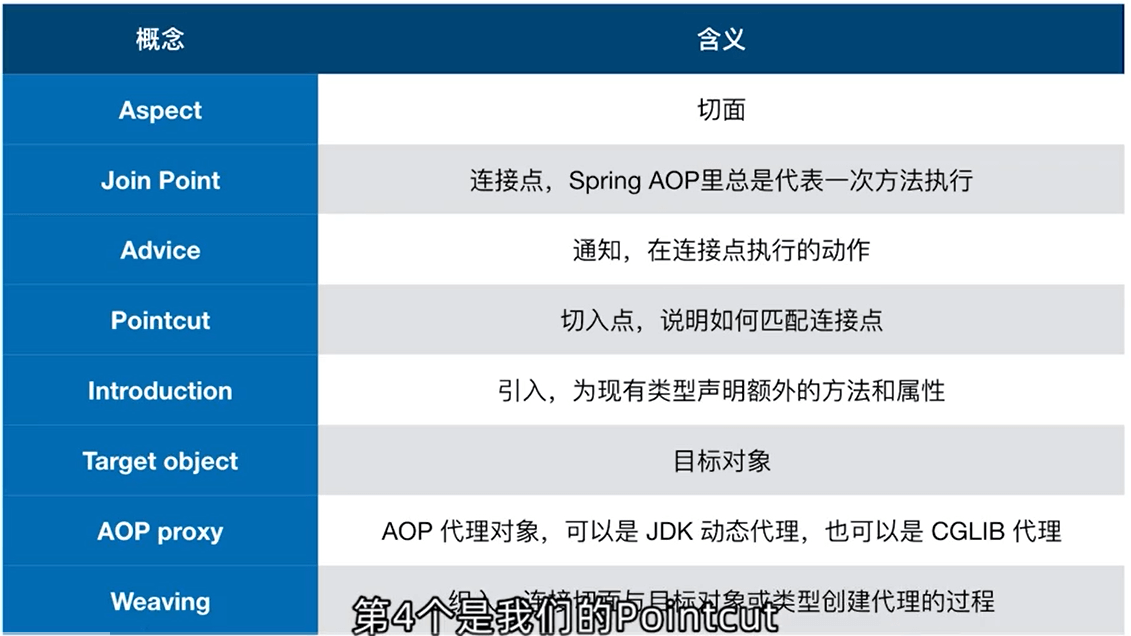
AOP中的代理说是由AOP框架动态生成的一个对象,该对象可以作为目标对象使用。Spring 中的AOP有两种,JDK动态代理,CGLIB代理。
JDK动态代理是通过java.lang.reflect.Proxy 类来实现的,我们可以调用Proxy类的newProxyInstance()方法来创建代理对象。对于使用业务接口的类,Spring默认会使用JDK动态代理来实现AOP。
JDK的动态代理用起来非常简单,但它是有局限性的,使用动态代理的对象必须实现一个或多个接口(如UserDaoImpl实现了UserDao接口)。 如果想代理没有实现接口的类,那么可以使用CGLIB代理。简单来说,它采用非常底层的字节码技术,对指定的目标类生成一个子类,并对子类进行增强。
看一个实际的测试代码:
public class CglibTest {public static void main(String[] args){//创建代理类对象CglibProxy cglibProxy=new CglibProxy();//创建目标对象UserDao userDao=new UserDao();//获取增强后的目标对象UserDao userDao1=(UserDao) cglibProxy.createProxy(userDao);//执行方法userDao1.addUser();userDao1.deleteUser();}}
Spring四种增强方式
前置增强 (org.springframework.aop.BeforeAdvice) 表示在目标方法执行前来实施增强 后置增强 (org.springframework.aop.AfterReturningAdvice) 表示在目标方法执行后来实施增强
环绕增强 (org.aopalliance.intercept.MethodInterceptor) 表示在目标方法执行前后同时实施增强
异常抛出增强 (org.springframework.aop.ThrowsAdvice) 表示在目标方法抛出异常后来实施增强
Spring事务失效的场景
https://baijiahao.baidu.com/s?id=1714667126401049636&wfr=spider&for=pc
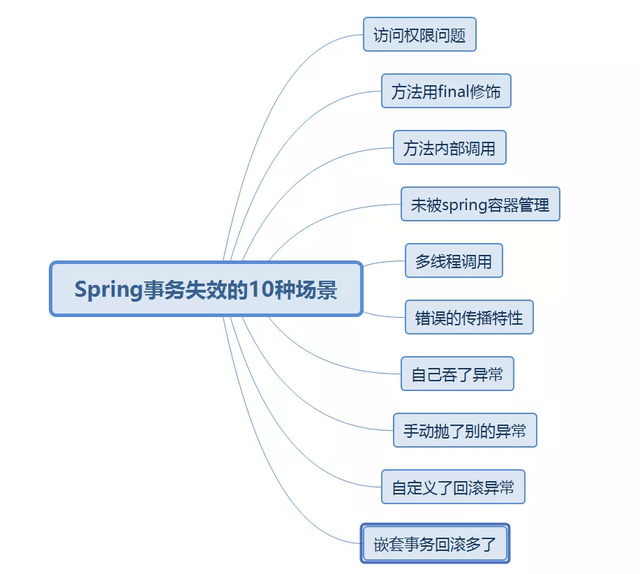
其中,方法内部调用是指,一个方法调用了另一个方法,虽然另一个方法存在事务性,但是由于当前方法没有事务性,造成最终事务没有生效,解决方式可以通过新建Service方法、在service中注入自己(因方法拥有事务的能力是因为spring aop生成代理了对象,但是这种方法直接调用了this对象的方法,所以updateOrder方法不会生成事务)或是通过Aopcontent获取代理对象进行调用!
O/R Mapping与JPA
O是指Object,R是指RDBMS(关系型数据库管理系统)。
O/R Mapping是指进行对象关系映射(Object/Relational Mapping),Object与RDBMS存在不匹配的问题: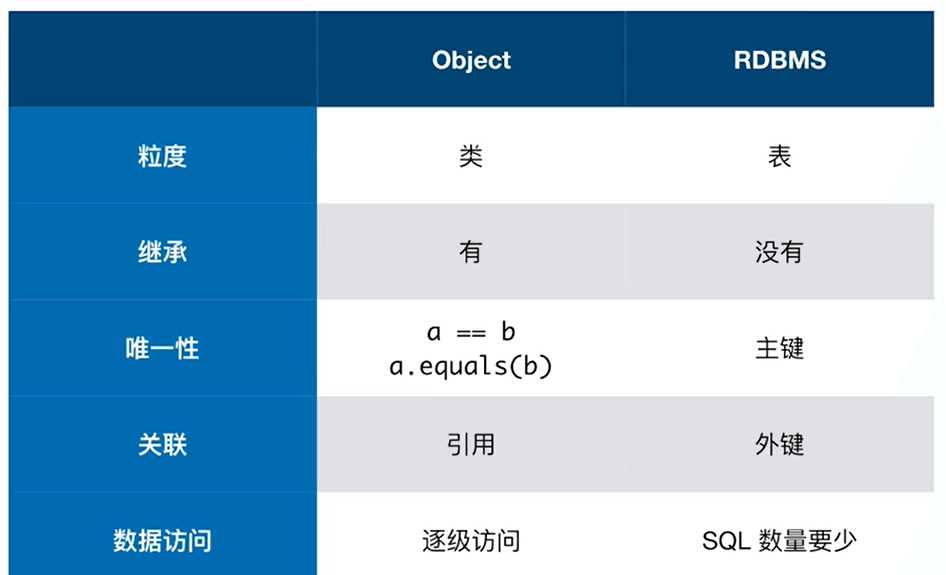
为解决这个问题,减少程序员开发CRUD的时间,Hibernate3.2提出了JPA(Java Persistence API),为对象关系映射提供了以及POJO的持久化模型。
什么是POJO? POJO(Plain Ordinary Java Object)是简单的Java对象,中文可以翻译成:普通Java类,又叫做实体类 entity bean,作用是方便程序员使用数据库中的数据表,对于广大的程序员,可以很方便的将POJO类当做对象来进行使用,具有一部分getter/setter方法的那种类就可以称作POJO,但是JavaBean则比 POJO复杂很多。


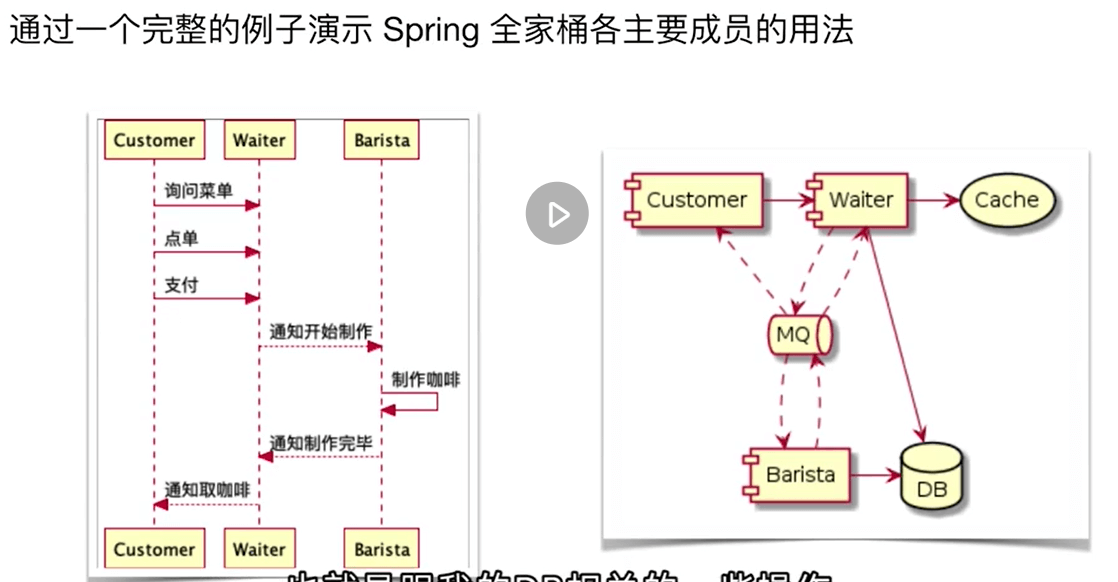
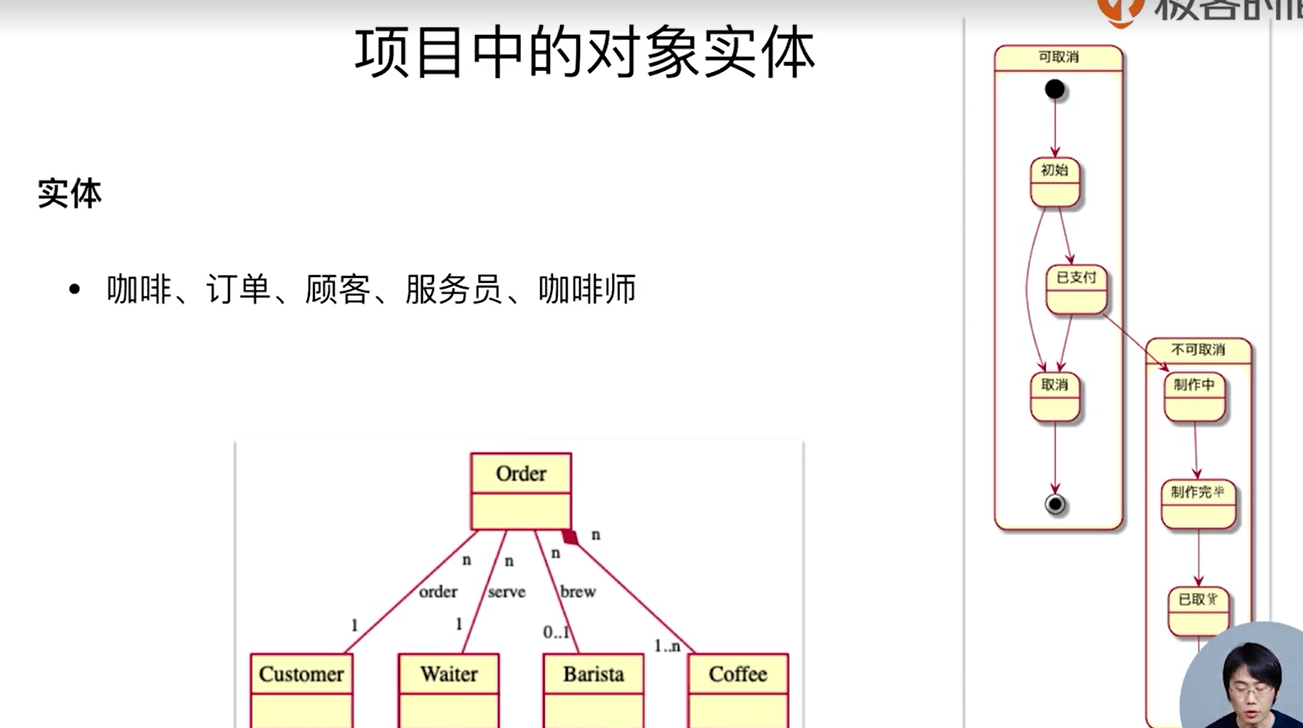
演示项目:线上咖啡点餐


可以创建一个父类来简化: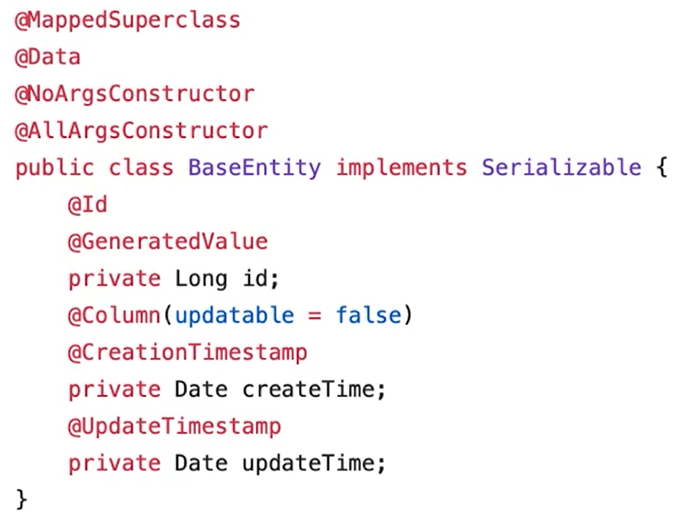
这样的化Coffee实体就可以这样写:
如何保存实体?

这是什么原理?
首先继承了JPA所提供的一个接口:
//Coffee表示对象,Long表示Id的类型public interface CoffeeOrderRepository extends CrudRepositry<Coffee,Long>{}
而这个CrduRepository中提供了一些基本的接口实现(JPA 实现的):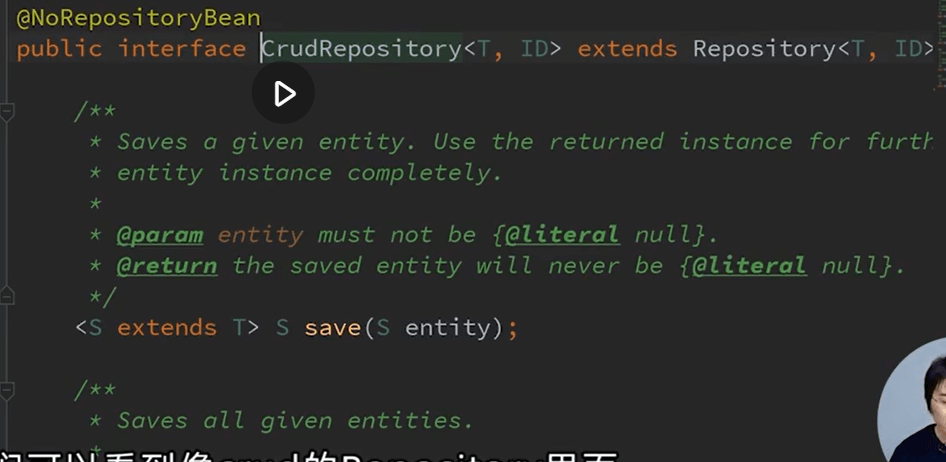
而CrudRepository则是扩展了Repository接口: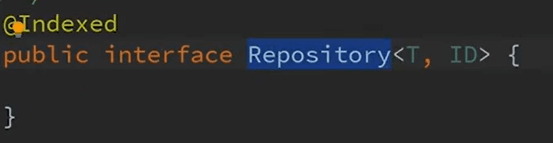
如何查询实体?

Repositry的使用



Repository这个接口是如何变成可以使用的Bean呢?
Repository Bean的创建过程:
查看源码:JPA,Repository/config中,从注解到创建Factory的整个过程,最后通过代理来创建了Repository实现。
那么接口中的方法又是如何解释的?
比如定义的findTop3ByOrderByUpdateTimeDescIdAsc()方法,我并没有自己去进行实现,那么它是如何变成可执行代码的?
简单来说,是做了一个正则匹配(语法解析),源码参见spring data common/repository/query等包中。
JpaRepository支持接口规范方法名查询。意思是如果在接口中定义的查询方法符合它的命名规则,就可以不用写实现,目前支持的关键字如下:
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByNameAndPwd | where name= ? and pwd =? |
| Or | findByNameOrSex | where name= ? or sex=? |
| Is,Equals | findById,findByIdEquals | where id= ? |
| Between | findByIdBetween | where id between ? and ? |
| LessThan | findByIdLessThan | where id < ? |
| LessThanEquals | findByIdLessThanEquals | where id <= ? |
| GreaterThan | findByIdGreaterThan | where id > ? |
| GreaterThanEquals | findByIdGreaterThanEquals | where id > = ? |
| After | findByIdAfter | where id > ? |
| Before | findByIdBefore | where id < ? |
| IsNull | findByNameIsNull | where name is null |
| isNotNull,NotNull | findByNameNotNull | where name is not null |
| Like | findByNameLike | where name like ? |
| NotLike | findByNameNotLike | where name not like ? |
| StartingWith | findByNameStartingWith | where name like ‘?%’ |
| EndingWith | findByNameEndingWith | where name like ‘%?’ |
| Containing | findByNameContaining | where name like ‘%?%’ |
| OrderBy | findByIdOrderByXDesc | where id=? order by x desc |
| Not | findByNameNot | where name <> ? |
| In | findByIdIn(Collection<?> c) | where id in (?) |
| NotIn | findByIdNotIn(Collection<?> c) | where id not in (?) |
| True | findByAaaTue | where aaa = true |
| False | findByAaaFalse | where aaa = false |
| IgnoreCase | findByNameIgnoreCase | where UPPER(name)=UPPER(?) |
| top | findTop10 | top 10/where ROWNUM <=10 |
具体的解析过程参见:(https://www.jb51.net/article/230325.htm),举个例子:
假设创建如下查询findByCategoryId()
框架在解析该方法时,首先剔除findBy(等关键词),然后对剩下的属性进行解析,假设查询实体为Spu
(1) 先判断categoryId(根据POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询(即直接是实体的成员变量);如果没有该属性,继续第二步;
(2) 从右往左截取第一个大写字母开头的字符串此处为Id),然后检查剩下的字符串是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;
如果没有该属性,则重复第二步,继续从右往左截取;最后假设user为查询实体的一个属性;
(3) 接着处理剩下部分(CategoryId),先判断用户所对应的类型是否有categoryId属性,如果有,则表示该方法最终是根据”Spu.categoryId”的取值进行查询;
否则继续按照步骤2的规则从右往左截取。
(4) 可能会存在一种特殊情况,比如Spu包含一个categoryId 的属性,也有一个 rootCategoryId属性,此时会存在混淆。可以明确在属性之间加上”_” 以显式表达意图,比如 “findByRoot_CategoryId()”
为什么在金融领域不使用float/double来表示金额?
简单来说,计算机中的二进制运算结果是近似相等,而不是完全相等,这就造成在小数点很多位之后其实不全为0,这些不为0的数据在多次计算之后会影响最终结果的准确性。
先看下面的代码:
//https://www.jianshu.com/p/2c3dd1fe01fepublic static void main(String[] args){System.out.println(0.2 + 0.1);System.out.println(0.3 - 0.1);System.out.println(0.2 * 0.1);System.out.println(0.3 / 0.1);}
运行结果为:
其实java的float只能用来进行科学计算或工程计算,在大多数的商业计算中,一般采用java.math.BigDecimal类来进行精确计算。
BigDecimal有三种构造方法:
1.public BigDecimal(double val) 将double表示形式转换为BigDecimal 不建议使用这个构造函数
2.public BigDecimal(int val) 将int表示形式转换成BigDecimal
3.public BigDecimal(String val) 将String表示形式转换成BigDecimal
分析详见:
https://www.jianshu.com/p/2c3dd1fe01fe
Hibernate
Hibernate 是一个开源的,对象关系模型框架 (ORM),它对JDBC进行了轻量的封装, 使java程序员可以面对象的方式进行数据库操作。
Hibernate是数据访问层框架,对JDBC进行了封装,是针对数据库访问提出的面向对象的解决方案。使用Hibernate可以直接访问对象,Hibernate自动将此访问转换为SQL执行,从而达到间接访问数据库的目的。
Hibernate 一共有5个核心接口
1.Session
用于连接数据库,相当于 jdbc 中的 Connection (它和 servlet 中 的Session 一点关系也没有),负责执行对象的CRUD操作 ,它是非线程安全的。
2.SessionFactory //用于得到 Session ,相当于jdbc中 DriverManager
3.Transaction //用于事务管理
4.Query 和 Criteria //主要用于查询数据
5.Configuration //用于得到配置信息
Project Reactor
响应式编程与Callback有什么区别呢: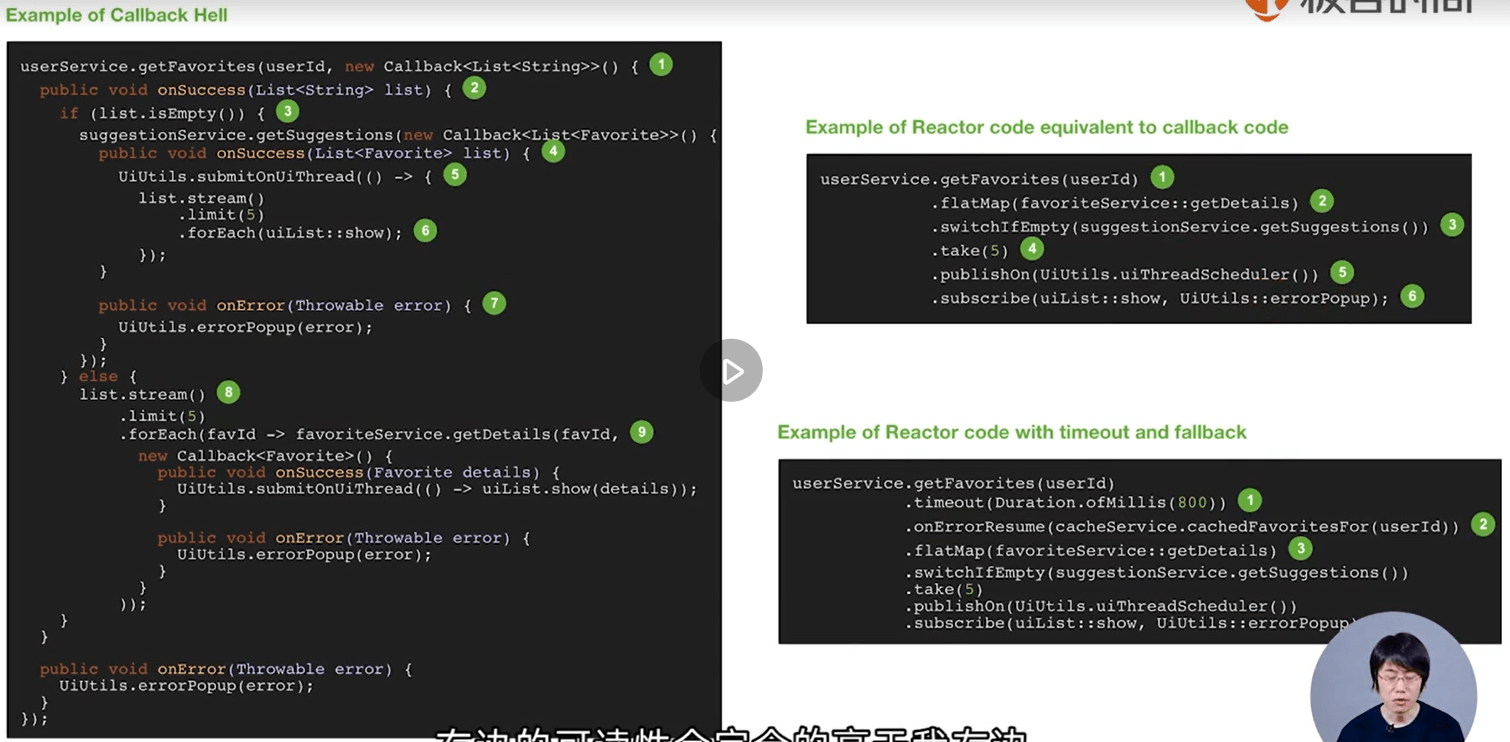
可以看出,Callback的代码虽然可读性较好,但较为冗余,而响应式编程则显得更为简洁。


MyBatis
MyBatis提供另一种操作数据库的方式,通常,如果业务上对数据库的操作比较简单,或是本身SQL比较简单,则可以使用JPA,反之,如果操作比较复杂,或是每一个SQL语句都需要进行安全检查等等,则可以考虑使用Mybatis。
补充:
Mybatis generator方便Mybatis的使用:
还有PageHelper:
还没有写完
Spring Data NoSQL
NoSQl一般针对四种类型的数据库:
1、KV类型,如Redis、Memcache
2、文档类型,如MongoDB、Couchbase
3、列存储,HBase、Cassandra
4、图数据库,Neo4j
Spring Data库有什么用?
Spring Data的目标就是在不失各底层数据库特性的前提下,去增加一个相对统一的封装。
Spring Data MongoDB
以Spring Data MongoDB为例,提供了MogoDBTemplate以及Repository等使用方式。
两者有什么区别?
Template是指提供了一些通用的CRUD接口,后者是指生成排序、查询等Bean,详情可以查看O/R Mapping章节。
MongoDB Template教程:https://www.jianshu.com/p/f47621a224a6
常见注解:
@Document 注明对应的是哪一个文档。
@Id每个文档的唯一id,会进行Autosharding,及自动分片。
类型转换Converter
在进行数据库的存储和读取时,一般都需要进行文档类型与对象类型的转换,即将实际的对象类型转换为底层数据库所支持的数据类型,一般有两种方式:
第三方库与TypeHandler。
如下是一个MongoDB文档到Money对象的转换代码: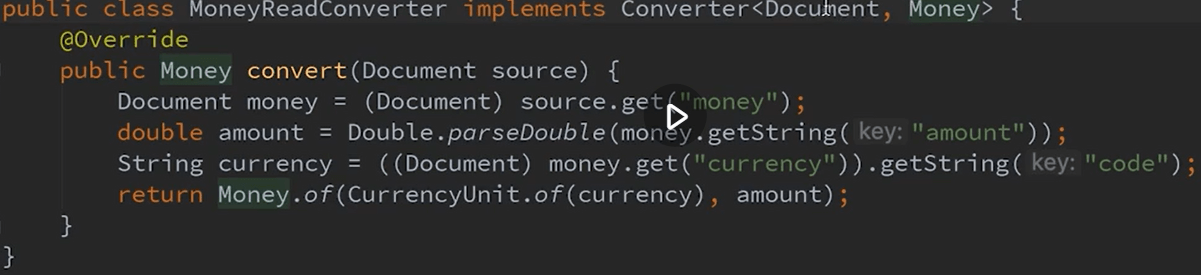
那如何从Money对象转换为文档呢? 在对象进行序列化时,Money对象会自动转换为bson格式(MongoDB的存储格式),这是由Spring Data MongoDB提供的。
在实际使用中,需要定义这样一个Bean:
这是从Spring Boot自动配置的源码中找到的,如果不定义这一个Bean,那么Spring Boot会默认配置一个空的自定义转换Bean。
Spring Data Redis

Spring 缓存抽象


参考资料
异步编程与同步编程
同步编程:传统的编程方式一般都是同步编程,即调用某一个方法,等待其响应返回,因此,一个进程在同一个时刻只能进行一个任务,只有这个任务完成了程序才能进行往下走。
异步编程:当一个异步过程调用发出后,调用者不能立刻得到结果。基于事件机制,实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。比如,你现在要有一批数据要大数据要入库,你又不想一边入库一边等待返回结果,你可以用异步,将大数据推入一个队列,然后另外一个线程来操作这个队列里面的数据入库,入完了,就通知一下主线程。这段时间你的主线程可以做任何事。——百度百科
Spring Boot Actuator监控程序健康状态
https://www.jianshu.com/p/c6d172577c3d Spring Boot使用“习惯优于配置的理念”,采用包扫描和自动化配置的机制来加载依赖jar中的Spring bean,不需要任何Xml配置,就可以实现Spring的所有配置。虽然这样做能让我们的代码变得非常简洁,但是整个应用的实例创建和依赖关系等信息都被离散到了各个配置类的注解上,这使得我们分析整个应用中资源和实例的各种关系变得非常的困难。 Actuator是Spring Boot提供的对应用系统的自省和监控的集成功能,可以查看应用配置的详细信息,例如自动化配置信息、创建的Spring beans以及一些环境属性等。
Actuator监控分成两类:原生端点和用户自定义端点;自定义端点主要是指扩展性,用户可以根据自己的实际应用,定义一些比较关心的指标,在运行期进行监控。
原生端点是在应用程序里提供众多 Web 接口,通过它们了解应用程序运行时的内部状况。原生端点又可以分成三类:
- 应用配置类:可以查看应用在运行期的静态信息:例如自动配置信息、加载的springbean信息、yml文件配置信息、环境信息、请求映射信息;
- 度量指标类:主要是运行期的动态信息,例如堆栈、请求连、一些健康指标、metrics信息等;
- 操作控制类:主要是指shutdown,用户可以发送一个请求将应用的监控功能关闭。
Actuator 提供了众多接口,具体如下表所示。
| 方法 | 路径 | 描述 |
|---|---|---|
| GET | /conditions | 提供了一份自动配置报告,记录哪些自动配置条件通过了,哪些没通过 |
| GET | /configprops | 描述配置属性(包含默认值)如何注入Bean |
| GET | /beans | 描述应用程序上下文里全部的Bean,以及它们的关系 |
| GET | /heapdump | 获取堆的快照 |
| GET | /threaddump | 获取线程活动的快照 |
| GET | /env | 获取全部环境属性 |
| GET | /env/{name} | 根据名称获取特定的环境属性值 |
| GET | /health | 报告应用程序的健康指标,这些值由HealthIndicator的实现类提供 |
| GET | /info | 获取应用程序的定制信息,这些信息由info打头的属性提供 |
| GET | /mappings | 描述全部的URI路径,以及它们和控制器(包含Actuator端点)的映射关系 |
| GET | /metrics | 报告各种应用程序度量信息,比如内存用量和HTTP请求计数 |
| GET | /metrics/{name} | 报告指定名称的应用程序度量值 |
| POST | /shutdown | 关闭应用程序,要求endpoints.shutdown.enabled设置为true |
| GET | /trace | 提供基本的HTTP请求跟踪信息(时间戳、HTTP头等) |
注意,Actuator默认只暴露了health与info端点,如果想开启所有端点,需要在application.properties配置文件进行配置:
management:endpoints:web:exposure:include: "*"
IDEA的Terminal权限问题
对于windows环境,如果在cmd中可以运行java或者mvn等命令,但在IDEA的Terminal中却无法使用,首先关闭IDEA,以管理员身份运行即可。
MVN生命周期
dependencyManagement介绍
https://blog.csdn.net/weixin_42114097/article/details/81391024
H2嵌入式数据库引擎
h2database,H2是一个短小精干的嵌入式数据库引擎,主要的特性包括:
- 免费、开源、快速
- 嵌入式的数据库服务器,支持集群
- 提供JDBC、ODBC访问接口,提供基于浏览器的控制台管理程序
- Java编写,可使用GCJ和IKVM.NET编译
- 短小精干的软件,1M左右。
—schema与data初始化操作 其实就是将数据在初始化时如何进行加载!
如何优化Java应用?
字节码层面进行优化,比如hikari,将18行字节码优化为15行,积少成多;
Java assistant使用
对于动态扩展现有类或接口的二进制字节码,有比较成熟的开源项目提供支持,如CGLib、ASM、Javassist等。其中,CGLib的底层基于ASM实现,是一个高效高性能的生成库;而ASM是一个轻量级的类库,但需要涉及到JVM的操作和指令;相比而言,Javassist要简单的多,完全是基于Java的API,但其性能相比前二者要差一些。
其实就是对Java的字节码进行扩展,或修改。

若有收获,就点个赞吧
0 人点赞
