MySQL必知必会
安装
安装Mysql,参考博客:
https://blog.csdn.net/weixx3/article/details/80782479
在SCU中安装了,博客收录在CSDN的数据库系统中。
如果编译报错,极有可能是因为依赖库少了:
https://www.cnblogs.com/coinbt/p/8306467.html
语法教程
| 小数取整 | ROUND | ||
|---|---|---|---|
| 记录数目 | TOP | SELECT TOP number/percent name FROM table_name | mysql的话使用limit SELECT name FROM _table_name _LIMIT 5 |
| 通配符 | LIKE | SELECT * FROM Persons WHERE City LIKE ‘N%’ | 其实就是正则匹配: % 代表0或多个字符 _ 代表一个字符 [chalist]字符串中任意一个字符 [!chalist]或[^chalist]不在字符串中任意一个字符 |
| 限定词 | IN | SELECT * FROM Persons WHERE LastName IN (‘Adams’,’Carter’) | |
| 范围 | BETWEEN AND | SELECT * FROM Persons WHERE LastName BETWEEN ‘Adams’ AND ‘Carter’ | 可以是数值、日期和文本 在BETWEEN前面加NOT表示不在其间。 |
| 别名 | AS | 表的别名: SELECT column_name(s) FROM table_name AS alias_name 列的别名: SELECT column_name AS alias_name FROM table_name |
多个表的别名: SELECT po.OrderID, p.LastName, p.FirstName FROM Persons AS p, Product_Orders AS po WHERE p.LastName=’Adams’ AND p.FirstName=’John’ 不使用别名: SELECT Product_Orders.OrderID, Persons.LastName, Persons.FirstName FROM Persons, Product_Orders WHERE Persons.LastName=’Adams’ AND Persons.FirstName=’John’ |
| 引用 | 无JOIN | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons, Orders WHERE Persons.Id_P = Orders.Id_P | id_P就是连接两个表的主键 |
| 引用 | JOIN | SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons INNER JOIN Orders ON Persons.Id_P = Orders.Id_P ORDER BY Persons.LastName |
JOIN还有其他的用法: JOIN: 如果表中有至少一个匹配,则返回行 LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行 RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行 FULL JOIN: 只要其中一个表中存在匹配,就返回行 |
子查询
其实说到底,SQL语法就是不停地一层套一层,select的结果还可以作为下一个select的条件,这就是所谓的子查询,例如:
SELECT name FROM world WHERE continent =(SELECT continentFROM world WHERE name = 'Brazil')
聚合
聚合(Aggregate)的函数有SUM、Count、MAX、AVG;
内联
外联
常用命令
创建数据库:
create database name;
删除数据库:
drop databases name;
创建数据表:
CREATE TABLE table_name (column_name column_type);(多个表项之间用,隔开);
删除数据表:
drop table 表名;
使用数据库:
use databasename;
退出数据库:
exit/quit;
注:不区分大小写,结尾用“;”表示执行命令;
insert命令
INSERT INTO table_name ( field1, field2,…fieldN ) VALUES ( value1, value2,…valueN );
简记,insert to 表名(区域)值(具体值)
删除某一行:
delete from h5user(表名) where opid(列名) = ‘o_XO’;
show命令
show databases,显示数据库名;
show tables,显示数据库中列表名;
show columns from tablename,显示表中的列名;(mysql独有==describe tablename);
检索命令select
distinct表示只返回不同的值(因为有的某一列有相同的值)
limit,n,m只显示前n行开始的m行,m默认为1;(之后可以显式的指出offest,如limit 4 offest 4,从行4开始的4行)
注:检索出的第一行为行0而不是行1,因此limit 1,1将检索第二行而不是第一行; 完全限定用数据库.表名.列名; 注:不明确排序顺序,则检索出的数据顺序就无意义。 order by 列名,表示按照该列的字母顺序排序(默认升序,降序是desc); 如果是多个列同时排序,那么是先满足前面的排序,才会考虑满足后面的排序; 注:可以过滤部分数据 where price=2.5,只会输出满足条件的列;(位于order之前)(两个值之间可用between,值与值之间用and,不等于用<>或!=) is null,判断是否有空值; 注:过滤操作可以联合执行 用and 将两个过滤的where子句共用,则依次匹配; or表示满足其中一个即可; (and的优先级最高,直接两and两端的条件看成一个条件,以防万一,可以加括号) or的操作可以由in来代替,如102 or 103 ==in(102,103); not 用来否定其之后的任何条件; 注:通配符的作用极其强大 like 表示跟之后的字符相同(利用通配符) %表示任何字符出现任意次数;(不能匹配NULL,感觉有点类似于?) _只匹配单个字符;
注:正则表达式可以进行搜索(*正则表达式可以搜索字符串中是否存在某子串,跟like不同的是,like需要全字符串匹配,而regexp只需要匹配其中一部分即可) 什么是正则表达式呢?描述了一种字符串匹配的模式(pattern); regexp 跟后续特殊字符:(若要区分大小写binary) .表示匹配任意一个字符;
| 表示或;
[]表示匹配其中的任何字符,如[123]表示匹配123其中任何一个即可;
^表示匹配[]之外的字符;
[m-n]表示匹配m到n范围内的字符;
若想匹配特殊字符(.、[]、|、-),需要\为前缀;(匹配\本身的需要\);
有时需要匹配多个实例(且带有选择性),有如下方式:
- 0或多匹配;(表示击中0个或多个)
+1或多匹配;(表示击中一个或多个)
?0或1匹配;(即表示前面中不中)
{m}指定匹配m次;
{m:}不少于m次击中;
{m:n}范围内的击中;
注:s?表示击中s0次或一次;
注2:有专门的预定义字符类,如[:digit:]为匹配任意数字,[[:digit:]]表示匹配连在一起的任意数字;
注:可以指定匹配的位置;
^文本的开始;(之前还提到过可以进行否定集合)
$文本的结尾;
[[:<:]]词的开始;
[[:>:]]词的结尾;拼接命令Concat Concat()可以实现列的合并;(SQL用+或||来实现拼接) RTrim()去掉右边的空格; AS 作为别名;
练习题目
在线练习网站
https://sqlzoo.net/wiki/SELECT_within_SELECT_Tutorial/zh 如果之前做的答案已经被清空了,可以百度答案 注:不区分大小写,结尾用“;”表示执行命令;
SQL实战:怎么从数据中取出各科的最大成绩?
原题可参考:链接
简单来说,数据库某一个表gradeMax中有三个字段 name subject grade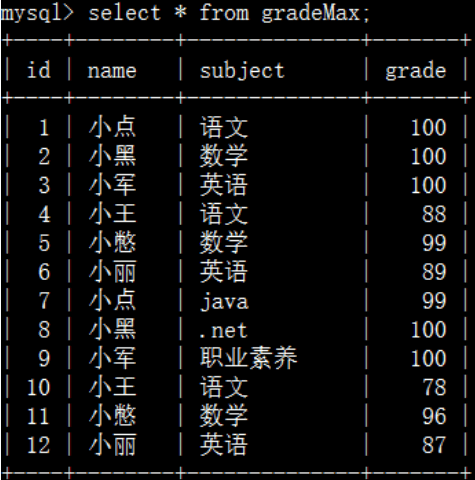
需要做的就是找出各科成绩的最大值(更进一步,获取到具体的同学),在线演练网站链接(左侧简历字段及主键值、并insert数据,右边进行sql语句的查询)
- 如何找到各科成绩的最大值?
- 这明显是一个分组的问题,需要使用group by subject
- 现在我们将数据按照各科拿出来了,取最大值就好了啊 max(grade)
- 于是整体 select max(grade) from gradeMax group by subject
- 如何把对应的人也找出来呢?
- select name,subject,max(grade) from gradeMax group by subject
- 上面的就可以了
重点:Mysql查询语句写法

若有收获,就点个赞吧
0 人点赞
