Java集合类的主要目的是创建一个简单的、高性能的数据结构操作框架。
总览
Java的集合框架均是围绕一组标准的接口而设计的,根接口是数据集合(Collection)与键值映射表(Map),并基于这两个接口派生了多个子接口,进而实现了包括数组、哈希表、集合等数据结构,以Collection接口为例,其派生的主要集合类如下:
在该框架中,主要有三部分内容,其一,容器的接口,如Collection、Map、Set等等;其二,实现类,是对容器的具体实现,也就是实际所用的数据结构,例如HashSet、ArrayList等等;其三,相应的算法,这些算法主要是配套数据集结构进行使用,完成一些常用的功能,如排序、搜索等等。
Collection
Collection接口主要定义了一些通用的方法,留待后续数据结构进行实现,详情如下:
public interface Collection<E> extends Iterable<E> {int size(); // 集合内元素个数boolean isEmpty();//该集合是否为空boolean contains(Object o);//是否包含某个元素,需要进行搜索Iterator<E> iterator();//返回迭代器Object[] toArray();//转换为数组<T> T[] toArray(T[] a);boolean add(E e);boolean remove(Object o);boolean containsAll(Collection<?> c);//相当于判断某个集合是不是另外集合的子集boolean addAll(Collection<? extends E> c);boolean removeAll(Collection<?> c);default boolean removeIf(Predicate<? super E> filter){…… //当满足条件时,对元素进行删除}boolean retainAll(Collection<?> c);//需要保留的元素,其他的删除void clear();boolean equals(Object o);int hashCode();default Spliterator<E> spliterator() { //分割为多个迭代器return Spliterators.spliterator(this, 0);}default Stream<E> stream() {//流处理return StreamSupport.stream(spliterator(), false);}default Stream<E> parallelStream() {//并行处理return StreamSupport.stream(spliterator(), true);}}
Iterable与Iterator
另外,Collections与Map都继承了Iterable接口,Iterable主要用作遍历:
public interface Iterable<T> {Iterator<T> iterator();default void forEach(Consumer<? super T> action) {Objects.requireNonNull(action);for (T t : this) {action.accept(t);}}default Spliterator<T> spliterator() {return Spliterators.spliteratorUnknownSize(iterator(), 0);}}
其中最重要的时迭代器Iterator接口:
public interface Iterator<E> {boolean hasNext();E next();default void remove() {throw new UnsupportedOperationException("remove");}default void forEachRemaining(Consumer<? super E> action) {Objects.requireNonNull(action);while (hasNext())action.accept(next());}}
迭代器Iterator有两个主要方法:hasNext与next,前者查询是否还有下一个迭代器,后者则是取下一个迭代器。不同数据结构对这两个方法的实现不一致,后文再表。
接下来先介绍Collection接口的三个子接口:List、Set、Queue。
List
根据Java Doc所言,List集合是一个元素可重复的有序集合,同广义上的数组类似,可以用过下标直接操作集合内元素。除了Collections接口原本的方法之外,List增加了一些自定义的方法:
public interface List<E> extends Collection<E> {……//Collection继承的default void sort(Comparator<? super E> c) {//根据comparator进行元素排序}E get(int index); //获取指定下标的元素E set(int index, E element); // 替换指定下标的元素,返回原来的元素值int indexOf(Object o); //返回第一次出现的下标,否则为-1int lastIndexOf(Object o);//最后一次出现,否则为-1List<E> subList(int fromIndex, int toIndex); //根据下标提取子List//iterator迭代器ListIterator<E> listIterator(); //返回迭代器ListIterator<E> listIterator(int index); //指定位置的迭代器}
ListIterator继承于Iterator,在原本的基础上进行方法的增加,从而便于List的遍历和使用:
public interface ListIterator<E> extends Iterator<E> {boolean hasNext();E next();//之前是否还有迭代器,与hasNext方向相反boolean hasPrevious();E previous();//迭代器下次访问的下标,如果已到末尾,则返回列表尺寸int nextIndex();//迭代器下次访问的下标(往前),如果已到开头,则返回-1int previousIndex();//从迭代器位置开始进行删除void remove();//替换迭代器位置的元素void set(E e);//其实是insert,再迭代器位置进行元素插入void add(E e);}
Vector
Vector的底层其实是元素数组,有三个重要属性:
//元素数组,使用Object类型进行初始化protected Object[] elementData;//当前数组中的元素个数protected int elementCount;//扩容时容量增加数量,默认为0,表示容量翻倍,否则为old+capacityIncrementprotected int capacityIncrement;
在往数组中进行插入时,需要先判定当前空间是否足够:
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}
其中的ensureCapacityHelper即是判断当前的容量是否够用,如果不够需要调用grow()方法进行扩容:
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity);}
值得注意的是,Vector是线程安全的,采用synchronized对成员函数进行加锁;
Stack
Stack继承Vector,在基类的基础上实现了push、pop、peek等方法,从而实现了栈的功能,也是线程安全的。
其实就是在Vector的末尾进行插入、删除等操作。
ArrayList
与Vector一样,ArrayList的底层也是一个自动扩容数组,且扩容为2倍(无法修改)。
另外,ArrayList是线程不安全的,不涉及synchronized,因此其性能相较于Vector更好,因为少去了加锁等操作。
LinkedList
LinkedList类是List接口的实现类——这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,可以被当作成双端队列来使用,因此既可以被当成“栈”来使用,也可以当成队列来使用。
LinkedList的实现机制与ArrayList完全不同。ArrayList内部是以数组的形式来保存集合中的元素的,因此随机访问集合元素时有较好的性能;而LinkedList内部以链表的形式来保存集合中的元素,因此随机访问集合元素时性能较差,但在插入、删除元素时性能比较出色。
ArrayList与LinkedList性能对比
ArrayList 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。ArrayList应使用随机访问(即,通过索引序号访问)遍历集合元素。
LinkedList 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。LinkedList应使用采用逐个遍历的方式遍历集合元素。
如果涉及到“动态数组”、“栈”、“队列”、“链表”等结构,应该考虑用List,具体的选择哪个List,根据下面的标准来取舍。
(01) 对于需要快速插入,删除元素,应该使用LinkedList。
(02) 对于需要快速随机访问元素,应该使用ArrayList。
(03) 对于“单线程环境” 或者 “多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。对于“多线程环境,且List可能同时被多个线程操作”,此时,应该使用同步的类(如Vector)。
Set
Set就是常规意义上的集合(Set),其接口定义与Collection几乎一样,特点在于该集合内部不能存在相同的元素,在第二次加入相同的元素时会提示错误。
HashSet
HashSet实质上是一个HashMap,并且在插入某一个对象时,以对象作为键,并“虚构”一个对象作为值:
public boolean add(E e) {return map.put(e, PRESENT)==null;}
当HashMap已存在该对象时,返回false,且不会改变HashMap,否则返回True,表示值已插入。
注意,HashSet是线程不安全的。
HashSet中藏着一个包私有的方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);}
EnumSet
枚举EnumSet是一个虚基类,无法直接New出。那么如何使用?
它提供了一系列的静态接口,因此可以通过静态工厂来获取EnumSet对象:
EnumSet<E> noneOf(Class<E> elementType):构造一个空的集合EnumSet<E> allOf(Class<E> elementType):构造一个包含枚举类中所有枚举项的集合EnumSet<E> of(E e):构造包含1个元素的集合EnumSet<E> of(E e1, E e2):构造包含2个元素的集合EnumSet<E> of(E e1, E e2, E e3):构造包含3个元素的集合EnumSet<E> of(E e1, E e2, E e3, E e4):构造包含4个元素的集合EnumSet<E> of(E e1, E e2, E e3, E e4, E e5):构造包含5个元素的集合EnumSet<E> of(E first, E... rest):构造包含多个元素的集合(使用可变参数)EnumSet<E> copyOf(EnumSet<E> s):构造包含参数中所有元素的集合EnumSet<E> copyOf(Collection<E> c):构造包含参数中所有元素的集合
例如使用of获取EnumSet:
public static <E extends Enum<E>> EnumSet<E> of(E e) {EnumSet<E> result = noneOf(e.getDeclaringClass());result.add(e);return result;}
其中国noneOf是EnumSet的关键函数,它会根据Set中的元素数目返回指定的枚举集合:
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) {Enum<?>[] universe = getUniverse(elementType);if (universe == null)throw new ClassCastException(elementType + " not an enum");if (universe.length <= 64)return new RegularEnumSet<>(elementType, universe);//仅有64位,以long为底层elsereturn new JumboEnumSet<>(elementType, universe);}
作个补充,什么是枚举类型(Enum Type)?
简单来说就是定义一个枚举类型,该枚举类型中的取值范围已经做了限定,比如彩虹七色:
enum RainbowColor { RED, ORANGE, YELLOW, GREEN, CYAN, BLUE, PURPLE }
那么EnumSet是怎么实现集合的功能的呢?比如add、contain?
位运算!如下是RegularEnumSet中add的部分代码:
public boolean add(E e) {typeCheck(e);long oldElements = elements;elements |= (1L << ((Enum<?>)e).ordinal());return elements != oldElements;}
其中typeCheck(e)是为了确保插入元素确实属于枚举类型,之后的三行操作简单理解就是通过位运算查看当前Set中是否已经插入了某个枚举类型,如果已经存在,则elements与oldElements相等,返回false,否则返回True。
contains的代代码如下:
public boolean contains(Object e) {if (e == null)return false;Class<?> eClass = e.getClass();if (eClass != elementType && eClass.getSuperclass() != elementType)return false;return (elements & (1L << ((Enum<?>)e).ordinal())) != 0;}
关键就在于最后一行代码,通过相与操作来判定当前Set中是否已存在该对象。
TreeSet
Queue
Queue队列,提供出队、入队方法:
public interface Queue<E> extends Collection<E> {boolean add(E e);//如果空间足够将指定元素加入队列,否则报出异常boolean offer(E e);//当用于有空间限制的队列时,优于add方法E remove();//获取并移除队列头,为空则报出异常E poll();//获取并移除队列头,为空则返回nullE element();//获取队列头,为空则报出异常E peek();//获取队列头,为空则返回null}
ArrayDeque
ArrayDeque是基于数组实现的双端队列,ArrayDeque为了满足可以同时在数组两端插入或删除元素的需求,其内部的动态数组还必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点。
下面再说说扩容函数doubleCapacity(),其逻辑是申请一个更大的数组(原数组的两倍),然后将原数组复制过去。过程如下图所示: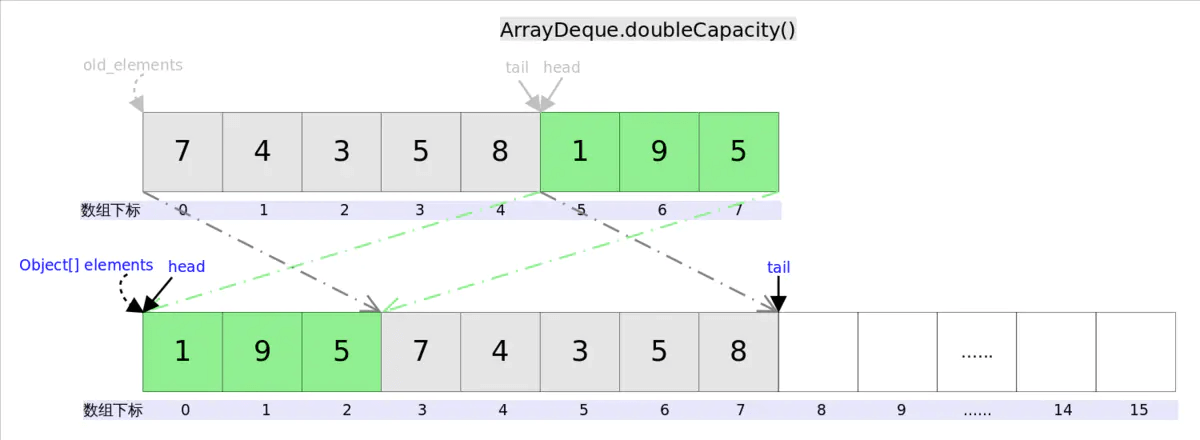
图中我们看到,复制分两次进行,第一次复制head右边的元素,第二次复制head左边的元素。
private void doubleCapacity() {assert head == tail;int p = head;int n = elements.length;int r = n - p; // number of elements to the right of pint newCapacity = n << 1;if (newCapacity < 0)throw new IllegalStateException("Sorry, deque too big");Object[] a = new Object[newCapacity];System.arraycopy(elements, p, a, 0, r);System.arraycopy(elements, 0, a, r, p);elements = a;head = 0;tail = n;}
PriorityQueue
PriorityQueue会根据队列中元素大小进行排序,因此当调用Peek或Pool取出队列元素时,并不是取出最先进入队列的元素,而是最大(最小,或自定义的方法)的元素。
怎么实现的?
其实本质也是一个动态数组,并通过二分法来进行元素的插入:
private void siftUpComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {int parent = (k - 1) >>> 1;Object e = queue[parent];if (key.compareTo((E) e) >= 0)break;queue[k] = e;k = parent;}queue[k] = key;}
PriorityQueue实现插入方法(offer、poll、remove() 和 add 方法) 的时间复杂度是O(log(n)) ;
实现 remove(Object) 和 contains(Object) 方法的时间复杂度是O(n) ;
实现检索方法(peek、element 和 size)的时间复杂度是O(1)。
所以在遍历时,若不需要删除元素,则以peek的方式遍历每个元素。
Map
Map(映射表)给用户提供了一种通过指定关键词来查询对应对象数据的方法。与List(数组)相比,如果要找到List中某个指定员工的薪资,智能通过遍历查找,这种方式过于费时费力。而使用Map,则可以直接根据员工姓名name返回其详细信息,因此Map的主要使用场景就是需要进行快速映射(定位:Key-Value。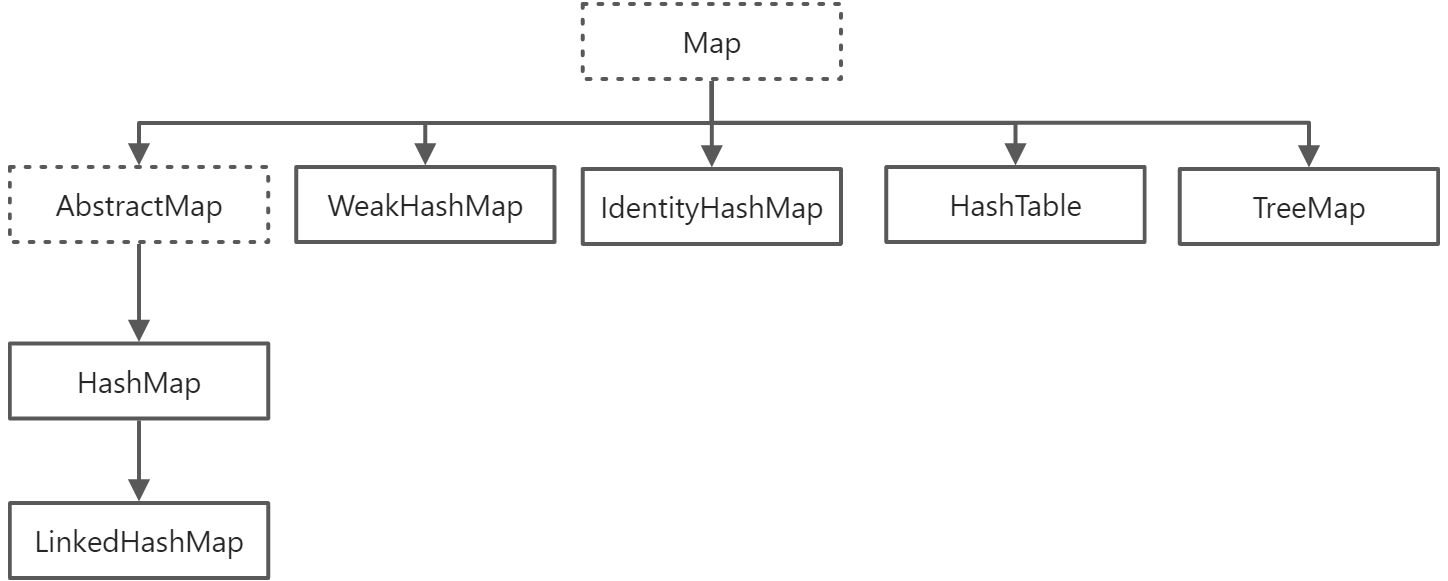
与Collection一样,Map其实是一个接口,预定义了一些通用的方法,主要进行键值对的存储、查询、删除等,之后由后续具体的实现类对其进行实现,相关方法定义和功能如下:
public interface Map<K,V>{int size();boolean isEmpty();boolean containsKey(Object key);//Map中是否存在某个键boolean containsValue(Object value);//是否存在某个值V get(Object key);//根据键获取值V put(K key, V value);//将一个(K,V)键值对插入Map中V remove(Object key);//删除某一个键值对//将两个Map进行合并,但是K与V必须满足泛型要求void putAll(Map<? extends K, ? extends V> m);void clear();//清空MapSet<K> keySet();//获取Map中所有的键,并放入一个Set中Collection<V> values();//获取Map所有的值,放入Collection中Set<Map.Entry<K, V>> entrySet();//将Map中的键值对用一个Set来存放,Entry的定义见下default V putIfAbsent(K key, V value) {...}//如果当前不存在某个Key,进行插入//当前key所对应的value满足条件进行更换default boolean replace(K key, V oldValue, V newValue) {Object curValue = get(key);if (!Objects.equals(curValue, oldValue) ||(curValue == null && !containsKey(key))) {return false;}put(key, newValue);return true;}//强制进行value替换default V replace(K key, V value) {V curValue;if (((curValue = get(key)) != null) || containsKey(key)) {curValue = put(key, value);}return curValue;}......}
值得注意的是,在Map中不能存在相同的Key,可以存在相同的value!当插入相同的Key时,其实是后面的一组将之前的内容给覆盖掉了,比如:
Map<String, Integer> map = new HashMap<>();map.put("zhangsan", 28000);map.put("zhangsan", 38000);
上述代码执行完毕之后,通过“zhangsan”进行查询时,获得的Value其实是38000。
另外,之前在Map的方法定义里可以看到put的方法签名为:V put(K key, V value),如果Map中本来不存在这个key,返回的V就是null,如果存在key,返回的V就是之前的value。
在定义的方法中,定义了两个replace方法用来更换键值对的值:boolean replace(K key, V oldValue, V newValue)与V replace(K key, V value) ,两者的区别在于前者仅在oldValue等于当前key所对应的值是进行更换,而后者则是只要当前key存在就进行更换,如何选择使用对应的方法根据实际使用场景来确定即可。
Entry
在Map中其实所有的K-V键值对都是用一类对象来存储的——Entry。
Entry在Key与Value基础上进行了封装,从而实现Key与Value的对应关系,相关接口定义如下:
interface Entry<K,V> {K getKey();V getValue();V setValue(V value);boolean equals(Object o);int hashCode();public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>>comparingByKey() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getKey().compareTo(c2.getKey());}public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>>comparingByValue() {return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> c1.getValue().compareTo(c2.getValue());}public static <K, V> Comparator<Map.Entry<K, V>>comparingByKey(Comparator<? super K> cmp) {Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());}public static <K, V> Comparator<Map.Entry<K, V>>comparingByValue(Comparator<? super V> cmp) {Objects.requireNonNull(cmp);return (Comparator<Map.Entry<K, V>> & Serializable)(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());}}
实际上,Entry才是Map中实际存储的对象: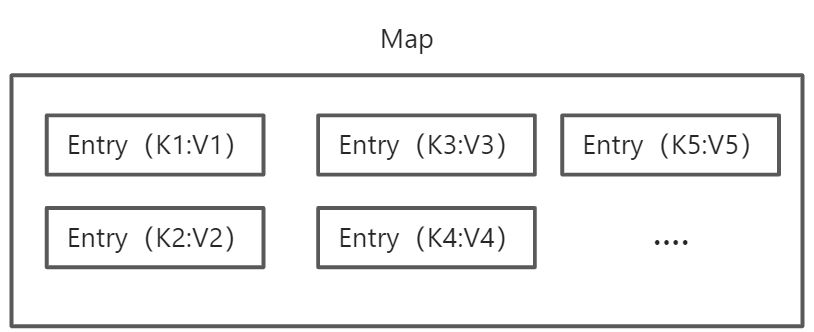
有关Map中的Entry如何排列,跟Entry中定义的四种Comparator比较器有关,且不同的Map实现均对Entry类进行了相应的修改,这将在后文具体的Map实现(HashMap, TreeMap, Hashtable, SortedMap等)中进行讲解。
AbstractMap
Abstract是一个虚拟类,实现了Map的大部分接口,减少后续Map实现类的实现复杂度。
HashMap(可以单独拿一章出来了)
怎么学一个集合? 从它的使用流程来学习,即新建,插入、删除等等。。。。。
首先需要对HashMap(哈希表)有一个整体的概念,Java的HashMap采用开链法,从结构看上来看就是数组+链表(红黑树),如下: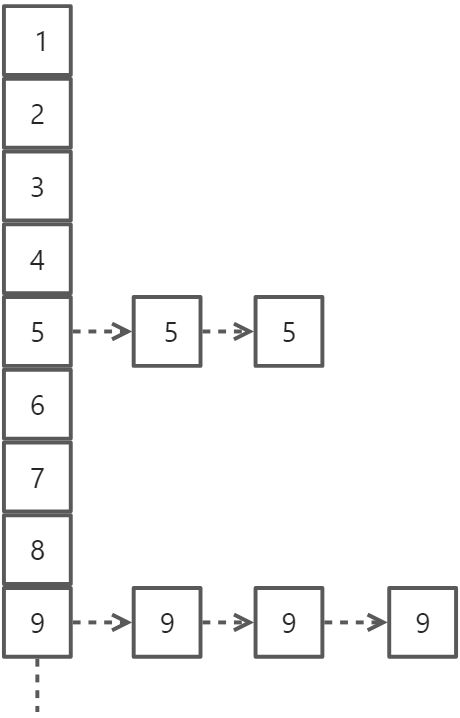
上图中,1,2,3……等表示数组下标,可以理解为一个一个的桶,每个桶都可以存放键值对(K-V)。
怎么放进去?
这就要说到哈希算法了,简单来说就是用来确定某一个键值对存放在数组的哪个小下标!
假设现在只有十个桶,我们需要将一批键值对(K-V)尽可能均匀地找位置放进去,可以设计一个最简单、最常见的哈希算法:hash(x) = x %10,也就是进行一个除10取余操作,余数是多少,就把键值对放进对应的数组空间内。
其中,x是键值对中Key的hashCode值(简单理解就是一个对象的id,类似于身份证,在程序中独一无二)。
哈希算法的目的,是为了将这批键值对放进数组中,而好的hash算法则是尽可能保证它们均匀的放入数组中,不会出现某一些数组下标内有贼多的键值对,但是另外的一个都没有。
为什么有的数组下标里有多个键值对?
因为桶的数量有限,一些K-V键值对经过哈希算法算出来的下标相同:
比如现在有两个键值对:12-‘apple’ 和 22-‘pencil’
通过除10取余,下标都是2,就只能丢到同一个桶里,为了简单可以用链表将其串联起来,这样就好比某些桶里只有一个球,有些桶里是一串球。
那怎么在链表中找到我想要的键值对?
没有别的办法,只能把链表拎出来,一个一个的比对Key,直到找到想要的Key为止,因为哈希表中的Key不允许重复。
可同一个桶里的键值对太多了怎么办?就不能体现哈希表的快速了啊!
问得好,哈希表就是为了能够实现快速的键值对映射,如果一个桶里的链表太长了,严重影响效率。
比如每一个桶里存放几千上万个键值对,怎么利用哈希表快速的找到自己想要的键值对?
对链表进行遍历?O(N)的时间复杂度有点遭不住……
在这种情况下,有两种解决思路:
第一,增加桶的数量,桶的数量多了,不同键值对被分配到同一个桶的概率就小,自然而然链表长度短了,查询时间降低;
第二,在不增加桶数量的前提下,为了优化查询时间,可以把链表转换为红黑树,红黑树这种数据结构的查询效率更高,查询时间仅有O(logn)。
哪种解决思路好?
前者的问题在于,空间总是有限的,不可能一味地增加数组上限,后者的问题在于,维护红黑树比维护一个链表要麻烦得多。
那么如何权衡时间与空间呢?
来看看JDK1.8的HashMap中有几个与之有关的重要属性:
//默认值static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认数组大小(哈希表容量)static final int MAXIMUM_CAPACITY = 1 << 30;//最大数组大小,2^30static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认负载因子static final int TREEIFY_THRESHOLD = 8;//链表转换为红黑树的阈值static final int UNTREEIFY_THRESHOLD = 6;//红黑树转换为链表的阈值static final int MIN_TREEIFY_CAPACITY = 64;//转换红黑树所要求的哈希表最小容量//成员遍历transient int size;//当前哈希表中的键值对数量int threshold;//当前键值对数量超过某个上限(capacity*loadfactor)时进行空间翻倍final float loadFactor;//设置的负载因子,如果没有设置,则为默认值
通过上面几个值,可以来模拟一下Java中HashMap是怎么进行空间和时间的平衡的:
1、创建一个HashMap,默认的数组大小为8,也就是有8个桶(这个数组其实会等到首次插入键值对时才会进行申请,亦称惰性分配),也可设置初始数组大小;
2、插入第一个键值对(这才真正分配数组空间),利用hash算法将其放入数组中;
3、插入第二个键值对……第三个……第四个键值对计算出的桶与第一个键值对一样,那么将第四个键值对放在第一个键值对的链表末尾(JDK1.8之后均采用插入链表尾部的方法)
4、当插入第6个(80.75)时,由于超过门限值,哈希表进行扩容,容量变为16,并将之前的键值对拷贝至新申请的数组空间内;
5、继续插值……当容量超过12(160.75)时再次扩容,容量变为32;
6、继续插值……当容量超过24(320.75)时再次扩容,容量变为64;
7、继续插值,在这个过程中,如果某一个桶中链表数量达到8(TREEIFY_THRESHOLD),则调用treeifyBin()函数将该链表转换为红黑树,注意,如果在之后进行删除操作,使得该红黑树的数量小于等于6(UNTREEIFY _THRESHOLD),则将该红黑树转换为链表;
8、删除操作大致相反,Over!
再次,总结一下上述过程,简单来说就是:
空间快不够用啦,空间加倍啊!
哈希计算冲突啦,用链表串啊!
*链表太特么长啦,用红黑树啊!
为什么要n-1&hash
任何两个数相与,其结果都不会大于最小的那个数。
因此n-1&hash,其实就是为了将最终的结果限定在数组范围内,相比于%,其效率更高。
还有个重点,在JDK1.8之后,hashmap的长度始终保持是2的倍数,原来的Key有两种结果,一是在原下标,二是在原下标+原数组长度。
比如原来的长度为8 :则n-1&hash计算为 0111 & hash
长度变为16时,则为0 1111 &hash,唯一的变数就在于多了一个1,该位相与的结果可能是1也可能是0。
关于计算tableforsize:power of two
int 是32字节 ,n-1的好处
https://www.cnblogs.com/xiyixiaodao/p/14483876.html
说到底,就是要将后面的位全部置为1,而后+1,即可得到一个2的整数幂!
modCount是为了实现快速失败机制,当在访问hashmap的过程中进行了修改,就会报异常,主要应用于多线程环境下。
如何遍历hashmap?
利用foreach方法,遍历底层数组+链表(红黑树);
也可以利用keyset、entryset、values函数直接获取值;
与concurrentHashmap的区别?
在进行迭代时,HashTable会锁住整个Map,而ConcurrentHashMap只锁住Map的一部分,所以ConcurrentHashMap在多线程环境下的性能更好。
锁住整个Map怎么理解? hashtable中直接对方法体上修饰synchronized,当一个线程操作时,其他线程都无法访问; 而concurrenthashmap仅锁定方法体中的一部分代码块,其他线程还可以调用相应的线程方法:
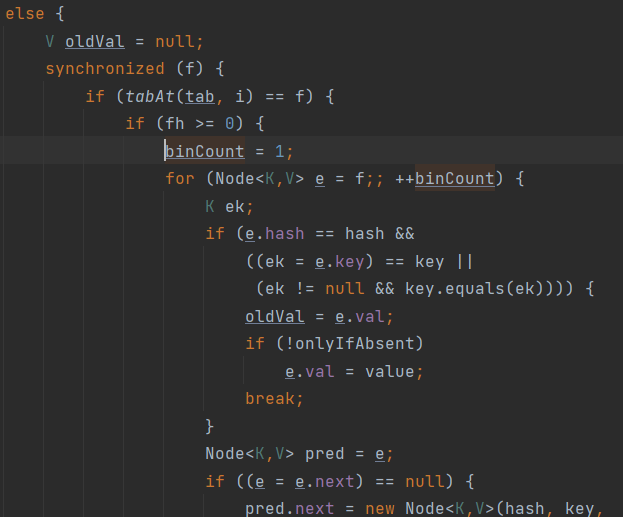
另外,concurrentHashmap的kv也不能有null,与hashtable保持一致。
如何让HashMap实现同步功能?
Map m = Collections.synchronizeMap(hashMap);
HashTable
其实现时基于数组+链表实现的,并具有一定的线程安全性。与HashMap相比:
实现接口不同
HashTable基于已经废弃的Dictionary类与Map接口实现的。
而HashMap主要是基于Map实现的,属于Java集合框架。
实现原理不同
Hashtable采用开链法构造哈希表,且hash函数较为简单:
index = (hash & 0x7FFFFFFF) % tab.length;
但Hashmap使用链表与红黑树相结合的方式实现,且hash函数较为复杂。
线程安全性不同
Hashtable利用synchronized实现线程安全。
而HashMap并没有进行相应的线程安全处理。
K-V键值对的要求不同
Hashtable要求K-V中的kv都不能为null,而Hashmap则两者都可以为null,关键性因素在于hashtable中直接对key调用了hashcode,会报错,而hashmap计算hashcode时先进行了判断:
//hashtableint hash = key.hashCode();//问题出在这里!!!//hashmapstatic final int hash(Object key) {int h;//当key等于null的时候,不走hashCode()方法return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
This函数是什么?
在看hashtable的源码时,发现:
public Hashtable() {this(11, 0.75f);}
这个this是Java的一个特点,this表示对象自身,可以用于在一个构造函数中调用另一个构造函数。
LinkedHashMap
在HashMap的基础上多维护了一个双向链表的,iteration时的遍历顺序是按照插入顺序(insertion-order)来的。
为记录插入的顺序,LinkedHashMap分别使用两个属性值来记录第一个插入值与最后一个插入值:
/*** The head (eldest) of the doubly linked list.*/transient LinkedHashMap.Entry<K,V> head;/*** The tail (youngest) of the doubly linked list.*/transient LinkedHashMap.Entry<K,V> tail;
在进行哈希表的迭代时,其按照插入的Key顺序进行迭代,这就是使用它的场景。
TreeMap
基于红黑树实现的Map结构,完全按照Key的自然顺序或指定的Comparator进行排序,因此,查询、插入、删除的时间复杂度均为log(n)。
如何判定相等?
类似于TreeSet中判断两个元素相等的标准,TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。
TreeMap中判断两个value相等的标准是:两个value通过equals()方法比较返回true。
Map实现类的性能分析及适用场景
HashMap与Hashtable实现机制几乎一样,但是HashMap比Hashtable性能更好些。
LinkedHashMap比HashMap慢一点,因为它需要维护一个双向链表。
TreeMap比HashMap与Hashtable慢(尤其在插入、删除key-value时更慢),因为TreeMap底层采用红黑树来管理键值对。
适用场景:
一般的应用场景,尽可能多考虑使用HashMap,因为其为快速查询设计的。
如果需要特定的排序时,考虑使用TreeMap。
如果仅仅需要插入的顺序时,考虑使用LinkedHashMap。
WeakHashMap
它的功能和实现与HashMap大致相同,其特点就在于其中的Entry继承了WeakReference(弱引用)类,这就让WeakHashMap中的Entry具备了弱引用特性,那何谓弱引用特性?
弱引用对象的生存周期极短,当弱引用对象不在被其他对象引用时,无论内存是否够用,GC都会对其进行回收。
从具体表现上看,在WeakHashMap中,如果某个健值已经不再被其他对象引用,则GC会自动删除其键值对,腾出空间。而在HashMap中,除非主动删除Key,否则该Key会一直存在。
如下面的这个例子:
//https://www.cnblogs.com/yjf512/p/7413236.htmlpublic class WeakHashMap {public static void main(String[] args){String a = new String("a");String b = new String("b");Map weakmap = new WeakHashMap();weakmap.put(a, "aaa");weakmap.put(b, "bbb");a=null; //将字符串对象“a”的引用取消了System.gc(); //a的键值对会被回收Iterator j = weakmap.entrySet().iterator();while (j.hasNext()) {Map.Entry en = (Map.Entry)j.next();System.out.println("weakmap:"+en.getKey()+":"+en.getValue());// 打印结果:weakmap:b:bbb}}}
WeakHashMap主要应用于缓存中,可以及时对不需要的缓存键值对进行处理,保存内存使用的高效性。
IdentityHashMap
与HashMap不同的是主要有两个区别:
其一,IdentityHashMap中没有使用红黑树;
其二,IdentityHashMap在比较两个Key是否相同时,采用的是引用相同(reference-equality)而HashMap采用对象相同(object-equality),看代码:
//其实就是==与equals的区别// identityHashmapk1 == k2// HashMap(k = e.key) == key || (key != null && key.equals(k)))
可以看到,Identify的要求很苛刻:必须是引用相等!
什么是引用相等==?那就是两个Key指向的是同一个对象(同一内存地址)!其实equals原本也是比较内存地址,但是很多类对该equals都进行了重写,变成了比较对象中的值。
==与equals的区别

若有收获,就点个赞吧
0 人点赞
