前言
由于在接下来的学习内容中涉及到对信息、数据的同步,我们在开发操作系统的时候必须考虑到并发、多核情况下的同步问题,要想解决这些问题,实际应用中一般采用锁:原子变量、关中断、信号量、自旋锁。
那么其底层如何实现的呢?
——让我们跟着彭老师的讲解,一起学习!
以对一个全局变量进行操作为例,下述代码是一个中断处理函数和逻辑函数,它们都是对全局变量a进行操作:
int a = 0;void interrupt_handle(){a++;}void thread_func(){a++;}
对于a++,在编译阶段一般是将其分为三步:
- 将a存入某寄存器
- 该寄存器值+1
- 将寄存器的值刷新回内存
但是,如果在第二步完成之后突然发生中断了该如何?由时刻为标尺对a的值进行观测:
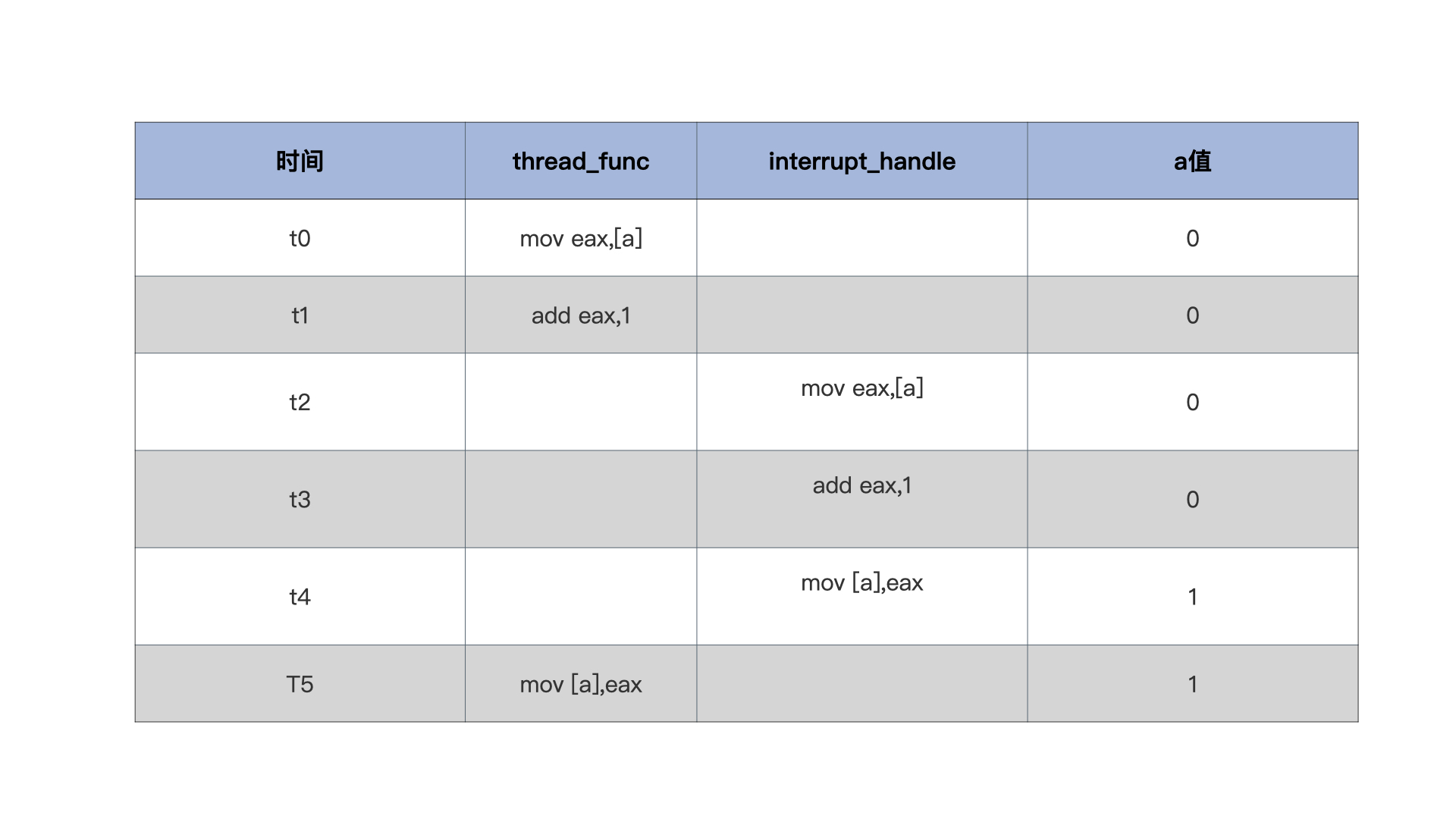
可以看到,由于中断的发生将thread_func的执行过程强行掐断,最终a的值为1,但其实它的值应该为2。
那么如何解决这个问题?
一是,将a++这个操作变成不可分割,即无法再拆解成3步执行,即是原子操作;
二是,在执行a++这个操作时,关闭中断,执行完毕之后再打开中断。
原子操作
原子操作需要底层操作系统支持,X86 CPU支持许多原子指令,C语言正是通过嵌入汇编代码调用这些原子指令来实现原子操作,而Java是在JVM层面对原子操作进行了实现。
另外,内嵌汇编代码编写格式的学习可参考:AT&T格式汇编代码,也可参考文末的补充部分进行理解。
实现原子读和原子写等:
//定义一个原子类型typedef struct s_ATOMIC{volatile s32_t a_count; //禁止编译器优化,使其每次都从内存中加载变量}atomic_t;//原子读static inline s32_t atomic_read(const atomic_t *v){//x86平台取地址处是原子return (*(volatile u32_t*)&(v)->a_count);}//原子写static inline void atomic_write(atomic_t *v, int i){//x86平台把一个值写入一个地址处也是原子的v->a_count = i;}//原子加上一个整数static inline void atomic_add(int i, atomic_t *v){__asm__ __volatile__("lock;" "addl %1,%0": "+m" (v->a_count): "ir" (i));}//原子减去一个整数static inline void atomic_sub(int i, atomic_t *v){__asm__ __volatile__("lock;" "subl %1,%0": "+m" (v->a_count): "ir" (i));}//原子加1static inline void atomic_inc(atomic_t *v){__asm__ __volatile__("lock;" "incl %0": "+m" (v->a_count));}//原子减1static inline void atomic_dec(atomic_t *v){__asm__ __volatile__("lock;" "decl %0": "+m" (v->a_count));}
注意,“lock”前缀是多核CPU下保证数据同步的指令,该指令会锁住数据总线,防止其他CPU更改对应内存地址的值,单核CPU不需要,更详细内容查看内存屏障、validate。
在使用原子操作的情况下,原本对全局变量的操作就可以改成:
atomic_t a = {0};void interrupt_handle(){atomic_inc(&a);}void thread_func(){atomic_inc(&a);}
关中断
上述原子操作虽然可以完成同步操作,但是只能对付一些简单的单体变量,对于复杂的数据结构,如果使用原子操作,可想而知代码的复杂程度有多大。
在这个时候可以考虑通过关闭中断,从而实现相应的代码控制。
x86平台上的CPU关闭中断、开启中断指令是cli、sti,其主要是对CPU的eflags寄存的IF位进行设置,CPU据此来决定是否响应中断信号。
简单的关、开中断代码:
//关闭中断void hal_cli(){__asm__ __volatile__("cli": : :"memory");}//开启中断void hal_sti(){__asm__ __volatile__("sti": : :"memory");}//使用场景void foo(){hal_cli();//操作数据……hal_sti();}void bar(){hal_cli();//操作数据……hal_sti();}
上述方式的问题就在于无法嵌套使用:
void foo(){hal_cli();//操作数据第一步……hal_sti();}void bar(){hal_cli();foo();//操作数据第二步……hal_sti();}
当从foo()函数返回到bar()时,这时中断已经被打开,但是bar()不知道!如果继续执行操作数据第二步,那么就可能因为其他线程函数的访问造成数据不一致问题。
为了让中断管理可以嵌套,就需要在关闭、开启中断的时候保存之前的状态,如下:
typedef u32_t cpuflg_t;static inline void hal_save_flags_cli(cpuflg_t* flags){__asm__ __volatile__("pushfl \t\n" //把eflags寄存器压入当前栈顶"cli \t\n" //关闭中断"popl %0 \t\n"//把当前栈顶弹出到flags为地址的内存中: "=m"(*flags):: "memory");}static inline void hal_restore_flags_sti(cpuflg_t* flags){__asm__ __volatile__("pushl %0 \t\n"//把flags为地址处的值寄存器压入当前栈顶"popfl \t\n" //把当前栈顶弹出到flags寄存器中:: "m"(*flags): "memory");}
简单来说,在关闭中断的时候,把之前的状态存入地址为flag的内存中;在开启中断时,究竟是否开启中断,是由flag地址中存储的值来确定的!(即进行关闭中断操作之前的中断状态)
注:内存中的flag只是用来保存的,CPU是否中断由寄存器中的值而定。
注:注意区分中断与子程序调用的区别。
注:这里没有区分中断的优先级,但是实际的操作系统中,低级中断应该被高级中断所打断。
自旋锁
中断完美解决了原子操作只能针对单体变量的情况,但是——中断只能控制单核CPU,在多核CPU的情况下,又会遇到并发冲突的问题了,这个时候就需要使用“自旋锁”。
自旋锁原理如下:
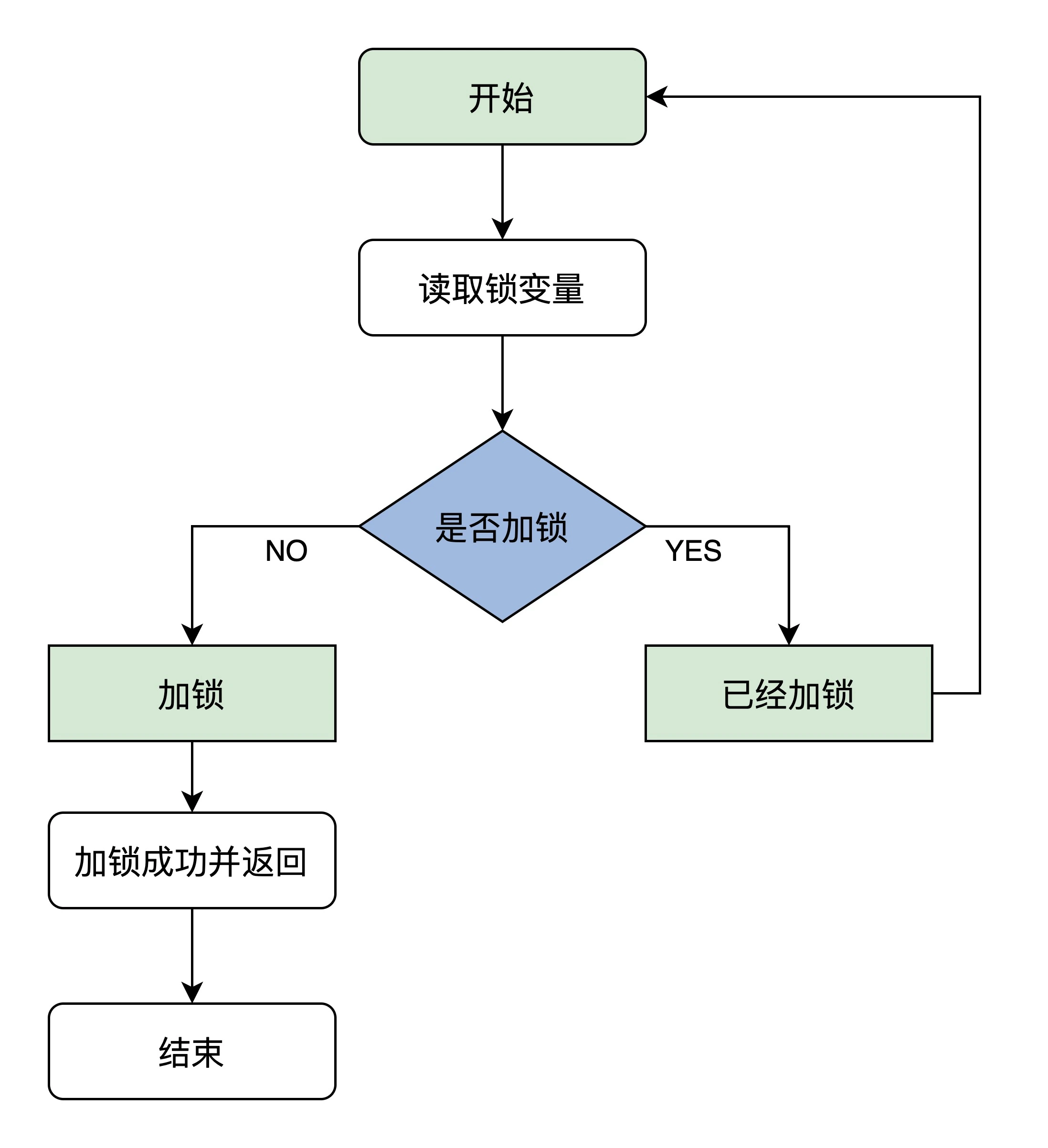
上述流程有一个必须保证的点:读取锁变量、判断加锁操作必须是原子操作,否则还是会造成并发错误。
好在x86 提供了一个原子交换指令:xchg——让寄存器的值和内存空间的值进行交换。
根据上述流程图,将自旋锁实现如下:
//自旋锁结构typedef struct{//volatile可以防止编译器优化//保证其它代码始终从内存加载lock变量的值volatile u32_t lock;} spinlock_t;//锁初始化函数static inline void x86_spin_lock_init(spinlock_t * lock){lock->lock = 0;//锁值初始化为0是未加锁状态}//加锁函数static inline void x86_spin_lock(spinlock_t * lock){__asm__ __volatile__ ("1: \n""lock; xchg %0, %1 \n"//把值为1的寄存器和lock内存中的值进行交换"cmpl $0, %0 \n" //用0和交换回来的值进行比较"jnz 2f \n" //不等于0则跳转后面2标号处运行"jmp 3f \n" //若等于0则跳转后面3标号处返回"2: \n""cmpl $0, %1 \n"//用0和lock内存中的值进行比较"jne 2b \n"//若不等于0则跳转到前面2标号处运行继续比较"jmp 1b \n"//若等于0则跳转到前面1标号处运行,交换并加锁"3: \n" :: "r"(1), "m"(*lock));}//解锁函数static inline void x86_spin_unlock(spinlock_t * lock){__asm__ __volatile__("movl $0, %0\n"//解锁把lock内存中的值设为0就行:: "m"(*lock));}
其中加锁函数的逻辑部分要好好理解,它通过转移指令形成了一个循环判断的逻辑,直到加锁才会退出。
注意,代码中汇编部分: : “r”(1), “m”(*lock)——系统分配一个寄存器,填入1;取内存地址为lock的值;而后xchg %0,%1即是将两者的值进行交换。
遗憾的是上述代码存在中断嵌套的问题:“如果一个CPU获取自旋锁后发生中断,中断代码里也尝试获取自旋锁,那么自旋锁永远不会被释放,发生死锁。”
关于自旋锁与中断的详细解释可以参考:Linux内核死锁,其中关于自旋锁与中断嵌套导致的一个经典场景叙述如下:
“考虑下面的场景(中断上下文场景):
- 运行在CPU0上的进程A在某个系统调用过程中访问了共享资源 R
- 运行在CPU1上的进程B在某个系统调用过程中也访问了共享资源 R
- 外设P的中断handler中也会访问共享资源 R
在这样的场景下,使用spin lock可以保护访问共享资源R的临界区吗?
我们假设CPU0上的进程A持有spin lock进入临界区,这时候,外设P发生了中断事件,并且调度到了CPU1上执行,看起来没有什么问题,执行在CPU1上的handler会稍微等待一会CPU0上的进程A,等它离开临界区就会释放spin lock的,但是,如果外设P的中断事件被调度到了同一个CPU0上执行会怎么样?
CPU0上的进程A在持有spin lock的状态下被中断上下文抢占,而抢占它的CPU0上的handler在进入临界区之前仍然会试图获取spin lock,悲剧发生了,CPU0上的P外设的中断handler永远的进入spin状态,这时候,CPU1上的进程B也不可避免在试图持有spin lock的时候失败而导致进入spin状态。
为了解决这样的问题,linux kernel采用了这样的办法:如果涉及到中断上下文的访问,spin lock需要和禁止本 CPU 上的中断联合使用。 ”
关于这一点的解决方式可以参考关中断,详细讲解请看:08 锁。提示一下,获取自旋锁的时候,干脆把中断关闭了就好,这样就不会导致中断嵌套。
经修改后,可以实现关中断下获取自旋锁,以及恢复中断状态释放自旋锁:
static inline void x86_spin_lock_disable_irq(spinlock_t * lock,cpuflg_t* flags){__asm__ __volatile__("pushfq \n\t""cli \n\t""popq %0 \n\t""1: \n\t""lock; xchg %1, %2 \n\t""cmpl $0,%1 \n\t""jnz 2f \n\t""jmp 3f \n""2: \n\t""cmpl $0,%2 \n\t""jne 2b \n\t""jmp 1b \n\t""3: \n":"=m"(*flags): "r"(1), "m"(*lock));}static inline void x86_spin_unlock_enabled_irq(spinlock_t* lock,cpuflg_t* flags){__asm__ __volatile__("movl $0, %0\n\t""pushq %1 \n\t""popfq \n\t":: "m"(*lock), "m"(*flags));}
代码中的cpuflg表示当前的中断状态。
信号量
以上三种解决同步的方式都不适合长等待,利用自旋锁这种方式去获取需要一定时间准备的资源,并且会造成CPU的时间消耗。
试想,能不能有一种机制,当资源准备好了之后,提醒CPU去获取呢?
还真有,那就是在1965年由荷兰学者Edsger Dijkstra(没错,就是提出那个算法的男人)提出的信号量机制。
信号量机制由三个环节组成:
- 等待:程序等待资源准备好
- 互斥:同时只有一个程序可以访问资源
- 唤醒:资源准备好之后唤醒固定程序
由于需要等待、互斥等操作,拟定一个数据结构如下:
//等待链数据结构,用于挂载等待代码执行流(线程)的结构//里面有用于挂载代码执行流的链表和计数器变量,后续会讲typedef struct s_KWLST{spinlock_t wl_lock;//等待链表的锁uint_t wl_tdnr;//计数器list_h_t wl_list;//等待进程的链表}kwlst_t;//信号量数据结构typedef struct s_SEM{spinlock_t sem_lock;//维护sem_t自身数据的自旋锁uint_t sem_flg;//信号量相关的标志sint_t sem_count;//信号量计数值kwlst_t sem_waitlst;//用于挂载等待代码执行流(线程)结构}sem_t;
想想信号量一般是怎么使用的呢?
- 获取信号量
将信号量自身加锁,如果信号值sem_count小于0,则将当前进程放入等待链;否则,对信号量执行“减一”,获取信号量成功,进入代码执行流程;
2. 代码执行
成功获取信号量之后,程序进行自己相应的操作逻辑。
3. 释放信号量
将信号量自身加锁,对信号值sem_count执行“加一”,如果大于0,则从等待链中唤醒一个进程;无论是否大于0,最终即完成信号量的释放
从上述流程可以看出,信号量其实就是一个“多人使用,用完放回”的场景。
根据以上分析一个简单的信号量实现如下:
//获取信号量void krlsem_down(sem_t* sem){cpuflg_t cpufg;start_step://之前自旋锁的封装krlspinlock_cli(&sem->sem_lock,&cpufg);if(sem->sem_count<1){//如果信号量值小于1,则让代码执行流(线程)睡眠krlwlst_wait(&sem->sem_waitlst);//之前自旋锁的封装krlspinunlock_sti(&sem->sem_lock,&cpufg);//切换代码执行流,下次恢复执行时依然从下一行开始执行//所以要goto开始处重新获取信号量进行判断krlschedul();goto start_step;}sem->sem_count--;//信号量值减1,表示成功获取信号量//之前自旋锁的封装krlspinunlock_sti(&sem->sem_lock,&cpufg);return;}//释放信号量void krlsem_up(sem_t* sem){cpuflg_t cpufg;//之前自旋锁的封装krlspinlock_cli(&sem->sem_lock,&cpufg);sem->sem_count++;//释放信号量if(sem->sem_count<1){//如果小于1,则说数据结构出错了,挂起系统krlspinunlock_sti(&sem->sem_lock,&cpufg);hal_sysdie("sem up err");}//唤醒该信号量上所有等待的代码执行流(线程)krlwlst_allup(&sem->sem_waitlst);krlspinunlock_sti(&sem->sem_lock,&cpufg);krlsched_set_schedflgs();return;}
其中krlschedul、krlwlst_wait、krlwlst_allup、krlsched_set_schedflgs是负责进程调度的相关函数,会在之后的进程章节进行讲解,敬请期待!
拓展:Linux的同步机制
Linux上实现数据同步主要有五个工具:原子变量、中断控制、自旋锁、信号量、读写锁。重点如下:
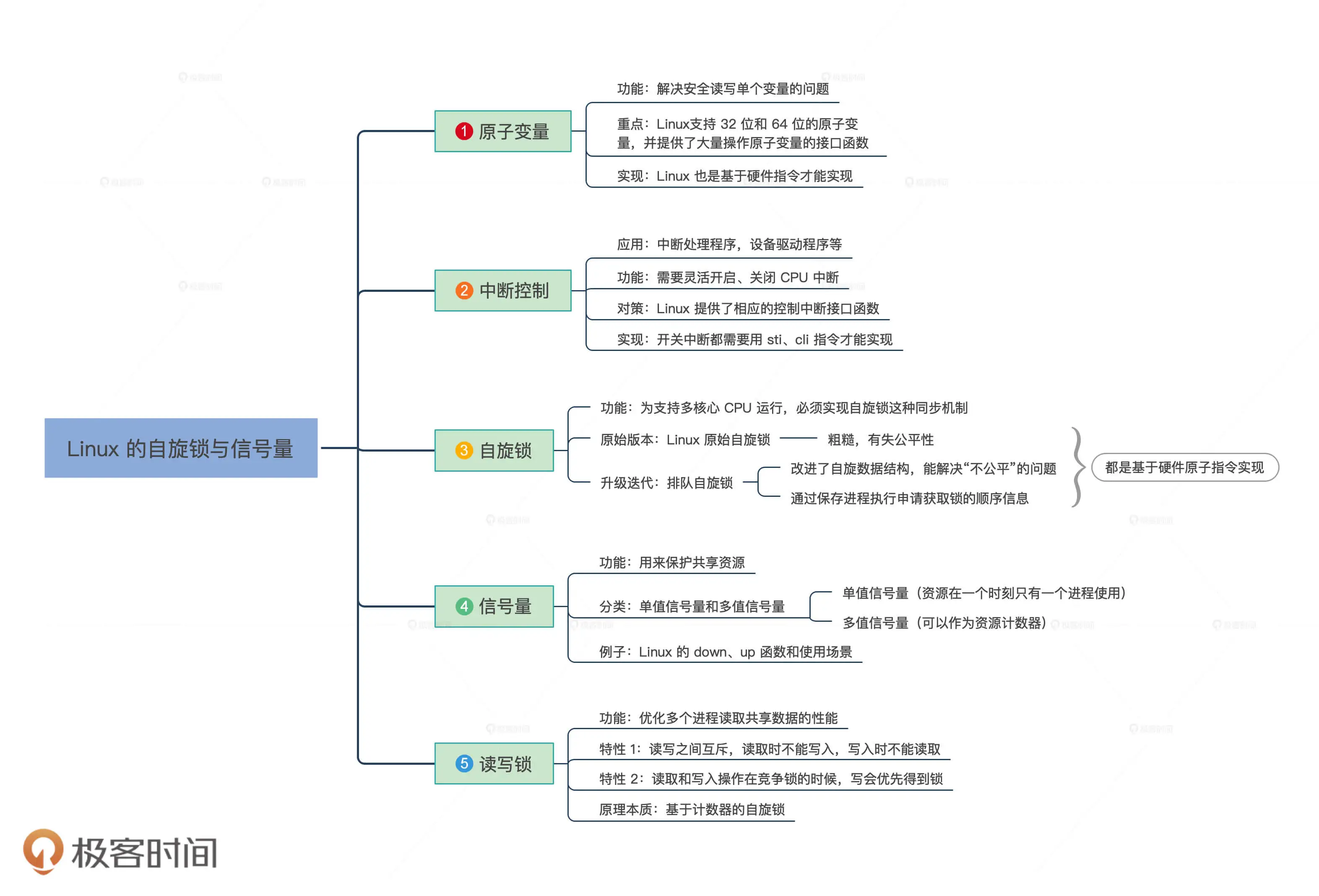
有关这部分的实现代码及讲解可以参考:09. Linux锁机制。
补充:GCC内嵌汇编代码
在 C 代码中嵌入汇编语句要比”纯粹”的汇编语言代码复杂得多,因为需要解决如何分配寄存器,以及如何与C代码中的变量相结合等问题。
通常嵌入到 C 代码中的汇编语句很难做到与其它部分没有任何关系,因此很多时候需要用到完整的内联汇编格式:
__asm__("asm statements" : outputs : inputs : registers-modified);
内嵌汇编格式分为四个部分,其中每个部分用“:”符号来隔断,每个部分中的各个操作用“;”来区分。
- asm statements:汇编代码部分,即指令部分,操作寄存器需要带上%,操作立即数需要带上$;
- output:输出列表部分,包括寄存器、内存,=号来连接;
- Input:输入列表部分,包括寄存器、内存、立即数等;
- register-modified:寄存器修改列表部分,这些寄存器在汇编代码中使用了,但是不属于输入和输出列表,因此对寄存器进行说明,以便GCC能够采用相应的措施,比如不用它们来保存其他的数据。
我们以下面的代码为例:
int main(){int a = 10, b = 0;__asm__ __volatile__(;这两行都是指令部分,%1、%0分别表示操作第二个、第一个“样板”操作数"movl %1, %%eax;\\n\\r""movl %%eax, %0;";从输出部分开始计数,这就是第一个“样板”操作数:b;不过标号为0:"=r"(b);这是输入部分,第二个样板操作数:a,标号为1:"r"(a);这是修改寄存器部分,由于用到了eax,告诉gcc在执行过程中该寄存器不能;保存其他值:"%eax");printf("Result: %d, %d\\n", a, b);}
上述代码完成操作:将a的值赋值给b。
参考链接

若有收获,就点个赞吧
0 人点赞
