由于随机森林里有决策树相关的知识,因此先对决策树的知识进行学习
简介
简单点说就是,决策树是一种类似于流程图的结构,其中每个内部节点代表在某一个特征上的“判断”(例如,一个硬币是正面还是反面),每个分支代表判断的结果,每个叶节点代表一个类标签(计算所有属性后做出的决定)。从根到叶的路径表示分类规则。
为了进一步帮助大家了解决策树,我们用titanic数据来预测一个乘客是否能生存,我们选用具有三个特征的数据集, 即性别、年龄和sibsp(配偶或子女的数量)。决策树算法结构如下:

那么到底是如何决策的呢?
假设有一个乘客:jack,年龄5岁,男,无子女。根据决策树的脉络,最后的结果就是生还!
决策树,就是一个显性构造决策逻辑过程
构造过程
决策树学习算法包含特征选择、决策树生成与决策树的剪枝。决策树的生成是局部最优,而决策树的剪枝则是全局最优。构造决策树的过程用一句话来说就是,寻找当前数据集特征中,最重要的一个特征,而后根据这个特征将这个数据集分为两类,之后再在分类的数据集中继续寻找下一个重要特征,直到判断完所有的特征,也就获得了最终的决策树。
因此核心的问题就是,如何寻找最重要的特征?
——主要有两种,一个是基于信息熵增益的ID3决策树;
——另一个是基于基尼系数的CART决策树;
ID3
以下面这个数据集为例,年龄、工作情况、房子情况、信贷情况这四个特征,决定着某位客户最终能否成功贷款:

在进行下一步之前,先学一些概念:

信息熵越大,表示某一个信息越复杂,越不确定;


ID3决策树,就是采用信息增益(知道这个信息,对于最后的判断有多大的作用)来确定最优特征的,计算过程如下:
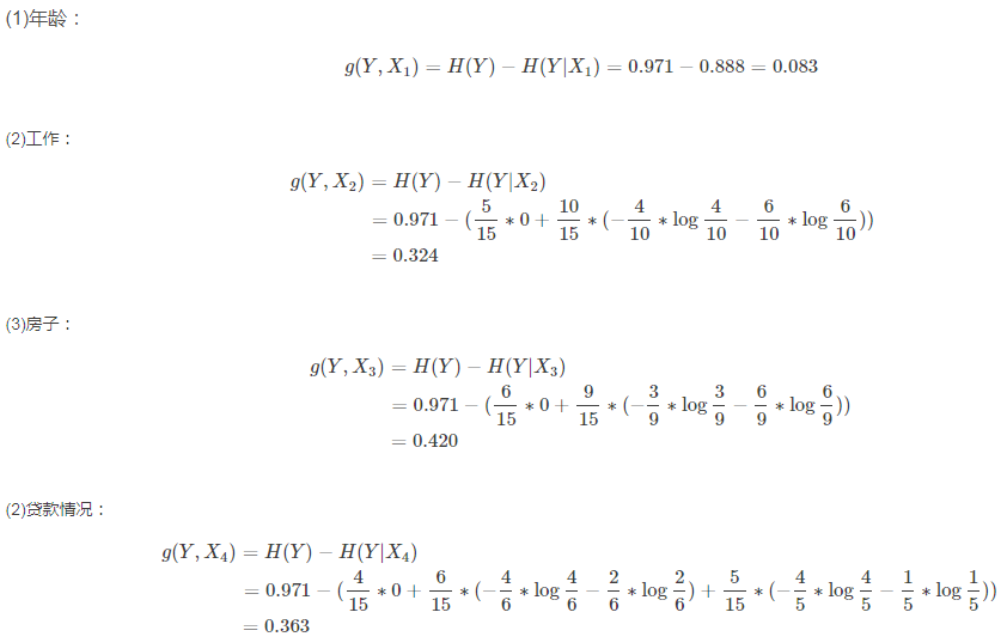
从上可以看到,房子这一特征所提供的信息增益是最大的:因此决策树的第一层的判断特征就出来了——房子。按照这种方式,递归下去,直到找完最后的特征值之后(或者达到指定的决策树层数),决策树就成型了,比如二层决策树:

C4.5
C4.5算法与ID3算法在整体流程上很相似,不同之处在于特征选择用的是信息增益比,然后最后有剪枝的过程。依据信息增益率,我们来计算上述例子:
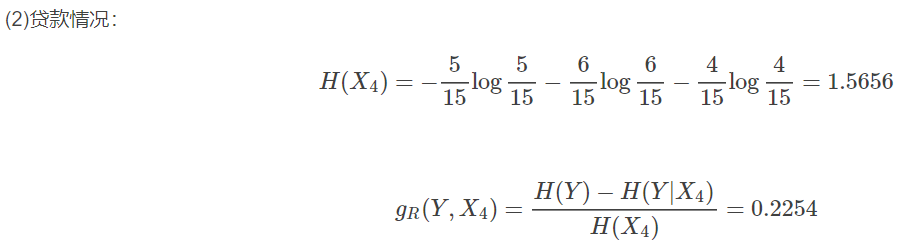
最大的信息增益比还是房子因素。
CART与剪枝
CART算法主要有两部分组成:(1) 决策树的生成:基于训练数据集生成决策树,生成的决策树要尽量大。这与ID3算法类似,不同之处也是特征选取的方式,选择的是最小基尼指数;
(2) 决策树的剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,此时用损失函数最小作为剪枝的标准。
CART算法可以用于回归,即建立回归树。在终于分类时,其算法流程与ID3较为类似。
那么为什么需要剪枝呢?
策树生成算法是递归地生成决策树,知道不能继续下去。 这样产生的决策树往往分类精细,对训练数据集分类准确,但是对未知数据集却没有那么准确,有比较严重的过拟合问题。因此,为了简化模型的复杂度,使模型的泛化能力更强,需要对已生成的决策树进行剪枝,即减除掉细枝末节的特征判断。如何进行剪枝?

如何理解上述公式?
后面的|T|其实就是于正则化惩罚。——即结构风险,削减参数数量,防止过拟合;
前面其实是经验风险。——利用条件熵计算整个决策树的确定性,一颗好的决策树,其确定性一定是极好的,其叶子节点理想情况下只有一类结果(因为完全确定了)。借用熵的概念,那么此时叶子节点的熵应该为-1*log1(只有一类结果,则概率为1),而一旦没有完全分类成功,则熵不为0。
考虑到不同的节点上,样本的数目不一样,才乘以了Nt来给每一个节点加上一个权重。
理想情况下的决策树如下:
而实际情况下,每一个叶子节点都会有多个输出类别。
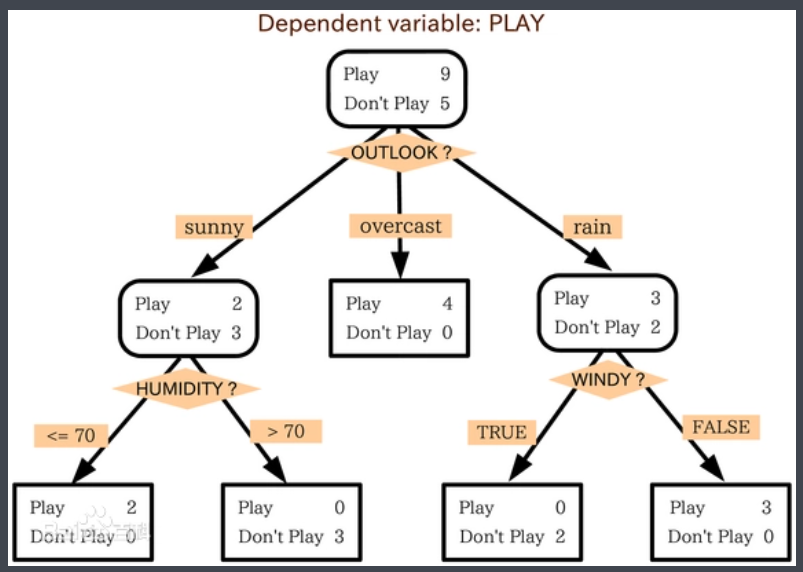
代码实现/参考链接

若有收获,就点个赞吧
0 人点赞
