前言
这一章深入了解内存有关知识,先学习一种划分内存与表示内存的方法,而后根据之前的内存页表示方法来研究内存分配释放算法。
内存的划分与组织
有关究竟内存是采用分段还是分页的讨论,在第五章CPU工作模式中已经讨论过了。
简而言之,内存采取分段的方式,一是不利于对内存状态进行表示,二是分段会产生较大的内存碎片,三是内存与硬盘的交换效率较低。
我们之后对内存相关的代码和研究都是基于4KB分页的内存模型(CPU长模式下,64位)。
内存页的表示
逻辑上内存结构如下:

不过要注意,真实的地址空间是有空洞的,不是连续的,在第五章已经通过INT 15H中断获取了计算机的内存视图(e820map_t 结构数组已转换到phymmarge_t 结构数组),其中内存每一页都是4K对齐的,现在考虑第一个问题——如何表示一个内存页?
如果用类似位图的方式来表示一个内存页已经被使用或者未被使用,比如标为1表示未被使用,为0表示已被使用。那么后续有关内存的分配算法等只能够采用最简单的遍历方式,但是效率却并不符合实际使用。
在实际的内存管理方式设计中,一个内存页的表示不仅要考虑它的状态(是否被分配),还要考虑到页的地址、分配次数、页的类型等,以结构的方式表示如下:
//内存空间地址描述符标志typedef struct s_MSADFLGS{u32_t mf_olkty:2; //挂入链表的类型u32_t mf_lstty:1; //是否挂入链表u32_t mf_mocty:2; //分配类型,被谁占用了,内核还是应用或者空闲u32_t mf_marty:3; //属于哪个区u32_t mf_uindx:24; //分配计数}__attribute__((packed)) msadflgs_t;//物理地址和标志typedef struct s_PHYADRFLGS{u64_t paf_alloc:1; //分配位u64_t paf_shared:1; //共享位u64_t paf_swap:1; //交换位u64_t paf_cache:1; //缓存位u64_t paf_kmap:1; //映射位u64_t paf_lock:1; //锁定位u64_t paf_dirty:1; //脏位u64_t paf_busy:1; //忙位u64_t paf_rv2:4; //保留位u64_t paf_padrs:52; //页物理地址位}__attribute__((packed)) phyadrflgs_t;//内存空间地址描述符typedef struct s_MSADSC{list_h_t md_list; //链表spinlock_t md_lock; //保护自身的自旋锁msadflgs_t md_indxflgs; //内存空间地址描述符标志phyadrflgs_t md_phyadrs; //物理地址和标志void* md_odlink; //相邻且相同大小msadsc的指针}__attribute__((packed)) msadsc_t;
注意到上述masdsc_t结构占用的内存很小,这是因为每一个内存页就有一个这样的结构,它必须得小。另外,在物理地址和标志中,低12位被用作它用,这是由于内存页4K对齐。
内存分区
为了便于对内存的管理,以及不同内存区域功能的区分,我们通常会在逻辑上对内存进行分区,如下:
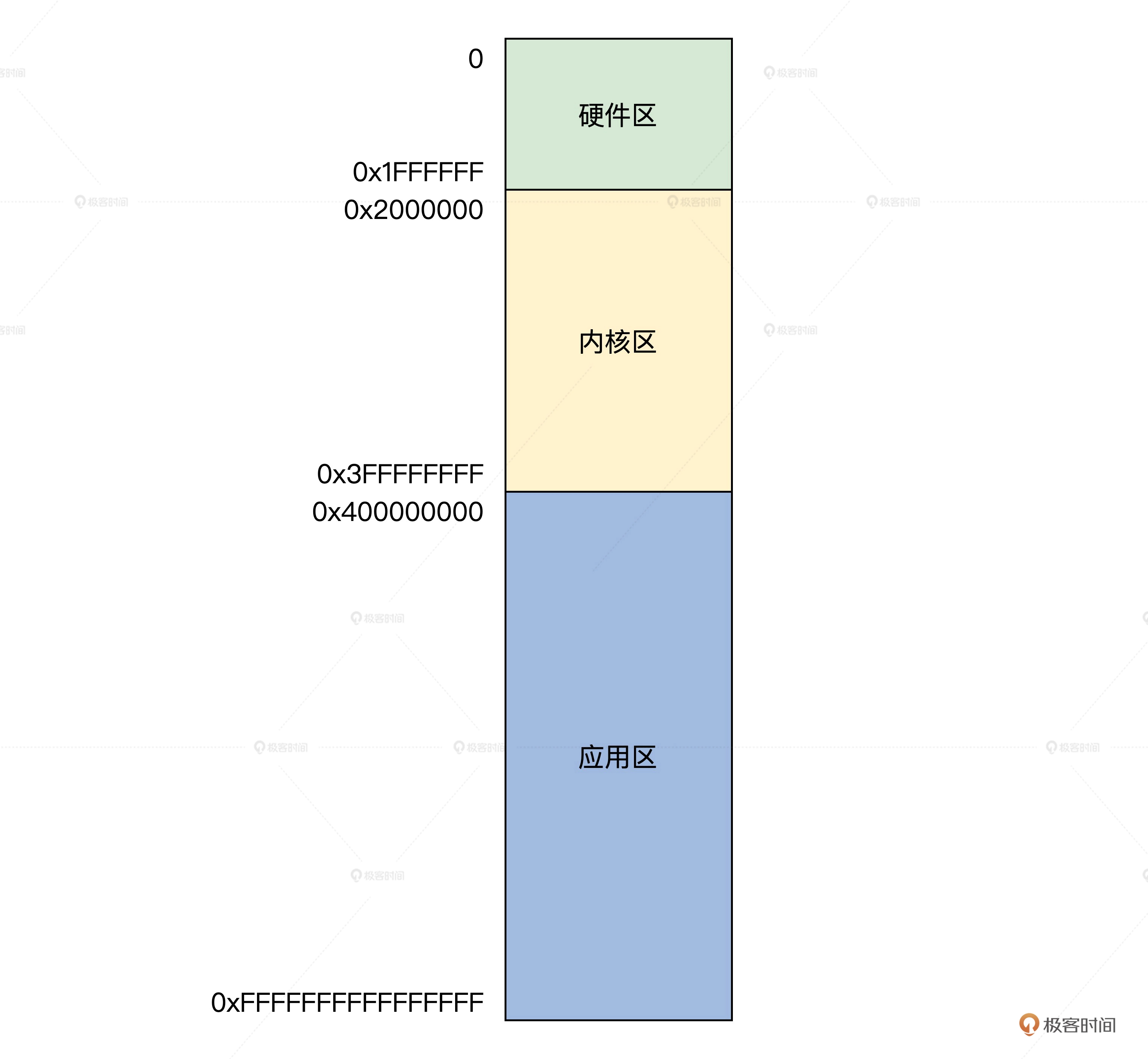
其中,硬件区位于低32MB空间,这个地址空间是给硬件使用的,它主要是提供给一些能够直接和内存交换数据的硬件,这些硬件不通过MMU进行虚拟地址到物理地址的转换,而是直接与物理地址打交道。
比较常见的是就是DMA访问内存,它只能访问低于24MB的物理内存,还有一些其他硬件也是如此,那么我们在分配内存的时候,就不应该将一部分低位内存分配出去。
之后的内存区,主要是考虑到内核也是运行在虚拟地址空间,将内核所使用的地址空间与物理地址空间一一对应,可以提高内存的运行效率。另外,有时需要在内核中分配连续、大块的内存,比如内核栈、显卡驱动等。总之,给内核单独分配一块区域具有很大的作用。
应用区,就是留给用户态程序所使用的内存区域了,这部分内存根据应用程序的需要,按需分配,如果访问到一个还没有与物理地址建立映射关系的虚拟地址时,会产生缺页异常,操作系统响应这个异常为其分配对应的物理内存页,从而达到“按需分配”。
那么如何表示一个内存区呢?其实无外乎内存页的状态,内存区的开始与结束物理地址等属性,用一个结构体来表示:
typedef struct s_MEMAREA{list_h_t ma_list; //内存区自身的链表spinlock_t ma_lock; //保护内存区的自旋锁uint_t ma_stus; //内存区的状态uint_t ma_flgs; //内存区的标志uint_t ma_type; //内存区的类型sem_t ma_sem; //内存区的信号量wait_l_head_t ma_waitlst; //内存区的等待队列uint_t ma_maxpages; //内存区总的页面数uint_t ma_allocpages; //内存区分配的页面数uint_t ma_freepages; //内存区空闲的页面数uint_t ma_resvpages; //内存区保留的页面数uint_t ma_horizline; //内存区分配时的水位线adr_t ma_logicstart; //内存区开始地址adr_t ma_logicend; //内存区结束地址uint_t ma_logicsz; //内存区大小//还有一些结构我们这里不关心。后面才会用到}memarea_t;
这些标志现在不会讲,继续往后看就懂了,现在只需要了解有这些属性就够了。
现在思考一个问题——如何将内存区域内存页相关联起来?
组织内存页
由于内存页是用msadsc_t结构体来表示的,组织内存页,即是找到一个合理、高效地方式来组织msadsc_t结构体。
注意到msadsc_t结构体中有链表,那么用链表串起来?——遍历链表跟遍历位图没有多大区别。
在讲解代码的时候,先以一副图来表示如何在内存区memarea_t中组织内存页msadsc_t:

我们在内存区中新建一个新的结构体——memdivmer_t,意指内存的分割与合并,分割即是将内存分配出去,合并即是内存被释放之后的回收。
memdivmer_t结构体中有一个dm_mdmlielst指针指向bafhlst_t结构体数组。
而bafhlst_t链表将内存页msadsc_t用链表串联起来,并且每一个bafhlst_链表所拥有的内存页msadsc_t数量是不一样的,分别是0,2,4,6,……2^(n-1),其中n是该bafhlst结构体在dm_mdmlielst数组中的下标!
为什么要用这样的方式来组织内存页呢?
需要注意的是,对于每一个bafhlst_t链表中的msadsc_t我们并不在意其中第一个 msadsc_t 结构对应的内存物理地址从哪里开始,但是第一个 msadsc_t 结构与最后一个 msadsc_t 结构,它们之间的内存物理地址是连续的。
举个例子,对于dm_mdmlielst数组第0个bafhlst,它挂载一个msadsc_t结构体,其内存地址可以是0x4000~0x5FFF;
对于dm_mdmlielst数组第1个bafhlst,它挂载2个msadsc_t结构体,其内存地址可以是0x101000~0x102FFF, 0x103000~0x104FFF,即是0x101000~0x4FFF的连续区域;
……
对于dm_mdmlielst数组第n个bafhlst,它挂载2^(n-1)个msadsc_t结构体,其内存地址也是一段连续区域;
通过这种方式,我们可以对内存中较大/较小的连续区域分别进行组织,减小了内存碎片出现的可能。
其中上述两个结构体的实现代码分别如下:
typedef struct s_BAFHLST{spinlock_t af_lock; //保护自身结构的自旋锁u32_t af_stus; //状态uint_t af_oder; //页面数的位移量uint_t af_oderpnr; //oder对应的页面数比如 oder为2那就是1<<2=4uint_t af_fobjnr; //多少个空闲msadsc_t结构,即空闲页面uint_t af_mobjnr; //此结构的msadsc_t结构总数,即此结构总页面uint_t af_alcindx; //此结构的分配计数uint_t af_freindx; //此结构的释放计数list_h_t af_frelst; //挂载此结构的空闲msadsc_t结构list_h_t af_alclst; //挂载此结构已经分配的msadsc_t结构}bafhlst_t;……#define MDIVMER_ARR_LMAX 52typedef struct s_MEMDIVMER{spinlock_t dm_lock; //保护自身结构的自旋锁u32_t dm_stus; //状态uint_t dm_divnr; //内存分配次数uint_t dm_mernr; //内存合并次数bafhlst_t dm_mdmlielst[MDIVMER_ARR_LMAX];//bafhlst_t结构数组bafhlst_t dm_onemsalst; //单个的bafhlst_t结构}memdivmer_t;
在下一节的分配、释放内存中,我们将会研究为什么这样的组织内存页。
内存的分配与释放
内存分配
也许你会想象内存分配是这么进行的:在一段循环代码中,遍历所有的内存页,而后将一个空闲的内存页返回即可。
但是现实是,内存管理器需要为内核、驱动、应用程序提供复杂的内存服务——需要多少内存页?内存页需不需要连续?物理地址是否有要求?……
由于这些现实问题的存在,关于内存的分配和释放不能采取上述简单遍历的方式。
有关这部分的代码详见代码仓库,下面是我梳理出的一个函数调用逻辑图:
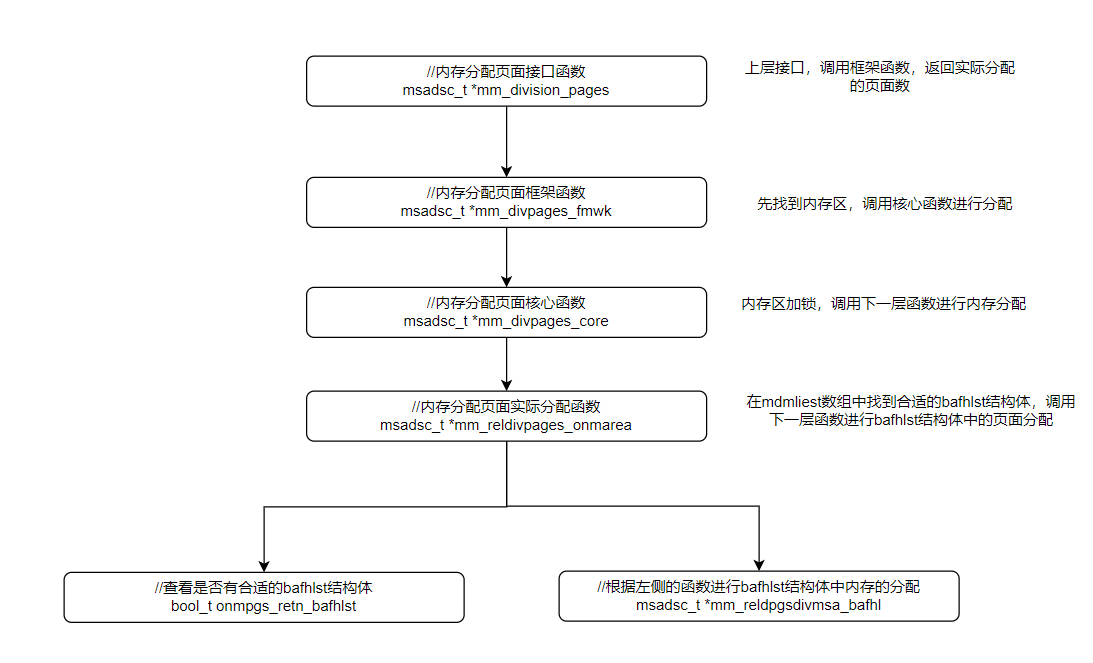
其实整个内存分配阶段最重要的部分就是如何从dm_mdmlielst数组中找到合适的bafhlst_t结构体,因为如果找到的bafhlst_t结构体中内存页msadsc_t过大,就会产生内存碎片,不利于下次内存的分配;如果找到的bafhlst_t结构体中内存页msadsc_t过小,就需要多个bafhlst_t结构体组合完成这次分配,效率又不高。
这部分的逻辑在两个函数里,一个是对dm_mdmlielst数组中根据下标遍历找到合适的bafhlst_t:
//找到合适的bafhlst_tbool_t onmpgs_retn_bafhlst(memarea_t *malckp, uint_t pages, bafhlst_t **retrelbafh, bafhlst_t **retdivbafh){//获取bafhlst_t结构数组的开始地址bafhlst_t *bafhstat = malckp->ma_mdmdata.dm_mdmlielst;//根据分配页面数计算出分配页面在dm_mdmlielst数组中下标sint_t dividx = retn_divoder(pages);//从第dividx个数组元素开始搜索for (sint_t idx = dividx; idx < MDIVMER_ARR_LMAX; idx++){//如果第idx个数组元素对应的一次可分配连续的页面数大于等于请求的页面数//,且其中的可分配对象大于0则返回if (bafhstat[idx].af_oderpnr >= pages &&0 < bafhstat[idx].af_fobjnr){//返回请求分配的bafhlst_t结构指针*retrelbafh = &bafhstat[dividx];//返回实际分配的bafhlst_t结构指针*retdivbafh = &bafhstat[idx];return TRUE;}}*retrelbafh = NULL;*retdivbafh = NULL;return FALSE;}
二是,处理获取到的bafhlst_t结构体,根据实际需要的内存大小,有可能需要对其进行拆分,将其剩下的部分挂载其他的bafhlst_t上:
msadsc_t *mm_reldpgsdivmsa_bafhl(memarea_t *malckp, uint_t pages, uint_t *retrelpnr, bafhlst_t *relbfl, bafhlst_t *divbfl){msadsc_t *retmsa = NULL;bool_t rets = FALSE;msadsc_t *retmstat = NULL, *retmend = NULL;//处理相等的情况if (relbfl == divbfl){//从bafhlst_t结构中获取msadsc_t结构的开始与结束地址rets = mm_retnmsaob_onbafhlst(relbfl, &retmstat, &retmend);//设置msadsc_t结构的相关信息表示已经删除retmsa = mm_divpages_opmsadsc(retmstat, relbfl->af_oderpnr);//返回实际的分配页数*retrelpnr = relbfl->af_oderpnr;return retmsa;}//处理不等的情况//从bafhlst_t结构中获取msadsc_t结构的开始与结束地址rets = mm_retnmsaob_onbafhlst(divbfl, &retmstat, &retmend);uint_t divnr = divbfl->af_oderpnr;//从高bafhlst_t数组元素中向下遍历for (bafhlst_t *tmpbfl = divbfl - 1; tmpbfl >= relbfl; tmpbfl--){//开始分割连续的msadsc_t结构,把剩下的一段连续的msadsc_t结构加入到对应该bafhlst_t结构中if (mrdmb_add_msa_bafh(tmpbfl, &retmstat[tmpbfl->af_oderpnr], (msadsc_t *)retmstat->md_odlink) == FALSE){system_error("mrdmb_add_msa_bafh fail\n");}retmstat->md_odlink = &retmstat[tmpbfl->af_oderpnr - 1];divnr -= tmpbfl->af_oderpnr;}retmsa = mm_divpages_opmsadsc(retmstat, divnr);if (NULL == retmsa){*retrelpnr = 0;return NULL;}*retrelpnr = relbfl->af_oderpnr;return retmsa;}
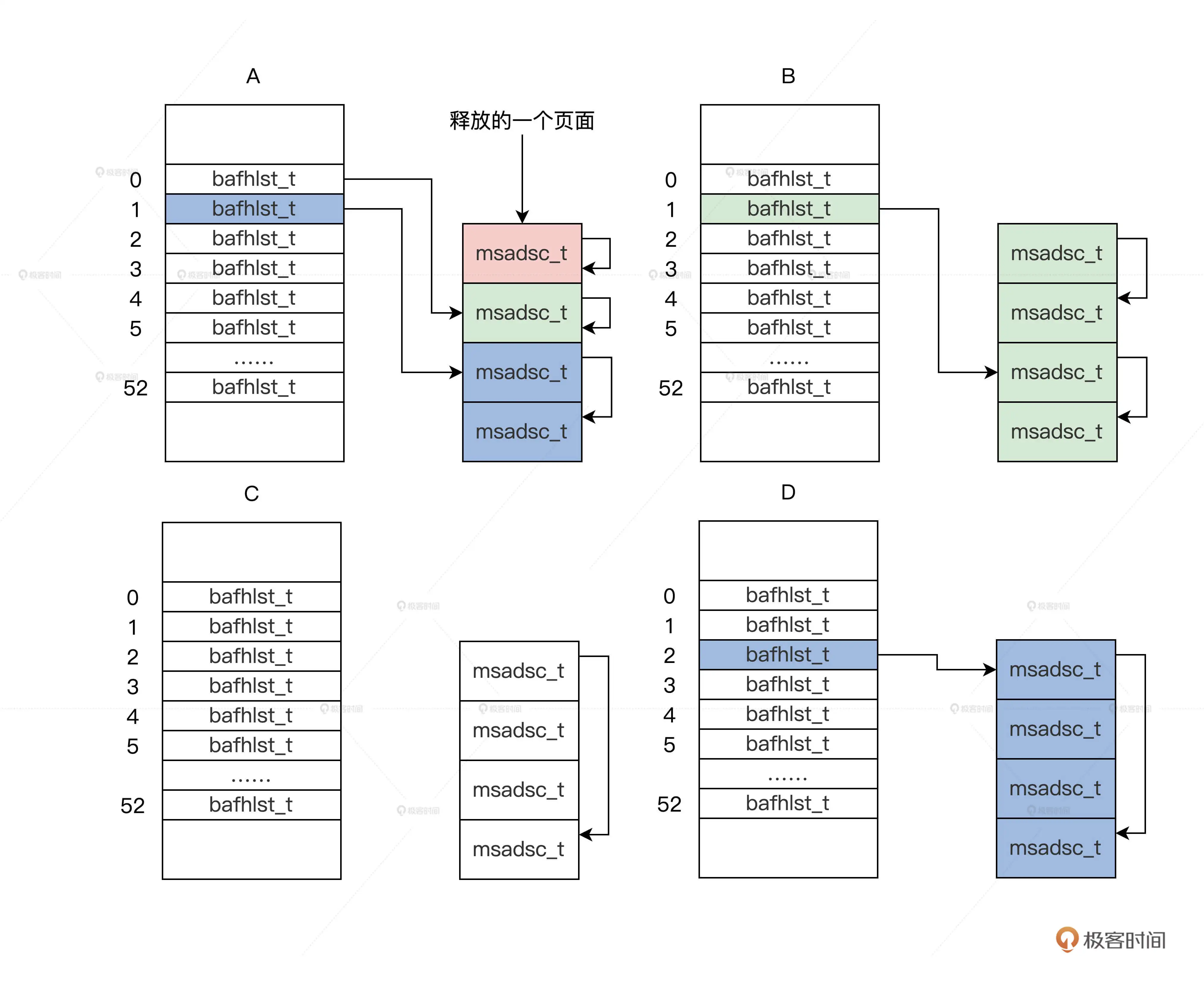
以彭老师所举的例子来解释一下这个过程:比如现在我们需要分配一个页面,这个算法将执行如下步骤:
根据一个页面的请求,会返回 m_mdmlielst 数组中的第 0 个 bafhlst_t 结构(第0个bafhlst_t结构中挂载了一个内存页)。
如果第 0 个 bafhlst_t 结构中有 msadsc_t 结构就直接返回,若没有 msadsc_t 结构(即这个bafhlst_t中的msadsc_t结构已经被用完了),就会继续查找 m_mdmlielst 数组中的第 1 个 bafhlst_t 结构。
如果第 1 个 bafhlst_t 结构中也没有 msadsc_t 结构,就会继续查找 m_mdmlielst 数组中的第 2 个 bafhlst_t 结构。
如果第 2 个 bafhlst_t 结构中有 msadsc_t 结构,记住第 2 个 bafhlst_t 结构中对应是 4 个连续的 msadsc_t 结构。这时让这 4 个连续的 msadsc_t 结构从第 2 个 bafhlst_t 结构中脱离。
把这 4 个连续的 msadsc_t 结构,对半分割成 2 个双 msadsc_t 结构,把其中一个双 msadsc_t 结构挂载到第 1 个 bafhlst_t 结构中。
把剩下一个双 msadsc_t 结构,继续对半分割成两个单 msadsc_t 结构,把其中一个单 msadsc_t 结构挂载到第 0 个 bafhlst_t 结构中,剩下一个单 msadsc_t 结构返回给请求者,完成内存分配。
整个过程如下图所示:
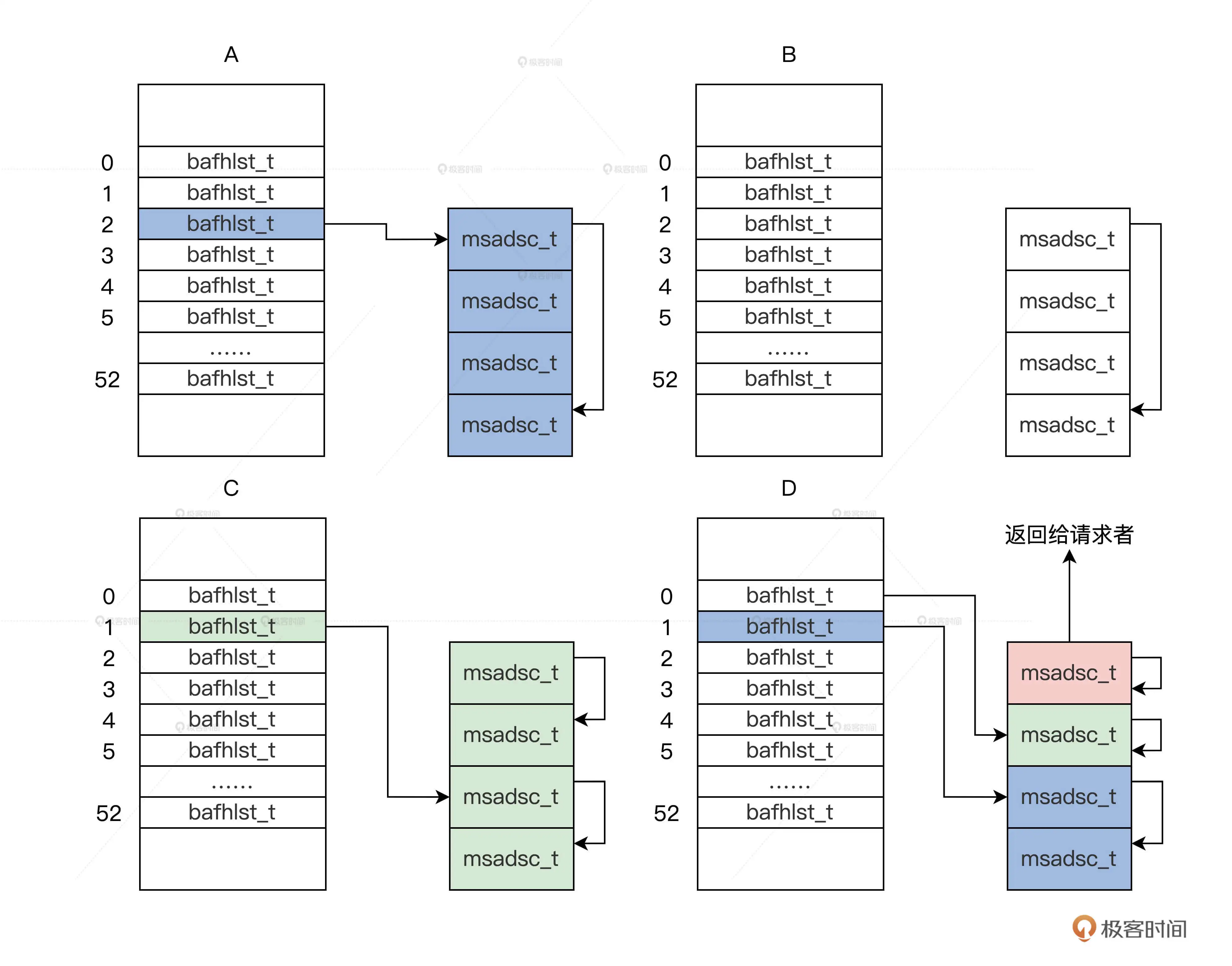
结合上面的代码、过程解释、流程图,现在我们对内存分配的具体过程有了较为详细的理解:如果当前下标的bafhlst_t中的msadsc结构不够,那就继续往后查,如果用不完当前bafhlst结构体中的msadsc还有剩余,就挂载到其之前的bafhlst_t结构体中。
内存释放
内存的释放过程,其实是内存分配的逆过程。因为代码量太多,这里同样不放出具体的代码,详情可见cosmos/hal/x86/memdivmer.c,我梳理出的函数调用逻辑如下:
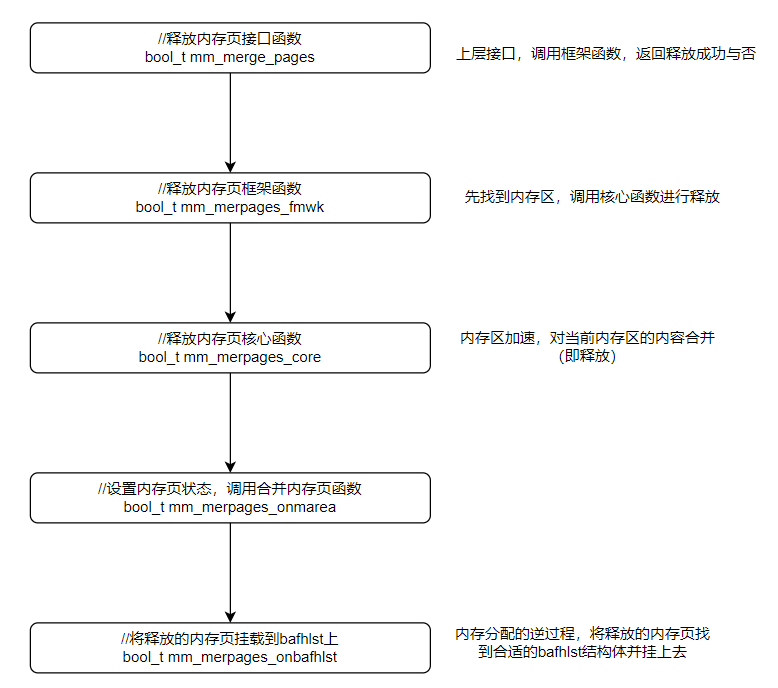
而在这个调用逻辑中,重点则是理解最后一个函数——如何将释放的内存页放到合适的bafhlst_t上呢?
先来看看代码:
bool_t mm_merpages_onbafhlst(msadsc_t *freemsa, uint_t freepgs, bafhlst_t *relbf, bafhlst_t *merbf){sint_t rets = 0;msadsc_t *mnxs = freemsa, *mnxe = &freemsa[freepgs - 1];bafhlst_t *tmpbf = relbf;//从实际要开始遍历,直到最高的那个bafhlst_t结构for (; tmpbf < merbf; tmpbf++){//查看最大地址连续、且空闲msadsc_t结构//如释放的是第0个msadsc_t结构我们就去查找第1个msadsc_t结构是否空闲//,且与第0个msadsc_t结构的地址是不是连续的rets = mm_find_cmsa2blk(tmpbf, &mnxs, &mnxe);if (1 == rets){break;}}//把合并的msadsc_t结构(从mnxs到mnxe)加入到对应的bafhlst_t结构中if (mpobf_add_msadsc(tmpbf, mnxs, mnxe) == FALSE){return FALSE;}return TRUE;}bool_t mpobf_add_msadsc(bafhlst_t *bafhp, msadsc_t *freemstat, msadsc_t *freemend){freemstat->md_indxflgs.mf_olkty = MF_OLKTY_ODER;//设置起始页面指向结束页freemstat->md_odlink = freemend;freemend->md_indxflgs.mf_olkty = MF_OLKTY_BAFH;//结束页面指向所属的bafhlst_t结构freemend->md_odlink = bafhp;//把起始页面挂载到所属的bafhlst_t结构中list_add(&freemstat->md_list, &bafhp->af_frelst);//增加bafhlst_t结构的空闲页面对象和总的页面对象的计数bafhp->af_fobjnr++;bafhp->af_mobjnr++;return TRUE;}
参考彭老师的例子来解释这个过程:比如,现在我们要释放一个页面,这个算法将执行如下步骤。
- 释放一个页面,会返回 m_mdmlielst 数组中的第 0 个 bafhlst_t 结构。
- 设置这个页面对应的 msadsc_t 结构的相关信息,表示已经执行了释放操作。
- 开始查看第 0 个 bafhlst_t 结构中有没有空闲的 msadsc_t,并且它和要释放的 msadsc_t 对应的物理地址是连续的。没有则把这个释放的 msadsc_t 挂载第 0 个 bafhlst_t 结构中,算法结束,否则进入下一步(即有空闲的msadsc并且地址连续)。
- 把第 0 个 bafhlst_t 结构中的 msadsc_t 结构拿出来与释放的 msadsc_t 结构,合并成 2 个连续且更大的 msadsc_t。
- 继续查看第 1 个 bafhlst_t 结构中有没有空闲的 msadsc_t,而且这个空闲 msadsc_t 要和上一步合并的 2 个 msadsc_t 对应的物理地址是连续的。没有则把这个合并的 2 个 msadsc_t 挂载第 1 个 bafhlst_t 结构中,算法结束,否则进入下一步。
- 把第 1 个 bafhlst_t 结构中的 2 个连续的 msadsc_t 结构,还有合并的 2 个地址连续的 msadsc_t 结构拿出来,合并成 4 个连续且更大的 msadsc_t 结构。
- 继续查看第 2 个 bafhlst_t 结构,有没有空闲的 msadsc_t 结构,并且它要和上一步合并的 4 个 msadsc_t 结构对应的物理地址是连续的。没有则把这个合并的 4 个 msadsc_t 挂载第 2 个 bafhlst_t 结构中,算法结束。
- ……
将上述过程,以流程图的方式表现如下:
总结
通过之前的学习,我们设计了一个较为优秀的内存页面管理器。其实这种管理内存页的方式,在Linux中也存在,并且称其为buddy内存分配算法(伙伴系统)。
有关buddy内存分配与释放算法的详细知识可以参考这两篇博客:
https://blog.csdn.net/btchengzi0/article/details/73649806
https://blog.csdn.net/orange_os/article/details/7392986
内存的初始化
其实在内核启动最开始的阶段,我们需要先进行内存初始化才能够为后续的工作进行内存的分配和释放,虽然我们建立了内存页和内存区相关的结构体,但是还远远不够。
因为我们还没有在内存中建立对应的实例变量。我们都知道,在代码中实际操作的数据结构必须在内存中有相应的变量,而所谓对内存的初始化就是建立相应的数据结构对应的实例。
内存的初始化主要有以下几个部分:
void init_memmgr(){//初始化内存页结构init_msadsc();//初始化内存区结构init_memarea();//处理内存占用init_search_krloccupymm(&kmachbsp);//合并内存页到内存区中init_merlove_mem();init_memmgrob();return;}
由于这部分的知识主要是代码层面上的理解,因此建议直接阅读彭老师的原文。
补充:Slab内存分配
参考链接

若有收获,就点个赞吧
0 人点赞
