keywords: TinywebServer面试题, 线程池, 并发模型, HTTP报文解析, 数据库登录注册, 压测
description: 本文介绍了TinywebServer项目中的一些面试题,涵盖项目介绍、线程池、并发模型、HTTP报文解析、定时器、日志系统以及压测等多个方面,旨在帮助读者更好地理解和掌握相关知识。
面试题
在Tinywebserver这个项目最后,社长提出了一些可能的面试问题,读者学习完该项目之后可以试着回答一下,看是否究竟对这个项目了如指掌::包括项目介绍,线程池相关,并发模型相关,HTTP报文解析相关,定时器相关,日志相关,压测相关,综合能力等。我对此进行了简单的回答,如果有所纰漏请大家不吝赐教。
原文地址:https://zhuanlan.zhihu.com/p/364044293
项目介绍
为什么要做这样一个项目?
——实验室的项目偏向于机器视觉,感觉自身对于后台开发的知识有点薄弱,故此想学习有关服务器后台开发的相关知识;
介绍下你的项目?
——Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器.
使用线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和模拟Proactor均实现) 的并发模型;
使用状态机解析HTTP请求报文,支持解析GET和POST请求;
访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件;
实现同步/异步日志系统,记录服务器运行状态;
经Webbench压力测试可以实现上万的并发连接数据交换;
线程池相关
手写线程池
#ifndef THREADPOOL_H#define THREADPOOL_H#include <list>#include <cstdio>#include <exception>#include <pthread.h>#include "../lock/locker.h"#include "../CGImysql/sql_connection_pool.h"template <typename T>class threadpool{public:/*thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量*/threadpool(int actor_model, connection_pool *connPool, int thread_number = 8, int max_request = 10000);~threadpool();bool append(T *request, int state);bool append_p(T *request);private:/*工作线程运行的函数,它不断从工作队列中取出任务并执行之*/static void *worker(void *arg);//为什么要用静态成员函数呢-----class specificvoid run();private:int m_thread_number; //线程池中的线程数int m_max_requests; //请求队列中允许的最大请求数pthread_t *m_threads; //描述线程池的数组,其大小为m_thread_numberstd::list<T *> m_workqueue; //请求队列locker m_queuelocker; //保护请求队列的互斥锁sem m_queuestat; //是否有任务需要处理connection_pool *m_connPool; //数据库int m_actor_model; //模型切换(这个切换是指Reactor/Proactor)};template <typename T>//线程池构造函数threadpool<T>::threadpool( int actor_model, connection_pool *connPool, int thread_number, int max_requests) : m_actor_model(actor_model),m_thread_number(thread_number), m_max_requests(max_requests), m_threads(NULL),m_connPool(connPool){if (thread_number <= 0 || max_requests <= 0)throw std::exception();m_threads = new pthread_t[m_thread_number]; //pthread_t是长整型if (!m_threads)throw std::exception();for (int i = 0; i < thread_number; ++i){//函数原型中的第三个参数,为函数指针,指向处理线程函数的地址。//若线程函数为类成员函数,//则this指针会作为默认的参数被传进函数中,从而和线程函数参数(void*)不能匹配,不能通过编译。//静态成员函数就没有这个问题,因为里面没有this指针。if (pthread_create(m_threads + i, NULL, worker, this) != 0){delete[] m_threads;throw std::exception();}//主要是将线程属性更改为unjoinable,使得主线程分离,便于资源的释放,详见PSif (pthread_detach(m_threads[i])){delete[] m_threads;throw std::exception();}}}template <typename T>threadpool<T>::~threadpool(){delete[] m_threads;}template <typename T>//reactor模式下的请求入队bool threadpool<T>::append(T *request, int state){m_queuelocker.lock();if (m_workqueue.size() >= m_max_requests){m_queuelocker.unlock();return false;}//读写事件request->m_state = state;m_workqueue.push_back(request);m_queuelocker.unlock();m_queuestat.post();return true;}template <typename T>//proactor模式下的请求入队bool threadpool<T>::append_p(T *request){m_queuelocker.lock();if (m_workqueue.size() >= m_max_requests){m_queuelocker.unlock();return false;}m_workqueue.push_back(request);m_queuelocker.unlock();m_queuestat.post();return true;}//工作线程:pthread_create时就调用了它template <typename T>void *threadpool<T>::worker(void *arg){//调用时 *arg是this!//所以该操作其实是获取threadpool对象地址threadpool *pool = (threadpool *)arg;//线程池中每一个线程创建时都会调用run(),睡眠在队列中pool->run();return pool;}//线程池中的所有线程都睡眠,等待请求队列中新增任务template <typename T>void threadpool<T>::run(){while (true){m_queuestat.wait();m_queuelocker.lock();if (m_workqueue.empty()){m_queuelocker.unlock();continue;}//T *request = m_workqueue.front();m_workqueue.pop_front();m_queuelocker.unlock();if (!request)continue;//Reactorif (1 == m_actor_model){if (0 == request->m_state){if (request->read_once()){request->improv = 1;connectionRAII mysqlcon(&request->mysql, m_connPool);request->process();}else{request->improv = 1;request->timer_flag = 1;}}else{if (request->write()){request->improv = 1;}else{request->improv = 1;request->timer_flag = 1;}}}//default:Proactorelse{connectionRAII mysqlcon(&request->mysql, m_connPool);request->process();}}}#endif
线程的同步机制有哪些?
——信号量、条件变量、互斥量等;
线程池中的工作线程是一直等待吗?
——是的,等待新任务的唤醒;
你的线程池工作线程处理完一个任务后的状态是什么?
——如果请求队列为空,则该线程进入线程池中等待;若不为空,则该线程跟其他线程一起进行任务的竞争;
如果同时1000个客户端进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
——该项目是基于IO复用的并发模式。需要注意的是,不是一个客户连接就对应一个线程!如果真是如此,淘宝双12服务器早就崩了!当客户连接有事件需要处理的时,epoll会进行事件提醒,而后讲对应的任务加入请求队列,等待工作线程竞争执行。如果速度还是慢,那就只能够增大线程池容量,或者考虑集群分布式的做法。
如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
——会,因为线程的数量是固定的,如果一个客户请求长时间占用着线程资源,势必会影响到服务器对外的整体响应速度。解决的策略可以是给每一个线程处理任务设定一个时间阈值,当某一个客户请求时间过长,则将其置于任务请求最后,或断开连接。
并发模型相关
简单说一下服务器使用的并发模型?
——该项目选用的半同步半反应堆的并发模型。
以Proactor模式为例的工作流程即是:主线程充当异步线程,负责监听所有socket上的事件
若有新请求到来,主线程接收之以得到新的连接socket,然后往epoll内核事件表中注册该socket上的读写事件
如果连接socket上有读写事件发生,主线程从socket上接收数据,并将数据封装成请求对象插入到请求队列中
所有工作线程睡眠在请求队列上,当有任务到来时,通过竞争(如互斥锁)获得任务的接管权
reactor、proactor、主从reactor模型的区别?
Reactor模式:要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生(可读、可写),若有,则立即通知工作线程,将socket可读可写事件放入请求队列,读写数据、接受新连接及处理客户请求均在工作线程中完成。(需要区别读和写事件)
Proactor模式:主线程和内核负责处理读写数据、接受新连接等I/O操作,工作线程仅负责业务逻辑(给予相应的返回url),如处理客户请求。
主从Reactor模式:核心思想是,主反应堆线程只负责分发Acceptor连接建立,已连接套接字上的I/O事件交给sub-reactor负责分发。其中 sub-reactor的数量,可以根据CPU的核数来灵活设置。下图即是其工作流程:
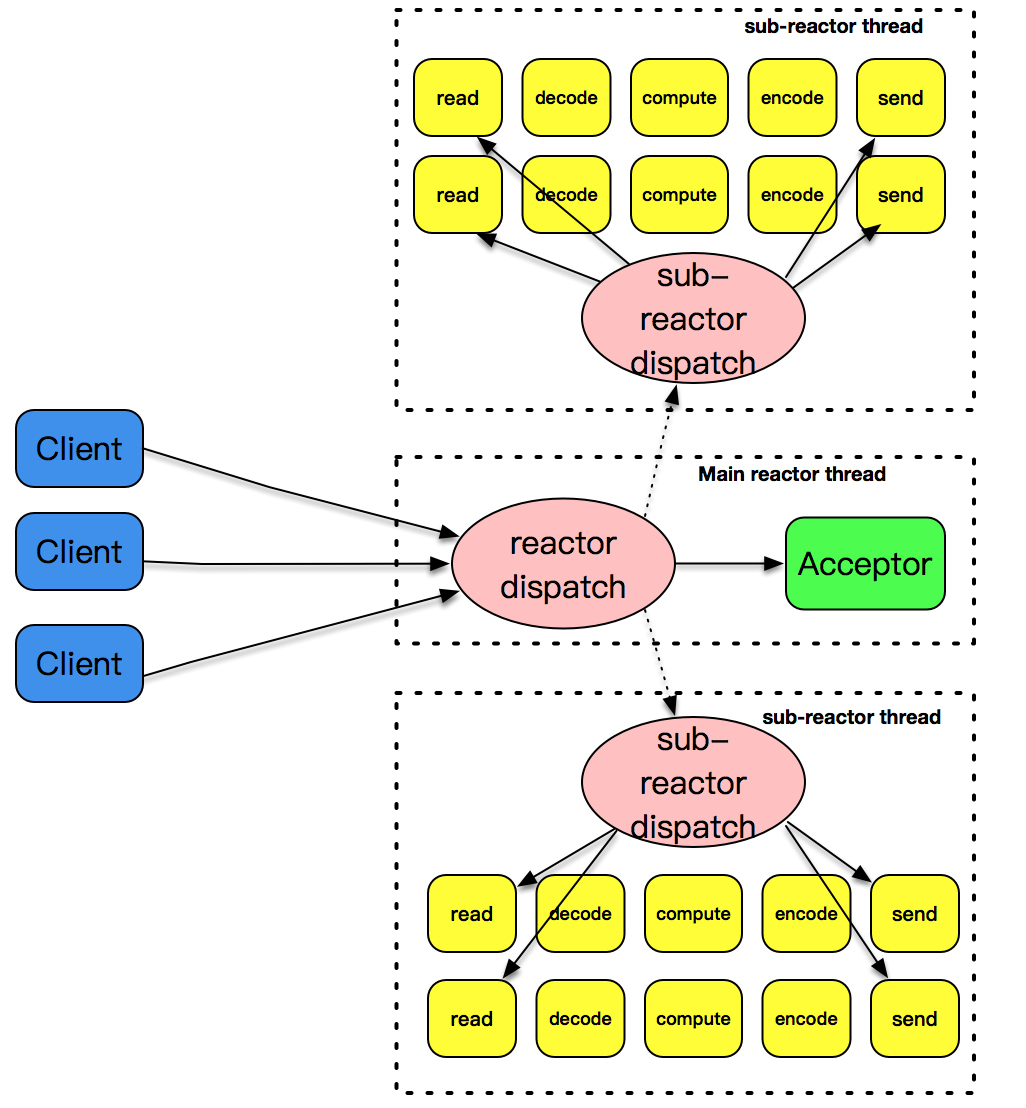
主反应堆线程一直在感知连接建立的事件,如果有连接成功建立,主反应堆线程通过accept方法获取已连接套接字,接下来会按照一定的算法选取一个从反应堆线程,并把已连接套接字加入到选择好的从反应堆线程中。主反应堆线程唯一的工作,就是调用accept获取已连接套接字,以及将已连接套接字加入到从反应堆线程中。
你用了epoll,说一下为什么用epoll,还有其他复用方式吗?区别是什么?
——先说说其他的复用方式吧,比较常用的有三种:select/poll/epoll。本项目之所以采用epoll,参考问题(Why is epoll faster than select?)
- 对于select和poll来说,所有文件描述符都是在用户态被加入其文件描述符集合的,每次调用都需要将整个集合拷贝到内核态;epoll则将整个文件描述符集合维护在内核态,每次添加文件描述符的时候都需要执行一个系统调用。系统调用的开销是很大的,而且在有很多短期活跃连接的情况下,epoll可能会慢于select和poll由于这些大量的系统调用开销。
- select使用线性表描述文件描述符集合,文件描述符有上限;poll使用链表来描述;epoll底层通过红黑树来描述,并且维护一个ready list,将事件表中已经就绪的事件添加到这里,在使用epoll_wait调用时,仅观察这个list中有没有数据即可。
- select和poll的最大开销来自内核判断是否有文件描述符就绪这一过程:每次执行select或poll调用时,它们会采用遍历的方式,遍历整个文件描述符集合去判断各个文件描述符是否有活动;epoll则不需要去以这种方式检查,当有活动产生时,会自动触发epoll回调函数通知epoll文件描述符,然后内核将这些就绪的文件描述符放到之前提到的ready list中等待epoll_wait调用后被处理。
- select和poll都只能工作在相对低效的LT模式下,而epoll同时支持LT和ET模式。
- 综上,当监测的fd数量较小,且各个fd都很活跃的情况下,建议使用select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使用epoll会明显提升性能。
HTTP报文解析相关
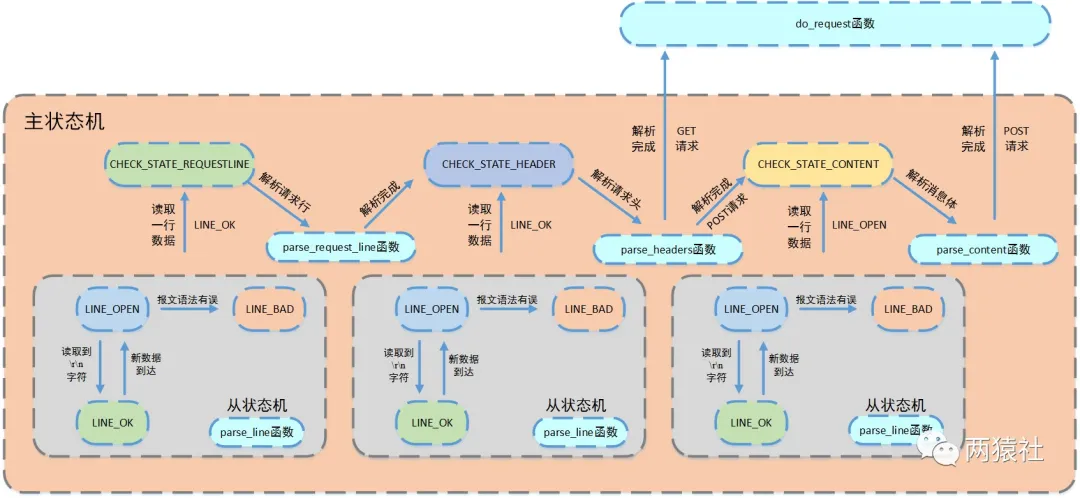
用了状态机啊,为什么要用状态机?
——有限状态机,是一种抽象的理论模型,它能够把有限个变量描述的状态变化过程,以可构造可验证的方式呈现出来。比如,封闭的有向图。有限状态机可以通过if-else,switch-case和函数指针来实现,从软件工程的角度看,主要是为了封装逻辑。有限状态机一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
状态机的转移图画一下?
——见下:
https协议为什么安全?
——连接建立阶段基于ssl安全验证;数据传输阶段加密,进一步了解可以百度;
https的ssl连接过程?
——一张图就够了:

GET和POST的区别?
——强烈推荐!网上其他答案都没答到点:https://www.cnblogs.com/logsharing/p/8448446.html
数据库登录注册相关
登录说一下?
——其实之前的文章已经提到了登录的详细过程:
具体的涉及到载入数据库表,提取用户名和密码,注册登录流程与页面跳转。
- 载入数据库表,结合代码将数据库中的数据载入到服务器中;
- 提取用户名和密码,结合代码对报文进行解析,提取用户名和密码;
- 注册登录流程,结合代码对描述服务器进行注册和登录校验的流程;
- 页面跳转,结合代码对页面跳转机制进行详解
你这个保存状态了吗?如果要保存,你会怎么做?
——可以利用session或者cookie的方式进行状态的保存。
cookie其实就是服务器给客户分配了一串“身份标识”,比如“123456789happy”这么一串字符串。每次客户发送数据时,都在HTTP报文附带上这个字符串,服务器就知道你是谁了;
session是保存在服务器端的状态,每当一个客户发送HTTP报文过来的时候,服务器会在自己记录的用户数据中去找,类似于核对名单;
登录中的用户名和密码你是load到本地,然后使用map匹配的,如果有10亿数据,即使load到本地后hash,也是很耗时的,你要怎么优化?
——这个问题的关键在于大数据量情况下的用户登录验证怎么进行?将所有的用户信息加载到内存中耗时耗利,对于大数据最遍历的方法就是进行hash,利用hash建立多级索引的方式来加快用户验证。具体操作如下:
首先,将10亿的用户信息,利用大致缩小1000倍的hash算法进行hash,这时就获得了100万的hash数据,每一个hash数据代表着一个用户信息块(一级);
而后,再分别对这100万的hash数据再进行hash,例如最终剩下1000个hash数据(二级)。
在这种方式下,服务器只需要保存1000个二级hash数据,当用户请求登录的时候,先对用户信息进行一次hash,找到对应信息块(二级),在读取其对应的一级信息块,最终找到对应的用户数据,
用的mysql啊,redis了解吗?用过吗?
——用过,详见:Redis解析。
定时器相关
为什么要用定时器?
——处理定时任务,或者非活跃连接,节省系统资源;
说一下定时器的工作原理?
——服务器就为各事件分配一个定时器。该项目使用SIGALRM信号来实现定时器,首先每一个定时事件都处于一个升序链表上,通过alarm()函数周期性触发SIGALRM信号,而后信号回调函数利用管道通知主循环,主循环接收到信号之后对升序链表上的定时器进行处理:若一定时间内无数据交换则关闭连接。
双向链表啊,删除和添加的时间复杂度说一下?还可以优化吗?
——添加一般情况下都是O(N),删除只需要O(1)。从双向链表的方式优化不太现实,可以考虑使用最小堆、或者跳表的数据结构,跳表详见。
最小堆优化?说一下时间复杂度和工作原理
——最小堆以每个定时器的过期时间进行排序,最小的定时器位于堆顶,当SIGALRM信号触发tick()函数时执行过期定时器清除,如果堆顶的定时器时间过期,则删除,并重新建堆,再判定是否过期,如此循环直到未过期为止。
插入,O(logn);
删除,O(logN);
日志相关
说下你的日志系统的运行机制?
——初始化服务器时,利用单例模式初始化日志系统,根据配置文件确认是同步还是异步写入的方式。
为什么要异步?和同步的区别是什么?
——同步方式写入日志时会产生比较多的系统调用,若是某条日志信息过大,会阻塞日志系统,造成系统瓶颈。异步方式采用生产者-消费者模型,具有较高的并发能力。
现在你要监控一台服务器的状态,输出监控日志,请问如何将该日志分发到不同的机器上?
——为了便于故障排查,或服务器状态分析,看是否需要维护;可以使用消息队列进行消息的分发,例如mqtt、rabitmq等等;
压测相关
服务器并发量测试过吗?怎么测试的?
——测试过,利用webbench,至少满足万余的并发量。
webbench是什么?介绍一下原理
——是一款轻量级的网址压力测试工具,可以实现高达3万的并发测试。其原理:Webbench实现的核心原理是:父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。
测试的时候有没有遇到问题?
——没·····
综合能力
你的项目解决了哪些其他同类项目没有解决的问题?
——自己造轮子;
说一下前端发送请求后,服务器处理的过程,中间涉及哪些协议?
——HTTP协议、TCP、IP协议等,计算机网络的知识。

若有收获,就点个赞吧
0 人点赞
