安装环境
安装环境=安装golang环境+编辑器
安装golang环境:https://www.runoob.com/go/go-environment.html,注意配置环境变量,大致有三个:
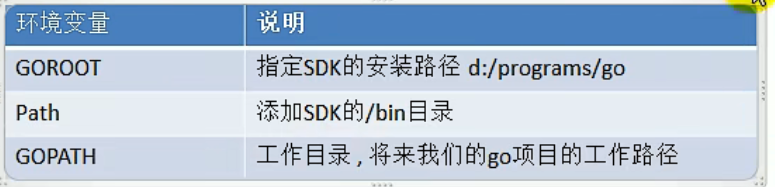
安装编辑器:goland(只有30天免费使用)或者直接使用sublime text(配置教程)或VSCode(用管理员身份运行)
介绍
开发团队

为什么Google创造golang?

golang特点
简洁、常规的语法(不需要解析符号表),它仅有25个关键字;
内置数组边界检查;
内置并发支持;(goroutine)
内置垃圾收集,降低开发人员内存管理的心智负担;
没有头文件;
没有循环依赖(package) ;
首字母大小写决定可见性;
任何类型都可以拥有方法(没有类);
没有子类型继承(没有子类);
没有算术转换;
接口是隐式的(无须implements声明);
方法就是函数;
接口只是方法集合(没有数据);
没有构造函数或析构函数;
n++和n—是语句,而不是表达式;
没有++n和—n;
赋值不是表达式;
在赋值和函数调用中定义的求值顺序(无“序列点”概念);
没有指针算术;
内存总是初始化为零值;
没有类型注解语法(如C++中的const、static等);
没有异常(exception) ;
内置字符串、切片(slice) . map类型;

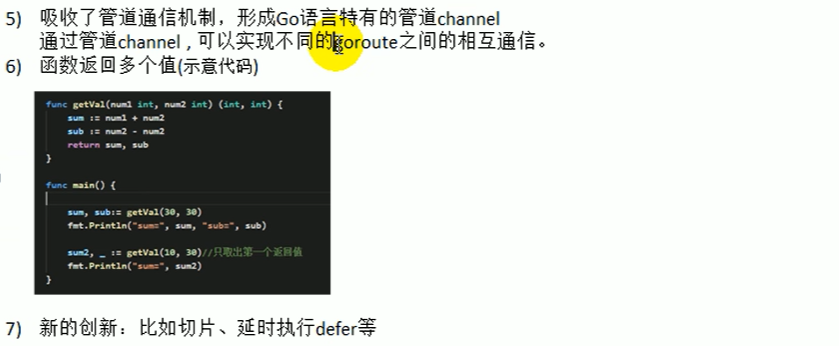
入门
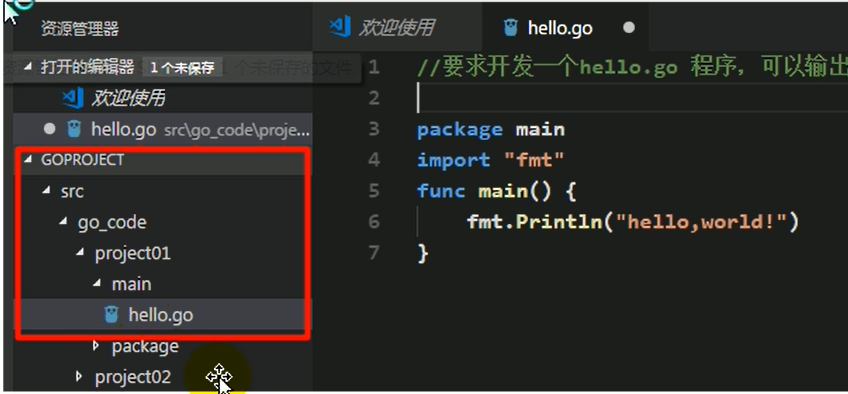
项目目录结构
一般采用如下所示的目录结构:
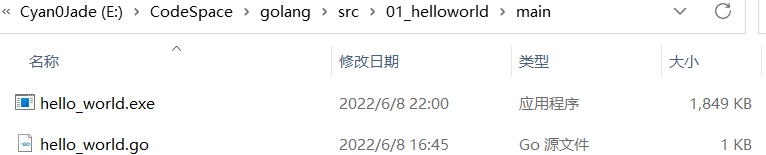
go run与go build
go run其实就是将编译与运行一步执行;
go build是将源代码进行编译,go build之后会将各种库文件自动打包:

首字母大小写表示访问权限
在golang中,对某个变量或类型(struct)进行命名时,如果首字母大写,则表示该类型可以被其他包所引用(import),否则,其他包无法引用该类型。
这种关系类似于private与public,给一个比较全面的例子:
package pabtype (EventObserver struct { // 大写外包可访问id int // 小写外包不可访问}EventNotifier struct { // 大写外包可访问ID int // 大写外包可访问}event struct { // 小写外包不可访问id int // 小写外包不可访问})func testAuthA() { // 外包不可访问// 在同一个包里方法和属性大小写都可以访问。n := &event { id : 1 }}func TestAuthB() { // 外包可访问}
其他:
1、函数中的变量声明必须引用,全局变量可以声明但不使用。
2、Go虽然有指针,但是仅有&(取地址)、*(解引用)的简单操作,不能进行指针运算,比如对指针进行加法等;
3、结构体定义如下:
type Vertex struct {X intY int}
符号命名原则——驼峰
Go语言官方要求标识符命名采用驼峰命名法(CamelCase),以变量名为例,如果变量名由一个以上的词组合构成,那么这些词之间紧密相连,不使用任何连接符(如下划线)。
驼峰命名法有两种形式:一种是第一个词的首字母小写,后面每个词的首字母大写,叫作“小骆峰拼写法”(lowerCamelCase),这也是在Go中最常见的标识符命名法;而第一个词的首字母以及后面每个词的首字母都大写,叫作“大驼峰拼写法”(UpperCamelCase),又称“帕斯卡拼写法”(PascalCase)。
数据类型
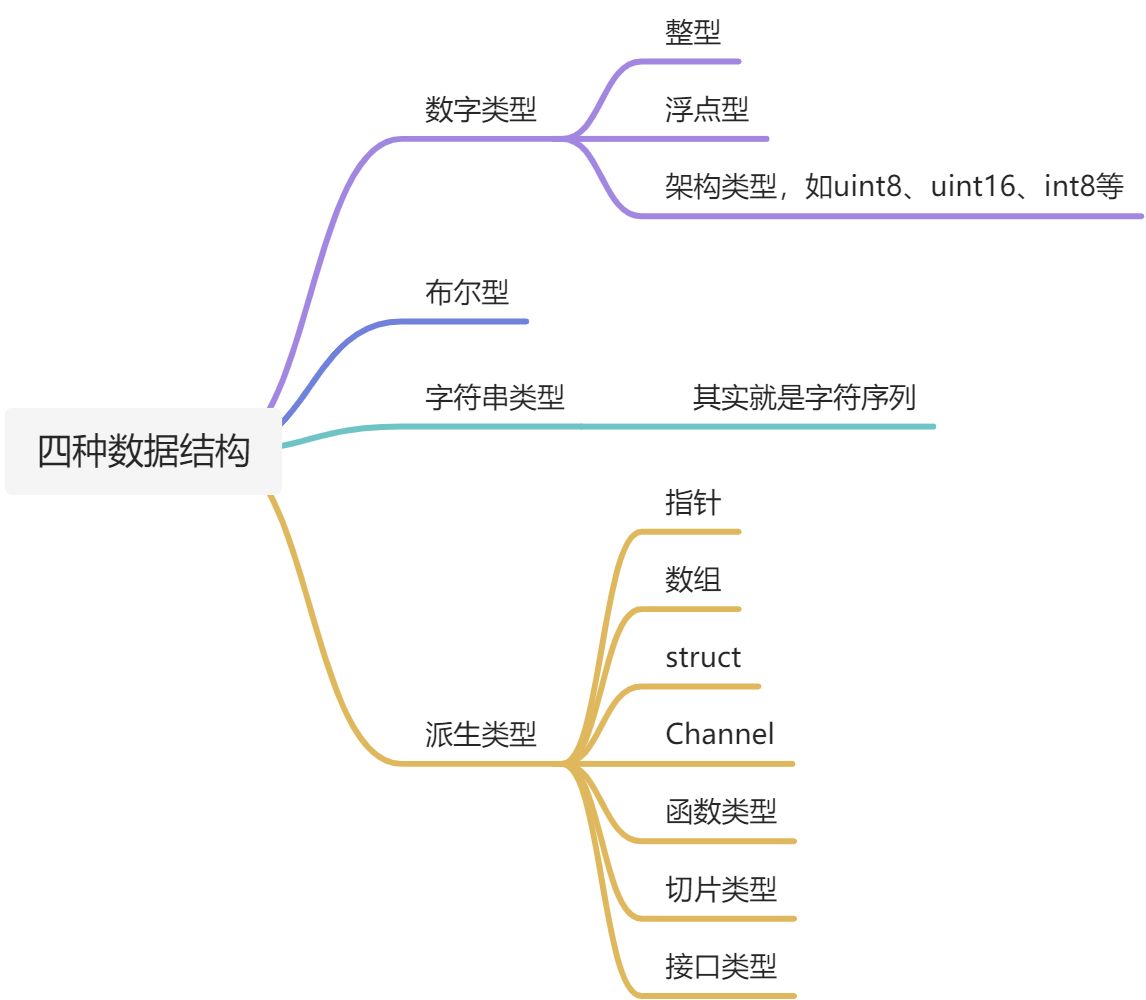
变量声明

举个例子:
// 第一种 先声明,再定义var num1 intvar a,b intvar num2,num3 int //没有初始化,默认为0或falsevar ptr1 *intvar arr []intvar map1 map[string] int //表示string为key,int为value//因式分解地方式多用于全局变量var (vname1 intvname2 float)var (a =1 //也可在a后加上intb = 3.14)var num3 = 4 //自动推理//第二种,声明并定义var num11=1// 这种是自动类型推断num4 :=1 //num4之前不能已被声明,这种方式只能够在函数内运行!无法在函数外定义全局变量!
类型转换
在go中,不允许隐式的类型转换,必须显式地给出转换类型。
// 这种是错的var x, y int = 3, 4var f float64 = math.Sqrt(x*x + y*y)var z uint = f//这是对的var x, y int = 3, 4var f float64 = math.Sqrt(float64(x*x + y*y))var z uint = uint(f)
值类型与引用类型
值类型,即基本数据类型,使用这些类型的变量直接指向其在内存中的值。变量直接传递的时候其实是值传递,即在内存中进行拷贝;
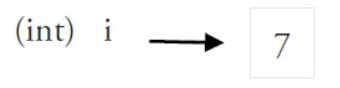
引用类型,类似于C的指针,这些变量存储的是指向对应类型对象的内存地址,通过该内存地址实时获取最新类型对象的数据;

注意,address1所指向的对象内存地址不一定是连续的,虽然连续形式最高效,但具体情况根据实际所用机器来决定;
for和if的写法
for的写法:exp;判别式;exp,如下:
for i := 0; i < 10; i++ {sum += i}
if的写法:exp;判别式 else,如下:
if v := math.Pow(x, n); v < lim { //表达式可以不存在return v} else {fmt.Printf("%g >= %g\n", v, lim)}
range避坑指南
使用range时要注意以下几点:
- 小心变量重用

上述代码中,在range{}内部代码共用了外部的i与v,在某些情况下会造成非预期的结果:

输出全都是45,也就是遍历最后的元素。要想解决这个问题,可以在调用goruntine时将当前的i、v值进行绑定:

- 参与range迭代的是副本

其实经过上述代码之后,原本a的值没有被改变,因为range是获取的a的副本!
如果想修改a的值呢?用指针进行引用!
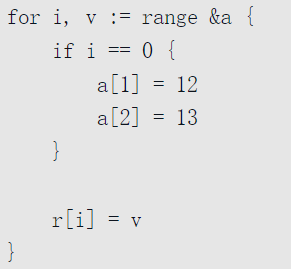
虽然在range表达式中也是先创建副本进行操作,但这个副本是一个指向原数组的指针,因此后续所有的操作其实是对原数组的操作。
也可以将数组替换为切片,因为切片的底层其实有三个主要元素:(*T, len, cap)三元组,即指向底层数组的指针,切片当前长度与切片的容量。因此对切片副本进行操作,同样可以修改原切片。
值得注意的是,如果有append的操作,则副本与原切片的长度就不一致了,因为len发生了变化。
switch
不需要进行break,如果没有条件,则根据判断true来决定,可以用于写长代码:if-else-then
//典型switch os := runtime.GOOS; os {case "darwin":fmt.Println("OS X.")case "linux":fmt.Println("Linux.")default:fmt.Printf("%s.\n", os)}// if-else-then类型func main() {t := time.Now()switch {case t.Hour() < 12:fmt.Println("Good morning!")case t.Hour() < 17:fmt.Println("Good afternoon.")default:fmt.Println("Good evening.")}}
defer/panic/recover
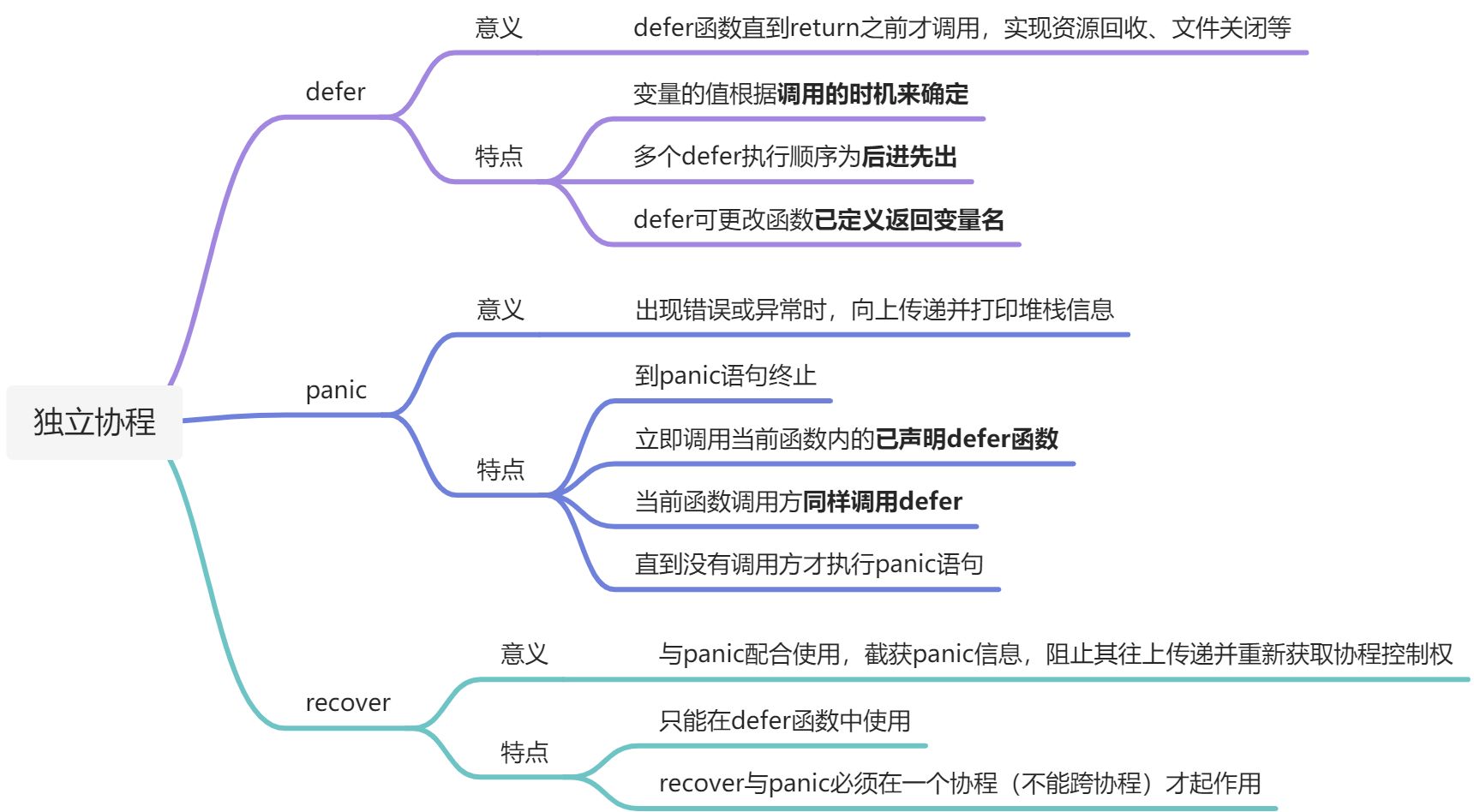
defer:将函数调用放在函数return时(之前)进行调用:
func main() {defer fmt.Println("world")fmt.Println("hello")}// hello world
有关panic与recover的官方例子:
package mainimport "fmt"func main() {f()fmt.Println("Returned normally from f.")}func f() {defer func() {if r := recover(); r != nil {fmt.Println("Recovered in f", r)}}()fmt.Println("Calling g.")g(0)fmt.Println("Returned normally from g.")}func g(i int) {if i > 3 {fmt.Println("Panicking!")panic(fmt.Sprintf("%v", i))}defer fmt.Println("Defer in g", i)fmt.Println("Printing in g", i)g(i + 1)}
上述代码的输出为:
Calling g.Printing in g 0Printing in g 1Printing in g 2Printing in g 3Panicking! //开始调用panicDefer in g 3 //往上依次回溯defer函数Defer in g 2Defer in g 1Defer in g 0Recovered in f 4Returned normally from f.
补充资料:Go语言之panic和recover_灰子学技术的博客-CSDN博客_go panic recover
字符串常用操作
Println:一般用于无格式化输出要求的场景;
Printf:用于格式化输出的场景;
Sprintf:返回的是一个字符串;
Scanln:获取用户输入;
array与slice扩容
array与slice都可以当成数组,不过array是固定长度数组,其可容纳长度在申明时已经固定,无法进行更改;
而slice相当于原slice或array的视图view,原slice或array的值改变,它也会随之改变。它也可以看成是动态数组,与C++的vector类似,其具有两个属性:length与capacity,前者表示当前slice的长度,后者表示当前slice所能容纳的最大的长。
如果超出长度,slice会自动扩容,扩容策略如下:
old_cap与old_len分别代表扩容前的容量和长度,new_cap和new_len是扩容后的值,add_len表示加入的元素个数。
第一步,计算期望容量exp_len:old_len+new_len,由于该值大于old_cap,进行扩容,三个判断策略:
1.若exp_len>2*old_cap,那么新的容量就是exp_len;
2.若exp_len<2old_cap,且old_cap<256,那么最终容量为2old_cap;
3.若old_cap>256,则循环计算new_cap += (new_cap + 3*threshold) / 4,其中threshold为256,直到new_cap>exp_len为止;
第二步,进行内存对齐!对齐操作会根据slice的元素类型来保证内存的连续性和最大利用率。
// class bytes/obj bytes/span objects tail waste max waste min align// 1 8 8192 1024 0 87.50% 8// 2 16 8192 512 0 43.75% 16// 3 24 8192 341 8 29.24% 8// 4 32 8192 256 0 21.88% 32// 5 48 8192 170 32 31.52% 16// 6 64 8192 128 0 23.44% 64// 7 80 8192 102 32 19.07% 16// 8 96 8192 85 32 15.95% 32// 9 112 8192 73 16 13.56% 16// 10 128 8192 64 0 11.72% 128
参考:https://blog.csdn.net/weixin_43237362/article/details/121445195
“类方法”
方法的本质
方法的本质:一个以方法所绑定类型实例为第一个参数的普通函数。
严格来说,go并没有类的概念, 但是可以通过设置函数的接收器receiver参数类型来实现类似于method的概念:

举个例子:
// method就是一种特殊的函数!func (v Vertex) Abs() float64 {return math.Sqrt(v.X*v.X + v.Y*v.Y)}
如果想实现可以修改对应结构体内部的数据,从而使得method更像是一个类方法,需要使用指针接收器:
type Vertex struct {X, Y float64}func (v *Vertex) Scale(f float64) {v.X = v.X * fv.Y = v.Y * f}func main() {v := Vertex{3, 4}v.Scale(10)}
Go方法具有如下特点。
1)方法名的首字母是否大写决定了该方法是不是导出方法。
2)方法定义要与类型定义放在同一个包内。由此我们可以推出:不能为原生类型(如int、float64、map等)添加方法,只能为自定义类型定义方法。同理,可以推出:不能横跨Go包为其他包内的自定义类型定义方法。
3)每个方法只能有一个receiver参数,不支持多receiver参数列表或变长receiver参数。一个方法只能绑定一个基类型,Go语言不支持同时绑定多个类型的方法。
4)receiver参数的基类型本身不能是指针类型或接口类型。
其实,上述方法的原型可以表示下面的函数:
func Scale(v *Vertex,f float64) {v.X = v.X * fv.Y = v.Y * f}
分析一下这两种调用方式:
var vertex Vertex//第一种vertex.Scale(0.3)//第二种Scale(&vertex,0.3)
可以看到,方法的本质,其实就是一个以方法所绑定类型实例为第一个参数的普通函数。
注意,T/T可以互相调用receiver方法,这是Go的语法糖,*在编译时自动进行了转换:

Go语言规范:对于非接口类型的自定义类型T,其方法集合由所有receiver为T类型的方法组成;而类型T的方法集合则包含所有receiver为T和T类型的方法。
那么问题来了,究竟什么时候用method什么时候用func呢?
method belongs to instance
function is a global function belongs to package. 当需要进行面向对象编程的时候建议使用method。
一道经典例题理解方法
先看代码:
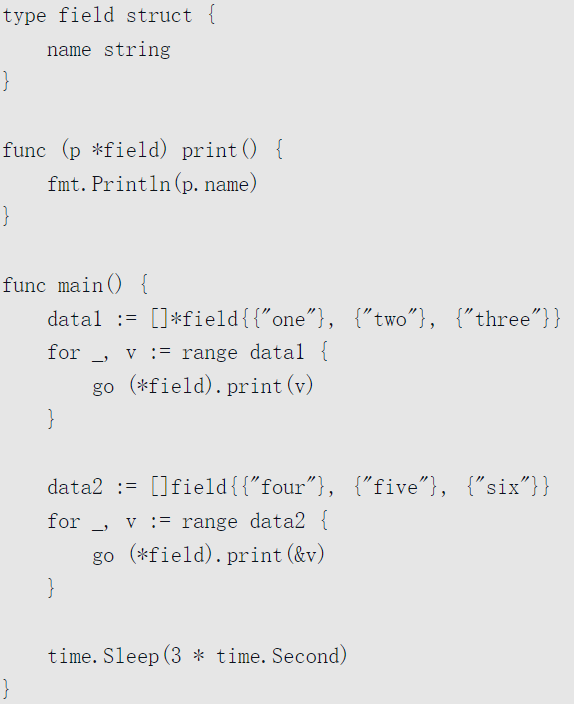
其实就是分析两种receiver方法的差异。
结果是什么?
……
……
结果为:one two three(这三者顺序不一定) six six six
原因就在于,将上述方法调用代码转换为方法表达式之后:

而range的有一个实现特性,那就是v的地址全程不变,且go * 是在遍历完所有的元素之后才进行的,这时v的地址中的值为”six”,这就造成错误的结果。**
接口
golang的接口象征意义大于实际意义。
而且empty interface的主要作用是可以接收任意类型的参数,如下:
package mainimport "fmt"func do(i interface{}) {switch v := i.(type) {case int:fmt.Printf("Twice %v is %v\n", v, v*2)case string:fmt.Printf("%q is %v bytes long\n", v, len(v))default:fmt.Printf("I don't know about type %T!\n", v)}}func main() {do(21)do("hello")do(true)}
Stringer接口
Strnger是最常用的接口,作用是进行序列化输出:
type Stringer interface {String() string}
用户可以对自定义结构体进行序列化输出:
type Person struct {Name stringAge int}func (p Person) String() string {return fmt.Sprintf("%v (%v years)", p.Name, p.Age)}
Error接口
Go语言中用error来表示错误状态,函数返回的error若是nil,则表示运行过程无异常。
与fmt.Stringer接口类似,error也是一个内置的接口类型:
type error interface {Error() string}
如果需要打印相应的error信息,就必须实现上述接口,以下面的代码为例:
package mainimport ("fmt""time")type MyError struct {When time.TimeWhat string}// 实现了Error接口func (e *MyError) Error() string {return fmt.Sprintf("at %v, %s",e.When, e.What)}func run() error {return &MyError{time.Now(),"it didn't work",}}func main() {if err := run(); err != nil {fmt.Println(err)}}
最终的打印结果即是出现错误的时间:

可以简单理解为,Error()接口其实就是对应error类型的串行化接口。在下面的例子中,如果没有将e类型转换为float64,会造成程序无限循环:
type ErrNegativeSqrt float64func (e ErrNegativeSqrt) Error() string {//return fmt.Sprintf("cannot Sqrt negative number: %v", e) //错误return fmt.Sprintf("cannot Sqrt negative number: %v", float64(e)) //正确}
因为e的类型是ErrNegativeSqrt,而ErrNegativeSqrt是实现了error这个interface的。
fmt.Sprintf(“cannot Sqrt negative number %v”,e)
内部发现e的类型之后,就会试图调用它的Error方法,然后就无限递归了
泛型编程
Go支持模板编程,主要有两类,一类是通用类型,一类是指定类型。
前者表示任何类型都支持,如下述的列表实现:
type List[T any] struct {next *List[T]val T}
后者表示仅有特定类型支持该函数或结构体,如下表示查找某值是否在数组中:
func Index[T comparable](s []T, x T) int {for i, v := range s {// v and x are type T, which has the comparable// constraint, so we can use == here.if v == x {return i}}return -1}
上述两个例子中,any表示任务类型都支持,comparable表示类型支持比较,如==或!=。
枚举类型
枚举的存在代表了一类现实需求:有限数量标识符构成的集合,且多数情况下并不关心集合中标识符实际对应的值;注重类型安全。
不同于C++、Java专门设计一种枚举类,golang使用常量语法来定义枚举常量,如下分别是完整写法与隐式重复写法:
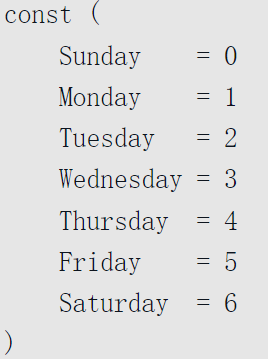


更进一步,go提供了iota机制,iota是一个预定义标识符,其表示const声明块中每个常量所处位置在块中的偏移值,也是一个五类型常量,可以参与不同类型的求值过程。
下图是标准库中一段枚举常量的定义代码:

上图的结果依次为:1,2,4,3,1e6.
如果想略过某个枚举值,可以这样:

进阶
GOROOT、GOPATH、依赖管理与go mod
GOROOT:表示golang的安装路径,其内容为源代码、库文件及相应的可执行程序,如run、build等;
GOPATH:表示当前go项目的路径,根据实际开发过程中的路径而定。一般而言,对于一个go_project,其项目结构如下:
go_project:
->bin //编译之后可执行程序存放地址
->pkg//编译包时,生成的*.a文件存放地址
->src//源文件地址,是go run 、 go build等工具的默认当前工作路径
在导入包时,go默认先搜索GOROOT,再搜索GOPATH,这种方式就是早期的手动管理方式,对项目的维护和更新都产生了巨大的阻碍。
但在GO11之后,引入了go mod来进行依赖管理,查看go环境是否开启gomod,可以通过go env进行查询,GO111MODULE字段有三种取值,分别表示:
GO111MODULE=off,旧版本的查找模式,GOROOT与GOPATH;
GO111MODULE=on,不会再查询GOPATH!(之前因为这个问题找了半天bug)。包存放位置变为$GOPATH/pkg,允许同一个package多个版本并存;
GO111MODULE=auto,这种情况下可以分为两种情形:1、当前目录在GOPATH/src之外且该目录包含go.mod文件
2、当前文件在包含go.mod文件的目录下面。
可以通过go env -w GO111MODULE=off进行设置
有关go mod的包管理可以查看:速学 GoMod 包管理(2021版本) - 腾讯云开发者社区-腾讯云
文件操作
输入流与输出流

流,表示数据在数据源(文件)与程序(内存)之间经历的路径
输入流,数据从数据源文件到程序内存;
输出流,数据从程序内存到数据源文件;
类型嵌入
golang并没有C++、Java那种继承机制,而是采用类型嵌入的方式来实现代码复用的目的,例如标准库中的Writer与Reader:
type Reader interface {Read(p []byte) (n int, err error)}type Writer interface {Write(p []byte) (n int, err error)}// ReadWriter is the interface that combines the Reader and Writer interfaces.type ReadWriter interface {ReaderWriter}//也可以进行struct到struct的嵌入// ReadWriter stores pointers to a Reader and a Writer.// It implements io.ReadWriter.type ReadWriter struct {*Reader // *bufio.Reader*Writer // *bufio.Writer}
单元测试—testing
单元测试是指,在工作中,测试某一个函数的在给定输入之后,输出的结果是否与预期的结果一致。
传统的测试方式有以下缺陷:
1)操作不便,需要在main函数中运行,可能会停止线上项目;
2)当需要测试多个函数时不利于管理;
3) go自带了单元测试框架——testing来解决上述问题,同事还能进行性能测试,即测试相关的运行代码;
其实testing框架,会加载所有_test.go文件,并引入其中的函数执行,测试函数命名规则:*Test+大写子木开头的测试函数名,如:
func TestAddUper(in int)
cmd运行命令:go test,结果正确无日志,错误则输出日志;go test -v 均有日志;
如何测试单个文件或单个方法?
单个文件:+加测试的源文件:
go test -v cal_test.go cal.go
单个函数:+加测试的那个方法:
go test -v -test.run TestAddUpper(测试的方法)
Struct中的标签(Tag)(未阅读)
序列化与反序列化
序列化,即是将结构体、map、slice等转换成字符串;
反序列化,即是将上述字符串恢复成原结构体、map与slice,即逆操作。
注意:反序列化中的某些字符需要进行转义,+’\’。
对于结构体的序列化,可以利用struct的tag(标签),实现指定序列化指定字段的名字,而不是默认的字段属性名称。
json、Marsh和unmarshal
map类型详解
值得注意的是,map类型不支持“零值可用”特性,对未初始化的map进行操作时会产生panic。
使用方法
两种初始化方式
- 复合字面值初始化:

- make函数进行创建:

注意:map作为参数时为引用类型,内部修改对外部可见;
插入元素:直接k-v输入即可,如果有重复的key,则新值覆盖旧值;
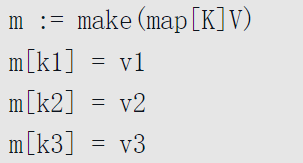
获取元素个数:len函数
删除元素:delete函数

查找数据:map进行查询时会返回两个值,第二个值(”common ok“)表示元素是否存在。

注意:当map中不存在该k-v时,会返回一个值0。
因此如果不使用common ok来判断元素是否存在,将可能出现错误操作。
数据遍历:map遍历时顺序不固定。
可以使用fo range 语句进行map的数据遍历:

这种方式的次序不固定,因为go初始化map迭代器时进行了随机处理。
如果想按照顺序遍历数据,最好的方式是将key保存到一个切片中,利用切片去按照顺序获取对应的value。

内部实现
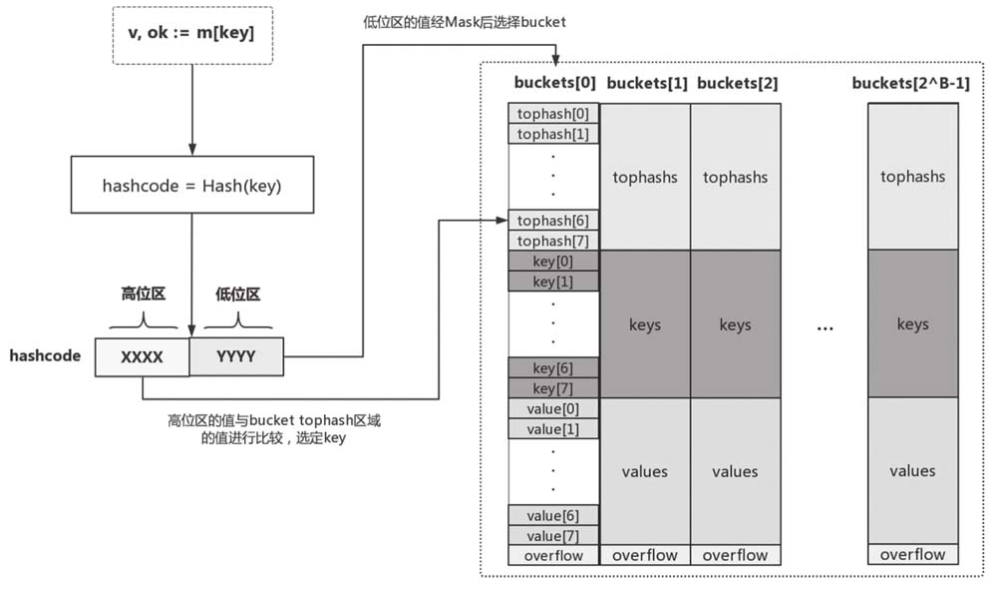
key-value分开存储:这种方式虽然增加了算法实现上的复杂性,但是相比于key-value连续存储的方式大大提高了内存利用效率(连续存储某些情况下仅有50%的利用率);
扩容时状态:在扩容时,其实map维护了两个bucket数组,新bucket数组的迁移与旧bucket数组的删除是在assign赋值与delete删除过程中逐步进行的,只有当旧bucket数组都被清空和转移,才将旧数组(oldbucket)进行删除:
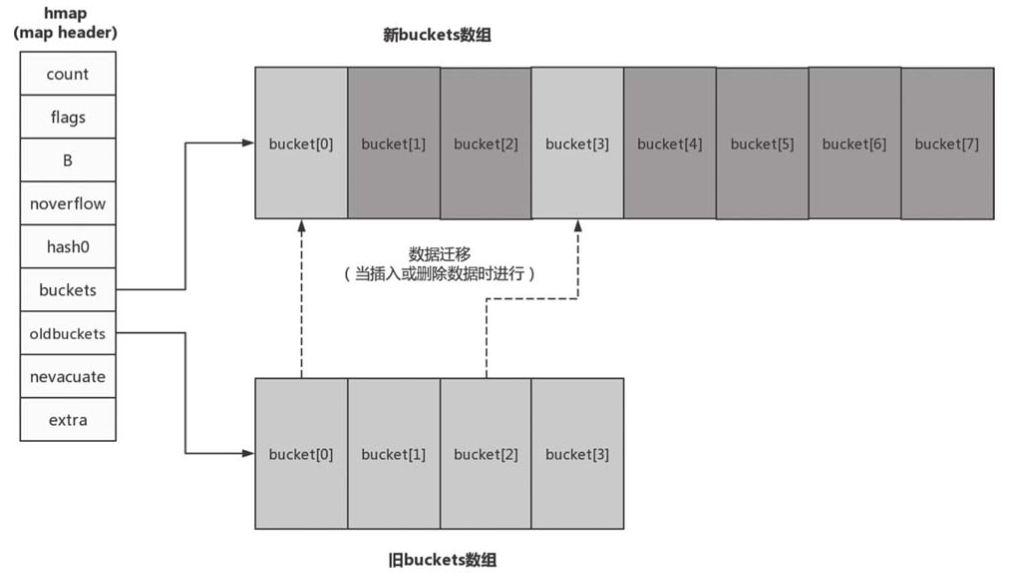
注:map不支持并发,会报panic错误;1.9版本之后的sync.Map支持并发操作;
注:map的value地址无法获取,因为扩容机制会使得value地址发生变化,因此在编译之初就进行了限制;
变量求值顺序
包级别变量声明语句中的表达式求值顺序:两个原则
- 按照声明顺序进行初始化
- 如果某个变量a依赖于其他变量b,则该变量a初始化顺序排在b之后
简答来说,不依赖其他变量的变量称为“可初始化变量ready for initialization”。变量初始化的过程其实就是按照声明顺序,不停查看rfi变量是否存在,存在则进行初始化。
见下例:

结果为:9 4 5 5
普通求值顺序
普通求值顺序是按照从左到右的次序进行求值。
赋值语句求值
看个例子:

分为两步走:
第一步,处理等号左侧的表达式,按照从左至右的方式进行;
第二部,处理右侧的表达式,也是从左到右;
假定n0、n1初值为1,2,则上述结果为:n0、n1分别为3,1。
编译过程
并发goroutine与管道Channel
goroutine:
各个版本的routine调度器缺陷和特点;
gonetpoller的介绍;
GMP代表的含义;
抢占式调度的意义(G没有时间片的概念);
go并发模型CSP;
channel的底层与使用;
goroutine实现并发
Rob Pike的观点:“并发关乎结构,并行关乎执行。”并发和并行是两个阶段的事情。并发在程序的设计和实现阶段,并行在程序的执行阶段。
传统的编程语言,如C/C++、Java等,应用程序负责创建线程,操作系统负责管理线程。
而go语言,采用用户级的轻量级线程(协程),调度、管理均由go调度器来负责。
- 早期版本:G-M调度器-GO1.0
每个goroutine对应于运行时中的一个抽象结构——G(goroutine),而被视作“物理CPU”的操作系统线程则被抽象为另一个结构——M(machine)。
主要有以下几点缺陷:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有goroutine相关操作(如创建、重新调度等)都要上锁。
- goroutine传递问题:经常在M之间传递“可运行”的goroutine会导致调度延迟增大,带来额外的性能损耗。
- 每个M都做内存缓存,导致内存占用过高,数据局部性较差。
- 因系统调用(syscall)而形成的频繁的工作线程阻塞和解除阻塞会带来额外的性能损耗。
- 现在版本:GPM调度器——Go1.1
有人曾说过:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。”
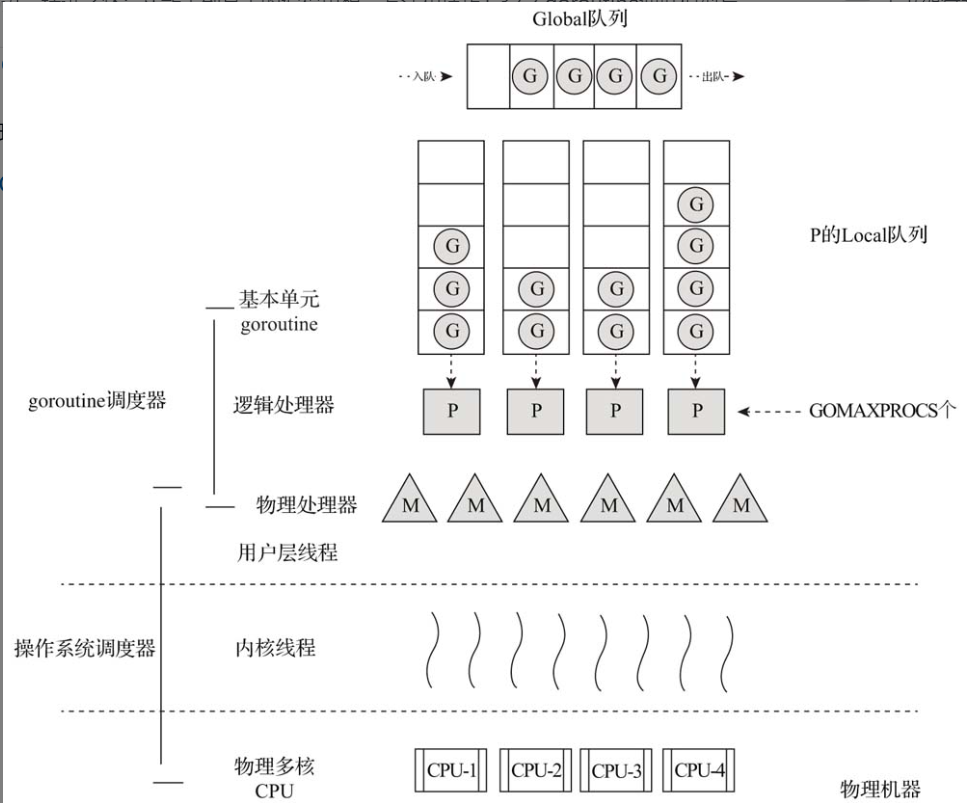
G:代表goroutine,存储了goroutine的执行栈信息、goroutine状态及goroutine的任务函数等。另外G对象是可以重用的。
P:代表逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理CPU核数>=P的数量)。P中最有用的是其拥有的各种G对象队列、链表、一些缓存和状态。Go从1.5版本开始将P的默认数量由1改为CPU核的数量(实际上还乘了每个核上硬线程数量)。
M:M代表着真正的执行计算资源。在绑定有效的P后,进入一个调度循环;而调度循环的机制大致是从各种队列、P的本地运行队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M。如此反复。M并不保留G状态,这是G可以跨M调度的基础。
抢占调度
细节分析:https://weread.qq.com/web/reader/f343248072895ed9f34f408k01332b9028a013d407161b5
与操作系统按时间片调度线程不同,Go中并没有时间片的概念。如果某个G没有进行系统调用(syscall)、没有进行I/O操作、没有阻塞在一个channel操作上,那么M是如何让G停下来并调度下一个可运行的G的呢?答案是:G是被抢占调度的。
Go1.2版本解决了之前版本无法抢占式调度的问题,这个抢占式调度的原理是在每个函数或方法的入口加上一段额外的代码,让运行时有机会检查是否需要执行抢占调度。这种协作式抢占调度的解决方案只是局部解决了“饿死”问题,对于没有函数调用而是纯算法循环计算的G(就是一大段代码),goroutine调度器依然无法抢占。
Go程序启动时,会新建一个M(机器线程)名为sysmon,简称监控线程。该M无需绑定P即可运行G,在整个程序运行过程中,该M主要完成以下几部分的工作:
- 释放闲置超过5分钟的span物理内存;
- 如果超过2分钟没有垃圾回收,强制执行;
- 将长时间未处理的netpoll结果添加到任务队列;
- 向长时间运行的G任务发出抢占调度;
- 收回因syscall长时间阻塞的P。
可以看出,sysmon执行内存回收以及对长时间运行的G进行抢占调度。怎么实现的呢?抢占判断!
当sysmon发现某个G运行时间过长时,就将该G的抢占位flag设置为true。这个G在下一次调用函数或方法之前就会判断该flag,如果flag为true,则将G移出运行状态并转入P本地队列/或全局队列。
另外,其实所谓的“有函数调用,就有了进入调度器代码的机会”,实际上是Go编译器在函数的入口处插入了一个运行时的函数调用:runtime.morestack_noctxt。这个函数会检查是否需要扩容连续栈,并进入抢占调度的逻辑中。
什么是扩容连续栈?简单理解,如果调用的函数还需要调用另外一个函数,那么则可能需要扩容。如果没有,则必定不需要扩容,那么go编译器很可能不会在函数调用前加入runtime.morestack_noctxt。同时,有时候内联优化也会取消函数调用。
值得注意的是,这种协作调度的方式完全依赖于运行的代码是否合规,如果是一个死循环代码,那么这个G将一直占用一个M,无法退出。因此在1.4版本之后,加入了非协作的调度方式,sysmon会通过信号将运行时间较长的程序强制调度。
有两个边界情况:
- 如果G被阻塞在某个channel操作或网络I/O操作上,那么G会被放置到某个等待队列中,而M会尝试运行P的下一个可运行的G。如果此时P没有可运行的G供M运行,那么M将解绑P,并进入挂起状态。当I/O操作完成或channel操作完成,在等待队列中的G会被唤醒,标记为runnable(可运行),并被放入某个P的队列中,绑定一个M后继续执行。
- 如果G被阻塞在某个系统调用上,那么不仅G会阻塞,执行该G的M也会解绑P(实质是被sysmon抢走了),与G一起进入阻塞状态。如果此时有空闲的M,则P会与其绑定并继续执行其他G;如果没有空闲的M,但仍然有其他G要执行,那么就会创建一个新M(线程)。当系统调用返回后,阻塞在该系统调用上的G会尝试获取一个可用的P,如果有可用P,之前运行该G的M将绑定P继续运行G;如果没有可用的P,那么G与M之间的关联将解除,同时G会被标记为runnable,放入全局的运行队列中,等待调度器的再次调度。
netpoller
值得一提的是,Go运行时已经实现了netpoller,这使得即便G发起网络I/O操作也不会导致M被阻塞(仅阻塞G),因而不会导致大量线程(M)被创建出来。
但是对于常规文件的I/O操作一旦阻塞,那么线程(M)将进入挂起状态,等待I/O返回后被唤醒。这种情况下P将与挂起的M分离,再选择一个处于空闲状态(idle)的M。如果此时没有空闲的M,则会新创建一个M(线程),这就是大量文件I/O操作会导致大量线程被创建的原因。
什么是netpoller?——简单来说是结合go routine实现的多路复用方式
协程间通信channel
多种并发场景代码:https://weread.qq.com/web/reader/f343248072895ed9f34f408k0f2324c028d0f28b5d492ee
Go的并发模型其实借鉴了CSP模型,即通信顺序进程(communication sequence process),如下图:

- 在CSP模型中,P与P之间应该是通过一个输入/输出原语来通信的。语言层面,Go针对CSP模型提供了三种并发原语。goroutine:对应CSP模型中的P,封装了数据的处理逻辑,是Go运行时调度的基本执行单元。
- channel:对应CSP模型中的输入/输出原语,用于goroutine之间的通信和同步。
- select:用于应对多路输入/输出,可以让goroutine同时协调处理多个channel操作。
channel是go用来进行协程间数据传递的手段,它不提倡使用共享内存,而是使用类似于管道的方式来进行数据传导:
ch := make(chan int) //必须先创建ch <- v // Send v to channel ch.v := <-ch // Receive from ch, and// assign value to v.
channel具有阻塞性质,只有当另一端处于就绪状态时才会进行数据传输,因此可以有效避免并发冲突。
发送端当无数据传递时,可以关闭channel,接收方可以通过返回值得知管道是否关闭,但这种方式一般只用于需要告知接收方无数据传输地场景,如终止range循环:
v, ok := <-ch // ok is flase 就表示管道已关闭//需要关闭管道的例子func fibonacci(n int, c chan int) {x, y := 0, 1for i := 0; i < n; i++ {c <- xx, y = y, x+y}close(c)}func main() {c := make(chan int, 10)go fibonacci(cap(c), c)for i := range c {fmt.Println(i)}}
buffered channel是一种特殊的channel,在声明时指定buffer长度,可以缓存一定的数据,但可能会造成死锁:
ch := make(chan int, 2)ch <- 1ch <- 2//ch <- 3 //插不进去fmt.Println(<-ch)fmt.Println(<-ch)//fmt.Println(<-ch) //读不出来
代码中注释的两行无论哪一行取消注销都会造成死锁错误.
select可以从多个管道中选择已就绪的管道执行,也就是说谁先就绪就选择哪个channel,还可设置default来进行兜底,类似于switch:
select {case <-tick:fmt.Println("tick.")case <-boom:fmt.Println("BOOM!")returndefault:fmt.Println(" .")time.Sleep(50 * time.Millisecond)}
Mutex
某些时候我们不需要进行多个协程间的数据通信,仅仅只是为了同步,这时就可以使用go标准库中的mutex,标准用法:
func (c *SafeCounter) Value(key string) int {c.mu.Lock()// Lock so only one goroutine at a time can access the map c.v.defer c.mu.Unlock()return c.v[key]}
使用defer来进行unlock可以确保锁的释放.
杂谈
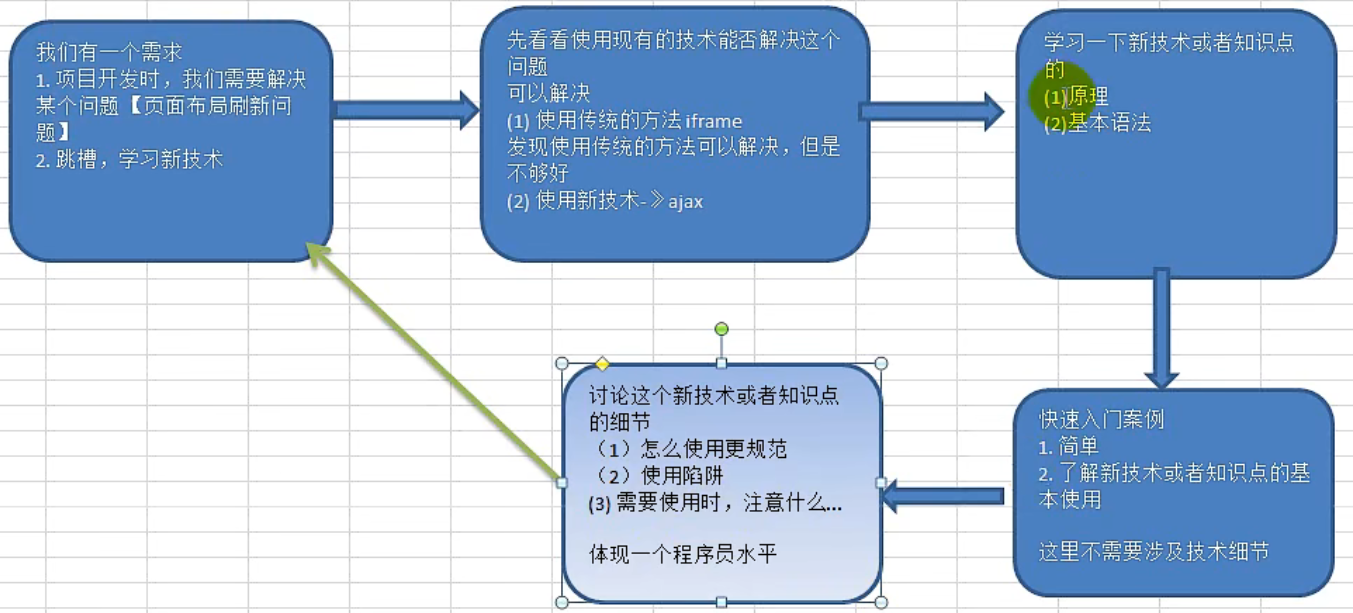
如何快速学习一门新技术并投入使用?
参考链接
Go语言精进之路:从新手到高手的编程思想、方法和技巧1-白明-微信读书
Go运行报错找不到包:package xxx is not in GOROOT_尚墨1111的博客-CSDN博客_go run 找不到包

若有收获,就点个赞吧
0 人点赞
