“如果你要组织一个活动怎么办?
你首先会想到,这个活动的流程是什么,需要配备哪些人员和物资,中途要不要休息,活动当前进行到哪里了……如果你是个精明的人,你大概会用表格把这些信息记录下来。
同理,你运行一个应用程序时,操作系统也要记录这个应用程序使用多少内存,打开了什么文件,当有些资源不可用的时候要不要睡眠,当前进程运行到哪里了。操作系统把这些信息综合统计,存放在内存中,抽象为进程。”
所以,什么是进程?
进程是一个程序运行时刻的实例;
进程是程序运行时所需资源的容器;
甚至说进程是一堆数据结构,由内核来管理。
进程的结构
在正式介绍操作系统中进程的结构时,先来看看多个进程是怎么共存于计算机中的。
之前介绍CPU工作模式中,提到了多个进程的高位地址其实都是同一份内核代码,它们之间的关系如下图:
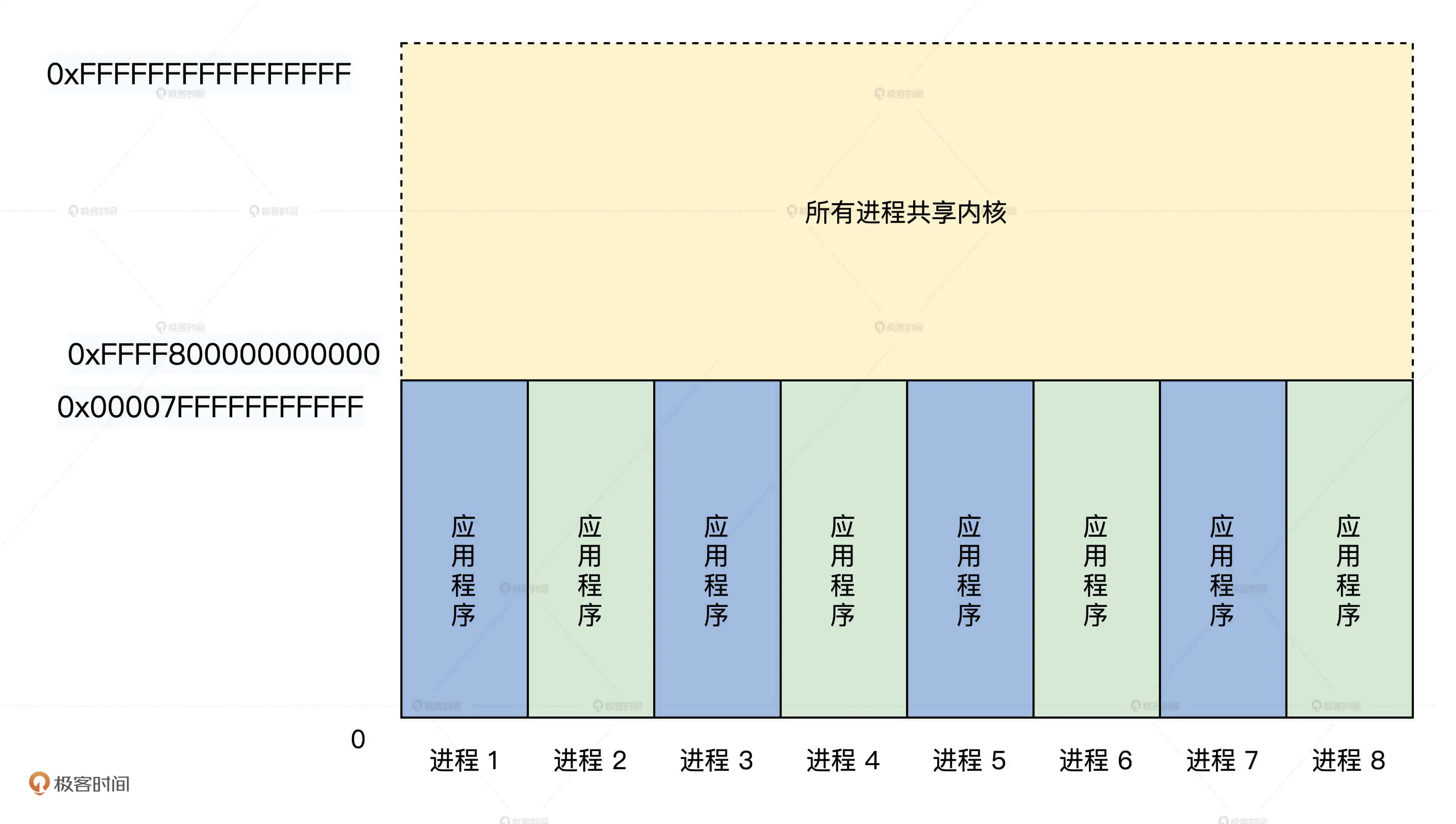
当 CPU 在 R0 特权级运行时,就运行在上半部分内核的地址空间中,当 CPU 在 R3 特权级时,就运行在下半部分的应用程序地址空间中(X86CPU一共有4个级别,不过只取了最高和最低的)。从左侧可以看出,各进程的虚拟地址空间是相同的,不过,它们之间物理地址不同,是通过MMU 页表进行隔离的,所以各个进程之间不会相互影响。
结合从用户态陷入到内核态(中断)、以及文件描述符等概念,一个细化的进程结构如下:
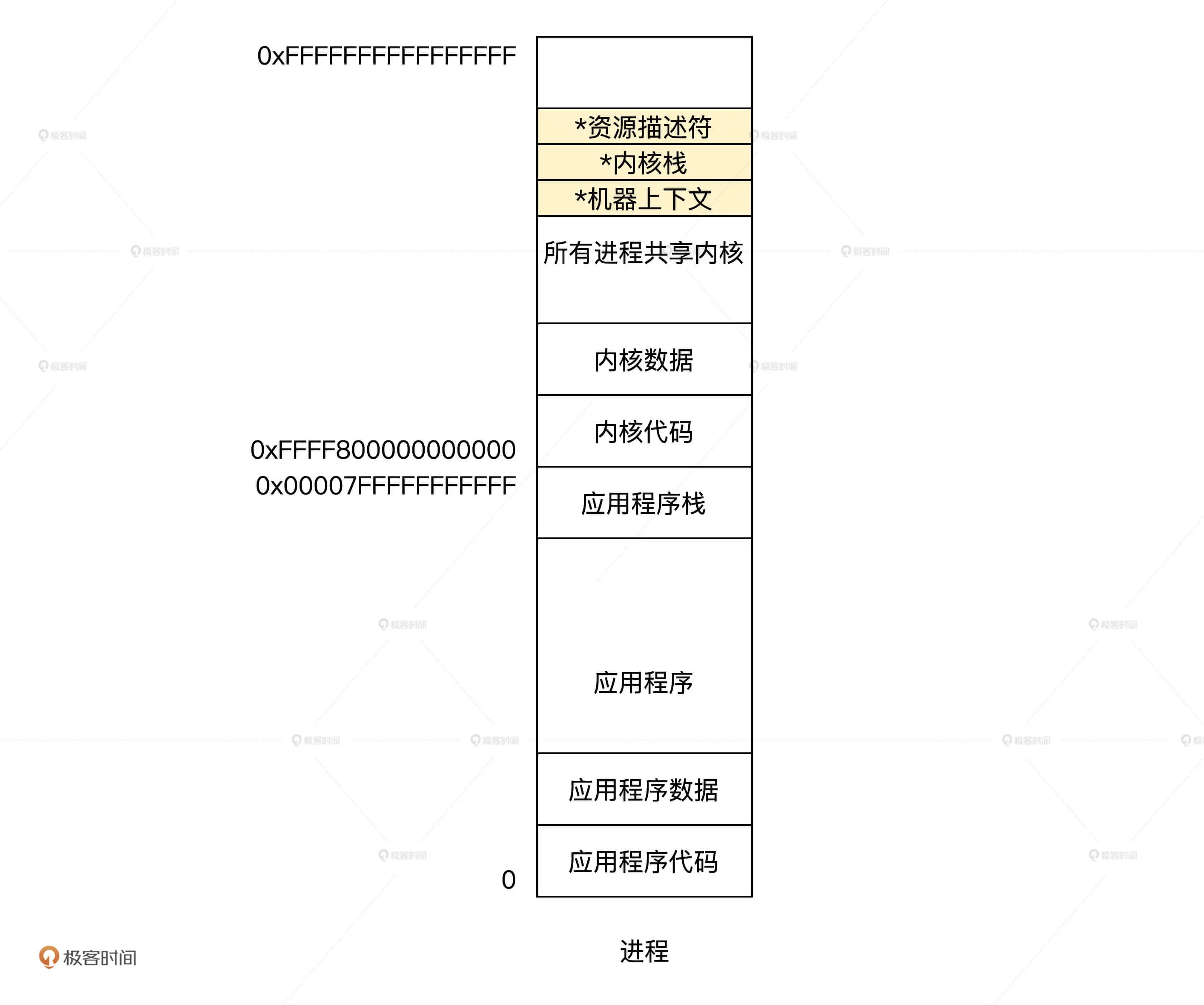
其中带 * 号是每个进程都有独立一份,有了这样的设计结构,多个进程就能并发运行了。将上述进程结构使用结构体代码表示如下:
typedef struct s_THREAD{spinlock_t td_lock; //进程的自旋锁list_h_t td_list; //进程链表uint_t td_flgs; //进程的标志uint_t td_stus; //进程的状态uint_t td_cpuid; //进程所在的CPU的iduint_t td_id; //进程的iduint_t td_tick; //进程运行了多少tickuint_t td_privilege; //进程的权限uint_t td_priority; //进程的优先级uint_t td_runmode; //进程的运行模式adr_t td_krlstktop; //应用程序内核栈顶地址adr_t td_krlstkstart; //应用程序内核栈开始地址adr_t td_usrstktop; //应用程序栈顶地址adr_t td_usrstkstart; //应用程序栈开始地址mmadrsdsc_t* td_mmdsc; //地址空间结构context_t td_context; //机器上下文件结构objnode_t* td_handtbl[TD_HAND_MAX];//打开的对象数组}thread_t;
其中,最下面的mmadrsdsc结构,即是之前内存章节所讲的虚拟地址空间(因为进程所面向的就是虚拟地址),每一个进程都有一个这样的结构体来“自我”分配进程中的东西;
Context结构体是机器的上下文结构,由两部分组成,一是CPU的寄存器(表示当前程序运行到哪个位置,现在各个寄存器的值是什么样子的,是进程的当前状态)在进入内核态时,被压入内核栈中;二是函数调用路径,即进入内核态之后调用函数的路径,对于一个进程来说,这是从子函数会退到调用函数所必备的(这是进程的以前状态)。它用结构体表示如下:
typedef struct s_CONTEXT{uint_t ctx_nextrip; //保存下一次运行的地址uint_t ctx_nextrsp; //保存下一次运行时内核栈的地址x64tss_t* ctx_nexttss; //指向tss结构}context_t;
其中,tss结构,是CPU硬性规定的结构,这个结构它本身的地址放在一个 GDT 表项中,由 CPU 的 tr 寄存器指向,tr 寄存器中的值是 GDT 中 x64tss_t 结构项对应的索引。x64tss_t 结构的代码如下:
// cosmos/hal/x86/halglobal.c// 每个CPU核心一个tssHAL_DEFGLOB_VARIABLE(x64tss_t,x64tss)[CPUCORE_MAX];typedef struct s_X64TSS{u32_t reserv0; //保留u64_t rsp0; //R0特权级的栈地址(拥有最高权限)u64_t rsp1; //R1特权级的栈地址,我们未使用u64_t rsp2; //R2特权级的栈地址,我们未使用u64_t reserv28;//保留u64_t ist[7]; //我们未使用u64_t reserv92;//保留u16_t reserv100;//保留u16_t iobase; //我们未使用}__attribute__((packed)) x64tss_t;
CPU 在发生中断时,会根据中断门描述里的目标段选择子,进行必要的特权级切换。
特权级的切换就必须要切换栈,CPU 硬件会自己把当前 rsp 寄存器保存到内部的临时寄存器 tmprsp;
然后从 x64tss_t 结构体中找出对应的栈地址,装入 rsp 寄存器中;接着,再把当前的 ss、tmprsp、rflags、cs、rip,依次压入当前 rsp 指向的栈中。
objnode是一个对象数组,即是资源描述符,文件是在内核态下打开的,这个结构体就保存着指向某个进程所拥有的文件的指针。
新建进程
那么怎么建立一个进程?
初始化进程结构体thread_t(建立进程的应用程序栈和进程的内核栈,进程地址空间等),而后将其加入到进程调度系统。
整个过程,初始化进程结构体,就好比招募一个员工,而后把他放到候选人列表指派任务。
建立进程的接口函数:
thread_t *krlnew_thread(void *filerun, uint_t flg, uint_t prilg, uint_t prity, size_t usrstksz, size_t krlstksz){size_t tustksz = usrstksz, tkstksz = krlstksz;//对参数进行检查,不合乎要求就返回NULL表示创建失败if (filerun == NULL || usrstksz > DAFT_TDUSRSTKSZ || krlstksz > DAFT_TDKRLSTKSZ){return NULL;}if ((prilg != PRILG_USR && prilg != PRILG_SYS) || (prity >= PRITY_MAX)){return NULL;}//进程应用程序栈大小检查,大于默认大小则使用默认大小if (usrstksz < DAFT_TDUSRSTKSZ){tustksz = DAFT_TDUSRSTKSZ;}//进程内核栈大小检查,大于默认大小则使用默认大小if (krlstksz < DAFT_TDKRLSTKSZ){tkstksz = DAFT_TDKRLSTKSZ;}//是否建立内核进程if (KERNTHREAD_FLG == flg){return krlnew_kern_thread_core(filerun, flg, prilg, prity, tustksz, tkstksz);}//是否建立普通进程else if (USERTHREAD_FLG == flg){return krlnew_user_thread_core(filerun, flg, prilg, prity, tustksz, tkstksz);}return NULL;}
内核进程
其实内核进程就是用进程的方式去运行一段内核代码,那么这段代码就可以随时暂停或者继续运行,又或者和其它代码段并发运行,只是这种进程永远不会回到进程应用程序地址空间中去,只会在内核地址空间中运行。
thread_t *krlnew_kern_thread_core(void *filerun, uint_t flg, uint_t prilg, uint_t prity, size_t usrstksz, size_t krlstksz){thread_t *ret_td = NULL;bool_t acs = FALSE;adr_t krlstkadr = NULL;//分配内核栈空间krlstkadr = krlnew(krlstksz);if (krlstkadr == NULL){return NULL;}//建立thread_t结构体的实例变量ret_td = krlnew_thread_dsc();if (ret_td == NULL){//创建失败必须要释放之前的栈空间acs = krldelete(krlstkadr, krlstksz);if (acs == FALSE){return NULL;}return NULL;}//设置进程权限ret_td->td_privilege = prilg;//设置进程优先级ret_td->td_priority = prity;//设置进程的内核栈顶和内核栈开始地址ret_td->td_krlstktop = krlstkadr + (adr_t)(krlstksz - 1);ret_td->td_krlstkstart = krlstkadr;//初始化进程的内核栈krlthread_kernstack_init(ret_td, filerun, KMOD_EFLAGS);//加入进程调度系统krlschdclass_add_thread(ret_td);//返回进程指针return ret_td;}
其中调用的 krlnew_thread_dsc()函数是为了初始化thread_t结构体中的变量。
值得一提的是后面初始化进程内核栈函数:krlthread_kernstack_init。
为什么要初始化内核栈?
就不能把内核栈全部设为0?当然不行,我们初始化进程的内核栈,其实是为了在进程的内核栈中放置一份 CPU 的寄存器数据。
嗯?这话是什么意思?
这份 CPU 寄存器数据是一个进程机器上下文的一部分,当一个进程开始运行时,我们将会使用“pop”指令从进程的内核栈中弹出到 CPU 中,这样 CPU 就开始运行进程了。而如果这个数据全为空,那显然没法继续往下执行了。因此我们需要对内核栈进行相应的初始化。初始化内核态进程的内核栈代码如下:
void krlthread_kernstack_init(thread_t *thdp, void *runadr, uint_t cpuflags){//处理栈顶16字节对齐thdp->td_krlstktop &= (~0xf);thdp->td_usrstktop &= (~0xf);//内核栈顶减去intstkregs_t结构的大小intstkregs_t *arp = (intstkregs_t *)(thdp->td_krlstktop - sizeof(intstkregs_t));//把intstkregs_t结构的空间初始化为0hal_memset((void*)arp, 0, sizeof(intstkregs_t));//rip寄存器的值设为程序运行首地址arp->r_rip_old = (uint_t)runadr;//cs寄存器的值设为内核代码段选择子arp->r_cs_old = K_CS_IDX;arp->r_rflgs = cpuflags;//返回进程的内核栈arp->r_rsp_old = thdp->td_krlstktop;arp->r_ss_old = 0;//其它段寄存器的值设为内核数据段选择子arp->r_ds = K_DS_IDX;arp->r_es = K_DS_IDX;arp->r_fs = K_DS_IDX;arp->r_gs = K_DS_IDX;//设置进程下一次运行的地址为runadrthdp->td_context.ctx_nextrip = (uint_t)runadr;//设置进程下一次运行的栈地址为arpthdp->td_context.ctx_nextrsp = (uint_t)arp;return;}
注意,上述是内核态的内核栈初始化,而非内核态的进程获取到的内核栈内容是不一样,结构一样:
void krlthread_userstack_init(thread_t *thdp, void *runadr, uint_t cpuflags){//处理栈顶16字节对齐thdp->td_krlstktop &= (~0xf);thdp->td_usrstktop &= (~0xf);//内核栈顶减去intstkregs_t结构的大小intstkregs_t *arp = (intstkregs_t *)(thdp->td_krlstktop - sizeof(intstkregs_t));//把intstkregs_t结构的空间初始化为0hal_memset((void*)arp, 0, sizeof(intstkregs_t));//rip寄存器的值设为程序运行首地址arp->r_rip_old = (uint_t)runadr;//cs寄存器的值设为应用程序代码段选择子arp->r_cs_old = U_CS_IDX;arp->r_rflgs = cpuflags;//返回进程应用程序空间的栈arp->r_rsp_old = thdp->td_usrstktop;//其它段寄存器的值设为应用程序数据段选择子arp->r_ss_old = U_DS_IDX;arp->r_ds = U_DS_IDX;arp->r_es = U_DS_IDX;arp->r_fs = U_DS_IDX;arp->r_gs = U_DS_IDX;//设置进程下一次运行的地址为runadrthdp->td_context.ctx_nextrip = (uint_t)runadr;//设置进程下一次运行的栈地址为arpthdp->td_context.ctx_nextrsp = (uint_t)arp;return;}
上述代码中初始化进程的内核栈,所使用的段选择子指向的是应用程序的代码段和数据段,这个代码段和数据段它们特权级为 R3,CPU 正是根据这个代码段、数据段选择子来切换 CPU 工作特权级的。这样,CPU 的执行流就可以返回到进程的应用程序空间了。
普通进程
内核进程和普通进程的区别在于内核栈初始化的调用函数不同以及普通程序多了一个应用程序栈:
thread_t *krlnew_user_thread_core(void *filerun, uint_t flg, uint_t prilg, uint_t prity, size_t usrstksz, size_t krlstksz){thread_t *ret_td = NULL;bool_t acs = FALSE;adr_t usrstkadr = NULL, krlstkadr = NULL;//分配应用程序栈空间usrstkadr = krlnew(usrstksz);if (usrstkadr == NULL){return NULL;}//分配内核栈空间krlstkadr = krlnew(krlstksz);if (krlstkadr == NULL){if (krldelete(usrstkadr, usrstksz) == FALSE){return NULL;}return NULL;}//建立thread_t结构体的实例变量ret_td = krlnew_thread_dsc();//创建失败必须要释放之前的栈空间if (ret_td == NULL){acs = krldelete(usrstkadr, usrstksz);acs = krldelete(krlstkadr, krlstksz);if (acs == FALSE){return NULL;}return NULL;}//设置进程权限ret_td->td_privilege = prilg;//设置进程优先级ret_td->td_priority = prity;//设置进程的内核栈顶和内核栈开始地址ret_td->td_krlstktop = krlstkadr + (adr_t)(krlstksz - 1);ret_td->td_krlstkstart = krlstkadr;//设置进程的应用程序栈顶和内核应用程序栈开始地址ret_td->td_usrstktop = usrstkadr + (adr_t)(usrstksz - 1);ret_td->td_usrstkstart = usrstkadr;//初始化返回进程应用程序空间的内核栈(跟内核态是不一样的)krlthread_userstack_init(ret_td, filerun, UMOD_EFLAGS);//加入调度器系统krlschdclass_add_thread(ret_td);return ret_td;}
总结一下,每个进程都有一个内核栈,指向同一个块内核内存区域,共享一份内核代码和内核数据。内核进程一份页表,用户进程两份页表,用户进程额外多了一份用户空间页表,与其它用户进程互不干扰。
进程调度
为什么需要进程调度?
- CPU同一个时刻只能运行一个进程,而CPU的个数总是比进程个数少,因此需要进程调度系统来让多个进程都能使用CPU一段时间;
- 当某一个进程由于没有资源而阻塞时,就需要及时让出CPU,避免影响系统整体性能。
如下图所示为多进程调度示意图:

进程的状态
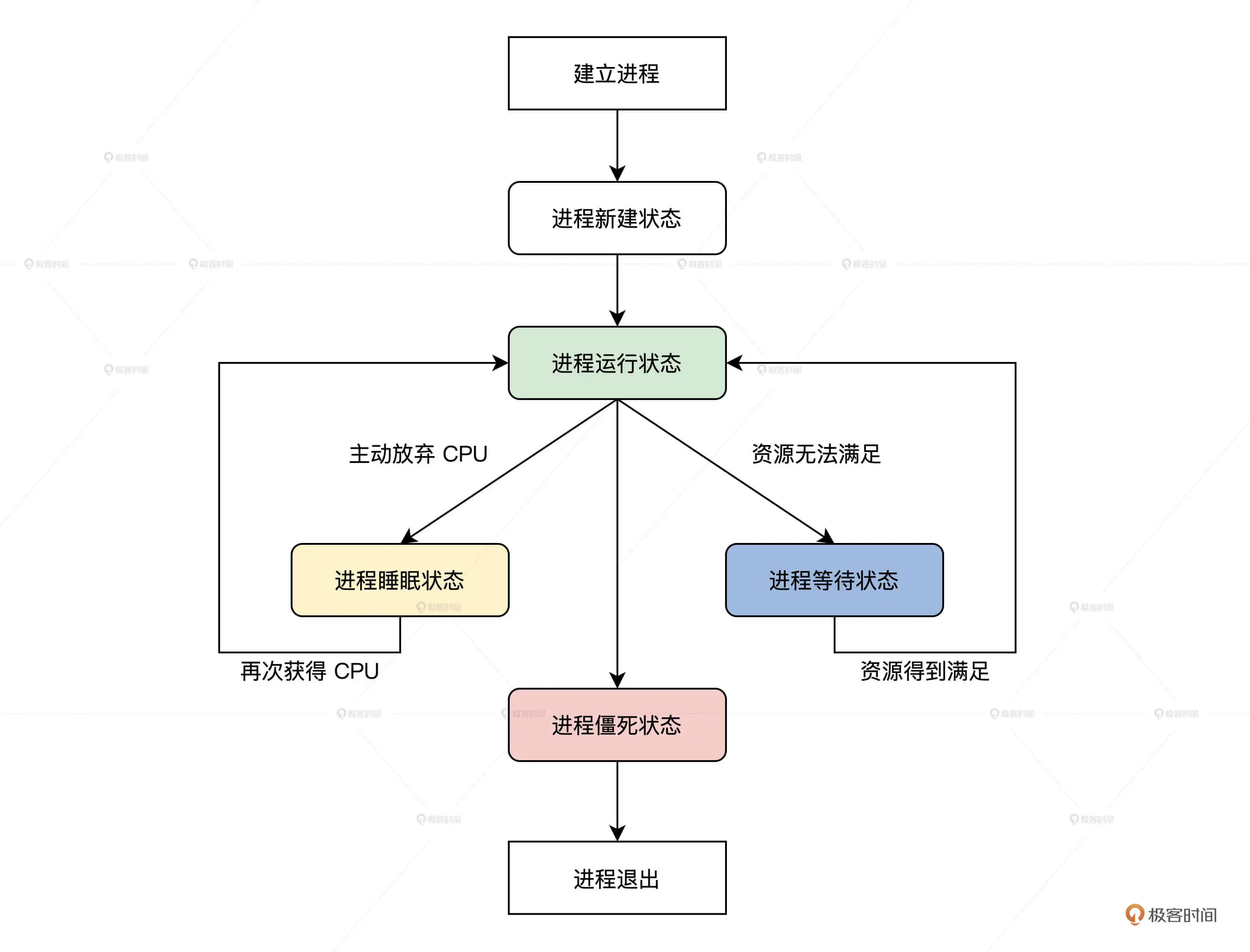
为了便于进行后面的进程调度,我们首先需要对各个进程的状态进行表示,将进程分为正在运行状态、睡眠状态(主动或者被动)、等待状态(等待资源完好)、新建状态、僵尸状态(出错或者因为未知原因卡住了):
#define TDSTUS_RUN 0 //进程运行状态#define TDSTUS_SLEEP 3 //进程睡眠状态#define TDSTUS_WAIT 4 //进程等待状态#define TDSTUS_NEW 5 //进程新建状态#define TDSTUS_ZOMB 6 //进程僵死状态
它们之间的转换关系如下:
组织进程
在解决了进程的表示之后,我们需要使用某种数据结构将所有的进程管理起来。考虑到进程可以随时创建或者销毁退出,我们使用链表来串联进程,并且不同的优先级,具有不同的链表头,这就便于后面进程调度算法的开发。
//挂载进程的链表typedef struct s_THRDLST{list_h_t tdl_lsth; //挂载进程的链表头thread_t* tdl_curruntd; //该链表上正在运行的进程uint_t tdl_nr; //该链表上进程个数}thrdlst_t;//某一核CPU的进程管理typedef struct s_SCHDATA{spinlock_t sda_lock; //自旋锁uint_t sda_cpuid; //当前CPU iduint_t sda_schdflgs; //标志uint_t sda_premptidx; //进程抢占计数uint_t sda_threadnr; //进程数uint_t sda_prityidx; //当前优先级thread_t* sda_cpuidle; //当前CPU的空转进程thread_t* sda_currtd; //当前正在运行的进程thrdlst_t sda_thdlst[PRITY_MAX]; //进程链表数组}schdata_t;//整个系统的进程管理typedef struct s_SCHEDCALSS{spinlock_t scls_lock; //自旋锁uint_t scls_cpunr; //CPU个数uint_t scls_threadnr; //系统中所有的进程数uint_t scls_threadid_inc; //分配进程id所用schdata_t scls_schda[CPUCORE_MAX]; //每个CPU调度数据结构}schedclass_t;
他们之间的关系用下图来表示:
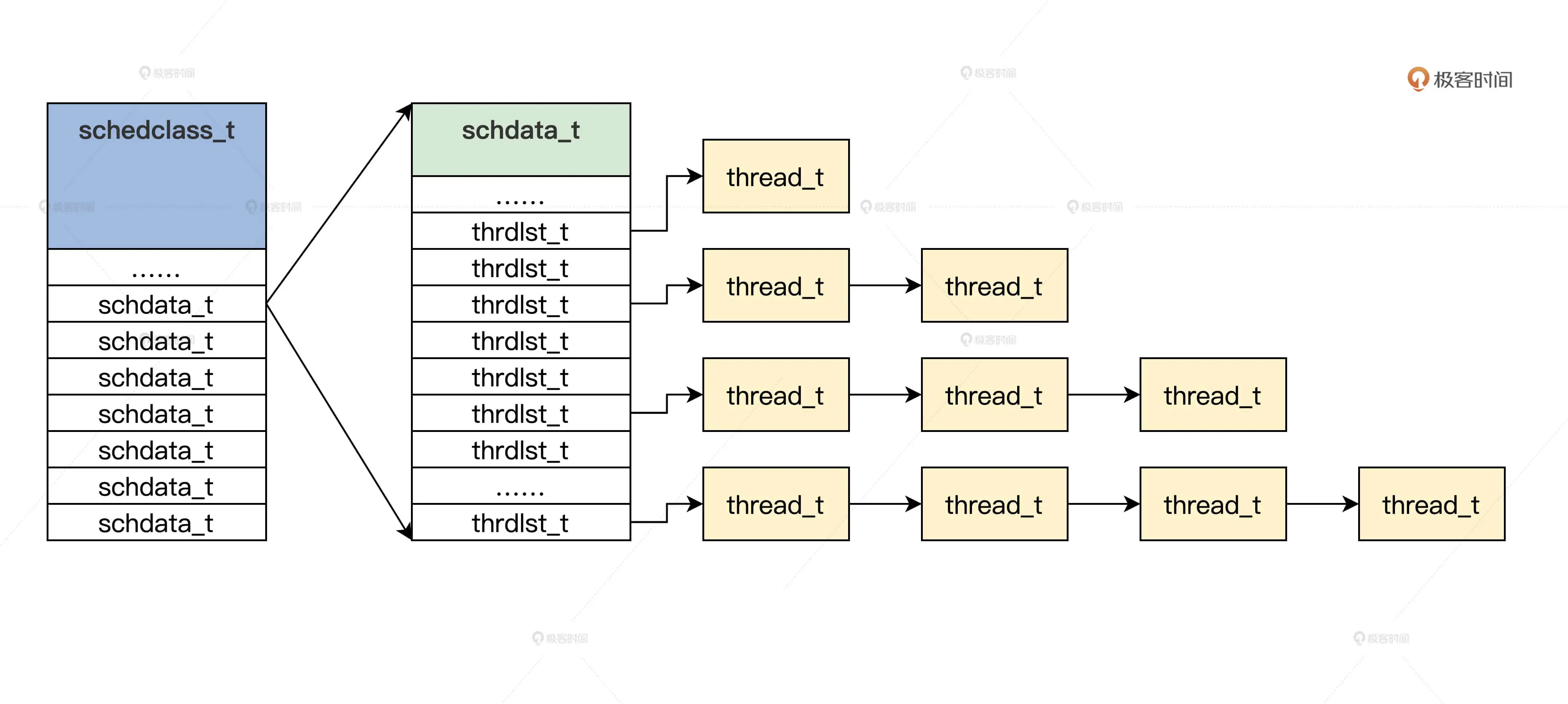
有多个CPU,就有多少个schdata_t,因为进程调度是将进程分配到具体的CPU核上的。在初始化内核层时init_krl 函数就会调用相应的初始化函数对这个schedclass进行初始化。
进程调度器的实现
接口函数
进程调度器是为了在合适的时间点,合适的代码执行路径上进行进程调度。就是从当前运行进程切换到另一个进程上运行,让当前进程停止运行,由 CPU 开始执行另一个进程的代码。
那我们就需要获取当前运行的进程,以及下一个将要运行的进程,接口函数就出来了:
void krlschedul(){thread_t *prev = krlsched_retn_currthread(),//返回当前运行进程*next = krlsched_select_thread();//选择下一个运行的进程save_to_new_context(next, prev);//从当前进程切换到下一个进程return;}
现在的问题就变成了,如何获取当前运行进程,以及下一个进程是谁?
还记得在组织进程时,定义了三个结构体,其中一个schdata结构体中,就存储了当前CPU所运行的进程:
thread_t *krlsched_retn_currthread(){uint_t cpuid = hal_retn_cpuid();//通过cpuid获取当前cpu的调度数据结构schdata_t *schdap = &osschedcls.scls_schda[cpuid];if (schdap->sda_currtd == NULL){//若调度数据结构中当前运行进程的指针为空,就出错死机hal_sysdie("schdap->sda_currtd NULL");}return schdap->sda_currtd;//返回当前运行的进程}
那么如何获得下一个将要运行的进程呢?
进程调度算法
选择下一个进程,就涉及到进程调度算法了,一个好的操作系统的流畅度、稳定性等,都跟进程调度算法具有密不可分的联系,它关乎到进程的吞吐量,能否及时响应请求,CPU 的利用率,各个进程之间运行获取资源的公平性。
常见的进程调度算法有:1.先来先去服务2.时间片轮转法3.多级反馈队列算法4.最短进程优先5.最短剩余时间优先6.最高响应比优先7.多级反馈队列调度算法
我们来实现一个最简单调度算法——优先级调度算法,始终选择链表中优先级最高的算法即可。
thread_t *krlsched_select_thread(){thread_t *retthd, *tdtmp;cpuflg_t cufg;uint_t cpuid = hal_retn_cpuid();schdata_t *schdap = &osschedcls.scls_schda[cpuid];krlspinlock_cli(&schdap->sda_lock, &cufg);for (uint_t pity = 0; pity < PRITY_MAX; pity++){//从最高优先级开始扫描if (schdap->sda_thdlst[pity].tdl_nr > 0){//若当前优先级的进程链表不为空if (list_is_empty_careful(&(schdap->sda_thdlst[pity].tdl_lsth)) == FALSE){//取出当前优先级进程链表下的第一个进程tdtmp = list_entry(schdap->sda_thdlst[pity].tdl_lsth.next, thread_t, td_list);list_del(&tdtmp->td_list);//脱链if (schdap->sda_thdlst[pity].tdl_curruntd != NULL){//将这sda_thdlst[pity].tdl_curruntd的进程挂入链表尾list_add_tail(&(schdap->sda_thdlst[pity].tdl_curruntd->td_list), &schdap->sda_thdlst[pity].tdl_lsth);}schdap->sda_thdlst[pity].tdl_curruntd = tdtmp;retthd = tdtmp;//将选择的进程放入sda_thdlst[pity].tdl_curruntd中,并返回goto return_step;}if (schdap->sda_thdlst[pity].tdl_curruntd != NULL){//若sda_thdlst[pity].tdl_curruntd不为空就直接返回它retthd = schdap->sda_thdlst[pity].tdl_curruntd;goto return_step;}}}//如果最后也没有找到进程就返回默认的空转进程schdap->sda_prityidx = PRITY_MIN;retthd = krlsched_retn_idlethread();return_step://解锁并返回进程krlspinunlock_sti(&schdap->sda_lock, &cufg);return retthd;}
上述代码所做的工作很简单:扫描优先级链表,如果该优先级链表不为空,那就取出链表上的第一个进程。如果为空,那就继续扫描下一个优先级链表。
有个问题,如果···所有链表中都没有进程怎么办?直接返回一个NULL?
不行,因为调度器的功能必须完成从一个进程到下一个进程的切换,如果没有下一个进程,而上一个进程又不能运行了,调度器将无处可去,整个系统也将停止运行。
为了解决这个窘境,内核设计者提出一个:空转进程的概念。
idle空转进程,又称为系统空闲进程,一般优先级最低,系统没事干的时候才执行它。实际上在某些系统会在idle中处理一些内存回收之类的事情。其存在的原因是为了让调度器有事情做。来看看那这个空转进程的实现:
void cpu_idle (void){...while (1) {void (*idle)(void) = pm_idle;if (!idle)idle = default_idle;while (!current->need_resched)idle();schedule();...}
参考链接:https://www.zhihu.com/question/26756156/answer/33912754
进程切换
解决了如何获取当前进程以及下一个进程如何获取的问题之后,最关键的一步来了,怎么实现进程的切换?
在第一节进程的结构中,我们提到了进程在内核中的函数调用路径,那么什么是函数调用路径?
举个例子,比如进程 P1 调用了函数 A,接着在函数 A 中调用函数 B,然后在函数 B 中调用了函数 C,最后在函数 C 中调用了调度器函数 S,这个函数 A 到函数 S 就是进程 P1 的函数调用路径。
进程 P2 开始调用了函数 D,接着在函数 D 中调用函数 E,然后在函数 E 中又调用了函数 F,最后在函数 F 中调用了调度器函数 S,函数 D、E、F 到函数 S 就是进程 P2 的函数调用路径。——彭老师
这些函数调用路径是通过栈来保存的,对于运行在内核空间的进程,就是保存在对应的内核栈中:

进程切换函数要完成的功能就是这些:
- 首先,把当前进程的通用寄存器保存到当前进程的内核栈中;
- 然后,保存 CPU 的 RSP 寄存器到当前进程的机器上下文结构中
- 读取保存在下一个进程机器上下文结构中的 RSP 的值,把它存到 CPU 的 RSP 寄存器中;
- 接着,调用一个函数切换 MMU 页表;
- 最后,从下一个进程的内核栈中恢复下一个进程的通用寄存器。
上面的步骤是进程切换的核心,理解了这些步骤,就知道进程切换到底是怎么运行的了。
进程切换函数的实现如下:
void save_to_new_context(thread_t *next, thread_t *prev){__asm__ __volatile__("pushfq \n\t"//保存当前进程的标志寄存器"cli \n\t" //关中断//保存当前进程的通用寄存器"pushq %%rax\n\t""pushq %%rbx\n\t""pushq %%rcx\n\t""pushq %%rdx\n\t""pushq %%rbp\n\t""pushq %%rsi\n\t""pushq %%rdi\n\t""pushq %%r8\n\t""pushq %%r9\n\t""pushq %%r10\n\t""pushq %%r11\n\t""pushq %%r12\n\t""pushq %%r13\n\t""pushq %%r14\n\t""pushq %%r15\n\t"//保存CPU的RSP寄存器到当前进程的机器上下文结构中"movq %%rsp,%[PREV_RSP] \n\t"//把下一个进程的机器上下文结构中的RSP的值,写入CPU的RSP寄存器中"movq %[NEXT_RSP],%%rsp \n\t"//事实上这里已经切换到下一个进程了,因为切换进程的内核栈//调用__to_new_context函数切换MMU页表"callq __to_new_context\n\t"//恢复下一个进程的通用寄存器"popq %%r15\n\t""popq %%r14\n\t""popq %%r13\n\t""popq %%r12\n\t""popq %%r11\n\t""popq %%r10\n\t""popq %%r9\n\t""popq %%r8\n\t""popq %%rdi\n\t""popq %%rsi\n\t""popq %%rbp\n\t""popq %%rdx\n\t""popq %%rcx\n\t""popq %%rbx\n\t""popq %%rax\n\t""popfq \n\t" //恢复下一个进程的标志寄存器//输出当前进程的内核栈地址: [ PREV_RSP ] "=m"(prev->td_context.ctx_nextrsp)//读取下一个进程的内核栈地址: [ NEXT_RSP ] "m"(next->td_context.ctx_nextrsp), "D"(next), "S"(prev)//为调用__to_new_context函数传递参数: "memory");return;}
捋一捋:通过切换进程的内核栈,导致切换进程,因为进程的函数调用路径就保存在对应的内核栈中,只要调用 krlschedul 函数,最后的函数调用路径一定会停在 save_to_new_context 函数中,当 save_to_new_context 函数一返回,就会导致回到调用 save_to_new_context 函数的下一行代码开始运行,在这里就是返回到 krlschedul 函数中,最后层层返回。
用图来表示一下(理解,重点!):

我们可以发现这个机制的一个关键点:那就是将要运行的进程必须调用过krlschedul函数,才能够实现进程的恢复。
那么已知新建进程绝对没有调用过 krlschedul 函数,所以它得进行特殊处理。比如在_to_new_context中:
void __to_new_context(thread_t *next, thread_t *prev){uint_t cpuid = hal_retn_cpuid();schdata_t *schdap = &osschedcls.scls_schda[cpuid];//设置当前运行进程为下一个运行的进程schdap->sda_currtd = next;//设置下一个运行进程的tss为当前CPU的tssnext->td_context.ctx_nexttss = &x64tss[cpuid];//设置当前CPU的tss中的R0栈为下一个运行进程的内核栈next->td_context.ctx_nexttss->rsp0 = next->td_krlstktop;//装载下一个运行进程的MMU页表hal_mmu_load(&next->td_mmdsc->msd_mmu);if (next->td_stus == TDSTUS_NEW){ //如果是新建进程第一次运行就要进行处理next->td_stus = TDSTUS_RUN;retnfrom_first_sched(next);}return;}
进程是否是新进程,通过td_stus标志来判断,如果是新建进程,那就进行特殊处理retnfrom_first_sched函数如下:
void retnfrom_first_sched(thread_t *thrdp){__asm__ __volatile__("movq %[NEXT_RSP],%%rsp\n\t" //设置CPU的RSP寄存器为该进程机器上下文结构中的RSP//恢复进程保存在内核栈中的段寄存器"popq %%r14\n\t""movw %%r14w,%%gs\n\t""popq %%r14\n\t""movw %%r14w,%%fs\n\t""popq %%r14\n\t""movw %%r14w,%%es\n\t""popq %%r14\n\t""movw %%r14w,%%ds\n\t"//恢复进程保存在内核栈中的通用寄存器"popq %%r15\n\t""popq %%r14\n\t""popq %%r13\n\t""popq %%r12\n\t""popq %%r11\n\t""popq %%r10\n\t""popq %%r9\n\t""popq %%r8\n\t""popq %%rdi\n\t""popq %%rsi\n\t""popq %%rbp\n\t""popq %%rdx\n\t""popq %%rcx\n\t""popq %%rbx\n\t""popq %%rax\n\t"//恢复进程保存在内核栈中的RIP、CS、RFLAGS,(有可能需要恢复进程应用程序的RSP、SS)寄存器"iretq\n\t":: [ NEXT_RSP ] "m"(thrdp->td_context.ctx_nextrsp): "memory");}
通过上述代码的void可以看出:retnfrom_first_sched 函数不会返回到调用它的 __to_new_context 函数中,而是直接运行新建进程的相关代码,也就不会出现之前的那个问题了。
进程的等待与唤醒
在上一节,我们实现了进程的切换,但是进程的状态除了新建、运行等,还有睡眠和等待,这两种状态又改如何实现呢?
进程得不到所需的某个资源时就会进入等待状态,直到这种资源可用时,才会被唤醒。
那么使用什么数据结构来完成进程从等待状态下唤醒?之前在介绍同步底层原理时,介绍了信号量,它就可以实现这样的功能。先将需要等待的进程挂载在链表上:
typedef struct s_KWLST{spinlock_t wl_lock; //自旋锁uint_t wl_tdnr; //等待进程的个数list_h_t wl_list; //挂载等待进程的链表头}kwlst_t;
如果某一个进程想进入等待状态,那就将其挂载到上述的结构体中:
void krlsched_wait(kwlst_t *wlst){cpuflg_t cufg, tcufg;uint_t cpuid = hal_retn_cpuid();schdata_t *schdap = &osschedcls.scls_schda[cpuid];//获取当前正在运行的进程thread_t *tdp = krlsched_retn_currthread();uint_t pity = tdp->td_priority;krlspinlock_cli(&schdap->sda_lock, &cufg);krlspinlock_cli(&tdp->td_lock, &tcufg);tdp->td_stus = TDSTUS_WAIT;//设置进程状态为等待状态list_del(&tdp->td_list);//脱链krlspinunlock_sti(&tdp->td_lock, &tcufg);if (schdap->sda_thdlst[pity].tdl_curruntd == tdp){schdap->sda_thdlst[pity].tdl_curruntd = NULL;}schdap->sda_thdlst[pity].tdl_nr--;krlspinunlock_sti(&schdap->sda_lock, &cufg);//*** 在这 这就是上述那个结构体的操作封装函数krlwlst_add_thread(wlst, tdp);//将进程加入等待结构中return;}
注意,某一个进程进入等待状态,是自愿的。
而想要将一个进程唤醒,那就是进入等待状态的反操作:
void krlsched_up(kwlst_t *wlst){cpuflg_t cufg, tcufg;uint_t cpuid = hal_retn_cpuid();schdata_t *schdap = &osschedcls.scls_schda[cpuid];thread_t *tdp;uint_t pity;//取出等待数据结构第一个进程并从等待数据结构中删除tdp = krlwlst_del_thread(wlst);pity = tdp->td_priority;//获取进程的优先级krlspinlock_cli(&schdap->sda_lock, &cufg);krlspinlock_cli(&tdp->td_lock, &tcufg);tdp->td_stus = TDSTUS_RUN;//设置进程的状态为运行状态krlspinunlock_sti(&tdp->td_lock, &tcufg);list_add_tail(&tdp->td_list, &(schdap->sda_thdlst[pity].tdl_lsth));//加入进程优先级链表schdap->sda_thdlst[pity].tdl_nr++;krlspinunlock_sti(&schdap->sda_lock, &cufg);return;}
当某一个资源准备好了之后,就会调用上面这个函数,从而唤醒正处于等待状态下的进程。
空转进程
在之前简要介绍了空转进程,空转进程是0号进程,其他进程都是在空转进程调用进程调度函数之后,再由进程调度器所调用的。
那么在COSMOS中,我们是怎么新建一个空转进程的呢?
thread_t *new_cpuidle_thread(){thread_t *ret_td = NULL;bool_t acs = FALSE;adr_t krlstkadr = NULL;uint_t cpuid = hal_retn_cpuid();schdata_t *schdap = &osschedcls.scls_schda[cpuid];krlstkadr = krlnew(DAFT_TDKRLSTKSZ);//分配进程的内核栈if (krlstkadr == NULL){return NULL;}//分配thread_t结构体变量ret_td = krlnew_thread_dsc();if (ret_td == NULL){acs = krldelete(krlstkadr, DAFT_TDKRLSTKSZ);if (acs == FALSE){return NULL;}return NULL;}//设置进程具有系统权限ret_td->td_privilege = PRILG_SYS;ret_td->td_priority = PRITY_MIN;//设置进程的内核栈顶和内核栈开始地址ret_td->td_krlstktop = krlstkadr + (adr_t)(DAFT_TDKRLSTKSZ - 1);ret_td->td_krlstkstart = krlstkadr;//初始化进程的内核栈 *****krlthread_kernstack_init(ret_td, (void *)krlcpuidle_main, KMOD_EFLAGS);//设置调度系统数据结构的空转进程和当前进程为ret_tdschdap->sda_cpuidle = ret_td;schdap->sda_currtd = ret_td;return ret_td;}//新建空转进程void new_cpuidle(){thread_t *thp = new_cpuidle_thread();//建立空转进程if (thp == NULL){//失败则主动死机hal_sysdie("newcpuilde err");}kprint("CPUIDLETASK: %x\n", (uint_t)thp);return;}
其中,初始化空转进程的内核栈时,传入了一个krlcpuildle_main,这就是空转进程的主函数:
void krlcpuidle_main()
{
uint_t i = 0;
for (;; i++)
{
kprint("空转进程运行:%x\n", i);//打印
krlschedul();//调度进程
}
return;
}
可以看到,空转进程的主函数,就是不停的打印东西,而后调度进程,如果此时有其他的进程需要处理,那就会调度其他的进程来执行;如果没有其他的进程,则继续执行空转进程。
如何运行空转进程?由于空转进程是第一个进程,因此我们也需要使用之前在进程切换中所用到的那个函数retnfrom_first_sched,用它来处理新建的进程:
void krlcpuidle_start()
{
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
//取得空转进程
thread_t *tdp = schdap->sda_cpuidle;
//设置空转进程的tss和R0特权级的栈
tdp->td_context.ctx_nexttss = &x64tss[cpuid];
tdp->td_context.ctx_nexttss->rsp0 = tdp->td_krlstktop;
//设置空转进程的状态为运行状态
tdp->td_stus = TDSTUS_RUN;
//启动进程运行
retnfrom_first_sched(tdp);
return;
}
以上我们所讲的有关空转进程的初始化操作,都是在内核层初始化时所进行的:
void init_krl()
{
init_krlsched();//初始化进程调度器
init_krlcpuidle();//初始化空转进程
die(0);//防止init_krl函数返回
//它一旦返回,就无处可去了,必须一直在这卡着
//等待进程调度器去执行相应的操作
return;
}
//初始化空转进程
void init_krlcpuidle()
{
new_cpuidle();//建立空转进程
krlcpuidle_start();//启动空转进程运行
return;
}
上述的进程调度切换器还有一点不足,那就是必须进程主动让出CPU,但是实际的操作系统中是有时间片的概念的,即是每一个进程即便自己还未执行完,一定时间过后就被迫让出CPU,CPU的使用权分给其他进程,这是为了保证系统中所有的进程都能够有机会运行,而不会因为一个进程而卡住。
这种时间片的方式需要设备的支持,即时钟信号,在第九章设备IO中会对这个部分进行补充。
拓展:Linux进程调度
相关结构体
在Linux中,进程是用下面这个结构体task_struct来抽象的:
struct task_struct {
struct thread_info thread_info;//处理器特有数据
volatile long state; //进程状态
void *stack; //进程内核栈地址
refcount_t usage; //进程使用计数
int on_rq; //进程是否在运行队列上
int prio; //动态优先级
int static_prio; //静态优先级
int normal_prio; //取决于静态优先级和调度策略
unsigned int rt_priority; //实时优先级
const struct sched_class *sched_class;//指向其所在的调度类
struct sched_entity se;//普通进程的调度实体
struct sched_rt_entity rt;//实时进程的调度实体
struct sched_dl_entity dl;//采用EDF算法调度实时进程的调度实体
struct sched_info sched_info;//用于调度器统计进程的运行信息
struct list_head tasks;//所有进程的链表
struct mm_struct *mm; //指向进程内存结构
struct mm_struct *active_mm;
pid_t pid; //进程id
struct task_struct __rcu *parent;//指向其父进程
struct list_head children; //链表中的所有元素都是它的子进程
struct list_head sibling; //用于把当前进程插入到兄弟链表中
struct task_struct *group_leader;//指向其所在进程组的领头进程
u64 utime; //用于记录进程在用户态下所经过的节拍数
u64 stime; //用于记录进程在内核态下所经过的节拍数
u64 gtime; //用于记录作为虚拟机进程所经过的节拍数
unsigned long min_flt;//缺页统计
unsigned long maj_flt;
struct fs_struct *fs; //进程相关的文件系统信息
struct files_struct *files;//进程打开的所有文件
struct vm_struct *stack_vm_area;//内核栈的内存区
};
注意到上述代码的13-15行的进程调度实体。它其实是 Linux 进程调度系统的一部分,被嵌入到了 Linux 进程数据结构中,与调度器进行关联,能间接地访问进程,这种高内聚低耦合的方式,保证了进程数据结构和调度数据结构相互独立,我们后面可以分别做改进、优化,这是一种高明的软件设计思想。
进程调度实体的结构体如下:
struct sched_entity {
struct load_weight load;//表示当前调度实体的权重
struct rb_node run_node;//红黑树的数据节点
struct list_head group_node;// 链表节点,被链接到 percpu 的 rq->cfs_tasks
unsigned int on_rq; //当前调度实体是否在就绪队列上
u64 exec_start;//当前实体上次被调度执行的时间
u64 sum_exec_runtime;//当前实体总执行时间
u64 prev_sum_exec_runtime;//截止到上次统计,进程执行的时间
u64 vruntime;//当前实体的虚拟时间
u64 nr_migrations;//实体执行迁移的次数
struct sched_statistics statistics;//统计信息包含进程的睡眠统计、等待延迟统计、CPU迁移统计、唤醒统计等。
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;// 表示当前实体处于调度组中的深度
struct sched_entity *parent;//指向父级调度实体
struct cfs_rq *cfs_rq;//当前调度实体属于的 cfs_rq.
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
struct sched_avg avg ;// 记录当前实体对于CPU的负载
#endif
};
注意到16行有一个cfs_fq,它是标识这个进程调度实体隶属于哪一个进程运行队列。Linux 定义了一个进程运行队列结构,每个 CPU 分配一个这样的进程运行队列结构实例变量,进程运行队列结构的代码如下。
struct rq {
raw_spinlock_t lock;//自旋锁
unsigned int nr_running;//多个就绪运行进程
struct cfs_rq cfs; //作用于完全公平调度算法的运行队列
struct rt_rq rt;//作用于实时调度算法的运行队列
struct dl_rq dl;//作用于EDF调度算法的运行队列
struct task_struct __rcu *curr;//这个运行队列当前正在运行的进程
struct task_struct *idle;//这个运行队列的空转进程
struct task_struct *stop;//这个运行队列的停止进程
struct mm_struct *prev_mm;//这个运行队列上一次运行进程的mm_struct
unsigned int clock_update_flags;//时钟更新标志
u64 clock; //运行队列的时间
//后面的代码省略
};
有三个不同的运行队列,是因为作用于三种不同的调度算法。以cfs_rq为例:
struct rb_root_cached {
struct rb_root rb_root; //红黑树的根
struct rb_node *rb_leftmost;//红黑树最左子节点
};
struct cfs_rq {
struct load_weight load;//cfs_rq上所有调度实体的负载总和
unsigned int nr_running;//cfs_rq上所有的调度实体不含调度组中的调度实体
unsigned int h_nr_running;//cfs_rq上所有的调度实体包含调度组中所有调度实体
u64 exec_clock;//当前 cfs_rq 上执行的时间
u64 min_vruntime;//最小虚拟运行时间
struct rb_root_cached tasks_timeline;//所有调度实体的根
struct sched_entity *curr;//当前调度实体
struct sched_entity *next;//下一个调度实体
struct sched_entity *last;//上次执行过的调度实体
//省略不关注的代码
};
用一幅图来表示上面这些的关系:

task_struct 结构中包含了 sched_entity 结构。sched_entity 结构是通过红黑树组织起来的,红黑树的根在 cfs_rq 结构中,cfs_rq 结构又被包含在 rq 结构,每个 CPU 对应一个 rq 结构。这样,我们就把所有运行的进程组织起来了。
为了支持不同的调度算法,Linux定义了调度器类:
struct sched_class {
//向运行队列中添加一个进程,入队
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
//向运行队列中删除一个进程,出队
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
//检查当前进程是否可抢占
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
//从运行队列中返回可以投入运行的一个进程
struct task_struct *(*pick_next_task)(struct rq *rq);
} ;
这些调度类按照一定的优先级,依次调用:
//定义在链接脚本文件中
extern struct sched_class __begin_sched_classes[];
extern struct sched_class __end_sched_classes[];
#define sched_class_highest (__end_sched_classes - 1)
#define sched_class_lowest (__begin_sched_classes - 1)
#define for_class_range(class, _from, _to) \
for (class = (_from); class != (_to); class--)
//遍历每个调度类
#define for_each_class(class) \
for_class_range(class, sched_class_highest, sched_class_lowest)
extern const struct sched_class stop_sched_class;//停止调度类
extern const struct sched_class dl_sched_class;//Deadline调度类
extern const struct sched_class rt_sched_class;//实时调度类
extern const struct sched_class fair_sched_class;//CFS调度类
extern const struct sched_class idle_sched_class;//空转调度类
CFS调度器
权重
接下来我们来研究一下Linux的CFS调度器(完全公平调度算法)。
首先提一句,CFS思路很简单,就是根据各个进程的权重分配运行时间。
在CFS调度算法中,是没有时间片的概念,而是CPU使用时间的比例,而每一个进程所占的比例就是权重。
举个例子,现在有 A、B 两个进程。进程 A 的权重是 1024,进程 B 的权重是 2048。那么进程 A 获得 CPU 的时间比例是 1024/(1024+2048) = 33.3%。进程 B 获得的 CPU 时间比例是 2048/(1024+2048)=66.7%。
因此,权重越大,分配的时间比例越大,就相当于进程的优先级越高。
可以得出这样一个进程时间的公式:
<font style="color:rgb(51, 51, 51);">进程的时间 = CPU 总时间 * 进程的权重 / 就绪队列所有进程权重之和</font>
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
调度延迟
调度延迟是保证每一个可运行的进程,都至少运行一次的时间间隔。 例如ABC三个程序,每个程序运行1ms,那么调度延迟就是3ms;都运行10ms,那么调度延迟就是30ms…… 随着进程的增加,每个进程分配的时间在减少,进程调度次数会增加,调度器占用的时间就会增加。因此,CFS 调度器的调度延迟时间的设定并不是固定的。当运行进程少于 8 个的时候,调度延迟是固定的 6ms 不变。当运行进程个数超过 8 个时,就要保证每个进程至少运行一段时间,才被调度。这个“至少一段时间”叫作最小调度粒度时间。在 CFS 默认设置中,最小调度粒度时间是 0.75ms。 ### 虚拟时间 在之前介绍进程调度实体时,有一个属性是虚拟时间:u64 vruntime;//当前实体的虚拟时间。
为什么CFS叫做完全公平调度器,从上面介绍来看,完全是根据权重来比较的,这一点也不公平!其实这个所谓的“公平”,CFS是这样实现的:它记录了每个进程的执行时间,为保证每个进程运行时间的公平,哪个进程运行的时间最少,就会让哪个进程运行。
注意,上面所说的运行时间,是“虚拟时间”。
虚拟时间,是CFS调度器通过相关的公式计算出来的:
<font style="color:rgb(51, 51, 51);">vruntime = wtime*( NICE_0_LOAD/weight)</font>
通过这个公式可以看到,权重越大的进程获得的虚拟运行时间越小。
举个例子,设系统的调度延迟是 10ms,现在一共有两个进程AB在运行,权重分别是 1024 和 820(nice 值分别是 0 和 1)。
则,进程 A 获得的运行时间是 10x1024/(1024+820)=5.6ms;
进程 B 获得的执行时间是 10x820/(1024+820)=4.4ms。
很明显,这两个进程的实际执行时间是不等的,但 CFS 调度器想保证每个进程的运行时间相等。
我们通过上述的虚拟时间转换公式来进行转换:
这样的话,进程 A 的虚拟时间为:5.6(1024/1024)=5.6;
进程 B 的虚拟时间为:4.4(1024/820)=5.6。
所以,虽然进程 A 和进程 B 的权重不一样,但是计算得到的虚拟时间是一样的。
CFS 调度只要保证每个进程运行的虚拟时间一致即可。于是在选择下一个即将运行的进程时,只需要找到虚拟时间最小的进程就行了。
> 这其实是一种CFS调度器自欺欺人的做法
>
那么如何快速找到虚拟时间最下的进程呢?还记得进程调度结果图中那个红黑树嘛?
在运行队列中用红黑树结构组织进程的调度实体,红黑树的 key正是进程虚拟时间,这样进程就以进程的虚拟时间被红黑树组织起来了。红黑树的最左子节点,就是虚拟时间最小的进程,随着时间的推移进程会从红黑树的左边跑到右,然后从右边跑到左边,如此循环往复。
总之,在CFS调度器中,将进程优先级这个概念弱化,而是强调进程的权重。一个进程的权重越大,则说明这个进程更需要运行,因此它的虚拟运行时间就越小,这样被调度的机会就越大。
调度延迟
调度延迟是保证每一个可运行的进程,都至少运行一次的时间间隔。
例如ABC三个程序,每个程序运行1ms,那么调度延迟就是3ms;都运行10ms,那么调度延迟就是30ms……
随着进程的增加,每个进程分配的时间在减少,进程调度次数会增加,调度器占用的时间就会增加。因此,CFS 调度器的调度延迟时间的设定并不是固定的。当运行进程少于 8 个的时候,调度延迟是固定的 6ms 不变。当运行进程个数超过 8 个时,就要保证每个进程至少运行一段时间,才被调度。这个“至少一段时间”叫作最小调度粒度时间。在 CFS 默认设置中,最小调度粒度时间是 0.75ms。
这章节的知识大纲如下:

致谢

若有收获,就点个赞吧
0 人点赞
