这部分想写好还是困难的
一般意义上,“正排”索引就是拿着字符串去网页、文件里一个一个找,这样的效率无疑是很低的,而倒排文件索引就是在建立索引时就确定字符串在哪个网页的哪里出现过在,这样查找时不需要再一个一个查找,其结构可以理解为:<br />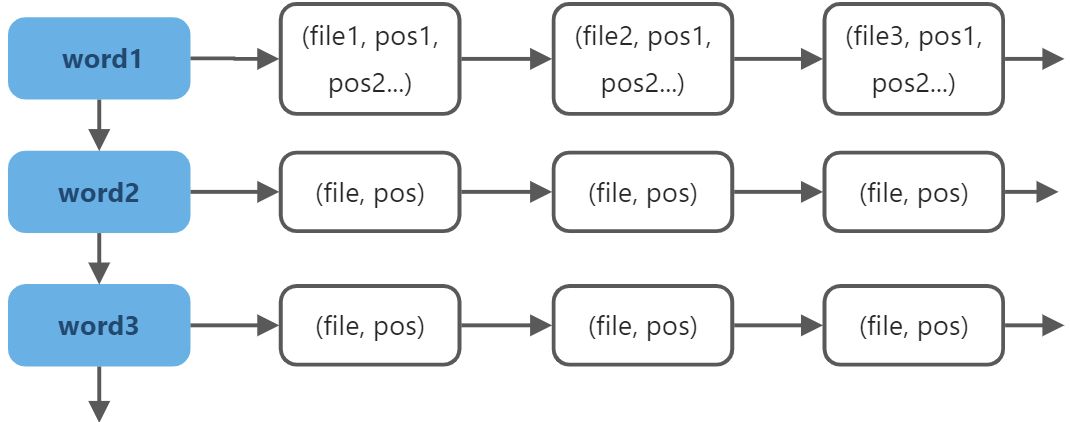<br />一个简化的索引生成过程可以描述为:<br />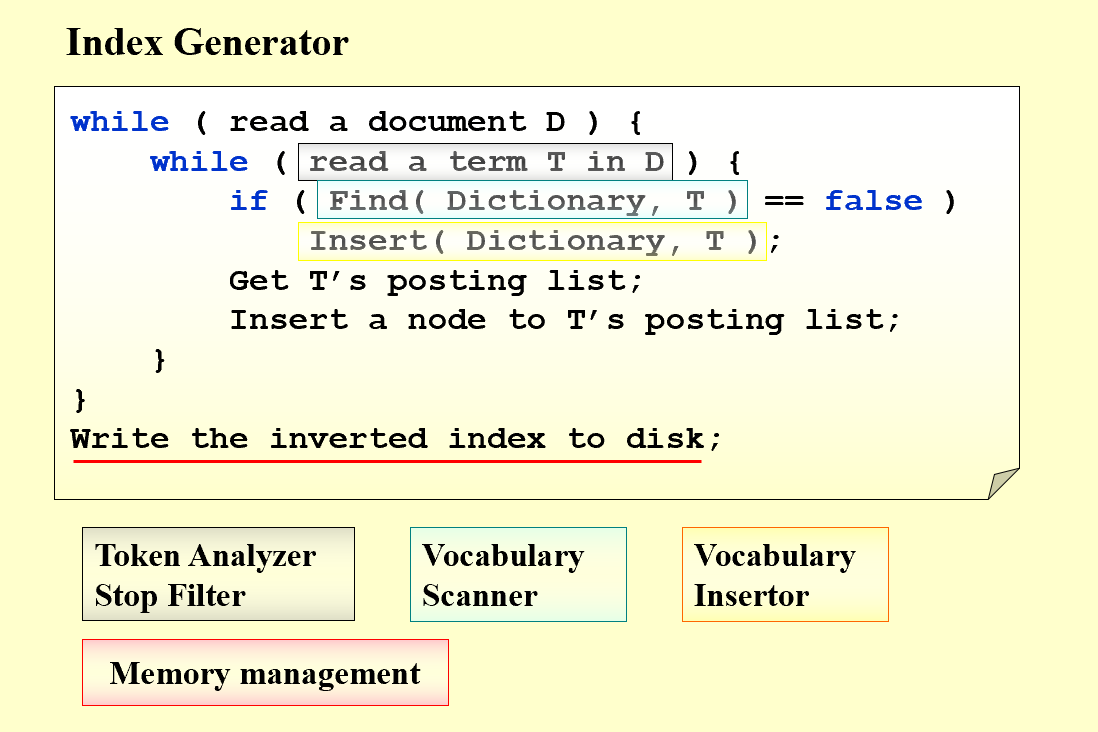<br />当读入一个term时,我们需要
- 提取词根
- 检查 Stop Words ( 那些大量出现的词,e.g. and )

建立索引的方式有很多种,常用的是B树、B+树、Tries和Hashing。
当我们的内存不足以将索引在一台机器上建立时,可以考虑分布式索引: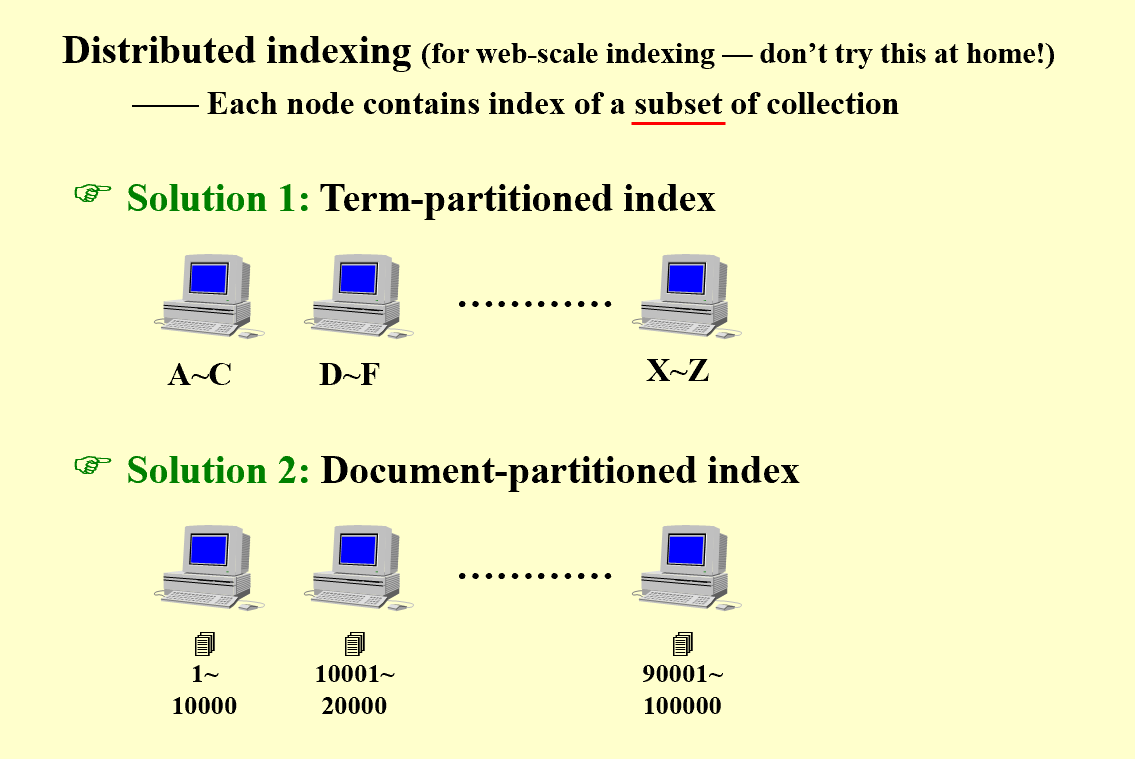
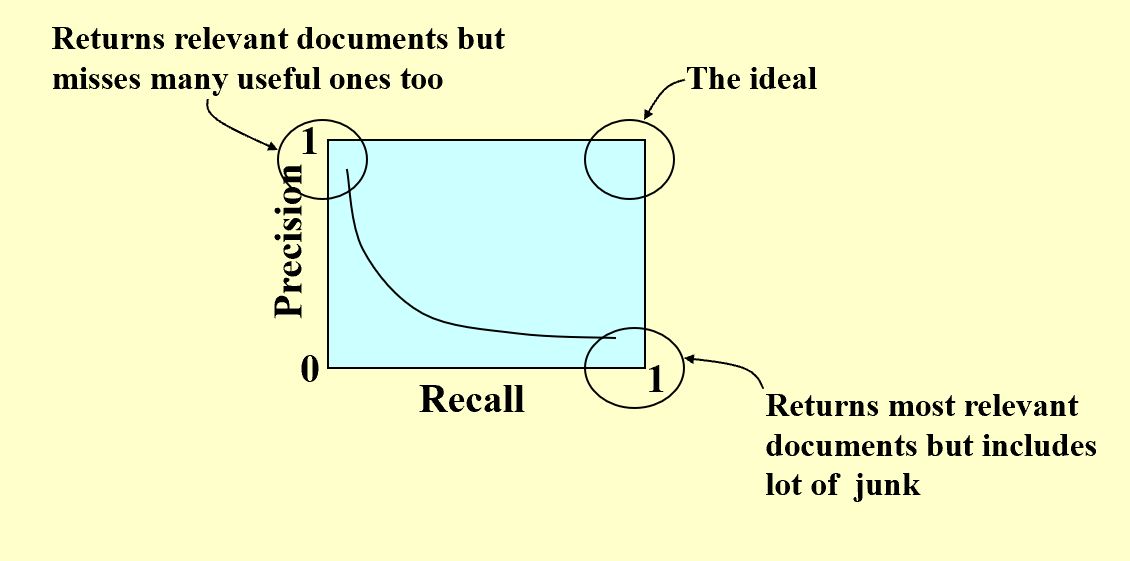
两个新概念:Precision 和 Recall
precison 是在查询到的文件中相关的比例,recall 是相关的文件中被查询到的比例。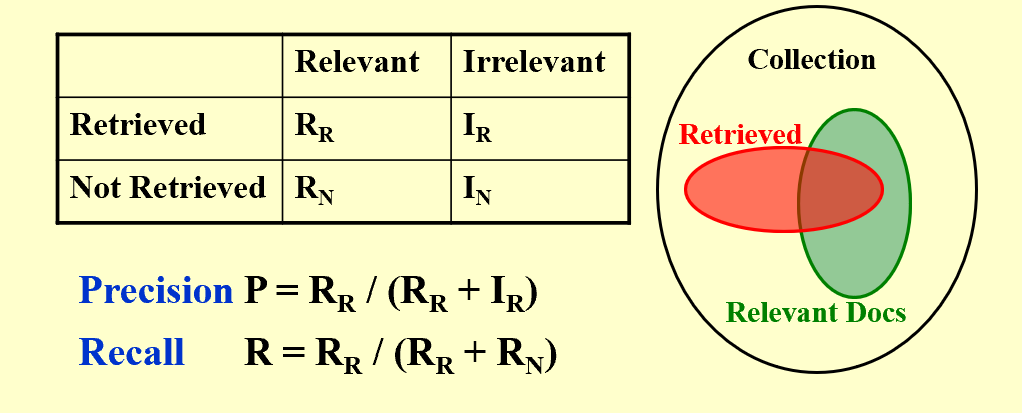

若有收获,就点个赞吧
0 人点赞
