- Grading Policy
- Quizs: 4~5 times 10%
- Assignments: 10%
- Experiments & Projects: 30%
- Final: Close Book( A4 cheat paper ) 50%
孙建伶智云 https://media.zju.edu.cn/index.php?r=course/live-view&id=37938&tenant=112 陈璐智云 https://media.cmc.zju.edu.cn/index.php?r=course/live-view&id=37958&tenant=112
Ch1 & Ch2
前面两章的内容我试着用思维导图的形式记录!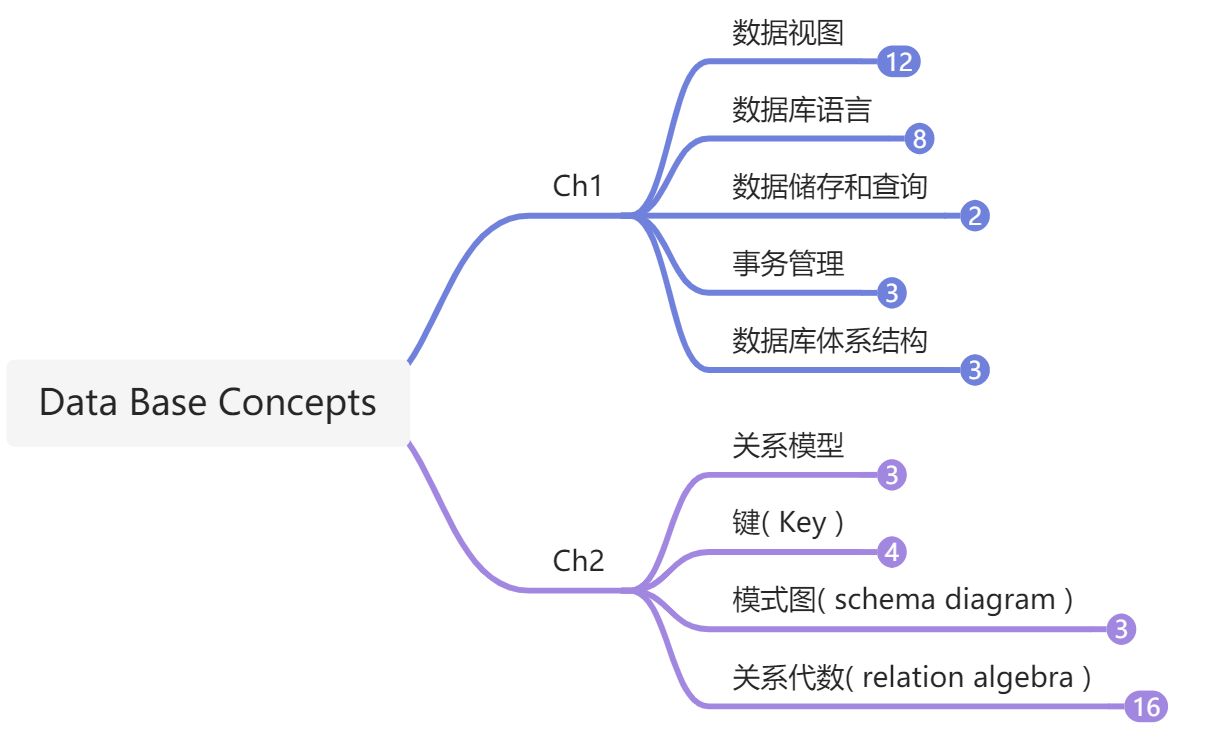
Ch3 Intro. to SQL
Basic Queries
For Single Relation
all和distinct分别表示从查询结果中不去重和去重。*表示所有属性- 在查询中可以使用
+ - * /运算符。 - 在
where中可以使用or and not和比较运算符。 as可以执行更名操作 ```plsql select all dept_name from instructor; select distinct dept_name from instructor; select * from department;
select salary * 1.1 from instructor;
select name from instructor where dept_name = ‘Comp.Sci’ and salary > 7000;
select salary from instructor as FOO
<a name="Q4oO6"></a>### For Multiple Relation通常查询需要从多个关系(笛卡尔积)中获取信息。下面的例子中我们假设`dept_name`是`instructor`的外键。```plsqlselect name, instructor, dept_namefrom instrcutor, departmentwhere instructor.dept_name = department.dept_name and dept_name = 'Comp.Sci';
Natural Join
在多关系查询中,我们需要匹配不同属性中的相同属性,SQL中自然连接可以实现这样的操作
select * from r1 natural join r2 natural join ...
Rename Operation
更名操作在重命名关系时很有用,下面这个例子是从instructor中选出那些薪水比Comp.Sci.系中薪水高的讲师名字。
select distinct T.namefrom instructor as T, instructor as Swhere T.salary > S.salary and S.dept_name = 'Comp.Sci.';
String Operation
- 转义:
\ like可以用于匹配字符,not like%可以匹配任意子串'Intro%'匹配任何以Intro开头的字符串'%Comp%'匹任何包含Comp的字符串
_匹配任意一个字符'___'匹配只含三个字符的字符串'___%'匹配至少含三个字符的字符串
-
Set Operation
union:并intersect:交expect:差
Null Values
unknown用于涉及空值的比较
如果**where**子句对某个元组的判断结果是**false**或者**unknown**,则该元组不能被加入结果中。
Aggregate Functions | 聚合函数
Basic Aggregation
select avg( salary ) as avg_salaryfrom instructorwhere dept_name = 'Comp.Sci.';select count(*) from course;
Grouping
嵌套子查询
in & exists
都可以用来做集合成员关系的测试,但是执行流程上有很大不同,参考这里。
一个not exists的例子,选出选了生物系所有课的学生,考虑否定之否定,即生物系的课没有不选的学生。下图子查询返回的结果是学生 S 没选的生物系课的集合,外层查询则验证 S 是否不存在于这个集合中
unique
用在子查询的是否返回重复元组的测试中。另外 sjl 上课时提到一句 sql 的子查询中不能使用distinct,搜了之后发现一个是效率问题,另一个是distinct在in``or``any``some``exists的子查询中不会做任何事。
Ch6 Entity-Relation Model | ER 模型
只记录一些听到的关键点,会比较乱
- ER 图基本结构
- 业务逻辑是通过 ER 图抽象出需求,然后再通过转化到关系数据库上的具体实现。
- 实现时,每个实体集和关系集可以看做一张表。多对多的关系必须转化为一张表。一对多和多对一关系可以合并到“多”上去。
- Reduction to Relation
- 强实体集和弱实体集:强实体集直接转化,弱实体集加上强的主键再转化,关系不用转化
- 多对多:实体集直接转化,关系集取两者主键和自己的属性(如果有)转化为表
- 多对一和一对多:可以合并“一”的主键到“多”上去,也可以转化为单独的关系
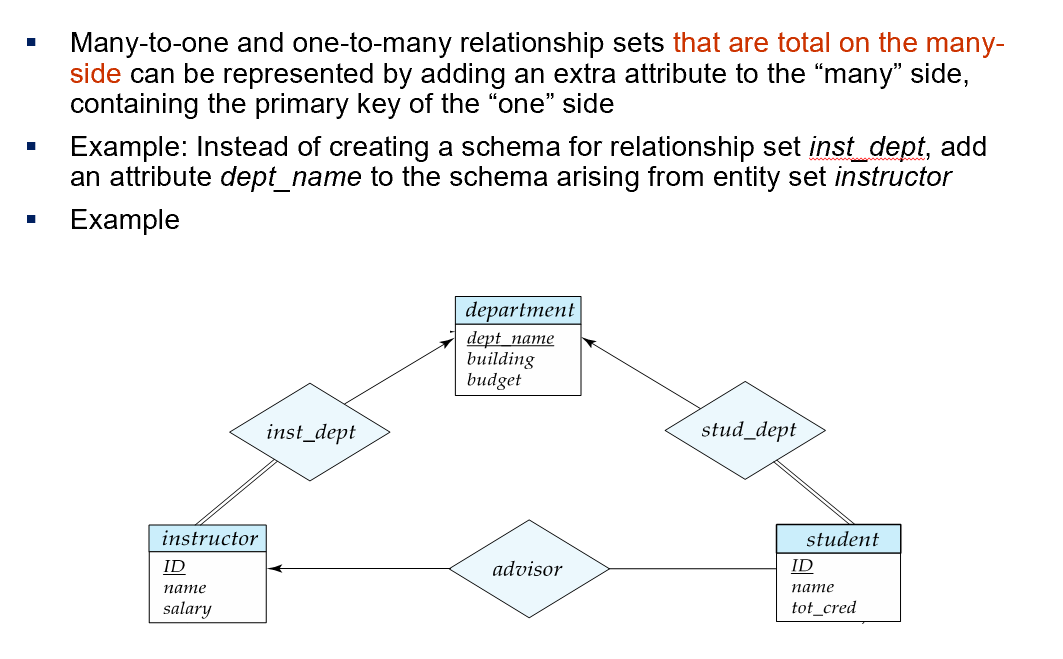
- 合并的好处:信息集中在一张表里,可以避免一些连接操作;坏处:若“多”的一侧并不是全部参与,会导致空值。若参与度很低,空值很多,会造成浪费
- 一对一:任意一方都可以当做“多”,但不要选择部分参与的一侧做“多”,否则会导致空值
- 复合关系:直接一股脑扔进去,不过结构特征会被抹平。转化多值属性简单的方式是直接建一个新表,例如
inst_phone_number(ID, phone_number)
- 常见 ER 图错误
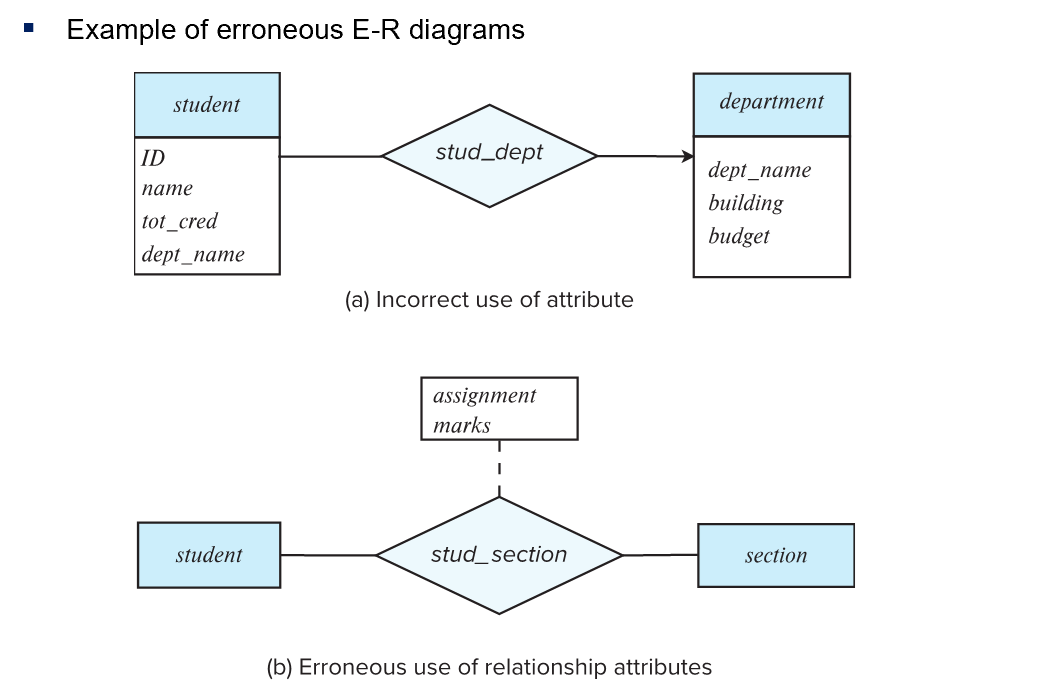
- 上图 a 中
student中不应该出现dept_name;b 中将assignment``marks设计为多值属性较为合适 - 正确的做法
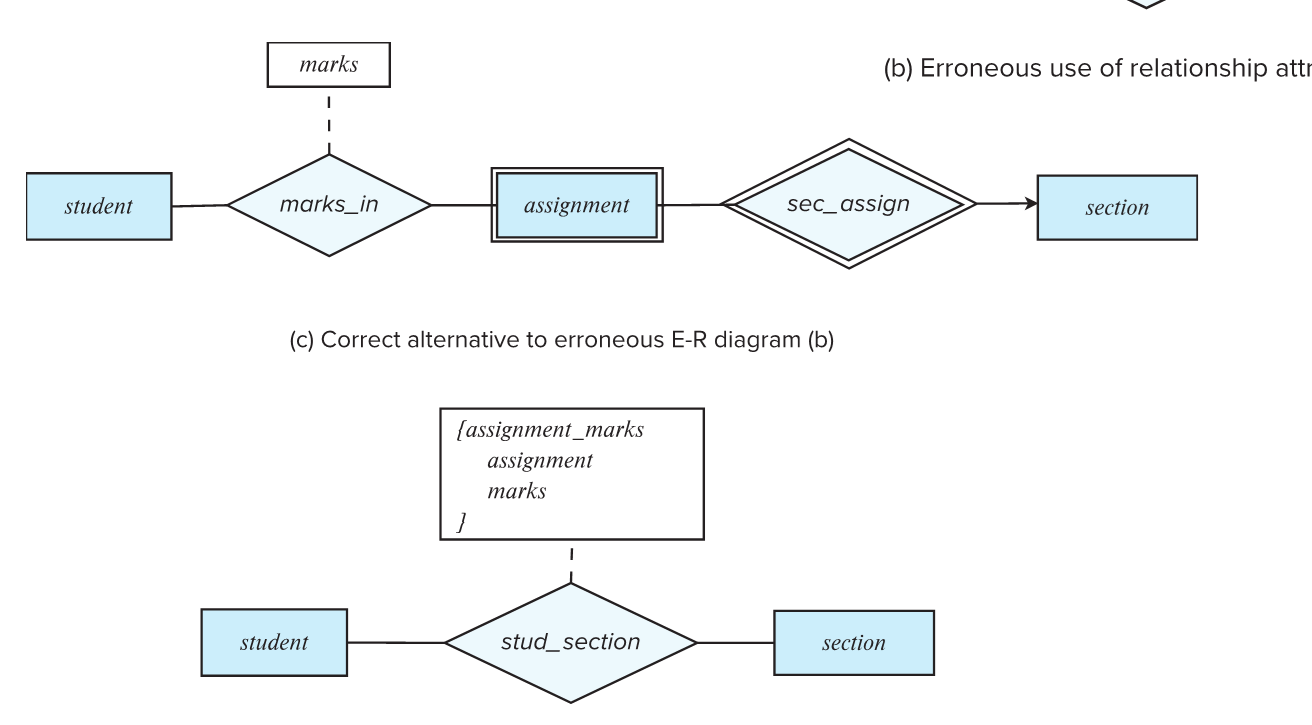
- 上图 a 中
- 多元关系向二元关系的转化
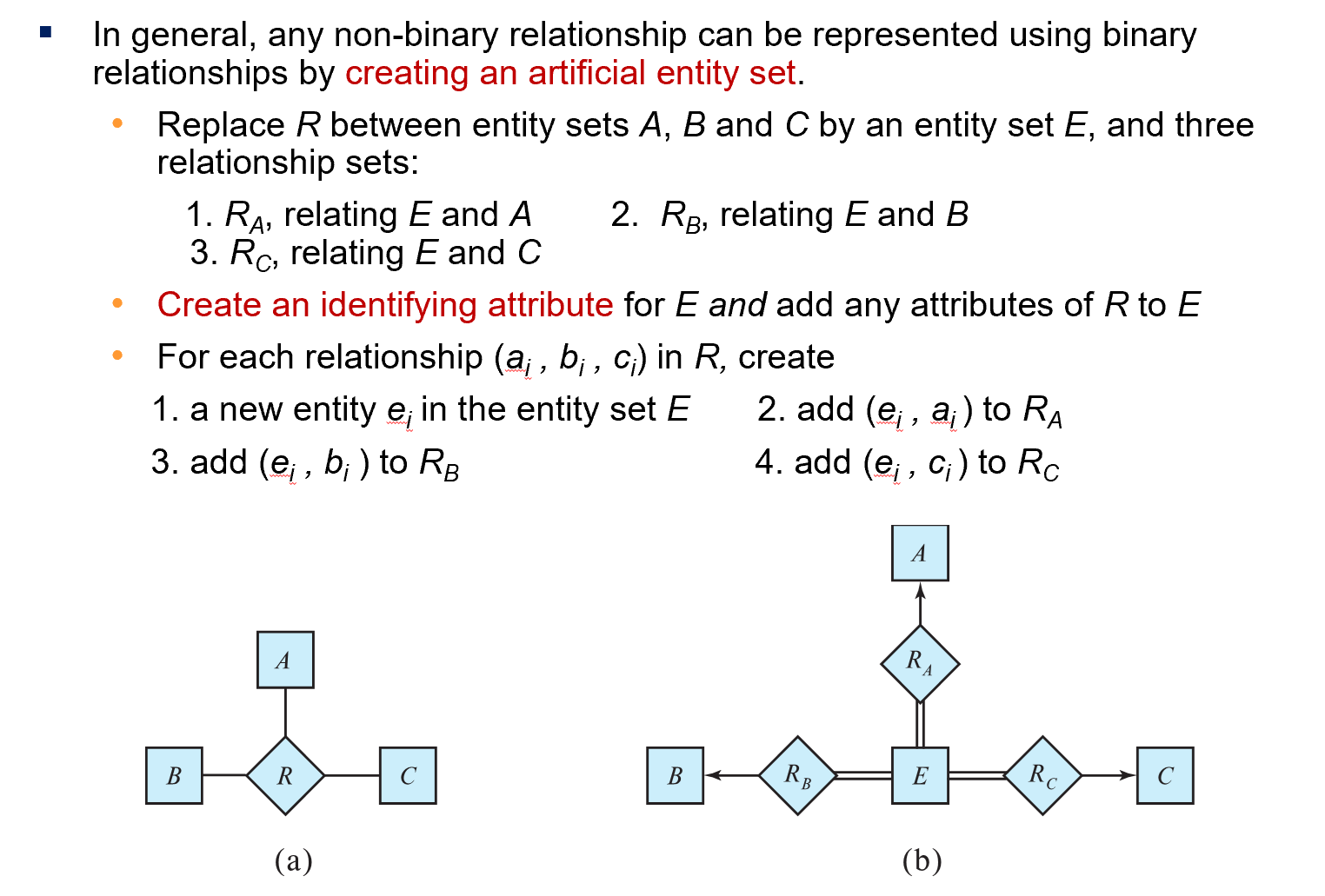
- sjl 老师举的一个很通俗的例子是:比如A B C 分别是老师,学生和课程,E 是教学班,这样很自然的就将三元联系转化为二元联系
- 设计的一些 tips
- 扩展特征
- 特化(specialization)
- 特化和面向对象中的继承一脉相承,是自顶向下的设计方法
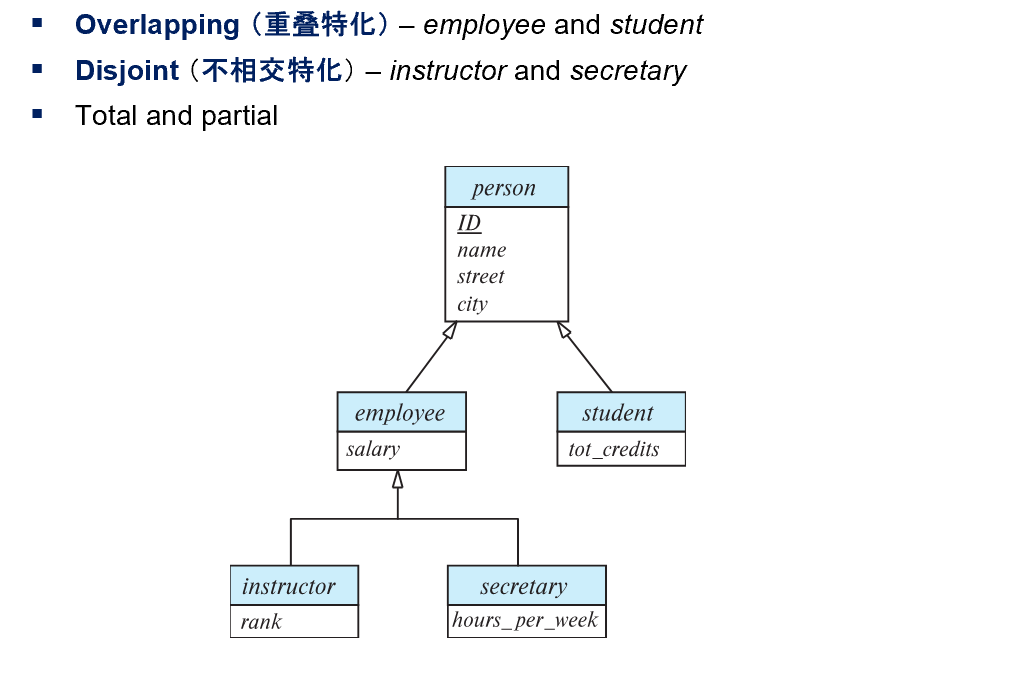
- 这里注意箭头的区别,上方两个继承出的关系并在一起并不是全部的 person,下方的并在一起是employee
- 如何实现?
- 方法一:继承的关系只放本关系的属性
- 方法二:关系中防止本关系和所有继承关系的属性
方法三:全部塞进一个关系里面
- 概化(generlization)
- 概化是自底向上的,从现有的具体的概念逐步抽象到高层次概念
- 聚集(aggregation)
- 是将一个联系集合它所联系的实体集看做一个大的实体集来优化结构的做法
- 特化(specialization)
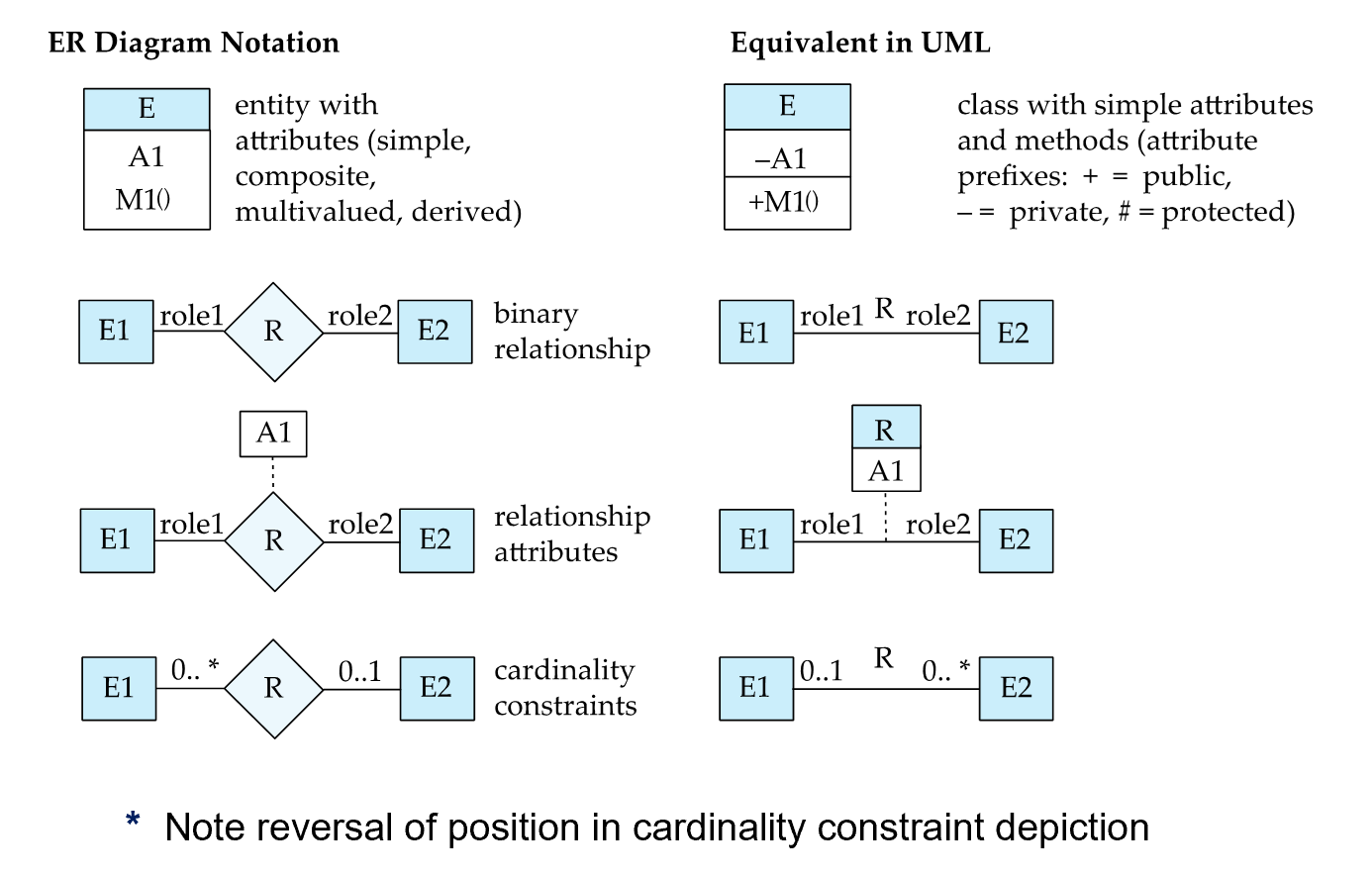
- UML( Unified Modeling Language ) | 统一建模语言
- ER 图和 UML 的一些区别
- ER 图和 UML 的一些区别




Ch7 Normalization | 范式
原子性 & 第一范式
第一范式需要满足所有属性都有原子性不可再分,下列是一些不满足原子性的例子:
- 多值属性
- 复合属性
- 面向对象的属性
一般来说,第一范式最容易满足。数据库里建一张表基本就是。
Decomposition | 分解
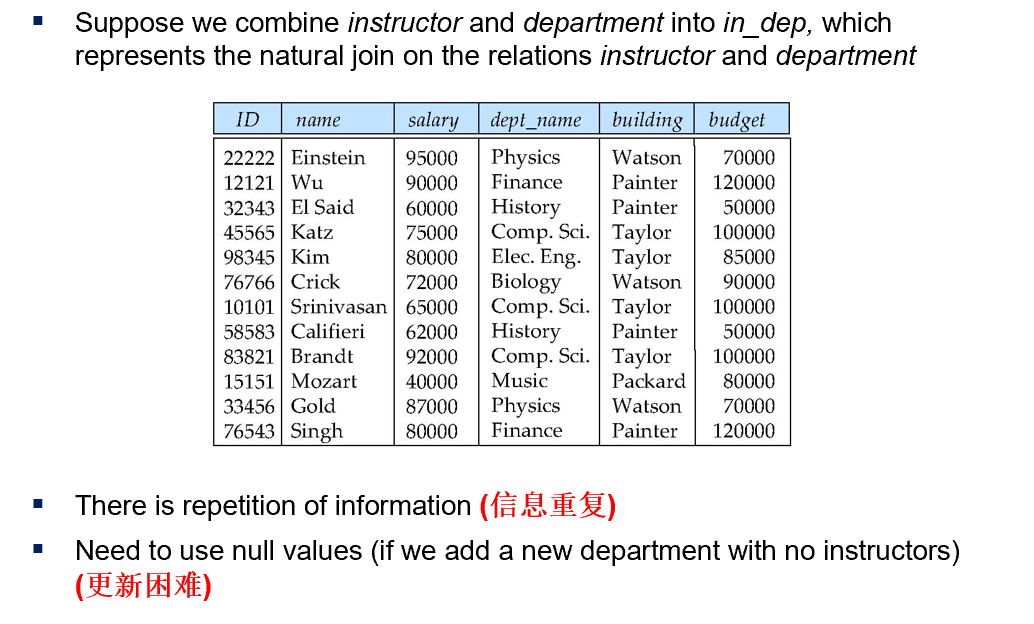
如上图,这样记录数据会导致大量的冗余数据,而且在更新数据时,稍不留神就会导致数据的不一致性,导致更新困难。因此我们希望将联系不强的概念进行分解。
Losless-join Decomposition

上图翻译一下就是,拆完了还能无损的合回去。下面是一个例子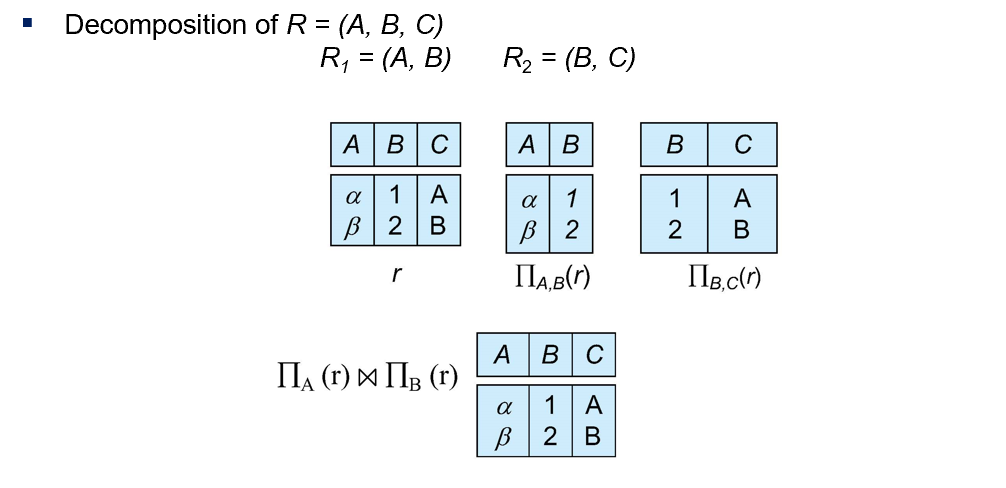
我们要满足如下两条性质至少其一就能保证无损连接分解


 是
是 或
或 的超键的分解就是无损分解
的超键的分解就是无损分解
Functional Dependency | 函数依赖

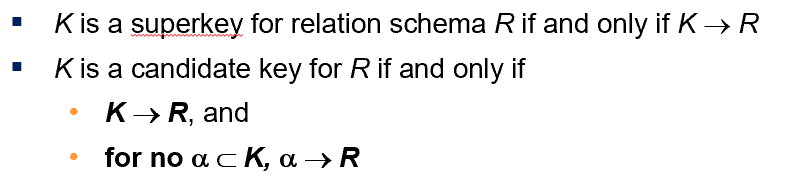
Trival & Non-trivial | 平凡和非平凡依赖

函数依赖的闭包(closure)
用 表示
表示 的闭包。首先引入 Armstrong 公理,注意这里的
的闭包。首先引入 Armstrong 公理,注意这里的 。
。
引申的
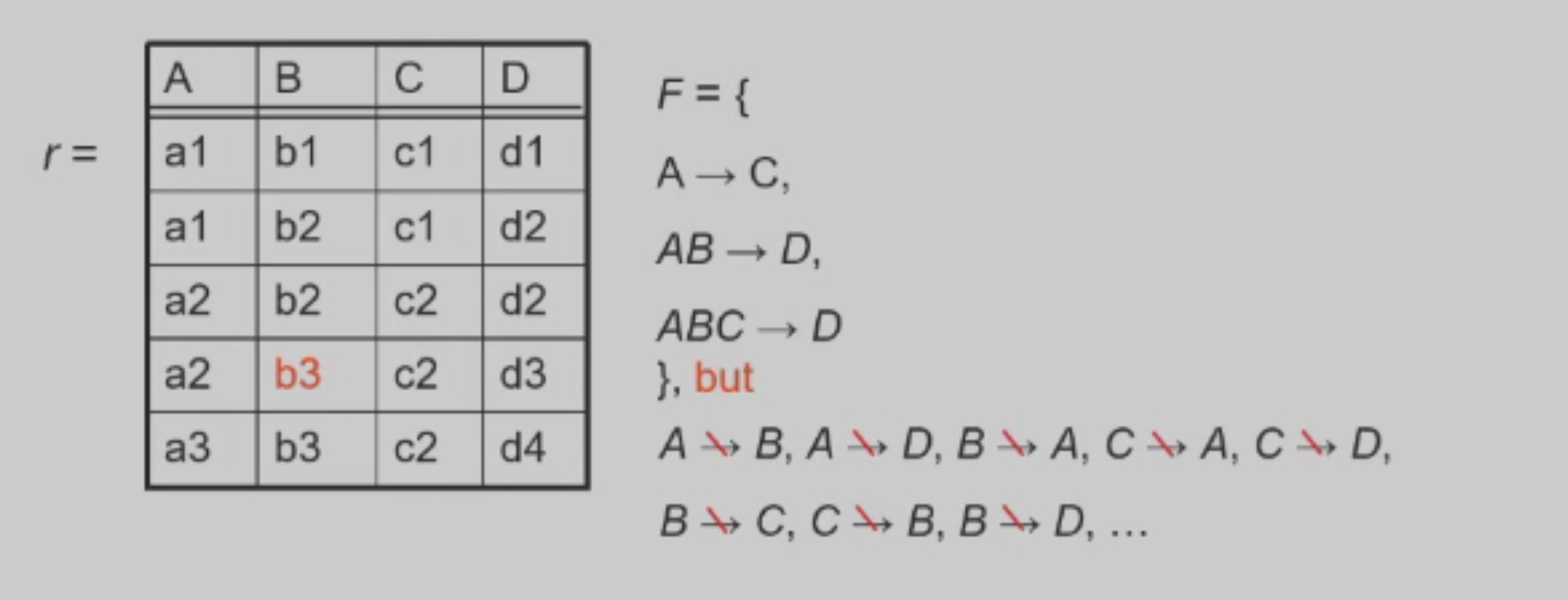
举个栗子: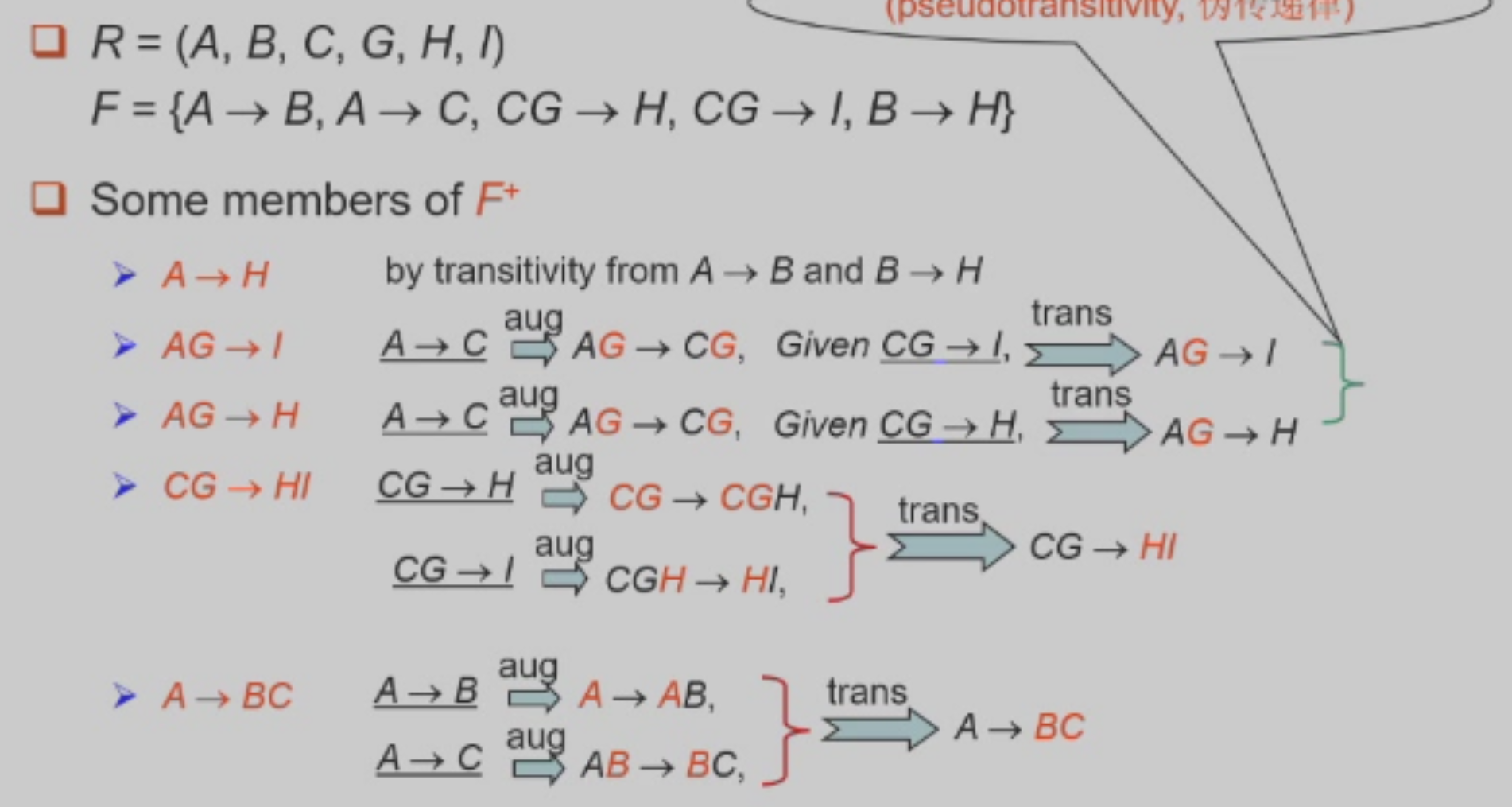
如何得到 的闭包?
的闭包?

- 先用自反和增补
- 再用传递
-
属性的闭包
我们要判断
 的
的 是否为超键,我们需要计算其确定的属性集
是否为超键,我们需要计算其确定的属性集 ,计算全部的
,计算全部的 的开销过大,于是我们有
的开销过大,于是我们有
举个栗子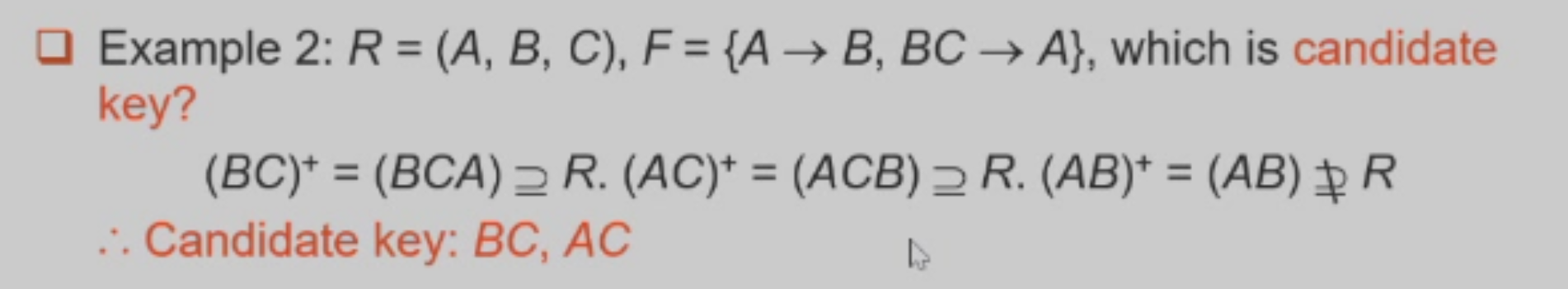
有什么用?
Canonical Cover | 正则覆盖
数据库在执行操作时必须保持关系上的函数依赖
 不被破坏,为此我们需要进行必要的检查。如果我们每次都对
不被破坏,为此我们需要进行必要的检查。如果我们每次都对 进行检查,势必会耗费很多时间,因此我们希望找到一个
进行检查,势必会耗费很多时间,因此我们希望找到一个 的正则覆盖
的正则覆盖 ,是函数依赖的“最小集”。闭包是“扩张”,正则覆盖就是“收缩”。
,是函数依赖的“最小集”。闭包是“扩张”,正则覆盖就是“收缩”。
判断无关属性
我们首先要去除冗余,有三种情况

- 去掉传递得到的依赖


总结一下就是
检验一个属性是否多余
给出计算正则覆盖的算法如下:
保持依赖
保持依赖是我们在对关系 进行分解后,仍希望原来关系上的函数依赖
进行分解后,仍希望原来关系上的函数依赖 在分解后的关系
在分解后的关系 上成立。
上成立。
简单地,我们可以直接检查 中的依赖是否在分解后的关系上成立,若均成立,则保持依赖。但这是一个充分条件,我们还需要做进一步普遍的检查。于是有如下算法:
中的依赖是否在分解后的关系上成立,若均成立,则保持依赖。但这是一个充分条件,我们还需要做进一步普遍的检查。于是有如下算法:
我们对 中每一对
中每一对 进行如上图的检查,如果最后的 result 集合包含了
进行如上图的检查,如果最后的 result 集合包含了 ,那么就是保持的(和前面简单的检查一起用可以少算一些)。该算法的思想是我们在
,那么就是保持的(和前面简单的检查一起用可以少算一些)。该算法的思想是我们在 下求出结果集与
下求出结果集与 的交集的闭包,再与
的交集的闭包,再与 取交集,这样求得的就是
取交集,这样求得的就是 在
在 上的函数依赖。
上的函数依赖。
看一道简单的例题:
:::info
- 给定关系模式R
A.具有无损连接性、保持函数依赖
B.不具有无损连接性、保持函数依赖
C.具有无损连接性、不保持函数依赖
D.不具有无损连接性、不保持函数依赖
————————————————————————————————————————————————
- 先看
 和
和 的交集,为
的交集,为 ,计算
,计算 为
为 ,故不是无损分解;再看 B→A, A→E, AC→B 在
,故不是无损分解;再看 B→A, A→E, AC→B 在 中均能保持,检查 D→A, 应用算法,对于
中均能保持,检查 D→A, 应用算法,对于 ,
, 为空集;对于
为空集;对于 ,
, ,
, ,无变化,故
,无变化,故 。不包含
。不包含 ,因此不保持依赖,选 D。
:::
,因此不保持依赖,选 D。
:::
BC Normal Form | BC 范式
在 (判断“大表”
(判断“大表” 就够了,判断子表一定要用
就够了,判断子表一定要用 )的所有函数依赖上,BC 范式满足以下两个性质至少其一:
)的所有函数依赖上,BC 范式满足以下两个性质至少其一:
 是平凡的
是平凡的 是超键
是超键
要检测 是否满足 BC 范式的条件也很简单,求
是否满足 BC 范式的条件也很简单,求 ,然后看是否包含所有属性即可。
,然后看是否包含所有属性即可。
BC 范式的分解
一个一般的规则是:
算法的细节:
这个算法产生了 BCNF 的一个无损分解,但不能保证是保持依赖的。
一个例子如下:
3NF | 第三范式
我们前面提到 BC 范式不能满足保持依赖,弱化一下条件,我们得到第三范式。
第三范式满足下面三条性质至少其一:
 是平凡的
是平凡的 是超键
是超键-
3NF 的分解
BCNF & 3NF 例题
解题流程这个讲的好:
点击查看【bilibili】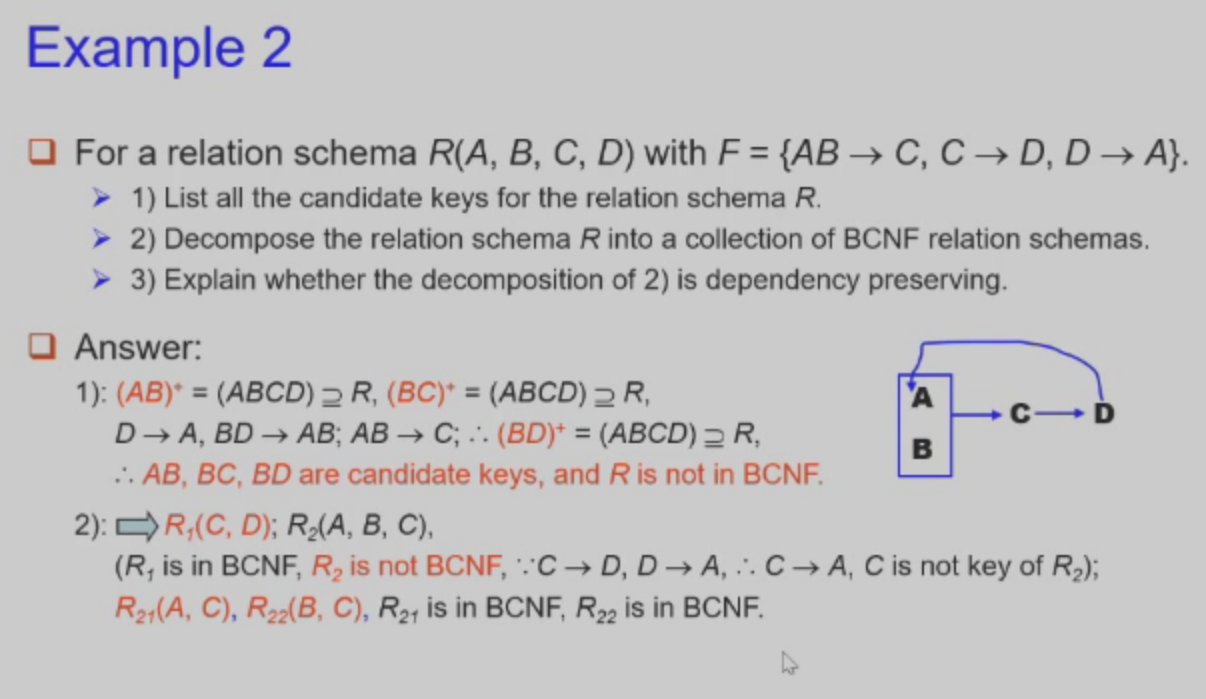


多值依赖 & 4NF
多值依赖

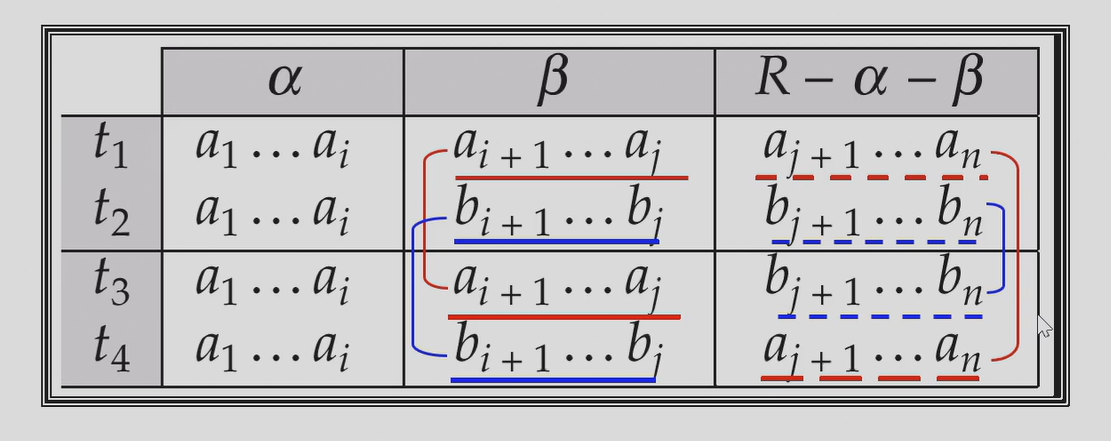
这个定义初看有些奇怪,但可以发现 和
和 部分说明的正是多值依赖保持相同的那部分。比如
部分说明的正是多值依赖保持相同的那部分。比如 和
和 ,在
,在 上取值不同但在
上取值不同但在 上相同。当然用三个 tuple 定义也是可以的
上相同。当然用三个 tuple 定义也是可以的
两个性质 函数依赖是特殊的多值依赖
- 有
 时,也有
时,也有
4NF
4NF 也是 BCNF
分解算法和 BCNF 相同,一个例子:
 的所有属性被都包含在 R 的一个候选键中
的所有属性被都包含在 R 的一个候选键中


若有收获,就点个赞吧
0 人点赞
