《趣谈网络协议》结课测试https://time.geekbang.org/quiz/intro?act_id=151&exam_id=335
“趣谈网络协议”专栏「食用指南」.html
协议专栏特别福利讲答疑解惑第一期.html
协议专栏特别福利讲答疑解惑第三期.html
协议专栏特别福利讲答疑解惑第二期.html
协议专栏特别福利讲答疑解惑第五期.html
协议专栏特别福利讲答疑解惑第四期.html
开篇词讲想成为技术牛人?先搞定网络协议!.html
我是如何创作“趣谈网络协议”专栏的?.html
测一测讲这些网络协议你都掌握了吗?.html
第1讲讲为什么要学习网络协议?.html
第2讲讲网络分层的真实含义是什么?.html
第3讲讲ifconfig:最熟悉又陌生的命令行.html
第4讲讲DHCP与PXE:IP是怎么来的,又是怎么没的?.html
第5讲讲从物理层到MAC层:如何在宿舍里自己组网玩联机游戏?.html
第6讲讲交换机与VLAN:办公室太复杂,我要回学校.html
第7讲讲ICMP与ping:投石问路的侦察兵.html
第8讲讲世界这么大,我想出网关:欧洲十国游与玄奘西行.html
第9讲讲路由协议:西出网关无故人,敢问路在何方.html
第10讲讲UDP协议:因性善而简单,难免碰到“城会玩”.html
第11讲讲TCP协议(上):因性恶而复杂,先恶后善反轻松.html
第12讲讲TCP协议(下):西行必定多妖孽,恒心智慧消磨难.html
第13讲讲套接字Socket:Talkischeap,showmethecode.html
第14讲讲HTTP协议:看个新闻原来这么麻烦.html
第15讲讲HTTPS协议:点外卖的过程原来这么复杂.html
第16讲讲流媒体协议:如何在直播里看到美女帅哥?.html
第17讲讲P2P协议:我下小电影,99%急死你.html
第18讲讲DNS协议:网络世界的地址簿.html
第19讲讲HTTPDNS:网络世界的地址簿也会指错路.html
第20讲讲CDN:你去小卖部取过快递么?.html
第21讲讲数据中心:我是开发商,自己拿地盖别墅.html
第22讲讲VPN:朝中有人好做官.html
第23讲讲移动网络:去巴塞罗那,手机也上不了脸书.html
第24讲讲云中网络:自己拿地成本高,购买公寓更灵活.html
第25讲讲软件定义网络:共享基础设施的小区物业管理办法.html
第26讲讲云中的网络安全:虽然不是土豪,也需要基本安全和保障.html
第27讲讲云中的网络QoS:邻居疯狂下电影,我该怎么办?.html
第28讲讲云中网络的隔离GRE、VXLAN:虽然住一个小区,也要保护隐私.html
第29讲讲容器网络:来去自由的日子,不买公寓去合租.html
第30讲讲容器网络之Flannel:每人一亩三分地.html
第31讲讲容器网络之Calico:为高效说出善意的谎言.html
第32讲讲RPC协议综述:远在天边,近在眼前.html
第33讲讲基于XML的SOAP协议:不要说NBA,请说美国职业篮球联赛.html
第34讲讲基于JSON的RESTful接口协议:我不关心过程,请给我结果.html
第35讲讲二进制类RPC协议:还是叫NBA吧,总说全称多费劲.html
第36讲讲跨语言类RPC协议:交流之前,双方先来个专业术语表.html
第37讲讲知识串讲:用双十一的故事串起碎片的网络协议(上).html
第38讲讲知识串讲:用双十一的故事串起碎片的网络协议(中).html
第39讲讲知识串讲:用双十一的故事串起碎片的网络协议(下).html
第40讲讲搭建一个网络实验环境:授人以鱼不如授人以渔.html
结束语讲放弃完美主义,执行力就是限时限量认真完成.html
🤔️ 你是否有这样的疑问
- 用 Nginx 搭建 Web 服务器,keepalive、rewrite、proxy_pass 都是怎么回事,为什么要这么配置?
- 都说 HTTP 缓存很有用,可以大幅度提升系统性能,可它是怎么做到的?又应该用在何
时何地?
- 用 Python 写爬虫,URI、URL“傻傻分不清”,有时里面还会加一些奇怪的字符,怎么
处理才好?
- HTTP 和 HTTPS 是什么关系?还经常听说有 SSL/TLS/SNI/OCSP/ALPN……这么多稀奇
古怪的缩写,头都大了,实在是搞不懂。
⌚️发展历程
- HTTP/0.9 是个简单的文本协议,只能获取文本资源;
- HTTP/1.0 确立了大部分现在使用的技术,但它不是正式标准;
- 增加了 HEAD、POST 等新方法;
- 增加了响应状态码,标记可能的错误原因;
- 引入了协议版本号概念;
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活;
- 传输的数据不再仅限于文本。
- HTTP/1.1 是目前互联网上使用最广泛的协议,功能也非常完善;.
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许响应数据分块(chunked),利于传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能。
- HTTP/2 基于 Google 的 SPDY 协议,注重性能改善,但还未普及;
- 二进制协议,不再是纯文本;
- 可发起多个请求,废弃了 1.1 里的管道;
- 使用专用算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,“事实上”要求加密通信。
-
HTTP是什么
:::info HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范 :::

协议:HTTP 是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之
间交流通信的规范,以及相关的各种控制和错误处理方式。
- 传输:HTTP 是一个在计算机世界里专门用来在两点之间传输数据的约定和规范。
- 超文本:图片、音频、视频、甚至是压缩包、超链 :::tips 在互联网世界里,HTTP 通常跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。
此外,还有一些协议依赖于 HTTP,例如 WebSocket、HTTPDNS 等。这些协议相互交织,构成了一个协议网,而 HTTP 则处于中心地位。 :::
基础概念
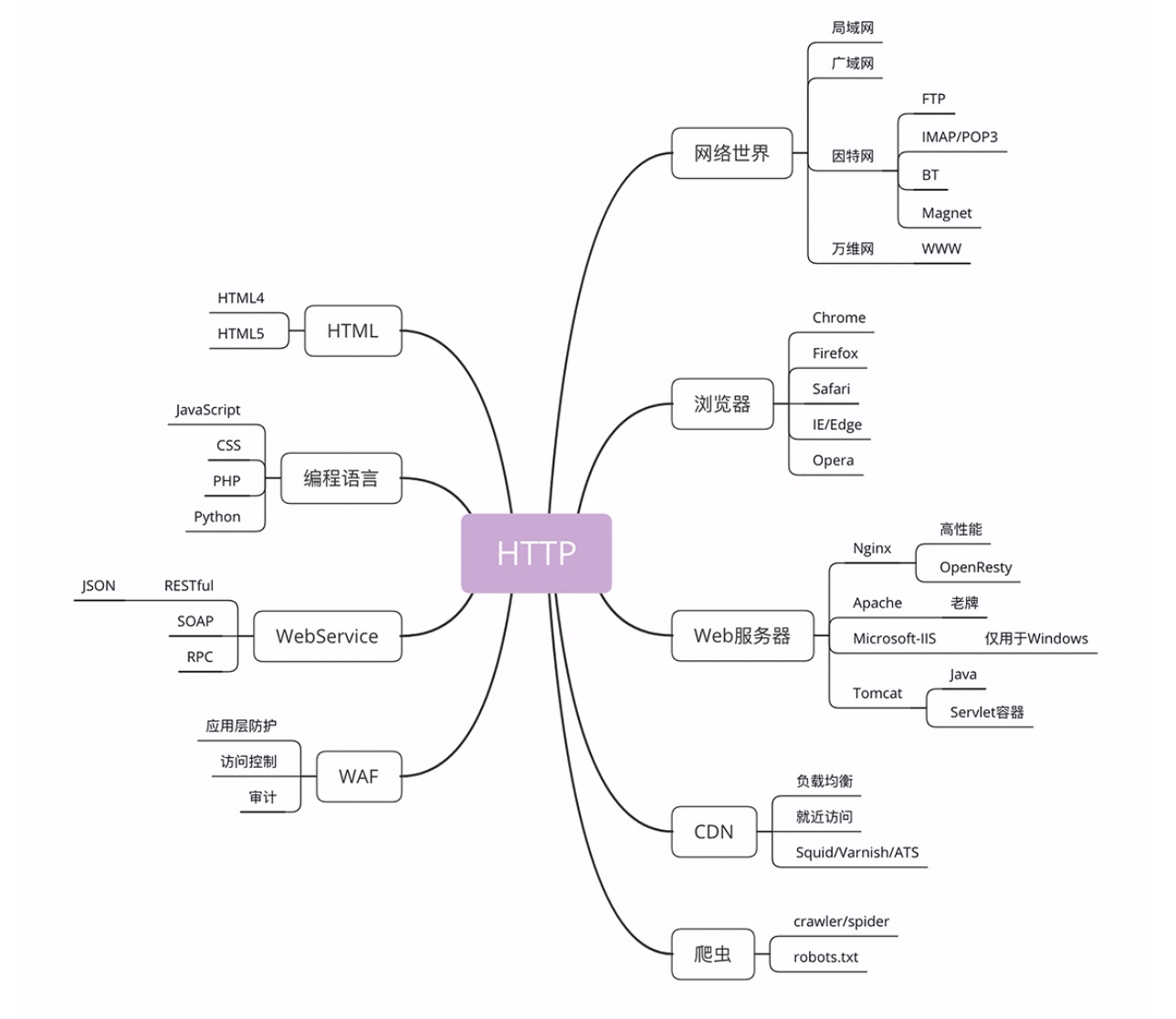
- 浏览器:即 HTTP 协议中的请求方,在 HTTP 中被称为 “User Agent“,也即客户端。
- Web Server:即 HTTP 协议中的响应方,
- 硬件:是物理形式或“云”形式的机器。是利用反向代理、负载均衡等技术组成的庞大集群。
- 软件:是提供 Web 服务的应用程序。利用强大的硬件能力响应海量的客户端 HTTP 请求,处理磁盘上的网页、图片等静态文件,或者把请求转发给后面的 Tomcat、Node.js 等业务应用,返回动态的信息。
- CDN:应用 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求。除了基本的网络加速外,还提供负载均衡、安全防护、边缘计算、跨运营商网络等功能,能够成倍地“放大”源站服务器的服务能力。通常扮演着透明代理和反向代理的角色
- 爬虫:是一种可以自动访问 Web 资源的应用程序。爬虫也有不好的一面,它会过度消耗网络资源,占用服务和带宽,影响网站对真实数据的分析,甚至导致敏感信息泄漏。所以,又出现了“反爬虫”技术,通过各种手段来限制爬虫。其中一项就是“君子协定”robots.txt,约定哪些该爬,哪些不该爬。
- Web Service:是一种应用服务开发规范。使用 client-server 主从架构,通常使用 WSDL 定义服务接口,使用 HTTP 协议传输 XML 或 SOAP 消息,也就是说,它是一个基于 Web(HTTP)的服务架构技术。
- WAF:“网络应用防火墙”。与硬件“防火墙”类似,它是应用层面的“防火墙”,专门检测 HTTP 流量,是防护 Web 应用的安全技术。开源项目是 ModSecurity,可以阻止如 SQL 注入、跨站脚本等攻击。
相关协议

- TCP/IP: 核心为TCP和IP协议的协议栈。
- IP 协议:决寻址和路由问题,以及如何在两点间传送数据包
- TCP 协议:传输控制协议。提供可靠的、字节流形式的通信。保证数据不丢失且完整。
- DNS:域名系统(Domain Name System)。
- URI(Uniform Resource Identifier):统一资源标识符,使用它就能够唯一地标记互联网上资源。
- URL(Uniform Resource Locator),统一资源定位符,是 URI 的一个子集。协议名/主机名/路径
- HTTPS:HTTP over SSL/TLS,运行在 SSL/TLS 协议上的 HTTP。
- SSL/TLS:综合了对称加密、非对称加密、摘要算法、数字签名、数字证书等技术,
- Proxy:中转站。既可以转发客户端的请求,也可以转发服务器端的应答。

TCP/IP 协议总共有四层,每一层需要下层的支撑,同时又支撑着上层,任何一层被抽掉都可能会导致整个协议栈坍塌。
- 链接层(link layer):负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标记网络上的设备,所以有时候也叫 MAC层。
- 网际层(internet layer):IP 协议就处在这一层。因为IP 协议定义了“IP 地址”的概念,所以就可以在“链接层”的基础上,用 IP 地址取代MAC 地址,把许许多多的局域网、广域网连接成一个虚拟的巨大网络,在这个网络里找设备时只要把 IP 地址再“翻译”成 MAC 地址就可以了。
- 传输层(transport layer):这个层次协议的职责是保证数据在 IP 地址标记的两点之间“可靠”地传输,是 TCP 协议工作的层次,另外还有UDP
- 应用层(application layer):由于下面的三层把基础打得非常好,所以在这一层就“百花齐放”了,有各种面向具体应用的协议。例如 Telnet、SSH、FTP、SMTP 等等,当然还有 HTTP。

OSI 模型分成了七层:
- 第一层:物理层,网络的物理形式,例如电缆、光纤、网卡、集线器等等;
- 第二层:数据链路层,它基本相当于 TCP/IP 的链接层;
- 第三层:网络层,相当于 TCP/IP 里的网际层;
- 第四层:传输层,相当于 TCP/IP 里的传输层;
- 第五层:会话层,维护网络中的连接状态,即保持会话和同步;
- 第六层:表示层,把数据转换为合适、可理解的语法和语义;
- 第七层:应用层,面向具体的应用传输数据。
:::tips 两个凡是凡是由操作系统负责处理的就是四层或四层以下,否则凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层 :::
- 四层负载均衡:就是指工作在传输层上,基于 TCP/IP 协议的特性,例如 IP 地址、端口号等实现对后端服务器的负载均衡。
- 七层负载均衡:就是指工作在应用层上,看到的是 HTTP 协议,解析 HTTP 报文里的 URI、主机名、资源类型等数据,再用适当的策略转发给后端服务器。
- 二层转发:指数据链路层,工作在二层的设备,通过查找到目标MAC地址,进行数据转发
- 三层路由:三层应该指网络层,工作在三层的设备,通过解析数据包头信息,找到目标IP地址,转发数据
- DNS: 凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层.因此工作在应用层
- CDN:凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层.因此工作在应用层
域名系统

- 主机名;通常用来表明主机的用途,比如“www”表示提供万维网服务、“mail”表示提供邮件服务,
- 二级域名
- 顶级域名
域名的作用:
- 代替IP地址
- 标识虚拟主机
- 重定向:因为域名代替了 IP 地址,所以可以让对外服务的域名不变,而主机的 IP 地址任意变动。当主机有情况需要下线、迁移时,可以更改 DNS 记录,让域名指向其他的机器。
- 名字空间:使用 bind9 搭建内部用的 DNS 作为名字服务器。
- 负载均衡:域名解析可以返回多个IP地址。
- 域名屏蔽:对域名直接不解析,返回错误,让你无法拿到IP地址
- 域名劫持:你要访问A网站,但给你B网站
DNS域名解析系统:
- 是树状的分布式查询系统
- 根域名服务器(Root DNS Server):管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的 IP 地址;
- 顶级域名服务器(Top-level DNS Server):管理各自域名下的权威域名服务器,比如com 顶级域名服务器可以返回 apple.com 域名服务器的 IP 地址;
- 权威域名服务器(Authoritative DNS Server):管理理自己域名下主机的 IP 地址,比如apple.com 权威域名服务器可以返回
www.apple.com的 IP 地址。
缓存解析:
浏览器缓存->操作系统缓存->hosts->dns- 操作系统里会对 DNS 解析结果做缓存,如果操作系统在缓存里找不到 DNS记录,就会找“主机映射”文件(hosts)
- 许多大公司、网络运行商都会建立自己的 DNS 服务器,作为用户 DNS 查询的代理,代替用户访问核心 DNS 系统
- Google: 8.8.8.8
- Microsoft: 4.22.1
- CloudFlare: 1.1.1.1
Nginx 中的配置命令 resolver:
resolver 8.8.8.8 valid=30s; # 指定 Google 的 DNS,缓存 30 秒
HTTP 实验环境
- Wireshark:网络抓包工具,能够截获在 TCP/IP 协议栈中传输的所有流量,并按协议类型、地址、端口等任意过滤,功能非常强大,是学习网络协议的必备工具
- Chrome:开发者工具”可以非常详细地观测 HTTP 传输全过程的各种数据.事后诸葛亮
- Telnet: 是一个命令行工具,可用来登录主机模拟浏览器操作。
- OpenResty:是基于 Nginx 的一个“强化包”,里面除了 Nginx 还有一大堆有用的功能模块,不仅支持 HTTP/HTTPS,还特别集成了脚本语言 Lua 简化 Nginx二次开发,方便快速地搭建动态网关,更能够当成应用容器来编写业务逻辑。下载地址
OpenResty
brew install openrestytar -xzvf openresty-VERSION.tar.gzcd openresty-VERSION/./configuremakesudo make install
如果有缺失模块的问题,可执行以下命令安装
yum -y install pcre-develyum -y install openssl openssl-devel
- 安装目录
/usr/local/openresty - 启动:
/usr/local/openresty/bin/openresty
“键入网址按下回车”后
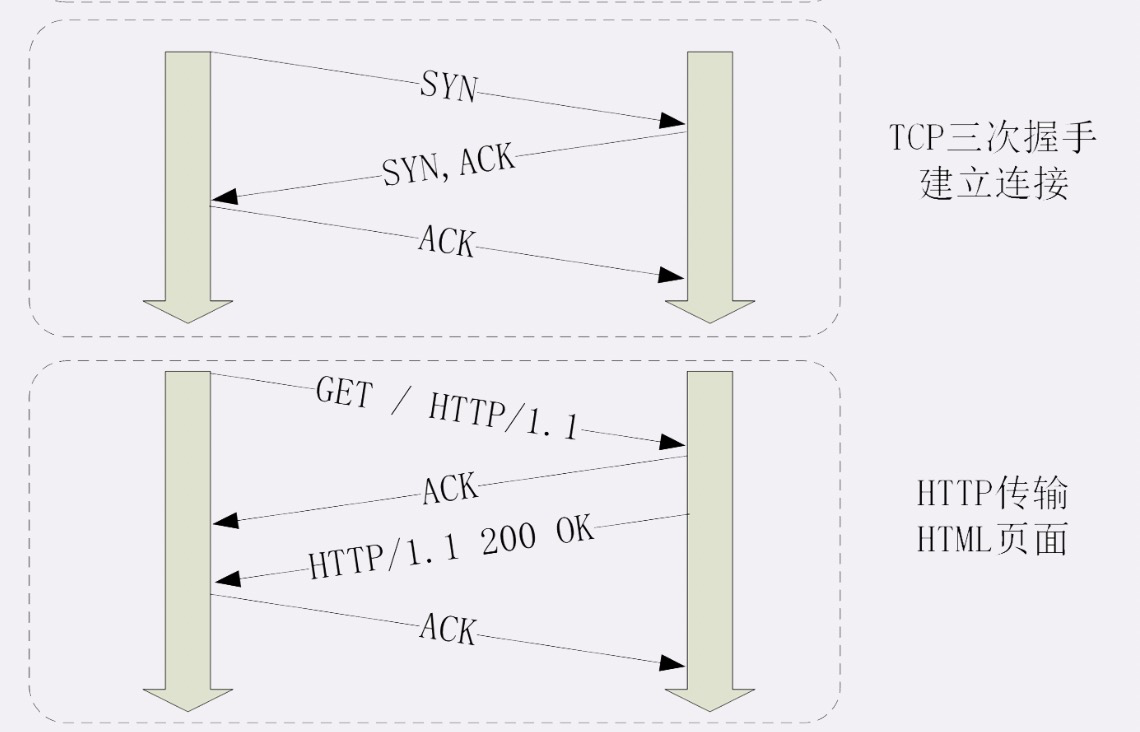
- 浏览器就要依照 TCP 协议的规范,使用“三次握手”建立与 Web 服务器的连接,这里产生3个包
- 有了可靠的 TCP 连接通道后,HTTP 协议就可以开始工作了。于是,浏览器按照 HTTP 协议规定的格式,通过 TCP 发送一个“GET / HTTP/1.1”请求报文,即第4个包
- Web 服务器回复了第五个包,在 TCP 协议层面确认:“刚才的报文我已经收到了”,不过这个 TCP 包 HTTP 协议是看不见的。
- Web 服务器收到报文后在内部就要处理这个请求。同样也是依据 HTTP 协议的规定,解析报文,看看浏览器发送这个请求想要干什么。将要读取的内容拼成符合 HTTP 格式的报文,发回去。这是第六个包“HTTP/1.1 200 OK”,底层走的还是 TCP 协议。
- 浏览器也要给服务器回复一个 TCP 的 ACK 确认,“你的响应报文收到了”,即第七个包。
浏览器收到了响应数据,解析报文。调用排版引擎、JavaScript 引擎等处理显示出来。
DNS 域名解析全过程
- 浏览器缓存全过程
- CDN 缓存的全过程
- 动态资源加载的全过程:经过无数的路由器、网关、代理,最后到达目的地。一般会有负载均衡,负载均衡设备会先访问系统里的缓存服务器,通常有 memory 级缓存 Redis 和 disk 级缓存 Varnish,它们的作用与 CDN 类似,不过是工作在内部网络里,把最频繁访问的数据缓存几秒钟或几分钟,减轻后端应用服务器的压力。如果缓存服务器里也没有,那么负载均衡设备就要把请求转发给应用服务器了。这里就是各种开发框架大显神通的地方了,例如 Java 的 Tomcat/Netty/Jetty,Python 的 Django,还有 PHP、Node.js、Golang 等等。它们又会再访问后面的 MySQL、PostgreSQL、MongoDB 等数据库服务,实现用户登录、商品查询、购物下单、扣款支付等业务操作,然后把执行的结果返回给负载均衡设备,同时也可能给缓存服务器里也放一份。
- 渲染页面全过程
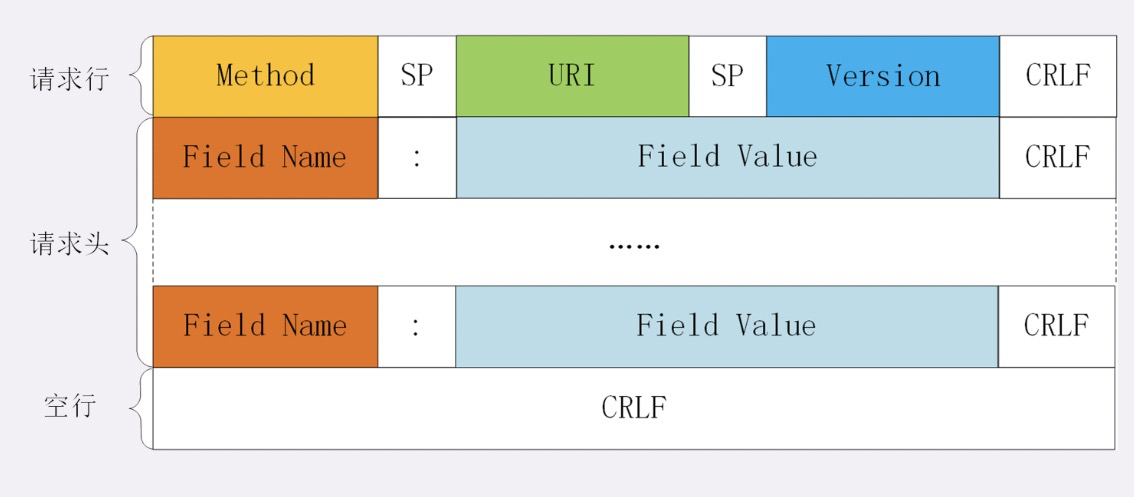
HTTP 报文
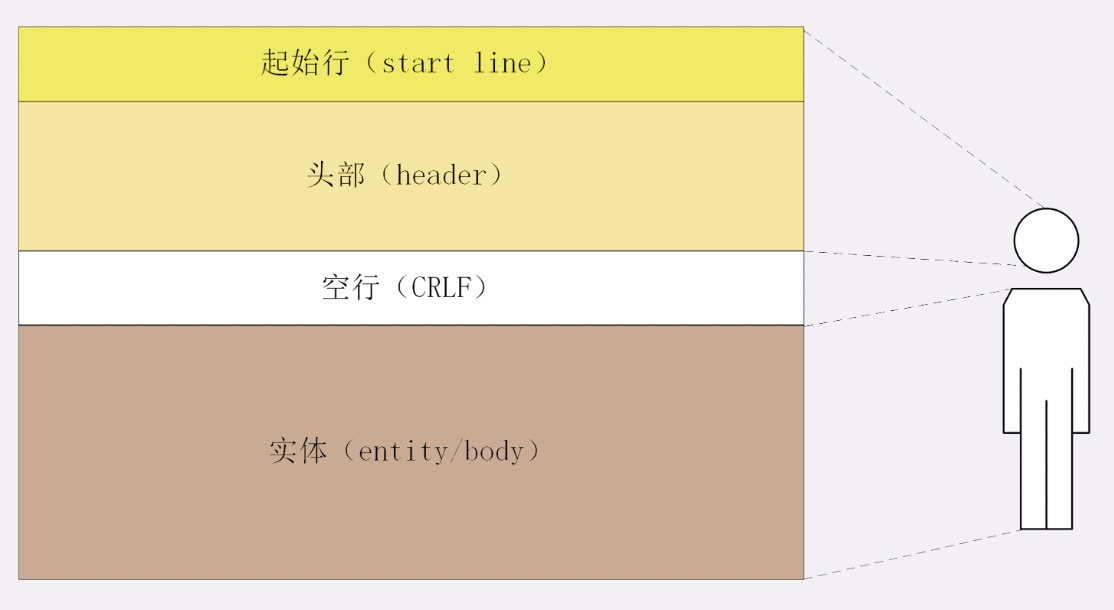
- 头数据都是 ASCII 码的文本
- 起始行(start line):描述请求或响应的基本信息
- 头部字段集合(header):使用 key-value 形式更详细地说明报文
- 消息正文(entity):实际传输的数据,不一定是纯文本,可以是二进制数据(图片、视频等)
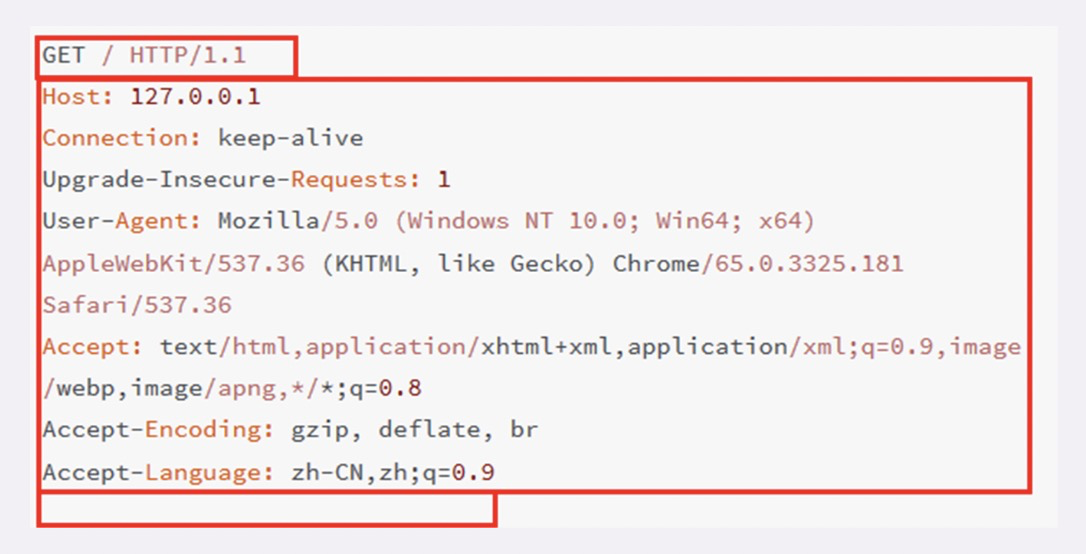

头字段:
- 不仅可以使用标准里的 Host、Connection 等已有头,也可以任意添加自定义头
- 字段名不区分大小写
- 字段名里不允许出现空格
- 字段名后面必须紧接着“:”,不能有空格,而“:”后的字段值前可以有多个空格
- 字段的顺序是没有意义的,可以任意排列不影响语义
- 字段原则上不能重复,除非这个字段本身的语义允许,例如 Set-Cookie。
- Host字段:是HTTP/1.1 规范里要求必须出现的字段也就是说,如果请求头里没有 Host,那这就是一个错误的报文。告诉服务器这个请求应该由哪个主机来处理,当一台计算机上托管了多个虚拟主机的时候,服务器端就需要用 Host 字段来选择。
- Content-Length:表示报文里 body 的长度,也就是请求头或响应头空行后面数据的长度。服务器看到这个字段,就知道了后续有多少数据,可以直接接收。如果没有这个字段,那么 body 就是不定长的,需要使用 chunked 方式分段传输。
:::tips Nginx, 默认字段不能超过 8K,不允许字段里使用”_” :::
请求方法

- HEAD :HEAD 方法与 GET 方法类似,也是请求从服务器获取资源,服务器的处理机制也是一样的,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的“元信息”。
- PUT:PUT 的作用与 POST 类似,也可以向服务器提交数据,但与 POST 存在微妙的不同,通常 POST 表示的是“新建”“create”的含义,而 PUT 则是“修改”“update”的含义。
- DELETE:DELETE方法指示服务器删除资源,因为这个动作危险性太大,所以通常服务器不会执行真正的删除操作,而是对资源做一个删除标记。当然,更多的时候服务器就直接不处理DELETE 请求。
- CONNECT:CONNECT 是一个比较特殊的方法,要求服务器为客户端和另一台远程服务器建立一条特殊的连接隧道,这时 Web 服务器在中间充当了代理的角色。
- OPTIONS:OPTIONS 方法要求服务器列出可对资源实行的操作方法,在响应头的 Allow 字段里返回。它的功能很有限,用处也不大,有的服务器(例如 Nginx)干脆就没有实现对它的支持。
TRACE:TRACE方法多用于对 HTTP 链路的测试或诊断,可以显示出请求 - 响应的传输路径。它的本意是好的,但存在漏洞,会泄漏网站的信息,所以 Web 服务器通常也是禁止使用。
“安全”:是指请求方法不会“破坏”服务器上的资源,即不会对服务器上的资源造成实质的修改,只有GET 和HEAD是安全的,POST/PUT/DELETE是不安全的。
- “幂等”:多次执行相同的操作,结果也都是相同的,即多次“幂”后结果“相等”。GET/HEAD/DELETE/PUT是幂等的,而POST是非幂等的。
网址

#fragment:片段标识符,是 URI 所定位的资源内部的一个“锚点”或者说是“标签”,浏览器可以在获取资源后直
接跳转到它指示的位置。但片段标识符仅能由浏览器这样的客户端使用,服务器是看不到的。也就是说,浏览器永远不会把带“#fragment”的URI 发送给服务器,服务器也永远不会用这种方式去处理资源的片段。
URI 编码:在 URI 里只能使用 ASCII 码,对于 ASCII 码以外的字符集和特殊字符做一个特殊的操作,把它们转换成与 URI 语义不冲突的形式。直接把非 ASCII 码或特殊字符转换成十六进制字节值,然后前面再加上一个“%”。而中文、日文等则通常使用 UTF-8 编码后再转义。需要注意的是URI转义与HTML里的编码转义是完全不同的,URI转义使用的是“%”。而HTML转义使用的是“&#”。
状态码
- 101 Switching Protocols:客户端使用 Upgrade 头字段,要求在 HTTP 协议的基础上改成其他的协议继续通信,比如 WebSocket。而如果服务器也同意变更协议,就会发送状态码 101,但这之后的数据传输就不会再使用 HTTP 了。
- 204 No Content:与“200 OK”基本相同,但响应头后没有 body 数据。
- 206 Partial Content:是 HTTP 分块下载或断点续传的基础,在客户端发送“范围请求”、要求获取资源的部分数据时出现,它与 200 一样,也是服务器成功处理了请求,但 只有部分body 数据
- 301 Moved Permanently:永久重定向,例如从 http 变成了 https
- 302 Found:临时重定向,会在响应头里使用字段 Location 指明后续要跳转的 URI
- 304 Not Modified:缓存重定向。用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。它不具有通常的跳转含义,但可以理解成“重定向已到缓存的文件”。
- 400 Bad Request:一般表示传参错误
- 403 Forbidden:表示服务器禁止访问资源
- 404 Not Found:资源在本服务器上未找到
- 405 Method Not Allowed:不允许使用某些方法操作资源,例如不允许 POST 只能 GET
- 502 Bad Gateway:服务器作为网关或者代理时返回的错误码
- 503 Service Unavailable:表示服务器当前很忙,暂时无法响应服务
实体数据
:::info MIME type:
- text:即文本格式的可读数据,如超文本文档text/html ,此外还有纯文本
- image:即图像文件,有 image/gif、image/jpeg、image/png 等
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等
application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的application/json,application/javascript、application/pdf 等,另外,如果实在是不知道数据是什么类型,像刚才说的“黑盒”,就会是application/octet-stream,即不透明的二进制数据 :::
Accept-Encoding字段标记的是客户端支持的压缩格式,例如 gzip、deflate 等,同样也可以用“,”列出多个,服务器可以选择其中一种来压缩数据
- Content-Encoding: 服务器响应实际使用的压缩格式,必须由应用自行解码。
:::info Encoding type :
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式
- deflate:zlib(deflate)压缩格式,流行程度仅次于gzip;
br:一种专门为 HTTP 优化的新压缩算法(Brotli) :::
Accept字段:标记的是客户端可理解的 MIME type,可以用“,”做分隔符列出多个类型,让服务器有更多的选择余地
- Content-Type字段:服务器会告诉浏览器发送响应的实体数据的真实类型 :::tips gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的,再用 gzip 处理也不会变小(甚至还有可能会增大一点)。Nginx的“gzip on” 只会压缩文本数据,不会压缩多媒体数据。 :::
:::info
语言类型:人类使用的自然语言,例如英语、汉语、日语等,而这些自然语言可能还有下属的地区性方
言,所以在需要明确区分的时候也要使用“type-subtype”的形式. en 表示任意的英语,en-US 表示美式英语,
en-GB 表示英式英语,而 zh-CN 汉语。
:::
:::info 字符编码: 英语世界用的 ASCII、汉语世界用的 GBK、BIG5,日语世界用的Shift_JIS 等。同样的一段文字,用一种编码显示正常,换另一种编码后可能就会变得一团糟。所以后来就出现了 Unicode 和 UTF-8,把世界上所有的语言都容纳在一种编码方案里,UTF-8 也成为了互联网上的标准字符集. :::
- Accept-Language字段:标记了客户端可理解的自然语言,也允许用“,”做分隔符列出多个类型.
- Content-Language字段:告诉客户端实体数据使用的实际语言类型
- Accept-Charset:标记了客户端可理解的字符集
- 没有对应的 Content-Charset:是在Content-Type字段的数据类型后面用“charset=xxx”来表示,这点需要特别注意
传输大文件

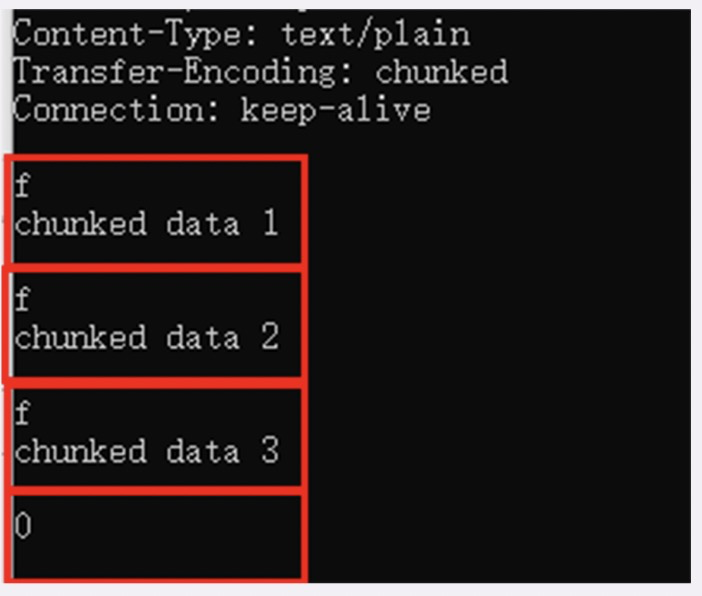
分块传输
- Transfer-Encoding: chunked报文里的 body 部分不是一次性发过来的,而是分成了许多的块(chunk)逐个发送。该字段和Content-Length是互斥字段。
- 每个分块包含两个部分,长度头和数据块;
- 长度头是以 CRLF(回车换行,即\r\n)结尾的一行明文,用 16 进制数字表示长度
- 数据块紧跟在长度头后,最后也用 CRLF 结尾,但数据不包含 CRLF;
最后用一个长度为 0 的块表示结束,即“0\r\n\r\n;
范围请求
Accept-Ranges: bytes 明确告知客户端:“我是支持范围请求的”
- Range:bytes=x-y:范围请求的专用字段,其中的 x 和 y 是以字节为单位的数据范围。
- Content-Range:bytesx-y/total: 告诉片段的实际偏移量和资源的总大小,格式是“bytes x-y/length”,与 Range 头区别在没有“=”,范围后多了总长度。例如,对于“0-10”的范围请求,值就是“bytes0-10/100”。
- 服务器收到 Range 字段后
- 检查范围是否合法,不合法返回状态码“416”,意思是“你的范围请求有误,我无法处理,请再检查一下。比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。
- 如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码“206 PartialContent”,和 200 的意思差不多,但表示 body 只是原数据的一部分。
- 服务器要添加一个响应头字段Content-Range
- 发送数据,直接把片段用 TCP 发给客户端,
:::tips 看视频的拖拽进度需要范围请求,常用的下载工具里的多段下载、断点续传就是基于范围请求实现的。
- 先发个 HEAD,看服务器是否支持范围请求,同时获取文件的大小;
- 开 N 个线程,每个线程使用 Range 字段划分出各自负责下载的片段,发请求传输数据;
- 下载意外中断也不怕,不必重头再来一遍,只要根据上次的下载记录,用 Range 请求剩下的那一部分就可以了。 :::
多段数据
- Content-Type: multipart/byteranges;boundary=xxx


连接管理

由于长连接对性能的改善效果非常显著,所以在 HTTP/1.1中的连接都会默认启用长连接.如果服务器支持长连接,它总会在响应报文里放一个“Connection: keep-alive”字段.
Connection: close: 客户端可以主动关闭连接。
服务器端主动关闭连接,如Nginx下:
- 使用“keep-Alive: timeout=value”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
- 使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
队头阻塞:请求-应答是先进先出的,如果最前面的请求未被处理,就会阻塞后面的所有请求。
并发连接 (concurrent connections): 同时对一个域名发起多个长连接,来解决队头阻塞的问题。HTTP 协议建议客户端使用并发,如chrome就限制最多并发6个连接。
域名分片(domain sharding):多个域名都指向同一台服务器,比如3个域名,这样并发限制就变成了3*6=18个。
重定向和跳转
- Location: 标记了服务器要求重定向的URI,但只有配合301/302才有意义。
- 性能损耗:
- 重定向的机制决定了一个请求会有两次请求-应答。
- 站外重定向,服务器需要开两个连接,如果网络连接质量差,成本就高多了,会严重影响用户体验
- 循环跳转:A=>B=>C=>A, 这种现象浏览器会检测“循环跳转”并阻止请求,给出错误提示。
- 性能损耗:
- Refresh: 5;url=xxx: 告诉浏览器5秒后再跳转
应用场景:
-
Cookie机制
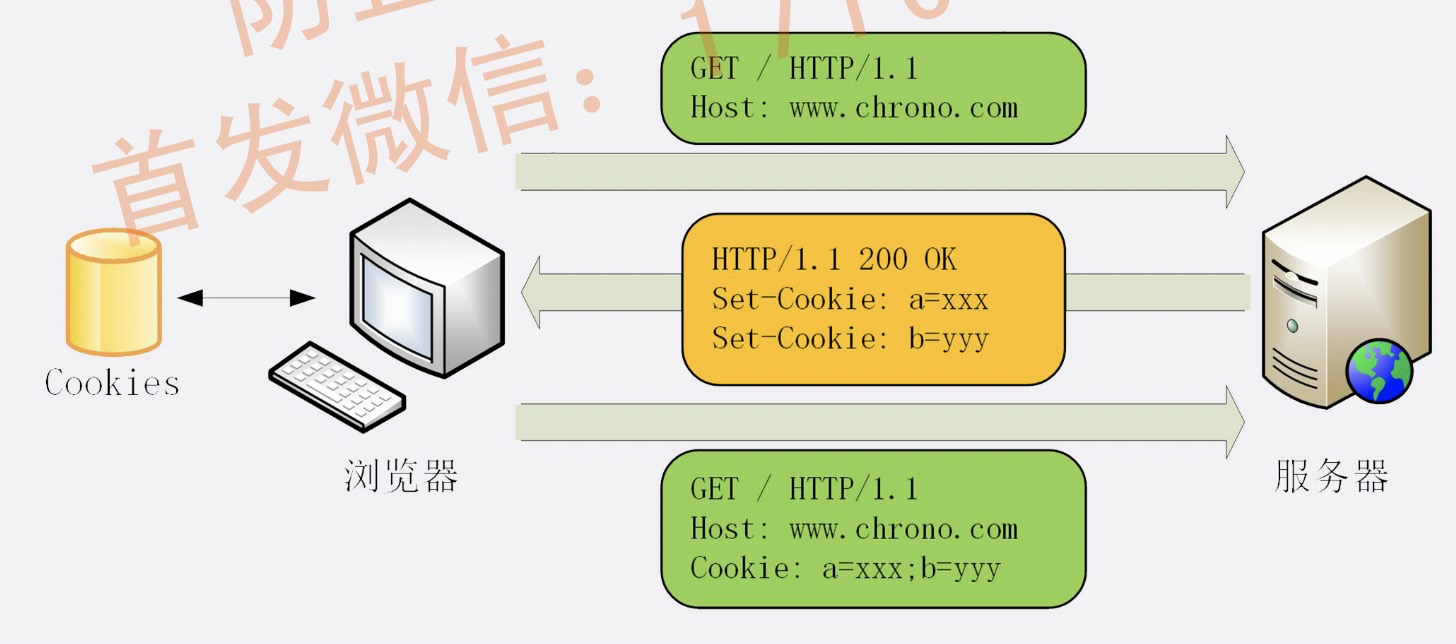

Expires: 用的是绝对时间点,可以理解为“截止日期”(deadline)。
- Max-Age: 用的是相对时间,单位是秒,浏览器用收到报文的时间点再加上 Max-Age,就可以得到失效的绝对时间。优先级更高。
- Domain 和 Path 指定了 Cookie 所属的域名和路径,浏览器在发送 Cookie 前会从 URI 中提取出 host 和 path 部分,对比 Cookie 的属性。如果不满足条件,就不会在请求头里发送 Cookie。
- HttpOnly:告诉浏览器,此 Cookie 只能通过浏览器 HTTP 协议传输,禁止其他方式访问,浏览器的 JS 引擎就会禁用 document.cookie 等一切相关的 API,“跨站脚本”(XSS),也就无从谈起了。
- SameSite:防范“跨站请求伪造”(XSRF)攻击,设置成“SameSite=Strict”可以严格限定 Cookie 不能随着跳转链接跨站发送, 而“SameSite=Lax”则略宽松一点,允许 GET/HEAD 等安全方法,但禁止 POST 跨站发 送。
Secure:表示这个 Cookie 仅能用 HTTPS 协议加密传输,明文的 HTTP 协议会禁止发送。 :::tips 应用场景:
身份识别:保存用户的登录信息,实现会话事务。一方面免去了重复登录的麻烦,另一方面也能够自动记录你的 浏览记录和购物下单(在后台数据库或者也用 Cookie),实现了“状态保持”。
- 广告跟踪:你上网的时候肯定看过很多的广告图片,这些图片背后都是广告商网站(例如 Google), 它会“偷偷地”给你贴上 Cookie 小纸条,这样你上其他的网站,别的广告就能用 Cookie 读出你的身份,然后做行为分析,再推给你广告。 这种 Cookie 不是由访问的主站存储的,所以又叫“第三方 Cookie”(third-party cookie)。如果广告商势力很大,广告到处都是,那么就比较“恐怖”了,无论你走到哪 里它都会通过 Cookie 认出你来,实现广告“精准打击”。 为了防止滥用 Cookie 搜集用户隐私,互联网组织相继提出了 DNT(Do Not Track)和 P3P(Platform for Privacy Preferences Project),但实际作用不大。 :::
:::tips 早期的 cookie 直接就是磁盘上的一些小文本文件,现在基本上都是以数据库记录形式记录在Sqlite,一般总大小不超过4K。 :::
HTTP 缓存
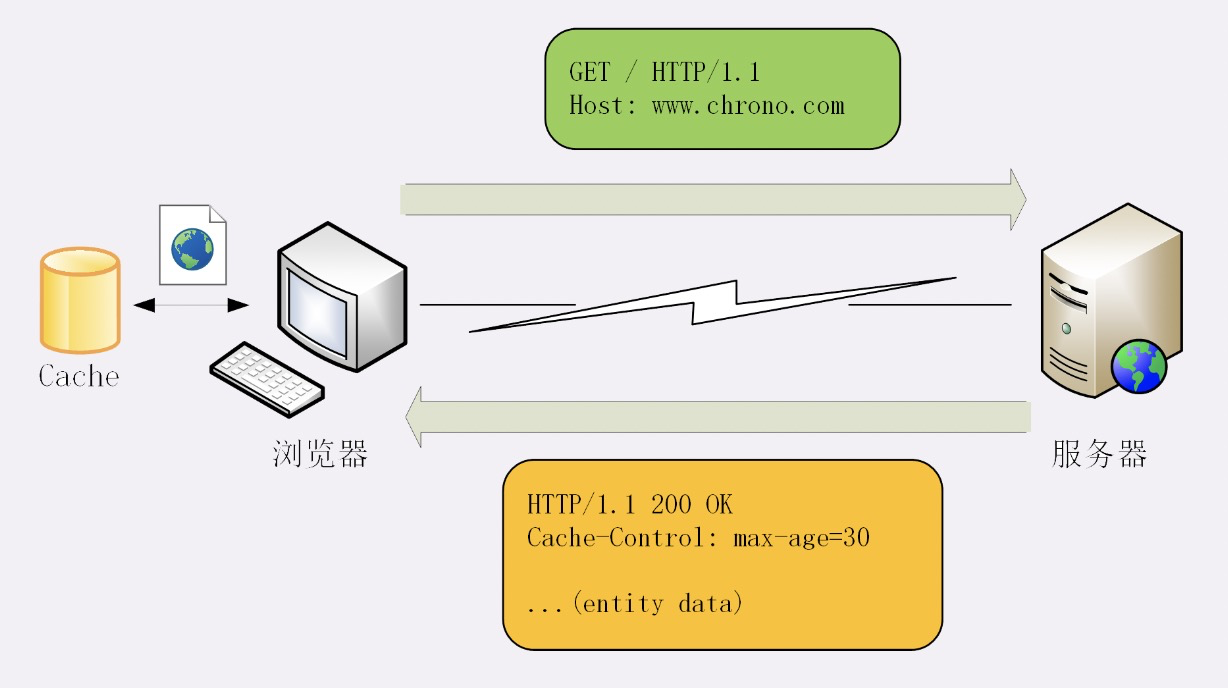
- 浏览器发现缓存无数据,于是发送请求,向服务器获取资源;
- 服务器响应请求,返回资源,同时标记资源的有效期;
-
Cache-Control
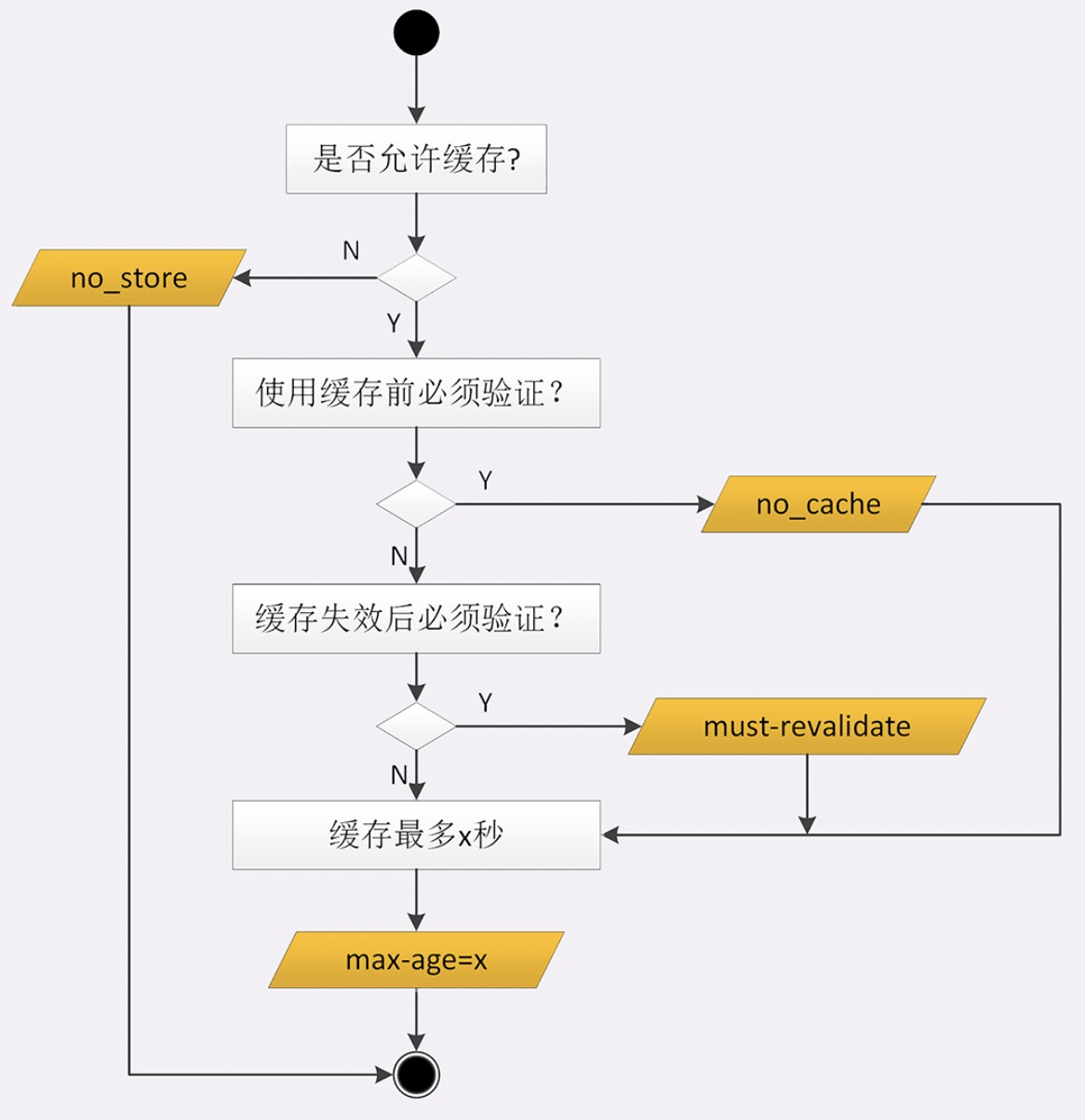
max-age是 HTTP 缓存控制最常用的属性
- no_store:不允许缓存,用于某些变化非常频繁的数据,例如秒杀页面;
- no_cache:它的字面含义容易与 no_store 搞混,实际的意思并不是不允许缓存,而是可以缓存,但在使用之前必须要去服务器验证是否过期,是否有最新的版本;可以理解为“max-age=0,must-revalidate“
must-revalidate:又是一个和 no_cache 相似的词,它的意思是如果缓存不过期就可以继续使用,但过期了如果还想用就必须去服务器验证。
F5(刷新):浏览器会在请求头里加一个“Cache-Control: max-age=0”。因为 max-age 是“生存时间”,max-age=0 的意思就是“我要一个最最新鲜的西瓜”,而本地缓存里的数据至少保存了几秒钟,所以浏览器就不会使用缓存,而是向服务器发请求。服务器看到 max-age=0,也就会用一个最新生成的报文回应浏览器
- Ctrl+F5(强制刷新): 请求头里的 If-Modified-Since 和 If-None-Match 会被清空所以会返回最新数据
- “前进”“后退”“跳转”这些重定向动作中浏览器不会“夹带私货”,只用最基本的请求头,没有“Cache-Control”,所以就会检查缓存,直接利用之前的资源,不再进行网络通信。
if-Modified-Sinc/Last-modified
文件的最后修改时间。需要服务器预先在响应报文里设置,搭配条件请求使用;
If-None-Match/ETag
资源的一个唯一标识,主要是用来解决修改时间无法准确区分文件变化的问题。
代理

代理服务就是指服务本身不生产内容,而是处于中间位置转发上下游的请求和响应,具有双重身份:面向下游的用户时,表现为服务器,代表源服务器响应客户端的请求;而面向上游的源服务器时,又表现为客户端,代表客户端发送请求。
反向代理的作用:
- 负载均衡:通过轮询、一致性哈希等算法,尽量把外部的流量合理地分散到多台源服务器,提高系统的整体资源利用率和性能。
- 健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用;
- 安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载;
- 加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本;
- 数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应;
内容缓存:暂存、复用服务器响应。
Via:标明代理的身份。Via: proxy1, proxy2”
- X-Forwarded-For:请求方的 IP 地址。包括中间代理的信息
- X-Real-IP:记录客户端 IP 地址,没有中间的代理信息

客户端的缓存只是用户自己使用,而代理的缓存可能会为非常多的客户端提供服务。所以,需要对它的缓存再多一些限制条件。
- 用两个新属性“private”和“public”来区分客户端上的缓存和代理上的缓存
- private”表示缓存只能在客户端保存,是用户“私有”的,不能放在代理上与别人共享。
- public”的意思就是缓存完全开放,谁都可以存,谁都可以用。
s-maxage:代理的生命周期
max-stale:如果代理上的缓存过期了也可以接受,但不能过期太多,超过 x 秒也会不要。
min-fresh:缓存必须有效,而且必须在 x 秒后依然有效
HTTPS
端口号:443
高度信任的应用场景:网络购物
- 网上银行
- 证券交易
 :::info
TLS 由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,
:::info
TLS 由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,
综合使用了对称加密、非对称加密、身份认证等许多密码学前沿技术。
:::
 :::tips
密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法
:::tips
密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法
ECDHE-RSA-AES256-GCM-SHA384
握手时使用 ECDHE 算法进行密钥交换,用 RSA 签名和身份认证,握手后的通信使用 AES 对称算法,密钥长度 256 位,分组模式是 GCM,摘要算法 SHA384 用于消息认证和产生随机数。
:::
OpenSSL是一个著名的开源密码学程序库和工具包,几乎支持所有公开的加密算法和协议,已经成为了事实上的标准,许多应用软件都会用它作为底层库来实现 TLS 功能.
- 机密性:对称加密AES256
- 完整性:摘要算法SHA384
- 身份认证和不可否认:非对称加密RSA
对称加密
:::tips
对称加密只使用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换,常
用的有 AES 和 ChaCha20
:::

非对称加密
:::tips
非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交
换问题但速度慢,常用的有 RSA 和 ECC;
单向性,公钥私钥虽然都可以用来加密解密,但公钥加密后只能用私钥解密,反过来,私钥加密后也只能用公钥解密。 :::

混合加密

数字证书与签名
摘要算法
:::info
只有算法,没有密钥,加密后的数据无法解密,不能从摘要逆推出原文.能够把任意长度的数据“压缩”成
固定长度、而且独一无二的“摘要”字符串,就好像是给这段数据生成了一个数字“指纹”。如MD5(Message-Digest 5)、SHA-1(SecureHash Algorithm 1)。
:::
完整性必须要建立在机密性之上,在混合加密系统里用会话密钥加密消息和摘要,这样黑客无法得知明文,也就没有办法动手脚。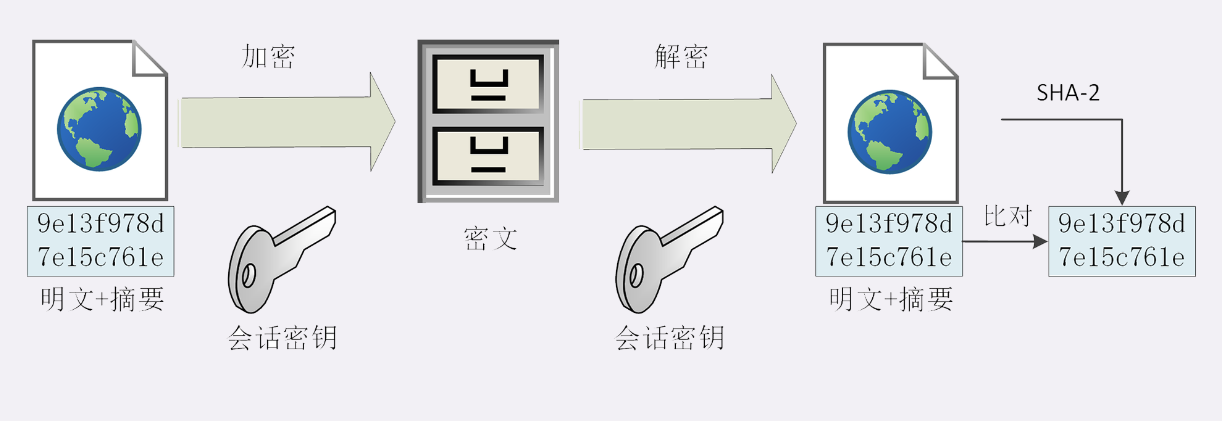
数字签名
:::info 数字签名 = 私钥 + 摘要算法 :::

CA

TSL 握手
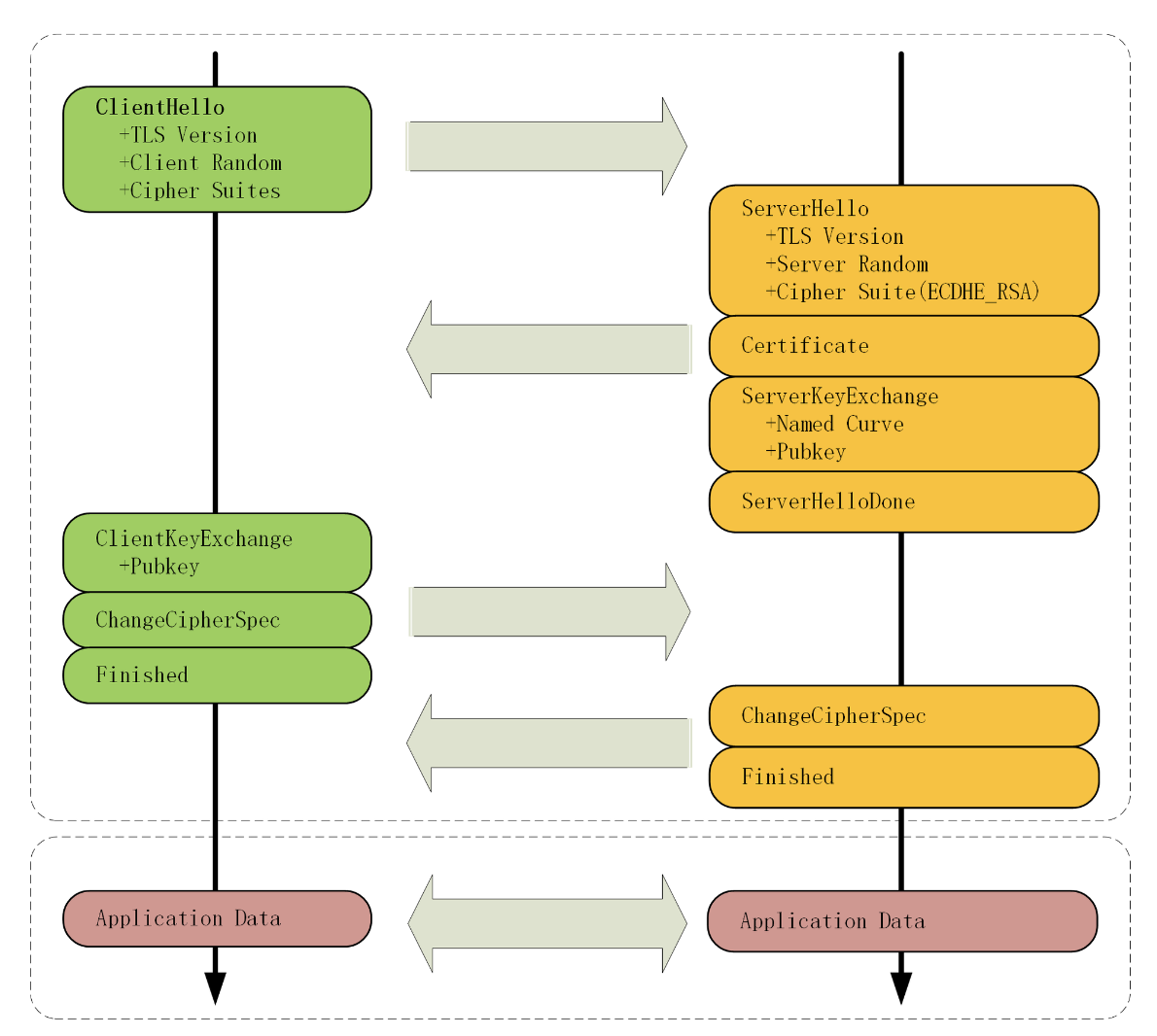


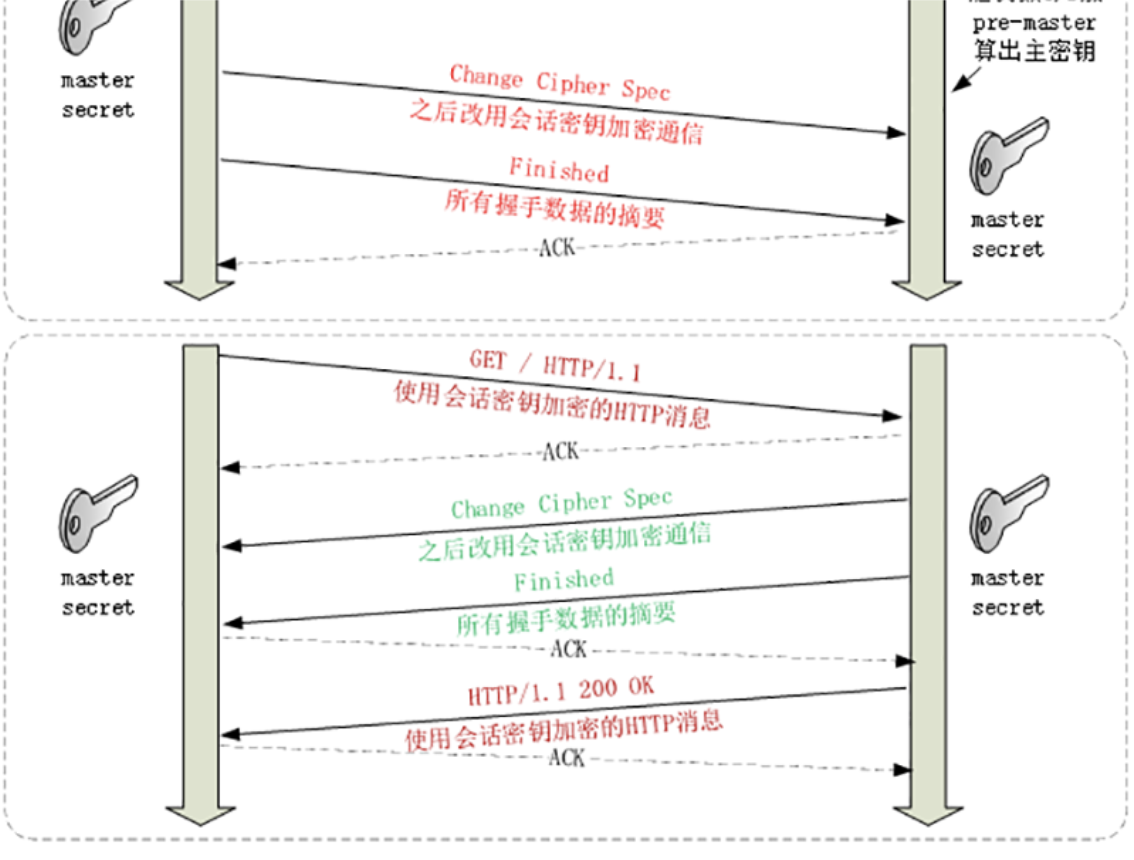

浏览器:
- 客户端的TSL版本号
- 支持的密码套件列表
- 一个随机数C

服务端:
- 服务端确认TSL版本号
- 选择的密码套件
- 一个随机数S
- 证书

服务端:
- 选择的非对称加密算法
- 公钥
- 数字签名

客户端:
- 公钥:按密码套件的要求生成的
master_secret = PRF(pre_master_secret, "master secret",ClientHello.random + ServerHello.random)
HTTP 的特点
- HTTP 是灵活可扩展的,可以任意添加头字段实现任意功能;
- HTTP 是可靠传输协议,基于 TCP/IP 协议“尽量”保证数据的送达;
- HTTP 是应用层协议,比 FTP、SSH 等更通用功能更多,能够传输任意数据;
- HTTP 使用了请求-应答模式,客户端主动发起请求,服务器被动回复请求;
- HTTP 本质上是无状态的,每个请求都是互相独立、毫无关联的,协议不要求客户端或服务器记录请求相关的信息。

若有收获,就点个赞吧
0 人点赞
