Dubbo简介
Dubbo是阿里巴巴开源的基于 Java 的高性能 RPC 分布式服务框架,现已成为 Apache 基金会孵化项目。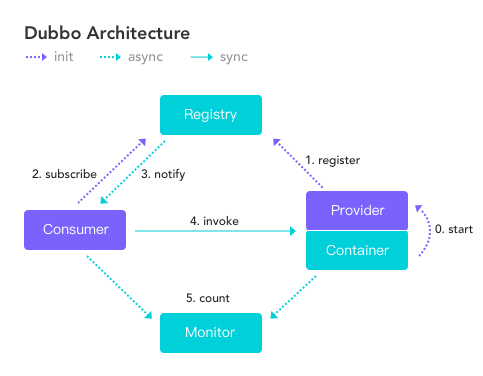
1、register:注册进zookeeper
2、subscribe:订阅
3、notify:通知
4、invoke:调用
5、count:计数监听
*RPC
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。有多种 RPC模式和执行。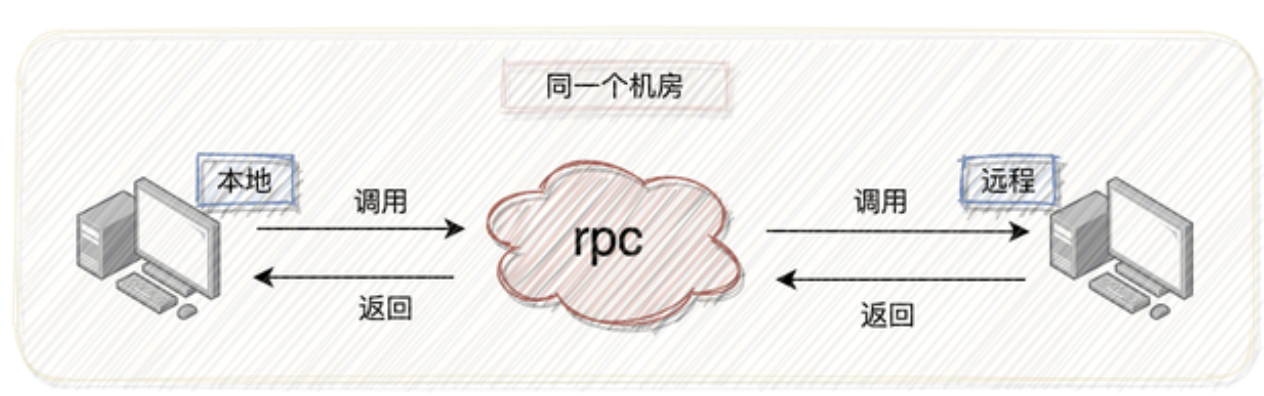
我们用一种通俗易懂的语言解释它,远程调用就是本地机器调用远程机器的一个方法,远程机器返回结果的过程。
特性
- 面向接口代理的高性能RPC调用;
- 服务自动注册与发现;
- 运行期流量调度;
- 智能负载均衡;
- 高可扩展;
-
解决的问题
高性能、透明的RPC调用;
服务的自动注册与发现(自动负载与容错、动态流量调度、依赖分析与调用统计)
*dubbo能做什么
远程通讯:dubbo-remoting模块, 提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型,序列化,以及“请求-响应”模式的信息交换方式。
- 集群容错: 提供基于接口方法的透明远程过程调用,包括多协议支持,以及软负载均衡,失败容错,地址路由,动态配置等集群支持。
- 自动发现: 基于注册中心目录服务,使服务消费方能动态的查找服务提供方,使地址透明,使服务提供方可以平滑增加或减少机器。
Dubbo和Spring Cloud的区别
Dubbo基于RPC,Spring Cloud基于HTTP Restful,开源Dubbo组件没有SpringCloud完善,比如缺少服务网关、分布式配置等等。谈谈对RESTful的理解
英文全称:Resource Representational State Transfer,对资源的访问状态的变化通过url的变化表述出来,REST描述的是在网络中client和server的一种交互形式,用大白话来说就是通过url就知道要什么资源,通过HTTP method就知道要干什么,通过HTTP status code就知道结果如何。
其实和rpc有一定的区别,rpc通常包括通信协议与序列化协议,而http只是一个通信协议,不是一个完整的远程调用方案,也就是说,http和rpc不是对等的概念,用来比较不合适。应用架构演进过程
单体应用:JEE时期->MVC时期
分布式应用:早期SOA->微服务化->云原生Dubbo大图
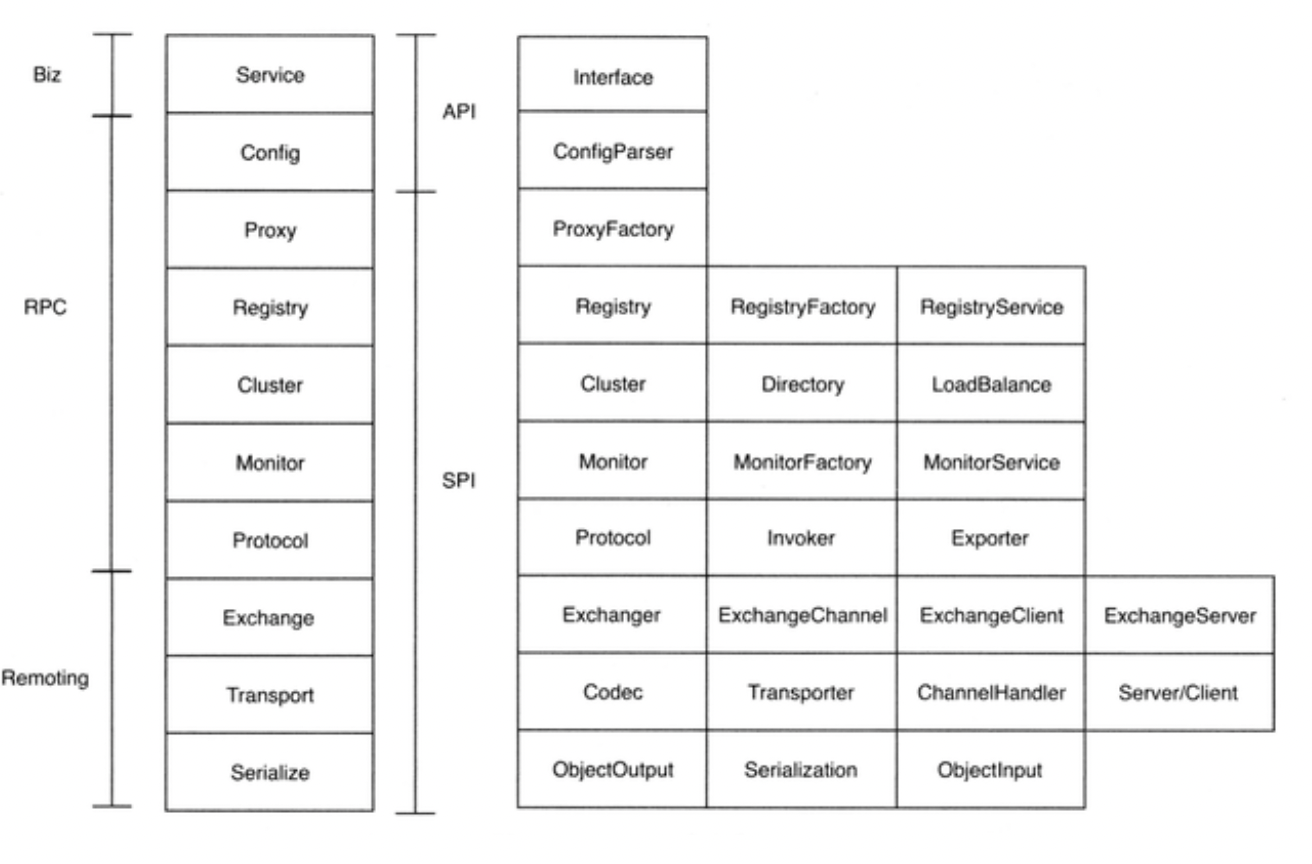
*总体分层
业务层(Biz)、RPC层、Remote层。
- Business:业务逻辑层由我们自己来提供接口和实现还有一些配置信息;
- RPC:就是真正的RPC调用的核心层,封装整个RPC的调用过程、负载均衡、集群容错、代理;
- Remoting:则是对网络传输协议和数据转换的封装。
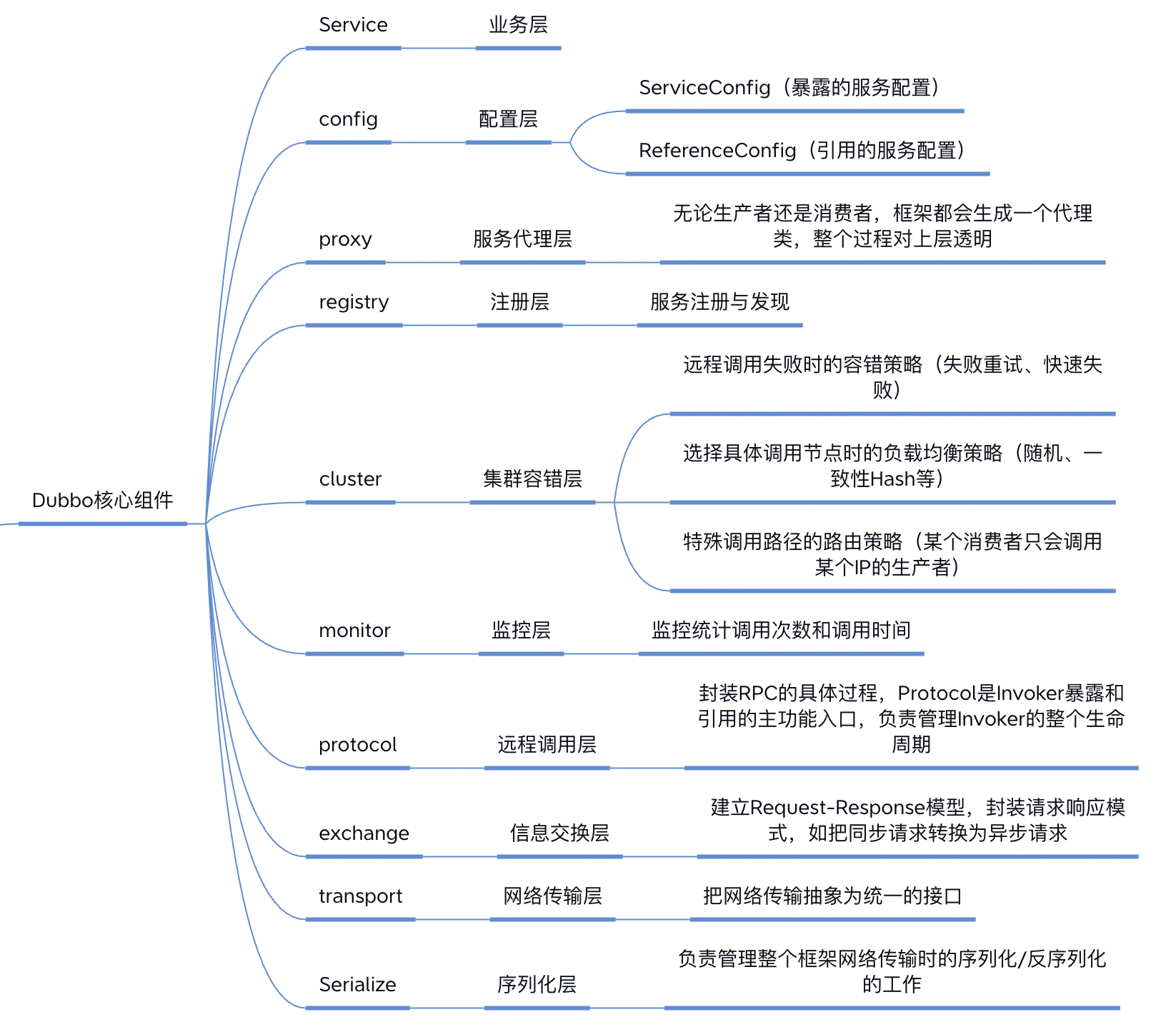
Dubbo核心组件
*调用过程
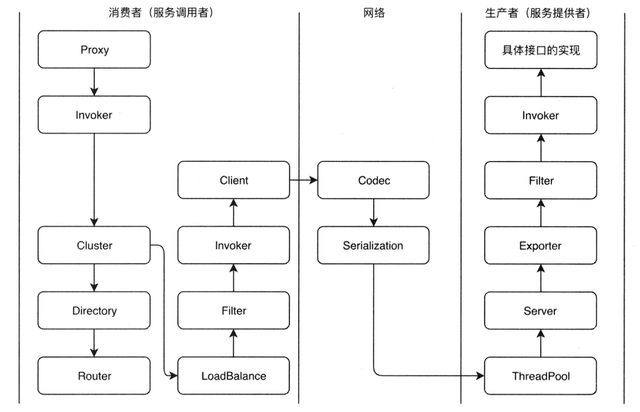
- Proxy持有一个Invoker对象,使用Invoker调用
- 之后通过Cluster进行负载容错,失败重试;
- 调用Directory获取远程服务的Invoker列表;
- 负载均衡用户配置了路由规则,则根据路由规则过滤获取到的Invoker列表用户没有配置路由规则或配置路由后还有很多节点,则使用LoadBalance方法做负载均衡,选用一个可以调用的Invoker;
- 经过一个一个过滤器链,通常是处理上下文、限流、计数等;
- 会使用Client做数据传输;
- 私有化协议的构造(Codec);
- 进行序列化;
- 服务端收到这个Request请求,将其分配到ThreadPool中进行处理;
- Server来处理这些Request;
- 根据请求查找对应的Exporter;
- 之后经过一个服务提供者端的过滤器链;
-
Dubbo注册中心
注册中心概述
主要作用
动态加入:提供者通过注册中心可以动态把自己暴露给其他消费者,无须消费者逐个更新配置文件
- 动态发现
- 动态调整:注册中心支持参数的动态调整
- 统一配置:避免了本地配置导致每个服务的配置不一致问题
Zookeeper原理概述
Zookeeper是树形结构的注册中心,每个节点的类型分为持久节点、持久顺序结点、临时节点和临时顺序节点;根结点是注册中心分组,下面有多个服务接口,分组值来自
Redis原理概述
使用key/map实现,结构如下:
[key:Root+Service+Type,value:[key:Url,value:超时时间]]
订阅、发布
Zookeeper
发布实现:
create节点;
订阅实现:
pull:消费者第一次启动时,全量拉取,并在订阅节点上注册一个watcher,客户端与其保持TCP长连接,后续通过watcher回调通知;
push:后续有事件发生时,因为每个节点都有版本号,发生变化就触发watcher事件。
Redis
依靠Redis的publish/subscribe功能即可。
Dubbo扩展点加载机制
加载机制概述
*SPI是什么
SPI(Service Provider Interface),是一种服务发现机制,其实就是将接口的实现类写入配置当中,在服务加载的时候将配置文件读出,加载实现类,这样就可以在运行的时候,动态的帮助接口替换实现类。
Dubbo的SPI其实是对java的SPI进行了一种增强,可以按需加载实现类之外,增加了 IOC 和 AOP 的特性,还有自适应扩展机制。
SPI在dubbo应用很多,包括协议扩展、集群扩展、路由扩展、序列化扩展等等。
Dubbo对于文件目录的配置分为了三类。
1.META-INF/services/ 目录:该目录下的 SPI 配置文件是为了用来兼容 Java SPI 。
2.META-INF/dubbo/ 目录:该目录存放用户自定义的 SPI 配置文件。
key=com.xxx.xxx
3.META-INF/dubbo/internal/ 目录:该目录存放 Dubbo 内部使用的 SPI 配置文件。
JAVA SPI
Dubbo SPI是基于Java SPI做的优化,所以我们先看看Java原生态的spi:
SPI使用策略模式,一个接口多种实现。Java SPI 在查找扩展实现类的时候遍历 SPI 的配置文件并且将实现类全部实例化,使用的具体的步骤是:
- 定义一个接口及对应的方法;
- 编写接口的一个实现类;
- 在META-INF/services/目录下,创建一个以接口全路径命名的文件;
- 文件内容为具体实现类的全路径名,如果有多个,则用分行符分隔;
在代码中通过java.util.ServiceLoader来加载具体的实现类。
*Dubbo SPI
与Java SPI的区别是:
对 Dubbo 进行扩展,不需要改动 Dubbo 的源码;
- 懒加载,可以一次只加载自己想要加载的扩展实现,注解实现;
- 抛出真实异常并打印日志;
实现了IOC和AOP机制,一个扩展点可以直接 setter 注入其它扩展点。
扩展点的分类
第一种分类分为Class缓存与实例缓存:对于Class缓存,获取扩展类时,先从缓存中读取,没有就加载配置文件,根据配置把Class缓存到内存中,并不会全部初始化;对于实例缓存,不仅会缓存Class,也会缓存Class实例化后的对象。
第二种是依据特性分类:普通扩展类:最基础的,配置在SPI配置文件中的扩展类实现;
- 包装扩展类:这种Wrapper类没有具体的实现,只做了通用的逻辑的抽象,并需要在构造方法中传入一个具体的扩展接口的实现;
- 自适应扩展类:一个扩展接口会有多种实现类,具体使用哪个实现类可以通过传入URL中的某些参数动态确定;
-
扩展点的特性
自动包装:ExtensionLoader在加载扩展时,如果发现这个扩展类包含其他扩展点作为构造函数的参数,则这个扩展类就会被认为是Wrapper类;
- 自动加载:ExtensionLoader在执行扩展点初始化的时候,会自动通过setter方法注入对应的实现类;
- 自适应:使用@Adaptive注解,可以动态地通过URL中的参数来确定要使用哪个具体的实现类;
自动激活:使用@Activate注解,可以标记对应的扩展点默认被激活使用。
扩展点注解
@SPI
标记这个接口是一个Dubbo SPI接口,即是一个扩展点,可以有多个不同的内置或用户定义的实现,运行时通过配置找到具体的实现类;
@Adaptive
类级别的注释,会直接将整个实现类作为默认实现,不在自动生成代码清单。多个实现里,只能有一个实现上可以加@Adaptive注解;
可以传入多个value参数,会一一匹配。@Activate
主要使用在有多个扩展点实现、需要根据不同条件被激活的场景中,
如Filter需要多个同时激活,因为每个Filter实现的是不同的功能。ExtensionLoader的工作原理
Dubbo启停原理解析
基于注解配置原理解析
注解处理逻辑
如果用户使用了配置文件,则框架按需生成对应Bean;
- 将所有使用Dubbo的注解@Service的class提升为Bean;
-
通过注解@Service进行暴露
本质:使用asm库进行字节码扫描注解元数据。
ServiceAnnotationBeanPostProcessor 提取用户配置的扫描包名称,进行解码;
- 开始真正的注解扫描,委托Spring对符合包名进行字节码分析;
- 使用@Service注解作为过滤条件;
- 将@Service标注的服务提升为不同的Bean;
- 根据注册的普通Bean生成ServiceBean占位符,用于后面的属性注入逻辑;
- 提取普通Bean上标注的Service注解生成新的RootBeanDefinition,用于Spring启动后的服务暴露。
ReferenceAnnotationBeanPostProcessor
- 获取类中标注的@Reference注解的字段和方法;
-
服务暴露的实现原理
配置承载初始化
-D传递给JVM参数优先级最高;
- 代码或XML配置优先级次高;
- 配置文件优先级最低;
受到provider影响,如果只有provider端指定配置,则会自动透传到客户端;如果客户端也配置了相应的属性,则服务端配置会被覆盖。
*远程服务的暴露机制
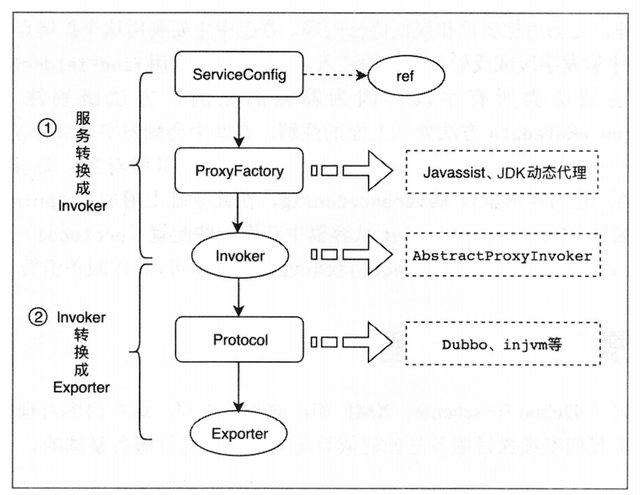
1.通过ServiceConfig解析标签,创建dubbo标签解析器来解析dubbo的标签,容器创建完成之后,触发ContextRefreshEvent事件回调开始暴露服务;
2.通过proxyFactory.getInvoker方法,并利用javassist或JdkProxyFactory来进行动态代理,将服务暴露接口封装成invoker对象,里面包含了需要执行的方法的对象信息和具体的URL地址;
3.再通过DubboProtocol的实现把包装后的invoker转换成exporter;
4.然后启动服务器server,监听端口;
5.最后RegistryProtocol保存URL地址和invoker的映射关系,同时注册到服务中心。服务消费的实现原理
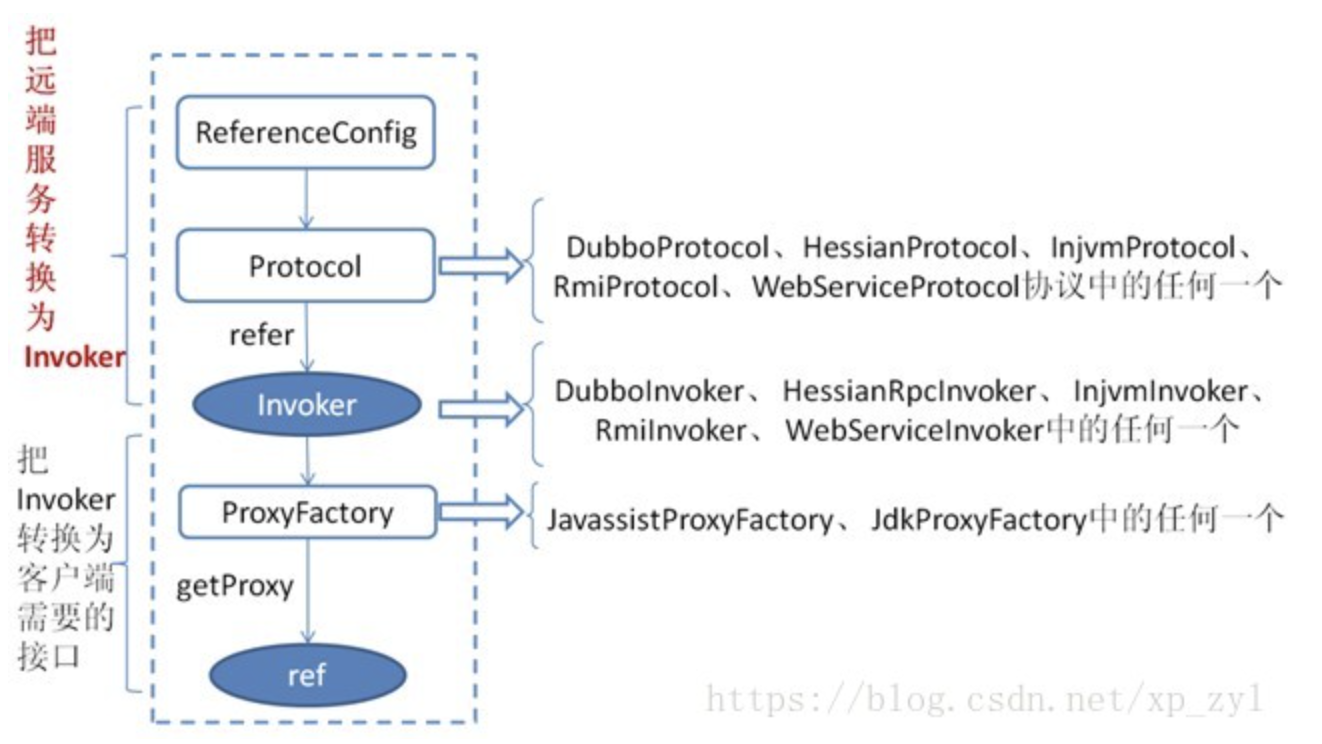
简而言之就是将远程服务转化为invoker,再将invoker转化成本地接口代理。*服务引用的流程
首先客户端根据config文件信息从注册中心订阅服务,首次会全量缓存到本地,后续的更新会监听动态更新到本地;
- DubboProtocol根据provider的地址和接口信息连接到服务端server,开启客户端client,然后创建invoker;
通过invoker为服务接口生成代理对象,这个代理对象用于远程调用provider,至此完成了服务引用。
*优雅停机
收到kill 9进程退出信号,Spring容器会出发容器销毁事件;
- provider端会取消注册服务元数据信息;
- consumer端会收到最新地址列表;
- Dubbo协议会发送readonly事件报文通知consumer服务不可用;
-
Dubbo远程调用
Dubbo调用介绍
从注册中心拉取和订阅对应的服务列表,Cluster将拉取的服务列表聚合成一个Invoker,每次RPC调用前会通过Directory#list获取providers地址;
- 触发路由操作,将路由结果得到的服务列表作为负载均衡参数,选出一台机器进行RPC调用;
- 将请求交给底层I/O线程池处理,线程池处理读写、序列化和反序列化等逻辑,不能阻塞;
进行端口复用,如果是Telnet调用,则先找出Invoker进行调用,Telnet序列化不使用Hessian,而是直接使用fastjson。
*Dubbo支持的协议以及各自的优缺点
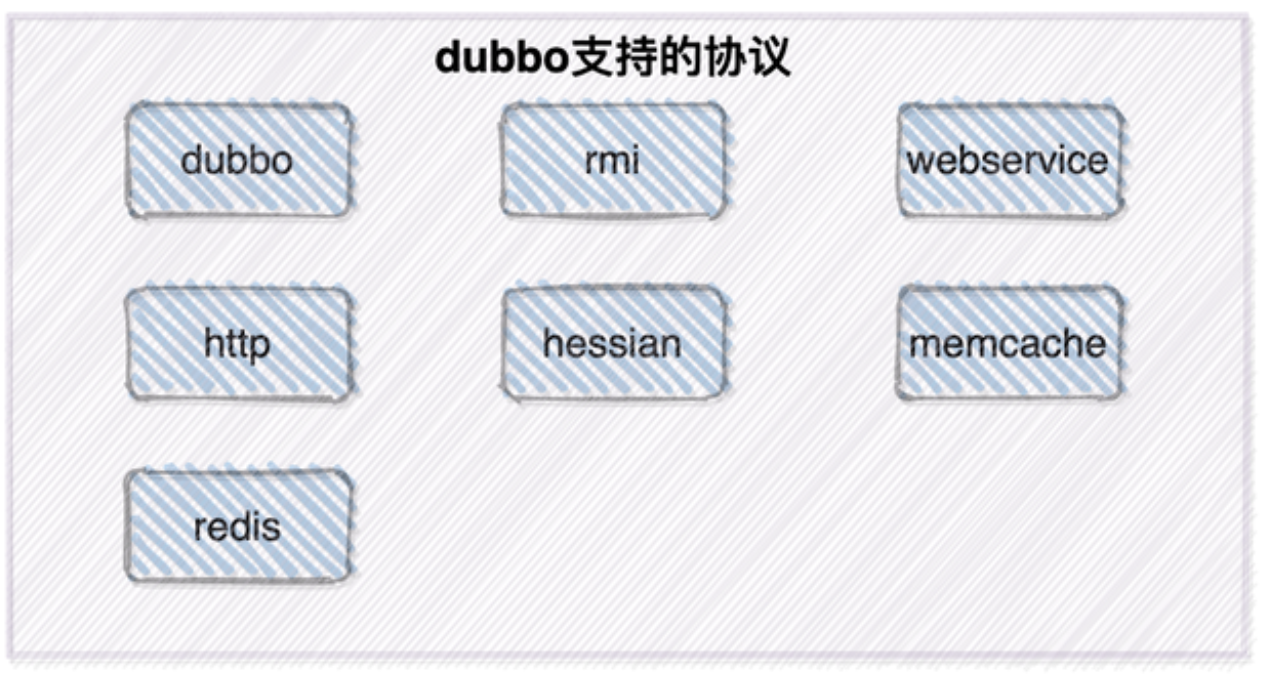
dubbo 单一长连接和 NIO 异步通讯,适合大并发小数据量的服务调用,以及消费者远大于提供者。传输协议 TCP,异步,Hessian 序列化
- rmi 采用 JDK 标准的 rmi 协议实现,传输参数和返回参数对象需要实现Serializable 接口,使用 java 标准序列化机制,使用阻塞式短连接,传输数据包大小混合,消费者和提供者个数差不多,可传文件,传输协议 TCP。 多个短连接,TCP 协议传输,同步传输,适用常规的远程服务调用和 rmi 互 操作。在依赖低版本的 Common-Collections 包,java 序列化存在安全漏洞
- webservice 基于 WebService 的远程调用协议,集成 CXF 实现,提供和原生 WebService 的互操作。多个短连接,基于 HTTP 传输,同步传输,适用系统集成和跨语言调用;
- http 基于 Http 表单提交的远程调用协议,使用 Spring 的 HttpInvoke 实 现。多个短连接,传输协议 HTTP,传入参数大小混合,提供者个数多于消 费者,需要给应用程序和浏览器 JS 调用;
- hessian 集成 Hessian 服务,基于 HTTP 通讯,采用 Servlet 暴露服务,Dubbo 内嵌 Jetty 作为服务器时默认实现,提供与 Hession 服务互操作。多个短连接,同步 HTTP 传输,Hessian 序列化,传入参数较大,提供者大于消费者,提供者压力较大,可传文件;
- memcache 基于 memcached 实现的 RPC 协议;
-
Dubbo集群容错
Cluster层概述
组成
Cluster、Directory、Router、LoadBalance工作总体流程
生成Invoker对象;
- 获得可调用的服务列表;
- 做负载均衡;
-
*容错机制
Failover:失败重试其他服务器;(默认)
- Failfast:快速失败;
- Failsafe:忽略异常;
- Failback:记录在失败队列,启动定时线程池重试;
- Forking:同时调用多个相同的服务,只要其中一个返回,则立即返回结果;
- Broadcast:广播调用所有可用的服务,任意一个节点报错则报错;
- Mock:调用失败时,返回伪造的响应结果;
- Available:找到第一个可用节点直接请求;
-
路由规则
负载均衡的实现
包装后的负载均衡
select特性
粘滞连接:尽可能让客户端总是向同一提供者发起调用,除非提供者“挂了”;
- 可用检测;
- 避免重复调用:对于已经调用过的远程服务,避免重复选择,每次都使用同一个节点。
步骤
- 检查URL是否有配置的粘滞连接;
- 通过ExtensionLoader获取负载均衡的具体实现;
- 进行节点的重新选择;
遍历所有已经调用过的节点,选出所有可用的节点,再通过负载均衡选出一个节点并返回。
*负载均衡的算法
Random LoadBalance(默认):随机,按权重设置随机概率;
- RoundRobin LoadBalance:轮询,按公约后的权重设置轮询比例;
- LeastActive LoadBalance:最少活跃调用数,如果相同则随机调用,活跃数是指调用前后计数差,使慢的提供者收到更少的请求;(每个服务提供者对应一个活跃数active 初始情况下,所有服务提供者活跃数均为0.每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数下降的也越快)
ConsistentHash LoadBalance:一致性哈希,相同参数的请求总是发到同一提供者。
Dubbo高级特性
主要有服务分组和版本、参数回调、隐式参数、异步调用、泛化调用等。
泛化调用
泛化调用是指不依赖服务接口API包的场景中发起远程调用。必须的参数需要有应用名称、注册中心、真实接口名称和泛化标识。
原理服务端处理调用时,在GenericFilter拦截器中把RpcInvocation中传递过来的参数类型和参数值提取出来,根据传递过来的接口名、方法名和参数类型查找服务端被调用的方法;
- 获取方法后,提取真实方法参数类型,然后将参数值做类型转换;
用解析后的参数值构造新的RpcInvocation对象发起调用。
Dubbo注册中心扩展
etcd背景介绍
etcd介绍
etcd是一种分布式键值存储系统,它提供了可靠的集群存储数据的途径;etcd使用Raft算法保证集群中的数据的一致性,leader下线时会触发leader选举。
优点不用全量拉取节点数据,降低网络压力;
- 使用增量快照,避免在创建快照时暂停;
- 使用对外存储,没有垃圾收集暂停功能;
- 在Kubernates中有大量生产实践,有稳定性;
- 具有更简单的运维和使用特性,基于Go开发更轻量;
- etcd的watch可以一直存在;
- Zookeeper会丢失一些旧的事件,etcd设计了一个滑动窗口来保存一段时间内的事件,客户端重连就不会丢失;
-
etcd数据结构设计
etcd的所有元数据信息都是基于键值对存储的,和Zookeeper中节点和子节点不同,etcd存储是通过前缀区分的。

补充面试题
Dubbo中运用的设计模式
责任链模式:责任链模式在Dubbo中发挥的作用举足轻重,就像是Dubbo框架的骨架。Dubbo的调用链组织是用责任链模式串连起来的。责任链中的每个节点实现Filter接口,然后由ProtocolFilterWrapper,将所有Filter串连起来。Dubbo的许多功能都是通过Filter扩展实现的,比如监控、日志、缓存、安全、telnet以及RPC本身都是。
- 观察者模式:Dubbo中使用观察者模式最典型的例子是RegistryService。消费者在初始化的时候回调用subscribe方法,注册一个观察者,如果观察者引用的服务地址列表发生改变,就会通过NotifyListener通知消费者。此外,Dubbo的InvokerListener、ExporterListener 也实现了观察者模式,只要实现该接口,并注册,就可以接收到consumer端调用refer和provider端调用export的通知。
- 修饰器模式:Dubbo中还大量用到了修饰器模式。比如ProtocolFilterWrapper类是对Protocol类的修饰。在export和refer方法中,配合责任链模式,把Filter组装成责任链,实现对Protocol功能的修饰。其他还有ProtocolListenerWrapper、 ListenerInvokerWrapper、InvokerWrapper等。
- 工厂方法模式:CacheFactory的实现采用的是工厂方法模式。CacheFactory接口定义getCache方法,然后定义一个AbstractCacheFactory抽象类实现CacheFactory,并将实际创建cache的createCache方法分离出来,并设置为抽象方法。这样具体cache的创建工作就留给具体的子类去完成。
- 抽象工厂模式:ProxyFactory及其子类是Dubbo中使用抽象工厂模式的典型例子。ProxyFactory提供两个方法,分别用来生产Proxy和Invoker(这两个方法签名看起来有些矛盾,因为getProxy方法需要传入一个Invoker对象,而getInvoker方法需要传入一个Proxy对象,看起来会形成循环依赖,但其实两个方式使用的场景不一样)。AbstractProxyFactory实现了ProxyFactory接口,作为具体实现类的抽象父类。然后定义了JdkProxyFactory和JavassistProxyFactory两个具体类,分别用来生产基于jdk代理机制和基于javassist代理机制的Proxy和Invoker。
- 适配器模式:为了让用户根据自己的需求选择日志组件,Dubbo自定义了自己的Logger接口,并为常见的日志组件(包括jcl, jdk, log4j, slf4j)提供相应的适配器。并且利用简单工厂模式提供一个LoggerFactory,客户可以创建抽象的Dubbo自定义Logger,而无需关心实际使用的日志组件类型。在LoggerFactory初始化时,客户通过设置系统变量的方式选择自己所用的日志组件,这样提供了很大的灵活性。
代理模式:Dubbo consumer使用Proxy类创建远程服务的本地代理,本地代理实现和远程服务一样的接口,并且屏蔽了网络通信的细节,使得用户在使用本地代理的时候,感觉和使用本地服务一样。
如果Dubbo中provider提供的服务由多个版本怎么办?
可以直接通过Dubbo配置中的version版本来控制多个版本即可。
比如:<dubbo:service interface="com.xxxx.rent.service.IDemoService" ref="iDemoServiceFirst" version="1.0.0"/><dubbo:service interface="com.xxxx.rent.service.IDemoService" ref="iDemoServiceSecond" version="1.0.1"/>
老版本 version=1.0.0,新版本version=1.0.1
服务提供者能实现失效踢出是什么原理?
服务失效踢出基于Zookeeper的临时节点原理。
Zookeeper中节点是有生命周期的,具体的生命周期取决于节点的类型,节点主要分为持久节点(Persistent)和临时节点(Ephemeral) 。为什么要通过代理对象通信?
其实主要就是为了将调用细节封装起来,将调用远程方法变得和调用本地方法一样简单,还可以做一些其他方面的增强,比如负载均衡,容错机制,过滤操作,调用数据的统计。
怎么设计一个RPC框架?
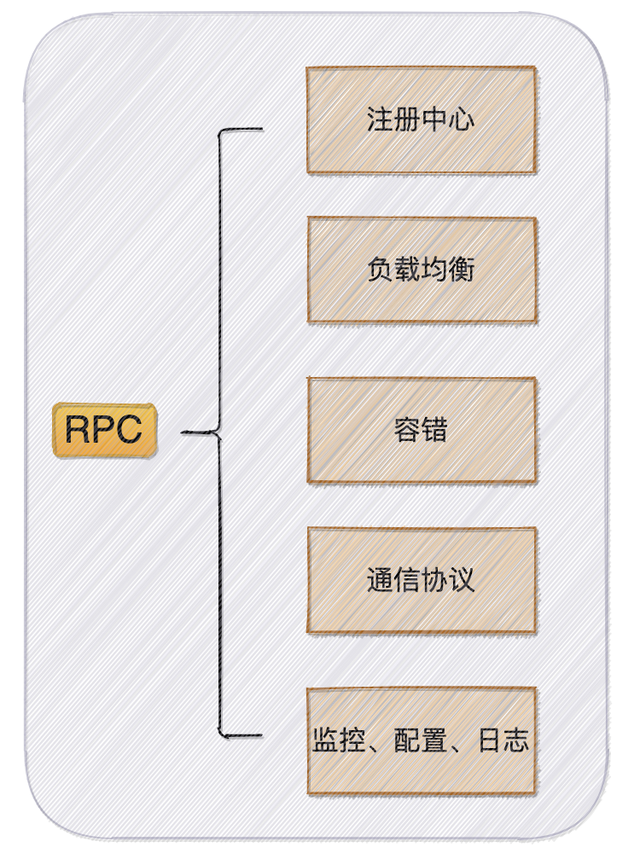
首先我们得需要一个注册中心,去管理消费者和提供者的节点信息,这样才会有消费者和提供才可以去订阅服务,注册服务;
- 当有了注册中心后,可能会有很多个provider节点,那么我们肯定会有一个负载均衡模块来负责节点的调用,至于用户指定路由规则可以使一个额外的优化点;
- 具体的调用肯定会需要牵扯到通信协议,所以需要一个模块来对通信协议进行封装,网络传输还要考虑序列化;
- 当调用失败后怎么去处理?所以我们还需要一个容错模块,来负责失败情况的处理;
- 其实做完这些一个基础的模型就已经搭建好了,我们还可以有更多的优化点,比如一些请求数据的监控,配置信息的处理,日志信息的处理等等。

若有收获,就点个赞吧
0 人点赞
